마지막 업데이트: 2026년 3월 | 대상: 데이터 엔지니어, 플랫폼 엔지니어, Spark 성능 튜너
대용량 데이터 조인은 Spark/Databricks 워크로드에서 가장 비싼 연산 중 하나다. 수백만 행을 가진 두 테이블을 조인할 때 기본 전략(SortMergeJoin)은 네트워크 셔플을 동반하며, 잘못 설정하면 전체 잡 시간의 80% 이상을 셔플에 소비하기도 한다. 이 문제의 가장 강력한 해결책이 Broadcast Hash Join(BHJ)이다.
1. Broadcast Join이란?
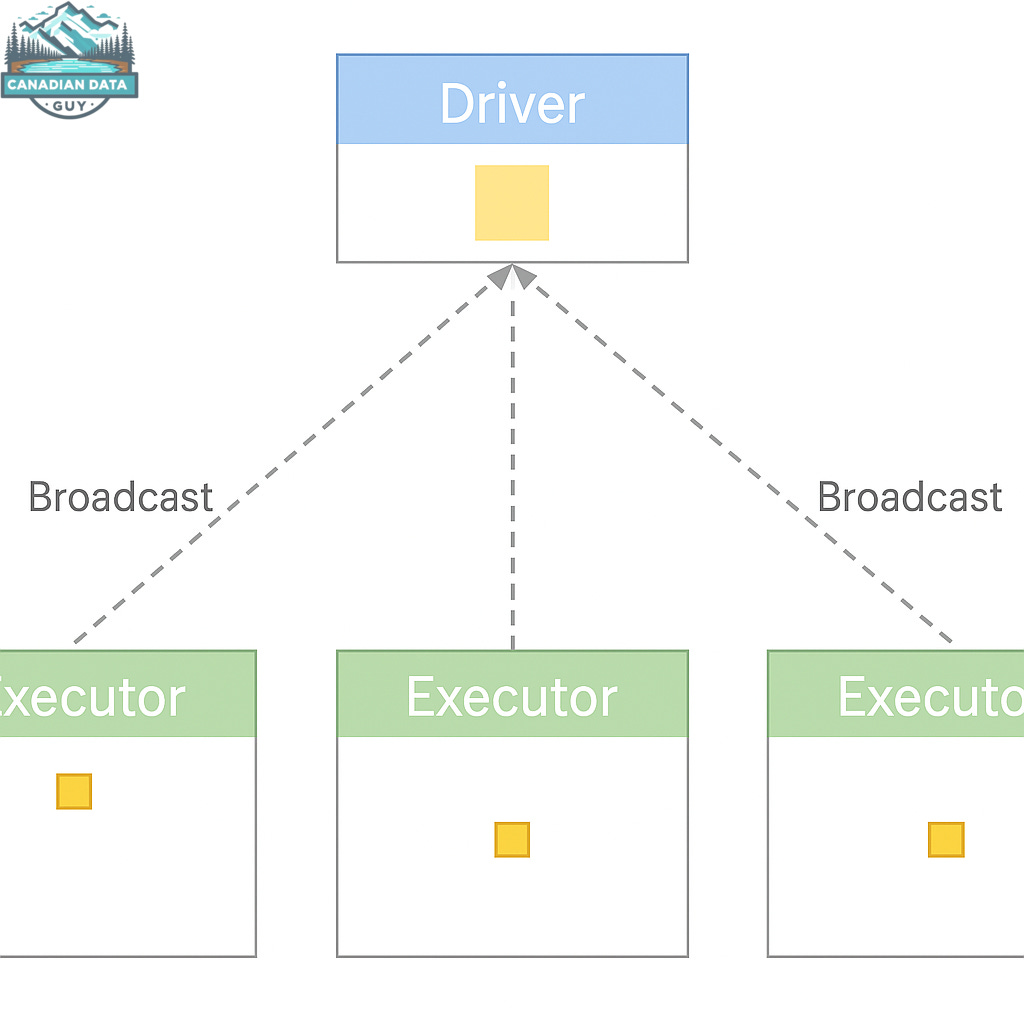
Broadcast Join은 두 테이블 중 작은 쪽을 Driver가 수집(collect)한 뒤 모든 Executor에 복제(broadcast)하고, 각 Executor가 로컬에서 해시 매핑으로 조인하는 전략이다. 셔플이 전혀 발생하지 않기 때문에 작은 테이블 조인에서 SortMergeJoin 대비 극적인 성능 차이를 만들어낸다.
위 다이어그램에서 Driver는 작은 테이블을 메모리에 올린 뒤 점선 화살표(Broadcast)를 통해 각 Executor 노드에 복사한다. 이후 각 Executor는 대용량 파티션을 로컬에서 해시 조인하므로 네트워크 셔플이 완전히 제거된다.
2. BroadcastHashJoin의 내부 동작
Broadcast Hash Join의 실행 흐름은 다음과 같다.
- Collect (Driver): 작은 테이블 전체를 Driver 메모리로 가져온다.
- Build HashMap: 조인 키를 기준으로 해시맵을 생성한다.
- Broadcast: 직렬화된 해시맵을 모든 Executor에 전송한다.
- Probe (Executor): 각 Executor는 큰 테이블의 파티션을 순회하면서 로컬 해시맵과 매칭한다.
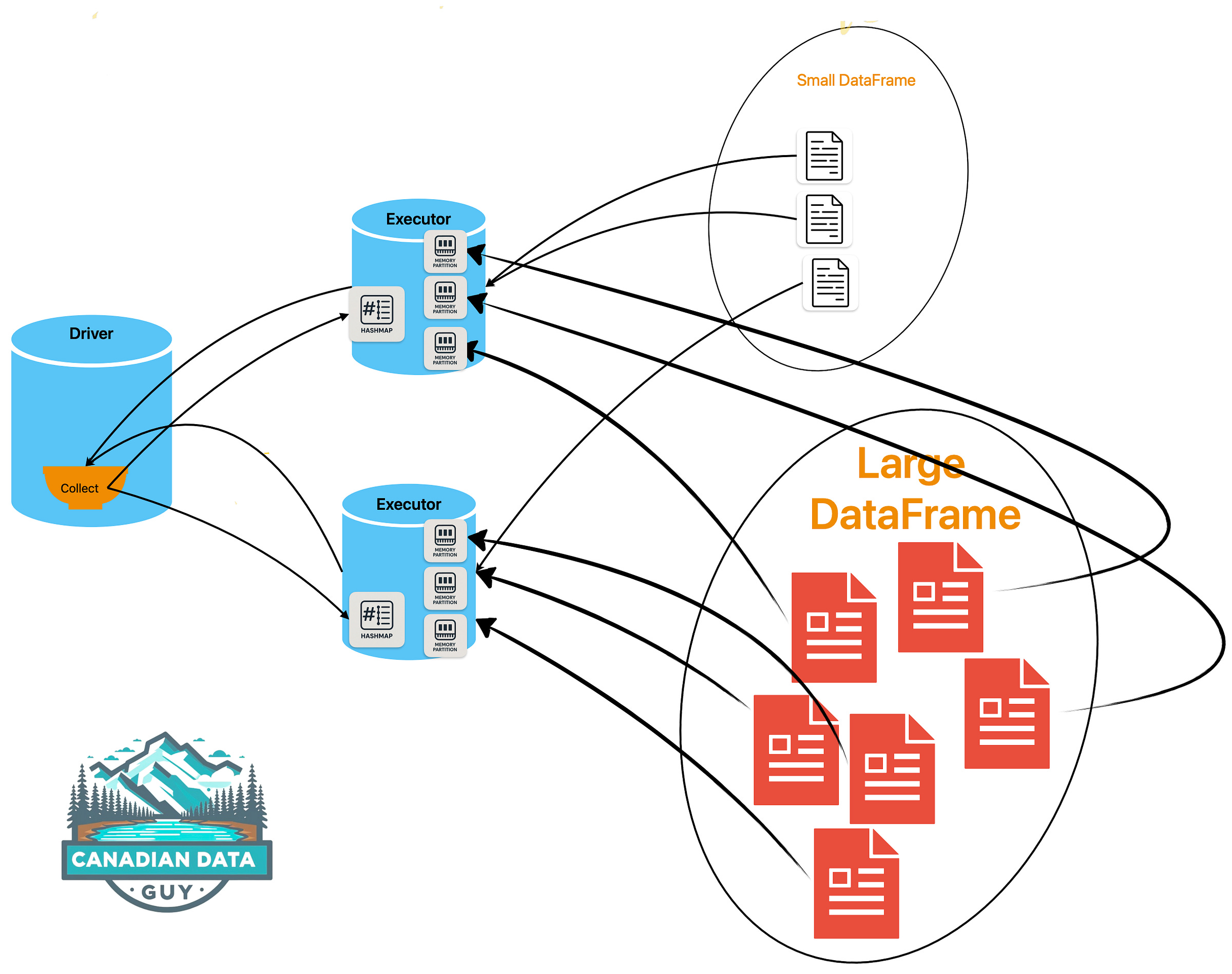
Small DataFrame(흰색 문서)은 Driver가 수집하여 각 Executor의 HashMap으로 내보낸다. Large DataFrame(빨간 문서)은 셔플 없이 해당 Executor에서 로컬로 Probe된다.
3. Databricks의 Adaptive Query Execution(AQE)과 동적 브로드캐스트
Spark 3.x / Databricks Runtime 8.x 이상에서는 AQE(Adaptive Query Execution)가 기본 활성화되어 있다. AQE의 핵심 기능 중 하나가 런타임에 SortMergeJoin을 BroadcastHashJoin으로 동적 변환하는 것이다.
AQE가 동적으로 조인 전략을 변경하는 방법
쿼리 플래닝 시점에는 테이블 크기를 과대 추정해도, 실제 실행 도중 맵 단계가 완료되면 실제 파티션 크기 통계가 수집된다. 이 통계를 바탕으로 작은 쪽이 브로드캐스트 임계값(autoBroadcastJoinThreshold) 이하라고 판단되면 자동으로 전략을 전환한다.
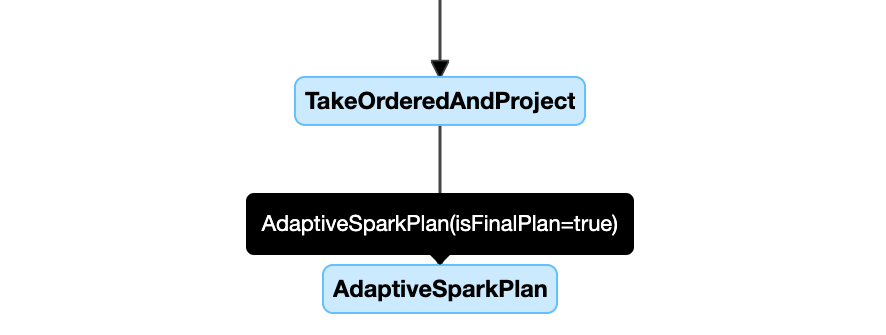
AQE는 각 Stage가 완료될 때마다 실제 통계를 수집하고 후속 Stage의 실행 계획을 재최적화한다.
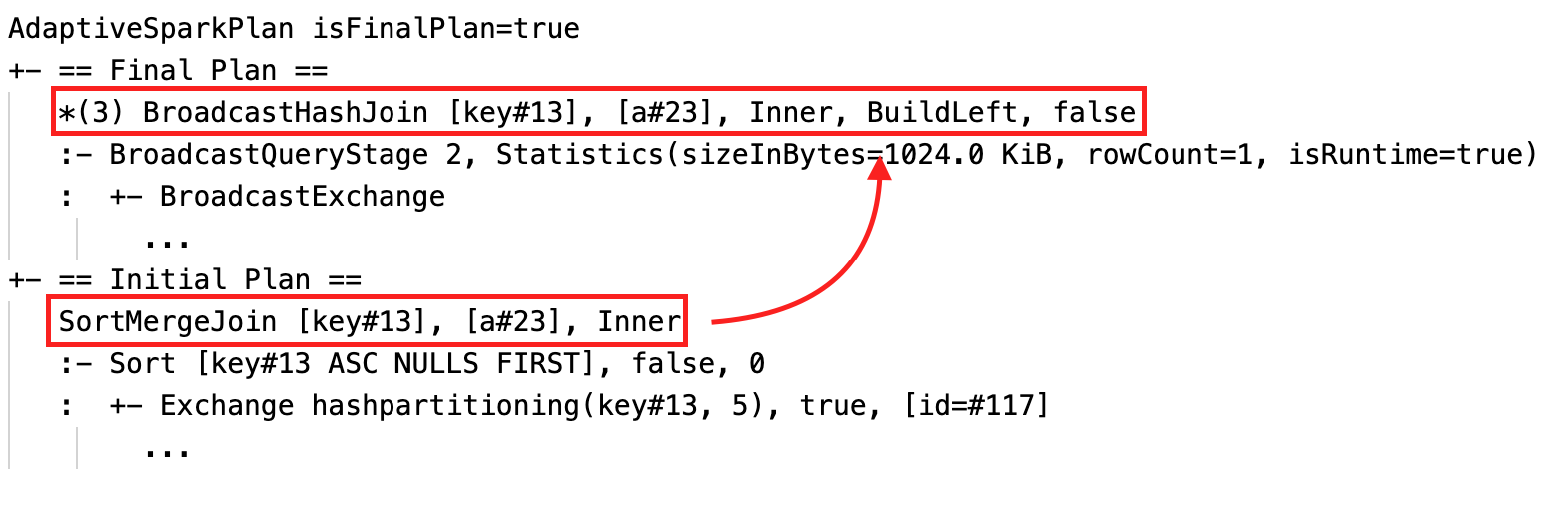
Plan 단계에서는 SortMergeJoin(SMJ)으로 계획되었던 조인이, 실제 데이터 크기 확인 후 BroadcastHashJoin(BHJ)으로 변환되는 모습을 볼 수 있다.
4. 핵심 설정 파라미터
4-1. 브로드캐스트 임계값
-- 기본값: 10MB. 이 크기 이하의 테이블은 자동으로 브로드캐스트됨
SET spark.sql.autoBroadcastJoinThreshold = 10485760; -- 10MB
-- 브로드캐스트 비활성화 (-1로 설정)
SET spark.sql.autoBroadcastJoinThreshold = -1;Databricks에서는 일반적으로 100MB~200MB까지 상향해도 안정적으로 동작한다. Driver와 각 Executor가 충분한 메모리를 보유하고 있는지 먼저 확인하자.
4-2. AQE 활성화 확인
-- AQE는 Databricks Runtime 7.3 LTS 이상에서 기본 활성화
SET spark.sql.adaptive.enabled = true;
-- AQE의 동적 조인 변환 활성화
SET spark.sql.adaptive.localShuffleReader.enabled = true;4-3. 힌트(HINT)를 통한 명시적 지정
통계가 부정확하거나 임계값 조정이 어려운 상황에서는 SQL 힌트로 직접 강제할 수 있다.
-- SQL 힌트로 브로드캐스트 조인 강제
SELECT /*+ BROADCAST(small_table) */
l.*,
s.category_name
FROM large_orders l
JOIN small_categories s
ON l.category_id = s.id;# PySpark에서 broadcast() 함수 활용
from pyspark.sql.functions import broadcast
result = large_df.join(
broadcast(small_df),
on="category_id",
how="left"
)5. Skew Join과 Broadcast Join의 관계
데이터 스큐(skew)가 있는 경우 SortMergeJoin은 특정 파티션이 수십 배 느려지는 문제를 일으킨다. AQE는 이를 탐지해 스큐 파티션을 자동으로 분할하고, 상대 테이블의 해당 파티션을 부분 브로드캐스트하는 방식으로 처리한다.
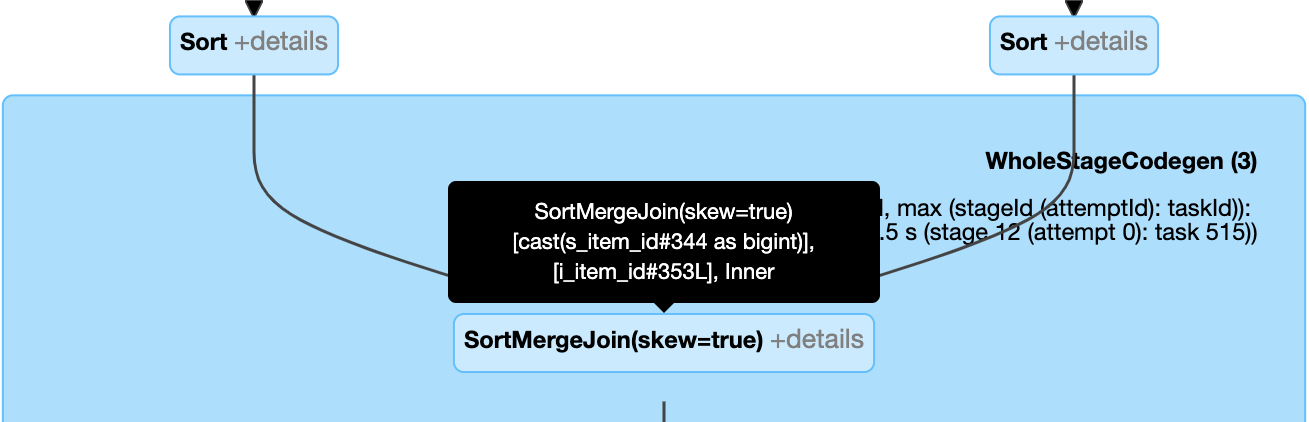
AQE가 스큐를 감지하면 SortMergeJoin(skew=true)로 표시하고, 스큐 파티션을 여러 서브 파티션으로 분할하여 분산 처리한다. 이 경우에도 Broadcast는 내부적으로 활용된다.
스큐 조인 최적화는 아래 설정으로 튜닝할 수 있다.
-- 스큐 파티션 탐지 임계값 (기본: 256MB)
SET spark.sql.adaptive.skewJoin.skewedPartitionFactor = 5;
SET spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes = 268435456;6. 성능 비교: 조인 전략별 특성 요약
| 조인 전략 | 셔플 여부 | 작은 테이블 크기 | 네트워크 비용 | 권장 시나리오 |
|---|---|---|---|---|
| BroadcastHashJoin | 없음 | < 수백 MB | 매우 낮음 | 작은 룩업 테이블 |
| SortMergeJoin | 있음 | 제한 없음 | 높음 | 두 테이블 모두 대용량 |
| ShuffleHashJoin | 있음 | 한쪽이 상대적으로 작음 | 중간 | 파티션 수 불균형 |
7. 주의사항 및 안티패턴
Driver OOM(메모리 부족): 브로드캐스트할 테이블이 실제로 크면 Driver가 OOM으로 죽는다. autoBroadcastJoinThreshold를 무조건 크게 올리기보다 실제 테이블 크기를 먼저 측정하자.
# 브로드캐스트 전 테이블 크기 확인
df_small.cache()
df_small.count() # 캐시 강제 실행
print(df_small._jdf.queryExecution().analyzed().stats().sizeInBytes())중첩 브로드캐스트 남용: 여러 조인이 연속될 때 모든 서브쿼리에 broadcast() 힌트를 사용하면 Driver 메모리를 중복 소비한다. 힌트는 명확히 작은 테이블에만 적용한다.
통계 미갱신: Delta 테이블에서 ANALYZE TABLE 없이 AQE 자동 전환에만 의존하면 추정 오류가 발생할 수 있다.
-- 통계 수동 갱신
ANALYZE TABLE catalog.schema.small_table COMPUTE STATISTICS;8. 실전 모니터링: Spark UI로 확인하기
Broadcast Join이 실제로 적용되었는지 확인하려면 Spark UI → SQL/DataFrame → 해당 쿼리 → Physical Plan에서 BroadcastHashJoin 또는 BroadcastExchange 노드를 찾아야 한다. AQE 변환이 발생했다면 Plan 상단에 AdaptiveSparkPlan 래퍼가 표시된다.
System Tables를 활용하면 SQL로도 추적이 가능하다.
-- system.query.history에서 브로드캐스트 조인 관련 슬로우 쿼리 탐지
SELECT
statement_id,
executed_by,
ROUND(total_duration_ms / 1000.0, 1) AS duration_sec,
read_bytes,
statement_text
FROM system.query.history
WHERE start_time >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
AND total_duration_ms > 30000 -- 30초 이상 걸린 쿼리
AND statement_text LIKE '%JOIN%'
ORDER BY total_duration_ms DESC
LIMIT 20;마치며
Broadcast Join은 작은 테이블이 포함된 조인 워크로드에서 셔플을 완전히 제거하는 가장 확실한 방법이다. Databricks의 AQE는 이를 런타임에 자동으로 적용해주지만, 임계값 설정, 통계 갱신, Driver 메모리 계획을 함께 관리해야 안정적으로 동작한다. 대용량 파이프라인에서 조인 성능을 개선해야 한다면, 가장 먼저 Spark UI → Physical Plan을 열어 BroadcastHashJoin이 쓰이고 있는지 확인하는 습관을 들이자.
참고:
