마지막 업데이트: 2026년 3월 | 대상: 데이터 엔지니어, 플랫폼 엔지니어, 분석 엔지니어
UDF(User-Defined Function)는 Databricks에서 기본 제공 함수로 표현하기 어려운 비즈니스 로직을 직접 구현할 수 있는 강력한 도구다. 하지만 잘못 사용하면 전체 파이프라인의 성능을 수십 배 저하시키는 원인이 된다.
이 글에서는 UDF 종류별 동작 원리와 성능 특성을 이해하고, 어떤 상황에서 무엇을 선택해야 하는지 실무 관점에서 깊이 다룬다.
1. UDF를 쓰기 전에: 반드시 네이티브 함수부터 확인하라
Databricks 공식 권고: UDF는 내장 Spark 함수로 표현하기 어려운 로직에만 사용하라. 내장 함수는 분산 처리에 최적화되어 있고, Catalyst 옵티마이저가 실행 계획을 생성할 때 완전히 활용된다.
UDF가 정당한 이유 없이 남용되는 흔한 사례들:
# ❌ 이렇게 하지 마라 — 내장 함수로 충분
@udf(returnType=StringType())
def to_upper(s):
return s.upper()
# ✅ 이렇게 하라
from pyspark.sql.functions import upper
df.withColumn("name_upper", upper("name"))# ❌ UDF로 날짜 파싱
@udf(returnType=DateType())
def parse_date(s):
from datetime import datetime
return datetime.strptime(s, "%Y-%m-%d")
# ✅ 내장 함수 활용
from pyspark.sql.functions import to_date
df.withColumn("dt", to_date("date_str", "yyyy-MM-dd"))일반적으로 UDF가 진짜 필요한 경우는 데이터 암·복호화, 커스텀 해싱, 복잡한 JSON 파싱, 외부 라이브러리 연동, 특수한 비즈니스 규칙 같은 로직이다.
2. UDF 종류와 성능 계층 구조
Databricks는 다양한 UDF 유형을 제공하며, 종류에 따라 성능 차이가 극명하게 갈린다.
성능 (빠름 → 느림)
──────────────────────────────────────────────────────
① 내장 Spark 함수 / SQL 내장 함수 ← 항상 최우선
② SQL UDF (Unity Catalog) ← JVM 내 실행, Catalyst 통합
③ Scala UDF (unisolated) ← JVM 내 실행, 직렬화 없음
④ Scala UDF (isolated) ← JVM 경계, 메모리 효율↑
⑤ Pandas UDF (Arrow 기반) ← 배치 벡터화, 최대 100x↑
⑥ Python UDF (Arrow 최적화, DBR 14+)← Row-by-row지만 Arrow 직렬화
⑦ Python Scalar UDF (기본 Pickle) ← 가장 느림, 회피 권장
──────────────────────────────────────────────────────왜 이렇게 차이가 날까? — JVM ↔ Python 경계 문제
Spark은 JVM 위에서 동작한다. Python UDF를 실행할 때 Spark은 데이터를 JVM에서 Python 프로세스로 전달해야 하며, 이 과정에서 직렬화(serialization)가 발생한다.

기본 Python UDF는 각 행을 하나씩 Python Worker로 전송하고 결과를 받아온다. 수천만 행이 있다면 수천만 번의 직렬화/역직렬화가 발생한다.
3. Apache Arrow가 바꾼 것: Pandas UDF
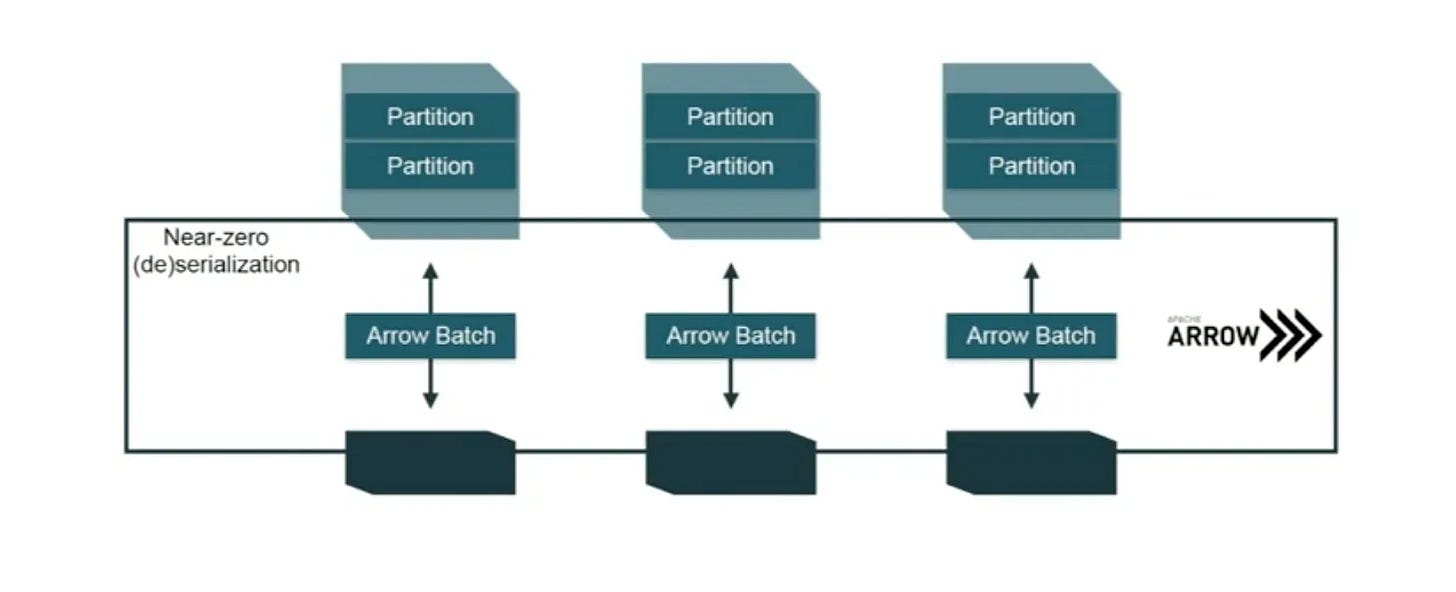
Pandas UDF(벡터화 UDF)는 Apache Arrow를 사용해 이 문제를 근본적으로 해결한다. Arrow의 핵심은 JVM과 Python이 동일한 메모리를 공유(zero-copy)할 수 있어 데이터를 복제하지 않고 전달할 수 있다는 점이다.

Row-by-row 직렬화 대신 컬럼 데이터를 Arrow Batch 단위로 묶어 전달한다. Python 코드는 개별 값이 아닌 전체 pd.Series를 받아 Pandas/NumPy의 벡터화된 연산을 그대로 적용할 수 있다.

결과적으로 Pandas UDF는 일반 Python UDF 대비 최대 100배 빠를 수 있다. 벤치마크에서 일반적으로 10~100배 개선이 관찰된다.
4. UDF 유형별 코드와 성능 특성
4-1. SQL UDF — 가장 간단하고 빠른 선택
SQL UDF는 Spark Catalyst 옵티마이저와 완전히 통합되고 Unity Catalog에 등록되어 재사용 가능하다. 단순 계산에는 가장 먼저 고려해야 한다.
-- Unity Catalog에 등록
CREATE OR REPLACE FUNCTION main.utils.mask_email(email STRING)
RETURNS STRING
RETURN CONCAT(
LEFT(email, 2),
REPEAT('*', LENGTH(SPLIT(email, '@')[0]) - 2),
'@',
SPLIT(email, '@')[1]
);
-- 사용
SELECT name, main.utils.mask_email(email) AS masked_email
FROM customers;4-2. Python Scalar UDF — 가장 흔하지만 가장 느린 선택
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
import hashlib
# 기본 Python UDF (Row-by-row, 느림)
@udf(returnType=StringType())
def sha256_hash(value: str) -> str:
if value is None:
return None
return hashlib.sha256(value.encode()).hexdigest()
df.withColumn("hashed_id", sha256_hash("user_id"))⚠️ 주의: 기본 Python UDF는 각 행마다 JVM ↔ Python 왕복이 발생한다. 대용량 데이터에서는 반드시 Pandas UDF로 대체를 검토하라.
4-3. Arrow 최적화 Python UDF (DBR 14.3+ / Spark 3.5)
Spark 3.5부터 기존 Python Scalar UDF에 Arrow 최적화를 적용할 수 있다. 코드 변경 없이 설정 하나로 ~1.6배 성능 향상이 가능하다.
# 방법 1: SparkSession 전체에 Arrow 최적화 적용
spark.conf.set("spark.sql.execution.pythonUDF.arrow.enabled", "true")
# 방법 2: UDF 개별 지정
@udf(returnType=StringType(), useArrow=True)
def sha256_hash(value: str) -> str:
if value is None:
return None
return hashlib.sha256(value.encode()).hexdigest()체이닝된 UDF가 여러 개인 경우 Arrow 최적화의 효과가 더 크다(~1.9배).
4-4. Pandas UDF (Series → Series) — 대용량 처리의 핵심
from pyspark.sql.functions import pandas_udf
import pandas as pd
import hashlib
# Pandas UDF — 배치 단위 처리, 최대 100x 빠름
@pandas_udf(StringType())
def sha256_hash_pandas(series: pd.Series) -> pd.Series:
return series.apply(
lambda v: hashlib.sha256(v.encode()).hexdigest() if v is not None else None
)
df.withColumn("hashed_id", sha256_hash_pandas("user_id"))# 여러 컬럼을 받는 Pandas UDF
@pandas_udf("double")
def bmi_calculator(weight: pd.Series, height: pd.Series) -> pd.Series:
return weight / (height ** 2)
df.withColumn("bmi", bmi_calculator("weight_kg", "height_m"))4-5. Iterator Pandas UDF — 모델 추론에 최적
모델 파일처럼 로딩 비용이 큰 리소스를 한 번만 초기화하고 여러 배치에 걸쳐 재사용할 수 있다. ML 배치 추론에서 매우 유용하다.
from typing import Iterator
import pandas as pd
from pyspark.sql.functions import pandas_udf
@pandas_udf("string")
def predict_batch(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
# 모델은 Iterator 시작 시 한 번만 로드
import mlflow
model = mlflow.sklearn.load_model("models:/my_model/Production")
for batch in iterator:
predictions = model.predict(batch.values.reshape(-1, 1))
yield pd.Series(predictions)
df.withColumn("prediction", predict_batch("feature"))💡 핵심 이점: 모델을 매 행마다 로드하는 것이 아니라 Executor당 한 번만 로드하므로, 대용량 모델 추론 성능이 극적으로 향상된다.
4-6. Scala UDF — JVM 내 최고 성능
Python 생태계가 필요 없고 성능이 최우선이라면 Scala UDF가 최선이다. JVM 내에서 직접 실행되므로 직렬화 오버헤드가 없다.
// Scala UDF 등록 후 PySpark에서 활용 가능
import org.apache.spark.sql.functions.udf
val sha256Udf = udf((value: String) => {
if (value == null) null
else java.security.MessageDigest.getInstance("SHA-256")
.digest(value.getBytes("UTF-8"))
.map("%02x".format(_)).mkString
})
spark.udf.register("sha256_scala", sha256Udf)# Python에서 등록된 Scala UDF 사용
df.createOrReplaceTempView("users")
spark.sql("SELECT sha256_scala(user_id) AS hashed_id FROM users")5. Pandas UDF 배치 크기 튜닝
Arrow 배치 크기는 성능과 메모리 사용량에 직접적인 영향을 미친다.
# 기본값: 배치당 10,000행
# 그룹이 크거나 메모리가 충분하면 늘려볼 것
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", "50000")
# OOM이 발생한다면 줄일 것
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", "5000")| 배치 크기 | 장점 | 단점 |
|---|---|---|
| 작게 (5,000↓) | 메모리 안정적 | 오버헤드 증가 |
| 기본 (10,000) | 균형 잡힌 기본값 | — |
| 크게 (50,000↑) | throughput 향상 | OOM 위험↑ |
6. 실무 성능 안티패턴과 해결책
안티패턴 1: UDF 내에서 외부 연결 매 행마다 생성
# ❌ 매 행마다 DB 연결 생성 — 극히 느리고 연결 고갈 위험
@udf(returnType=StringType())
def lookup_from_db(key: str) -> str:
conn = create_db_connection() # 매 행마다!
result = conn.query(f"SELECT val FROM t WHERE k='{key}'")
conn.close()
return result
# ✅ Iterator Pandas UDF로 연결 재사용
@pandas_udf("string")
def lookup_from_db_batch(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
conn = create_db_connection() # 배치 Iterator 당 1회
for batch in iterator:
keys = batch.tolist()
results = conn.query_batch(keys) # 벌크 쿼리
yield pd.Series(results)
conn.close()안티패턴 2: Null 처리 누락
# ❌ Null 처리 없으면 NullPointerException 또는 잘못된 결과
@pandas_udf("double")
def divide(a: pd.Series, b: pd.Series) -> pd.Series:
return a / b # b가 0이거나 None이면 오류
# ✅ Null 및 엣지케이스 명시적 처리
@pandas_udf("double")
def divide_safe(a: pd.Series, b: pd.Series) -> pd.Series:
result = a / b.replace(0, float("nan"))
return result # 0 나눗셈 → NaN으로 처리안티패턴 3: groupBy 후 applyInPandas로 전체 그룹 메모리 로드
# ⚠️ 그룹 전체가 하나의 Executor 메모리에 올라옴
# 그룹이 크면 OOM 발생
df.groupBy("category").applyInPandas(
my_func,
schema="category string, result double"
)
# ✅ 그룹 크기를 미리 파악하고 필요한 경우 salting으로 분산
df.groupBy("category", "sub_partition").applyInPandas(...)안티패턴 4: UDF 결과를 다시 UDF 입력으로 체이닝
# ❌ 체이닝된 Python UDF는 각 단계마다 직렬화 왕복
df = df.withColumn("step1", python_udf1("col"))
df = df.withColumn("step2", python_udf2("step1"))
df = df.withColumn("step3", python_udf3("step2"))
# ✅ 단일 Pandas UDF 또는 Arrow UDF로 통합
@pandas_udf("string")
def combined_transform(series: pd.Series) -> pd.Series:
return series.apply(step1).apply(step2).apply(step3)7. 상황별 UDF 선택 가이드
로직을 내장 Spark 함수로 표현 가능한가?
└─ YES → 내장 함수 사용 (끝)
└─ NO ─┐
SQL UDF로 표현 가능한가?
└─ YES → SQL UDF 사용 (Unity Catalog 등록 권장)
└─ NO ─┐
Scala/Java 팀이 있고 성능이 최우선인가?
└─ YES → Scala UDF
└─ NO ─┐
배치 단위 처리가 가능한가? (대부분 YES)
└─ YES → Pandas UDF (@pandas_udf)
모델 로딩 필요 시 → Iterator Pandas UDF
└─ NO → Arrow 최적화 Python UDF
(spark.sql.execution.pythonUDF.arrow.enabled=true)| 시나리오 | 권장 UDF | 이유 |
|---|---|---|
| 단순 문자열/수식 변환 | SQL UDF / 내장함수 | Catalyst 최적화 활용 |
| 데이터 암·복호화 | Pandas UDF | 벡터화 연산 |
| ML 배치 추론 | Iterator Pandas UDF | 모델 1회 로드 |
| 복잡한 집계 | Scala UDAF / Pandas UDAF | 성능 우선 |
| 외부 API 호출 | Iterator Pandas UDF | 연결 재사용 |
| 레거시 Python 로직 마이그레이션 | Arrow-enabled Python UDF | 최소 코드 변경 |
8. 성능 검증: UDF 프로파일링 방법
# Spark UI에서 Stage 단위로 UDF 병목 확인
# 또는 직접 시간 측정
import time
from pyspark.sql.functions import pandas_udf, udf
from pyspark.sql.types import DoubleType
n = 1_000_000
df = spark.range(n).withColumn("val", (col("id") % 100).cast("double"))
# Python UDF 측정
start = time.time()
df.withColumn("result", python_udf("val")).count()
print(f"Python UDF: {time.time() - start:.2f}s")
# Pandas UDF 측정
start = time.time()
df.withColumn("result", pandas_udf_func("val")).count()
print(f"Pandas UDF: {time.time() - start:.2f}s")
# 내장 함수 측정
from pyspark.sql.functions import sqrt
start = time.time()
df.withColumn("result", sqrt("val")).count()
print(f"Native: {time.time() - start:.2f}s")일반적인 벤치마크 결과 (백만 행 기준):
| UDF 유형 | 상대적 소요 시간 | 비고 |
|---|---|---|
| 내장 Spark 함수 | 1x (기준) | Catalyst 완전 최적화 |
| SQL UDF | ~1.5x | JVM 내 실행 |
| Scala UDF | ~2x | JVM 내, 직렬화 없음 |
| Pandas UDF | ~3~10x | Arrow 배치, 벡터화 |
| Arrow Python UDF | ~15x | 행 단위지만 Arrow 직렬화 |
| 기본 Python UDF | ~50~200x | Pickle 직렬화, 행 단위 |
마치며
UDF 성능 최적화는 단일 설정 하나로 해결되는 문제가 아니다. UDF 종류를 선택하는 것 자체가 아키텍처 결정이다.
핵심 원칙 세 가지를 기억하면 대부분의 함정을 피할 수 있다.
첫째, UDF보다 내장 함수가 항상 우선이다. Spark SQL 함수 목록을 충분히 숙지해두면 UDF 작성 빈도를 절반 이상 줄일 수 있다.
둘째, Python Scalar UDF가 필요하다면 Pandas UDF로 전환할 수 있는지 검토하라. 대부분의 변환은 Series 단위로 표현 가능하며, 10배 이상의 성능 차이가 날 수 있다.
셋째, 모델 추론처럼 초기화 비용이 큰 작업은 Iterator 패턴을 활용하라. 모델을 한 번만 로드하고 전체 파티션 데이터를 처리하는 것이 핵심이다.
참고 자료:
