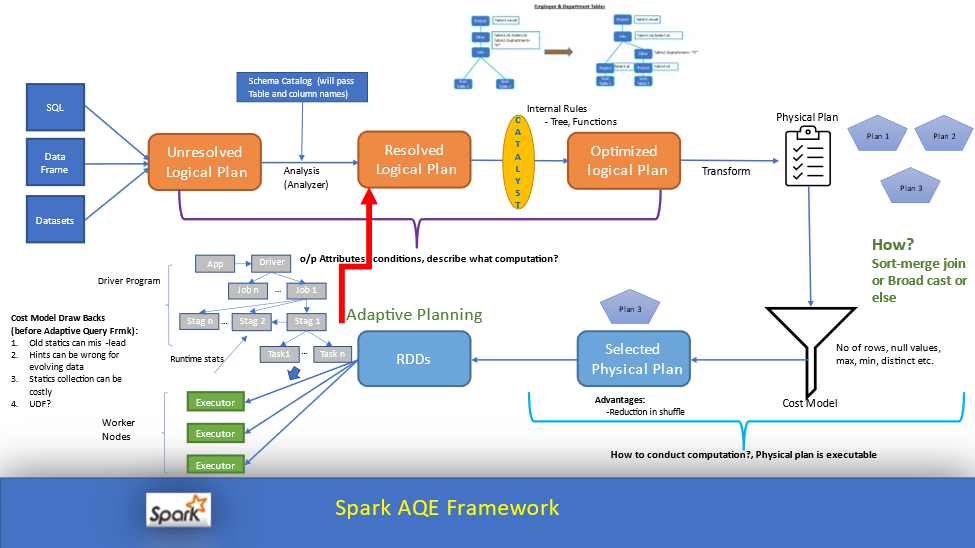
1. AQE 개요
Adaptive Query Execution(AQE)는 Apache Spark 3.0에서 도입된 동적 쿼리 최적화 프레임워크입니다. AQE는 런타임 시 발생하는 다양한 통계치를 수집하여, 기존의 정적 최적화가 가진 한계점을 극복하고 쿼리 성능을 향상시키는 기능입니다. Apache Spark 3.2 버전부터는 AQE가 기본적으로 활성화되어 있습니다.
AQE 이전의 Spark는 실행 계획을 최적화할 때 사전에 계산된 통계에만 의존했습니다. 이러한 정적 최적화 방식은 실제 데이터 특성과 달라 비효율적인 쿼리 실행으로 이어질 수 있었습니다. AQE는 쿼리 실행 중에 실시간으로 통계를 수집하고, 이를 바탕으로 쿼리 계획을 재최적화함으로써 보다 효율적인 실행을 가능하게 합니다.
2. AQE의 주요 기능
AQE는 다음과 같은 세 가지 주요 기능을 제공합니다:
2.1 동적 셔플 파티션 병합 (Dynamically coalescing shuffle partitions)

Spark에서는 셔플 파티션 수를 적절히 설정하는 것이 중요합니다. 파티션이 너무 많으면 작은 파일이 많이 생성되어 I/O 오버헤드가 증가하고, 파티션이 너무 적으면 병렬성이 떨어져 성능이 저하될 수 있습니다.
AQE는 셔플 통계를 분석하여 런타임에 작은 크기의 셔플 파티션들을 자동으로 병합합니다. 이를 통해:
- 작은 파일 생성을 줄여 I/O 오버헤드 감소
- 태스크 수 감소로 리소스 활용도 향상
- 사용자가 셔플 파티션 수를 수동으로 튜닝할 필요성 감소
# AQE 및 파티션 병합 활성화 설정
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", true)
2.2 동적 조인 전략 전환 (Dynamically switching join strategies)
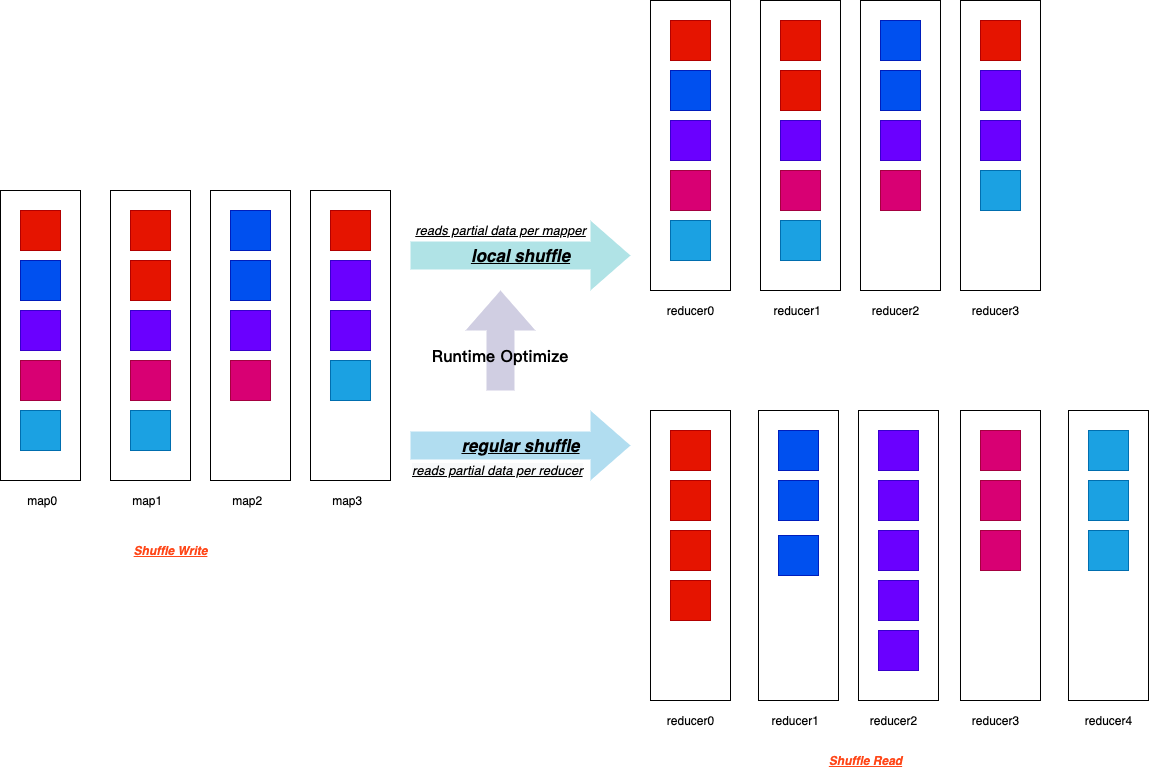
Spark에서는 주로 Broadcast Hash Join(BHJ)과 Sort Merge Join을 사용합니다. 기존에는 통계 기반으로 조인 전략을 선택했지만, 실제 데이터 크기와 특성이 예상과 다를 수 있었습니다.
AQE는 런타임에 실제 데이터 크기를 확인하고 최적의 조인 전략으로 전환합니다:
- 테이블 크기가 예상보다 작을 경우, Sort Merge Join에서 Broadcast Hash Join으로 전환
- 로컬 셔플 리더 활용으로 네트워크 트래픽 감소
2.3 데이터 스큐 최적화 (Dynamically optimizing skew joins)

데이터 스큐(특정 파티션에 데이터가 불균형하게 분포)는 Spark 작업 성능을 크게 저하시키는 요인입니다. 스큐가 있으면 일부 태스크가 다른 태스크보다 훨씬 오래 실행되어 전체 작업 지연이 발생합니다.
AQE는 스큐를 감지하고 다음과 같이 최적화합니다:
- 런타임에 스큐된 파티션 식별
- 스큐된 파티션을 여러 개의 작은 파티션으로 분할
- 균등한 크기의 태스크로 분산 처리
# 스큐 조인 최적화 활성화
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", true)
3. AQE 작동 원리
AQE는 쿼리 실행 중에 "query stages"라는 개념을 활용합니다. 각 쿼리 스테이지는:
- 교환(Exchange) 연산자를 기준으로 나뉨
- 실행 중 중간 결과가 구체화(materialize)되는 지점
- 다음 스테이지로 진행하기 전에 통계 정보 수집
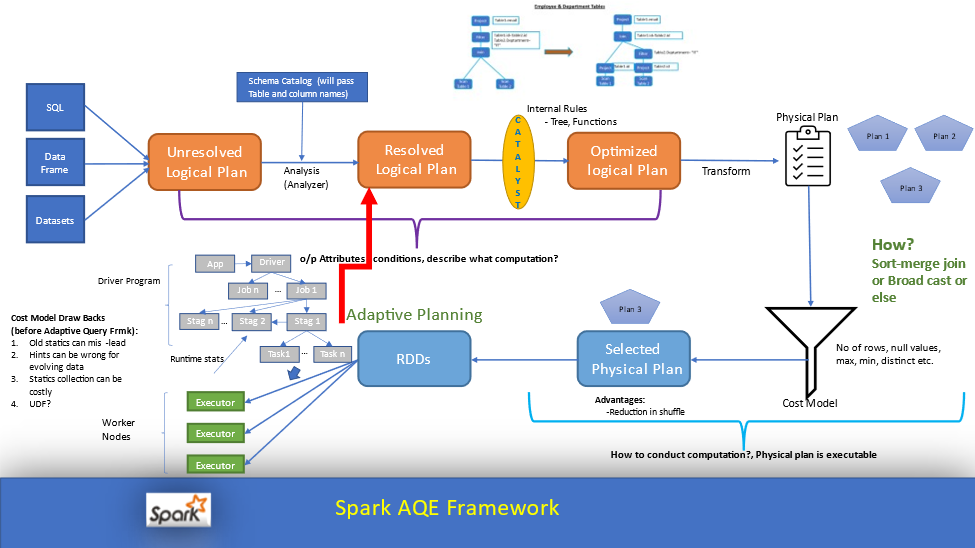
AQE 처리 흐름:
- 초기 실행 계획 생성
- 쿼리 실행 및 런타임 통계 수집
- 수집된 통계를 기반으로 실행 계획 재최적화
- 최적화된 계획으로 쿼리 계속 실행
4. AQE 구성 및 설정
AQE의 주요 구성 매개변수:
| 설정 | 기본값 | 설명 |
|---|---|---|
| spark.sql.adaptive.enabled | true (Spark 3.2+) | AQE 전체 활성화/비활성화 |
| spark.sql.adaptive.coalescePartitions.enabled | true | 셔플 파티션 병합 기능 활성화 |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 64MB | 목표 파티션 크기 |
| spark.sql.adaptive.skewJoin.enabled | true | 스큐 조인 최적화 활성화 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5.0 | 스큐 판단 기준 (중앙값 대비) |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 256MB | 스큐 판단 기준 (절대값) |
| spark.sql.adaptive.localShuffleReader.enabled | true | 로컬 셔플 리더 사용 여부 |
5. AQE의 이점
- 성능 향상: 런타임 통계를 활용한 최적화로 쿼리 성능 개선
- 자원 활용도 증가: 파티션 병합 및 스큐 최적화로 자원 효율성 향상
- 수동 튜닝 필요성 감소: 동적 최적화로 파티션 수 등의 수동 설정 부담 감소
- 데이터 스큐 자동 처리: 데이터 불균형 문제 자동 해결
- 메모리 사용 최적화: 불필요한 연산 제거와 효율적인 실행 계획으로 메모리 사용량 개선
6. 결론
Apache Spark의 Adaptive Query Execution은 런타임 통계를 활용하여 쿼리 실행 계획을 동적으로 최적화하는 강력한 기능입니다. AQE를 통해 셔플 파티션 병합, 조인 전략 전환, 데이터 스큐 최적화와 같은 중요한 최적화가 자동으로 이루어져 Spark 애플리케이션의 성능과 안정성이 크게 향상됩니다.
Spark 3.2 버전부터는 기본적으로 활성화되어 있어 별도의 설정 없이도 이점을 누릴 수 있지만, 특정 워크로드에 맞게 관련 매개변수를 조정하면 더 나은 성능을 얻을 수 있습니다.
참고 문헌
