apache spark
1.아파치 스파크(Apache Spark)와 데이터브릭스(Databricks)의 비교: 빅데이터 처리의 두 가지 솔루션

빅데이터의 시대에 효율적인 데이터 처리와 분석은 기업의 성공에 필수 요소가 되었습니다. 이러한 환경에서 아파치 스파크(Apache Spark)와 데이터브릭스(Databricks)는 빅데이터 처리를 위한 강력한 도구로 자리잡고 있습니다. 이 글에서는 아파치 스파크와 데이
2.아파치 스파크(Apache Spark)란? - 빅데이터 처리의 핵심 엔진

아파치 스파크(Apache Spark)는 대규모 데이터 세트를 위한 통합 분석 엔진으로, 빅데이터 처리를 위한 오픈소스 분산 처리 플랫폼입니다. SQL, 스트리밍, 머신러닝 및 그래프 처리를 위한 기본 제공 모듈이 있어 다양한 데이터 처리 작업을 수행할 수 있습니다.
3.아파치 스파크(Apache Spark) 설치

안녕하세요! 오늘은 빅데이터 처리를 위한 강력한 엔진인 아파치 스파크(Apache Spark)의 설치 방법에 대해 알아보겠습니다. 스파크는 대용량 데이터 처리, 머신러닝, 실시간 스트리밍 등 다양한 분야에서 활용되고 있는 필수 도구입니다.스파크를 설치하기 전에 필요한
4.PySpark란, 간단한 사용법

PySpark는 Apache Spark를 위한 Python API입니다. Apache Spark는 빅데이터 처리를 위한 강력한 오픈소스 분산 컴퓨팅 시스템으로, 원래 Scala 언어로 작성되었습니다. PySpark는 Python 프로그래머들이 Spark의 강력한 기능을
5.Apache Spark AQE(Adaptive Query Execution)란?
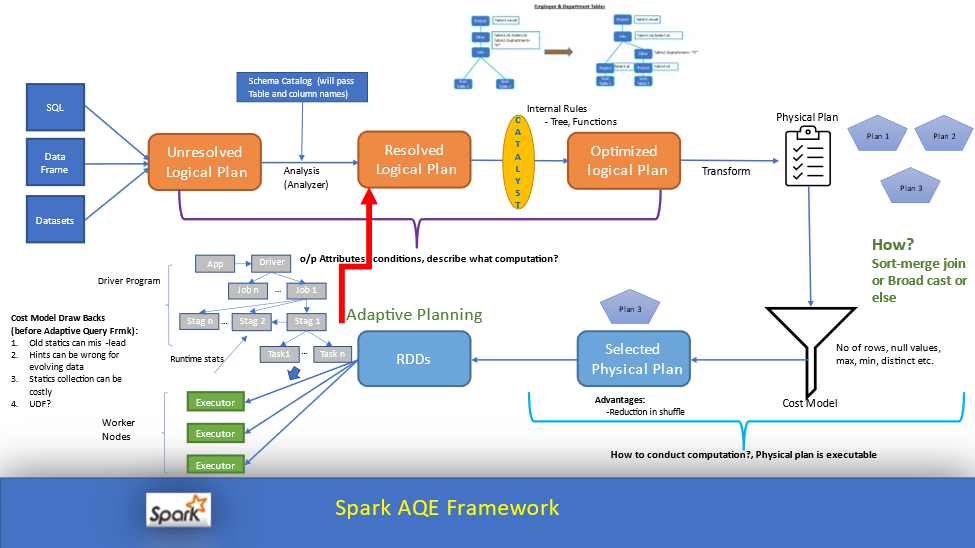
Adaptive Query Execution(AQE)는 Apache Spark 3.0에서 도입된 동적 쿼리 최적화 프레임워크입니다. AQE는 런타임 시 발생하는 다양한 통계치를 수집하여, 기존의 정적 최적화가 가진 한계점을 극복하고 쿼리 성능을 향상시키는 기능입니다.