
PySpark의 정의와 개념
PySpark는 Apache Spark를 위한 Python API입니다. Apache Spark는 빅데이터 처리를 위한 강력한 오픈소스 분산 컴퓨팅 시스템으로, 원래 Scala 언어로 작성되었습니다. PySpark는 Python 프로그래머들이 Spark의 강력한 기능을 활용할 수 있도록 개발되었으며, 데이터 과학자와 엔지니어들 사이에서 널리 사용되고 있습니다.
PySpark의 주요 특징
- 분산 처리: 대용량 데이터를 여러 컴퓨터에 분산하여 병렬로 처리할 수 있습니다.
- 인메모리 컴퓨팅: 데이터를 메모리에 캐싱하여 반복 작업의 성능을 크게 향상시킵니다.
- 고장 내성: 노드 실패에도 작업을 계속할 수 있는 내결함성 기능을 제공합니다.
- 지연 평가(Lazy Evaluation): 실제 계산이 필요할 때까지 연산을 지연시켜 효율성을 높입니다.
- 통합 분석: SQL, 스트리밍, 머신러닝, 그래프 처리 등 다양한 데이터 처리 방식을 하나의 프레임워크로 통합합니다.
PySpark 구성 요소 및 라이브러리
PySpark는 다양한 라이브러리와 모듈을 포함하고 있으며, 주요 구성 요소는 다음과 같습니다:
1. PySpark SQL
PySpark SQL은 구조화된 데이터 처리를 위한 모듈로, DataFrame API를 제공합니다. SQL과 유사한 쿼리를 실행하거나 복잡한 데이터 변환을 수행할 수 있습니다.
2. MLlib
MLlib은 PySpark의 머신러닝 라이브러리로, 분류, 회귀, 클러스터링, 협업 필터링 등 다양한 알고리즘을 지원합니다. 대량의 데이터에 대해 분산 환경에서 머신러닝 모델을 학습시키고 예측할 수 있습니다.
3. GraphFrames
GraphFrames는 그래프 분석을 위한 라이브러리로, 네트워크 분석, 경로 찾기, 페이지 랭크 등의 알고리즘을 제공합니다.
4. Streaming
PySpark Streaming은 실시간 데이터 스트림을 처리하기 위한 API를 제공합니다. 카프카, 플룸, 키네시스 등 다양한 소스에서 데이터를 스트리밍하여 실시간 분석을 수행할 수 있습니다.
PySpark 설치 및 환경 설정
PySpark를 사용하기 위해서는 먼저 Python과 Java가 설치되어 있어야 합니다. 설치 방법은 다음과 같습니다:
Copy# pip를 사용한 설치
pip install pyspark
# 하둡 지원 없이 설치
pip install pyspark --no-dependencies
PySpark 기본 사용법
1. SparkSession 생성하기
PySpark에서 모든 작업은 SparkSession에서 시작됩니다. SparkSession은 Spark 애플리케이션의 진입점입니다.
Copyfrom pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder \
.master("local[*]") \
.appName("PySpark 기초") \
.getOrCreate()
# 로그 레벨 설정 (선택사항)
spark.sparkContext.setLogLevel("ERROR")
이 코드에서:
master("local[*]"): 로컬 모드에서 실행하며, 가용한 모든 코어를 사용appName("PySpark 기초"): Spark 애플리케이션의 이름 설정getOrCreate(): 존재하는 세션이 있으면 사용하고, 없으면 새로 생성
2. DataFrame 생성하기
PySpark의 DataFrame은 관계형 데이터베이스의 테이블과 유사한 구조로, 열과 행으로 구성된 분산 데이터 컬렉션입니다. DataFrame을 생성하는 여러 방법이 있습니다:
2.1 리스트에서 DataFrame 생성
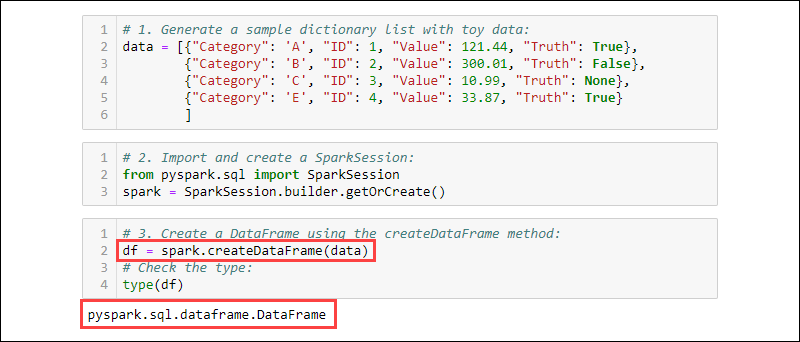
Copy# 간단한 데이터 리스트
data = [
("John", 30, "Sales"),
("Alice", 35, "Marketing"),
("Bob", 40, "Engineering"),
("Sarah", 28, "HR")
]
# 스키마 정의
columns = ["name", "age", "department"]
# DataFrame 생성
df = spark.createDataFrame(data=data, schema=columns)
# DataFrame 출력
df.show()
출력 결과:
+-----+---+------------+
| name|age| department|
+-----+---+------------+
| John| 30| Sales|
|Alice| 35| Marketing|
| Bob| 40|Engineering|
|Sarah| 28| HR|
+-----+---+------------+2.2 스키마 명시적 정의
보다 정확한 데이터 타입 제어를 위해 스키마를 명시적으로 정의할 수 있습니다:
Copyfrom pyspark.sql.types import StructType, StructField, StringType, IntegerType
# 스키마 정의
schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True),
StructField("department", StringType(), True)
])
# 명시적 스키마로 DataFrame 생성
df = spark.createDataFrame(data=data, schema=schema)
df.printSchema()
df.show()
출력 결과:
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- department: string (nullable = true)
+-----+---+------------+
| name|age| department|
+-----+---+------------+
| John| 30| Sales|
|Alice| 35| Marketing|
| Bob| 40|Engineering|
|Sarah| 28| HR|
+-----+---+------------+
2.3 외부 데이터 소스에서 DataFrame 생성
CSV, JSON, Parquet 등 다양한 포맷의 파일에서 DataFrame을 생성할 수 있습니다:
Copy# CSV 파일에서 DataFrame 생성
df_csv = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("path/to/file.csv")
# JSON 파일에서 DataFrame 생성
df_json = spark.read.format("json") \
.load("path/to/file.json")
# Parquet 파일에서 DataFrame 생성
df_parquet = spark.read.format("parquet") \
.load("path/to/file.parquet")
3. DataFrame 기본 작업
3.1 데이터 조회 및 필터링
Copy# 특정 열 선택
df.select("name", "age").show()
# 조건에 따른 필터링
df.filter(df.age > 30).show()
# SQL 표현식을 사용한 필터링
df.filter("department = 'Sales'").show()
# 여러 조건 결합
from pyspark.sql.functions import col
df.filter((col("age") > 30) & (col("department") == "Engineering")).show()
3.2 데이터 변환
Copyfrom pyspark.sql.functions import col, expr, lit
# 새로운 열 추가
df_with_new_col = df.withColumn("salary", lit(50000))
# 열 값 변환
df_transformed = df.withColumn("age_plus_10", col("age") + 10)
# 열 이름 변경
df_renamed = df.withColumnRenamed("age", "employee_age")
# 표현식을 사용한 변환
df_expr = df.selectExpr("name", "age", "age + 10 as age_plus_10")
3.3 그룹화 및 집계
Copyfrom pyspark.sql.functions import avg, count, sum
# 부서별 평균 나이
df.groupBy("department").agg(avg("age").alias("avg_age")).show()
# 부서별 직원 수
df.groupBy("department").count().show()
# 여러 집계 함수 사용
result = df.groupBy("department").agg(
count("*").alias("employee_count"),
avg("age").alias("avg_age"),
sum("age").alias("total_age")
)
result.show()
3.4 정렬
Copy# 나이순 정렬 (기본: 오름차순)
df.orderBy("age").show()
# 나이 내림차순 정렬
df.orderBy(col("age").desc()).show()
# 여러 열로 정렬
df.orderBy(col("department"), col("age").desc()).show()
4. DataFrame 조인
여러 DataFrame을 조인하여 복잡한 데이터 분석을 수행할 수 있습니다:
Copy# 부서 정보가 있는 두 번째 DataFrame 생성
department_data = [
("Sales", "New York", "John Smith"),
("Marketing", "San Francisco", "Lisa Brown"),
("Engineering", "Seattle", "Mike Johnson"),
("Finance", "Chicago", "Tom Wilson")
]
dept_columns = ["department", "location", "manager"]
df_dept = spark.createDataFrame(data=department_data, schema=dept_columns)
# 내부 조인 (Inner Join)
df_joined = df.join(df_dept, on="department", how="inner")
# 왼쪽 외부 조인 (Left Outer Join)
df_left_joined = df.join(df_dept, on="department", how="left")
# 오른쪽 외부 조인 (Right Outer Join)
df_right_joined = df.join(df_dept, on="department", how="right")
# 완전 외부 조인 (Full Outer Join)
df_full_joined = df.join(df_dept, on="department", how="full")
df_joined.show()
5. SQL 쿼리 실행
PySpark에서는 SQL 쿼리를 직접 실행할 수도 있습니다:
Copy# 임시 뷰 생성
df.createOrReplaceTempView("employees")
df_dept.createOrReplaceTempView("departments")
# SQL 쿼리 실행
result = spark.sql("""
SELECT e.name, e.age, d.location, d.manager
FROM employees e
JOIN departments d ON e.department = d.department
WHERE e.age > 30
ORDER BY e.age DESC
""")
result.show()
6. 데이터 저장
DataFrame을 다양한 형식으로 저장할 수 있습니다:
Copy# CSV로 저장
df.write.format("csv") \
.option("header", "true") \
.mode("overwrite") \
.save("path/to/output/csv")
# Parquet으로 저장
df.write.format("parquet") \
.mode("overwrite") \
.save("path/to/output/parquet")
# 테이블로 저장
df.write.saveAsTable("my_table")
7. DataFrame을 Pandas로 변환
분석이나 시각화를 위해 PySpark DataFrame을 Pandas DataFrame으로 변환할 수 있습니다:
Copy# PySpark DataFrame을 Pandas DataFrame으로 변환
pandas_df = df.toPandas()
# Pandas DataFrame 출력
print(pandas_df.head())
PySpark 성능 최적화 팁
-
적절한 파티션 수 사용: 파티션이 너무 많거나 적으면 성능이 저하될 수 있습니다.
Copy# 파티션 수 조정 df = df.repartition(10) -
캐싱 활용: 반복 작업에서 데이터를 캐싱하여 성능 향상
Copydf.cache() # 메모리에 데이터 캐싱 -
불필요한 셔플 최소화: 셔플 연산(예: groupBy, join)은 비용이 많이 드므로 최소화해야 합니다.
-
필요한 열만 선택: 필요한 열만 선택하여 메모리 사용량 감소
Copydf = df.select("name", "age") # 필요한 열만 선택
실제 예제: 간단한 데이터 분석
다음은 더 복잡한 실제 분석 예제입니다:
Copyfrom pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, count, round, desc
# SparkSession 생성
spark = SparkSession.builder \
.appName("판매 데이터 분석") \
.getOrCreate()
# 샘플 판매 데이터 생성
sales_data = [
("2023-01-01", "Product A", 10, 100.0),
("2023-01-01", "Product B", 5, 200.0),
("2023-01-02", "Product A", 15, 100.0),
("2023-01-02", "Product C", 8, 150.0),
("2023-01-03", "Product B", 7, 200.0),
("2023-01-03", "Product C", 10, 150.0),
("2023-01-04", "Product A", 20, 100.0),
("2023-01-04", "Product B", 3, 200.0)
]
schema = ["date", "product", "quantity", "unit_price"]
df_sales = spark.createDataFrame(data=sales_data, schema=schema)
# 판매 총액 계산
df_with_total = df_sales.withColumn("total_amount", col("quantity") * col("unit_price"))
# 제품별 판매 분석
product_analysis = df_with_total.groupBy("product") \
.agg(
sum("quantity").alias("total_quantity"),
round(sum("total_amount"), 2).alias("total_revenue"),
round(avg("unit_price"), 2).alias("avg_price")
) \
.orderBy(desc("total_revenue"))
# 일별 판매 분석
daily_analysis = df_with_total.groupBy("date") \
.agg(
count("product").alias("products_sold"),
sum("quantity").alias("total_quantity"),
round(sum("total_amount"), 2).alias("daily_revenue")
) \
.orderBy("date")
# 결과 출력
print("제품별 판매 분석:")
product_analysis.show()
print("일별 판매 분석:")
daily_analysis.show()
# SparkSession 종료
spark.stop()
결론
PySpark는 대용량 데이터 처리와 분석을 위한 강력한 도구입니다. 분산 컴퓨팅의 복잡성을 숨기면서 Python의 간결함과 사용 편의성을 제공합니다. 기본적인 DataFrame 조작부터 복잡한 분석, 머신러닝까지 다양한 작업을 수행할 수 있습니다.
이 글에서는 PySpark의 기본 개념과 간단한 사용법을 살펴보았습니다. PySpark에 더 익숙해지면 스트리밍 데이터 처리, 고급 머신러닝 알고리즘, 그래프 분석 등 더 복잡한 작업도 수행할 수 있습니다. 빅데이터 분석과 처리에서 PySpark는 매우 유용한 도구이며, 데이터 과학자와 엔지니어에게 강력한 기능을 제공합니다.
참고 자료
