VAE에 대해서 리뷰한다.
VAE는 계산하기 어려운 posterior distributions에서의 연속적인 latent variables로부터 효과적인 인퍼런스와 학습을 수행하기 위해서 개발되었다.
기존 오토인코더는 차원 축소의 목적, 즉 인코더를 위해서 개발된 것이고 VAE는 디코더로 새로운 데이터를 생성하기 위해 개발됐다.
AE는 z의 값이 특정 값이고 VAE는 설명하기 쉬운 (uniform, normal)같은 분포로 나타내는 것이 차이점이라고 보면 되겠다.
Introduction
SGVB(Stochastic Gradient Variational Bayes) 방식을 사용한다.
variational lower bound를 reparameterization하는 것으로, 계산하기 힘든 psterior distribution의 근사추론을 위해 사용되는 방식이다.
뒤의 수식에서 설명하겠다.
Independent and identically distributed한 데이터셋을 가정하고, 저자들은 AEVB(Auto-Encoding Variational Bayes)방식을 사용했다.
VAE 저자들이 인코더를 도입한 이유를 설명하는 듯한데, 뒤에서 소개하도록 하겠다.
Method
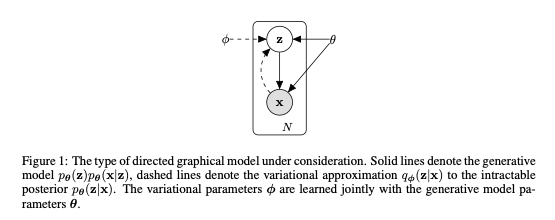
는 일반적인 generative model(실선)을 나타낸다.
하지만 실제 데이터셋의 posterior 를 알아내는 것은 intractable하다.
따라서 저자들은 (점선)을 도입했다.
이때 는 학습 가능한 파라미터들이다.
Problem scenario

위와 같은 데이터셋이 있다고 가정을 해본다.
이때 샘플 는 continuous 하거나 discrete할 수 있다.
데이터는 관측되지 않은 연속적인 랜덤 변수 를 포함한 과정에서 생성된다.
데이터가 생성되는 과정은,
(1) 값은 어떤 prior distribution 에서 생성된다.
(2) 는 어떤 conditional distribution 로부터 생성된다.
이때 prior 와 likelihood 는 parametric distribution인 로 나타낼 수 있다고 가정하고, 얘네들의 확률밀도함수는 와 로 미분 가능하다고 가정한다.
하지만 이때 와 는 우리는 알고있지 않다.
또한 posterior probability를 이용하는 단순한 가정은 하지 않는데, 이유는 아래 두가지와 같다.
- 를 구할 수 없다. 따라서 true psoterior density를 구할 수 없다.
- 큰 데이터셋에서는 Monte Carlo EM같은 데이터 포인트마다 샘플링을 해야하는 기법의 cost가 높다.
저자들은 에 대한 단순한 가정을 하지 않았기 때문에 두가지 경우에도 적용될 수 있다.
저자들은 true posterior 에 대한 근사치로 를 제안한다.
인코더로 를 사용해 데이터 포인트 가 생성될 수 있는 의 값이 존재할 수 있는 distribution을 생성한다.
디코더로 를 사용해 z가 주어졌을 때 x가 존재할 수 있는 분포를 생성한다.
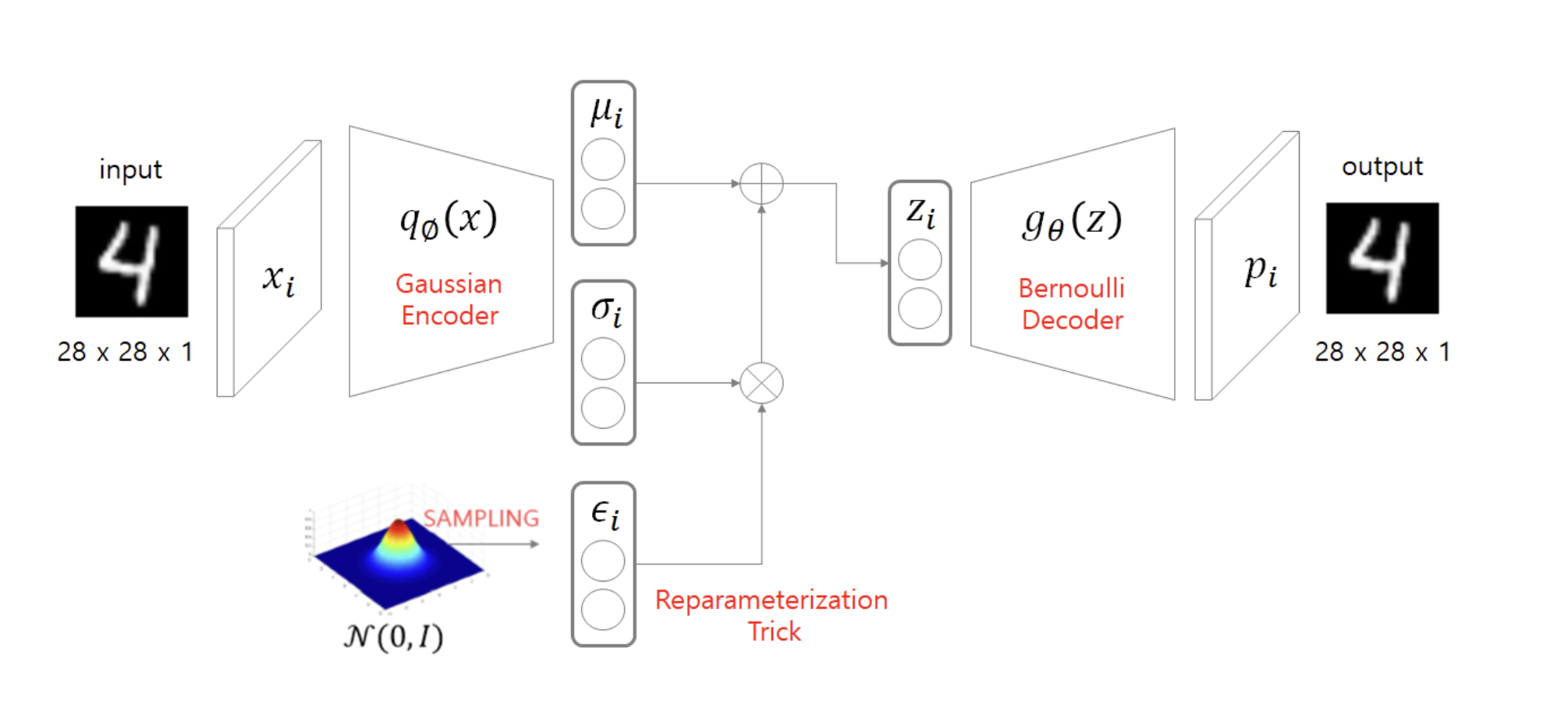
도식화한 그림은 위와 같다.
- input x로부터 를 거쳐 를 생성한다.
- 생성된 의 distribution에서 를 샘플링한다.
- 를 를 거쳐 를 생성해 아웃풋으로 도출한다.
Encoder
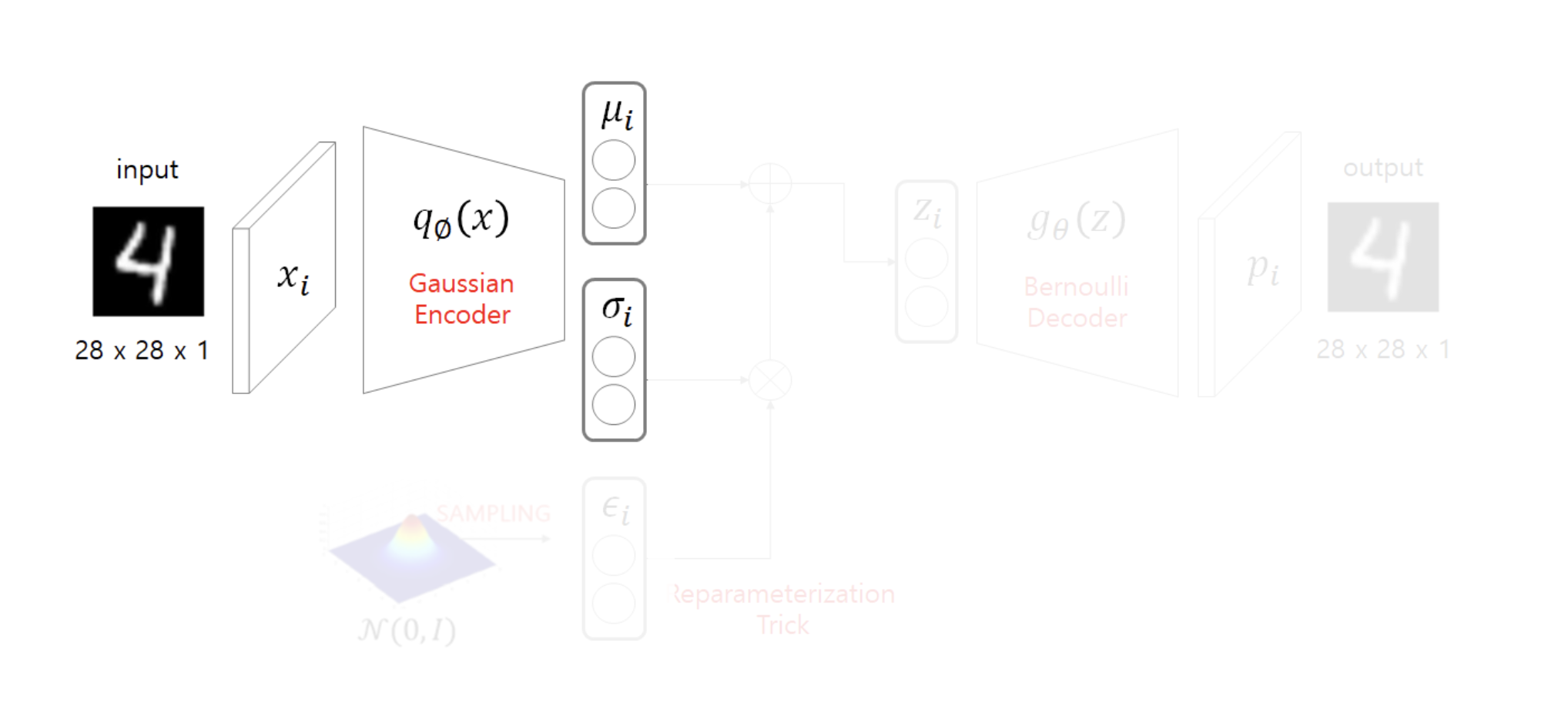
X라는 입력을 넣어 인코더를 통해 를 생성한다.
데이터의 특징을 X를 통해 추측한다고 볼 수 있다.
를 따르는 정규분포를 만들고, 그 분포 안에서 를 샘플링한다.
Reparameterization Trick (Sampling)
VAE는, 어떤 data의 true 분포가 있을 때, 그 분포에서 하나를 뽑아 기존 DB에 있지 않은 새로운 data를 생성하는 것이 목적이다.
따라서 데이터의 확률분포와 같은 분포에서 하나를 뽑는 sampling이 필요하게 된다.
를 따르는 정규분포에서, 를 그냥 샘플링하는 것은 역전파 진행 시 미분이 불가능하다.
따라서 reparameterization trick을 사용한다.
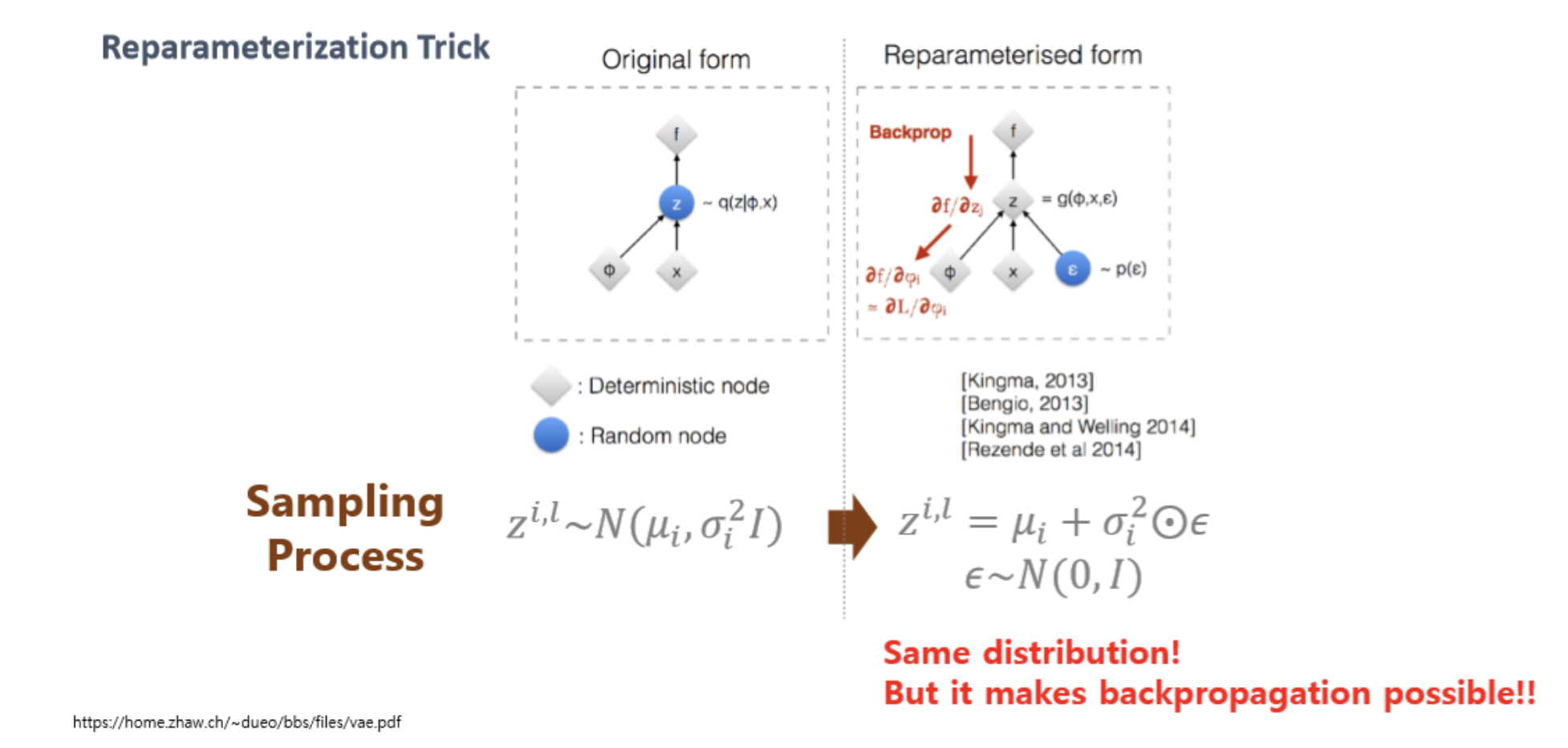
평균이 0이고, 표준편차가 1인 표준 정규분포에서, 를 더하고 를 곱하는 방식을 통해 z에 대한 수식을 정의할 수 있게 된다.
따라서 미분이 가능해진다.
Decoder
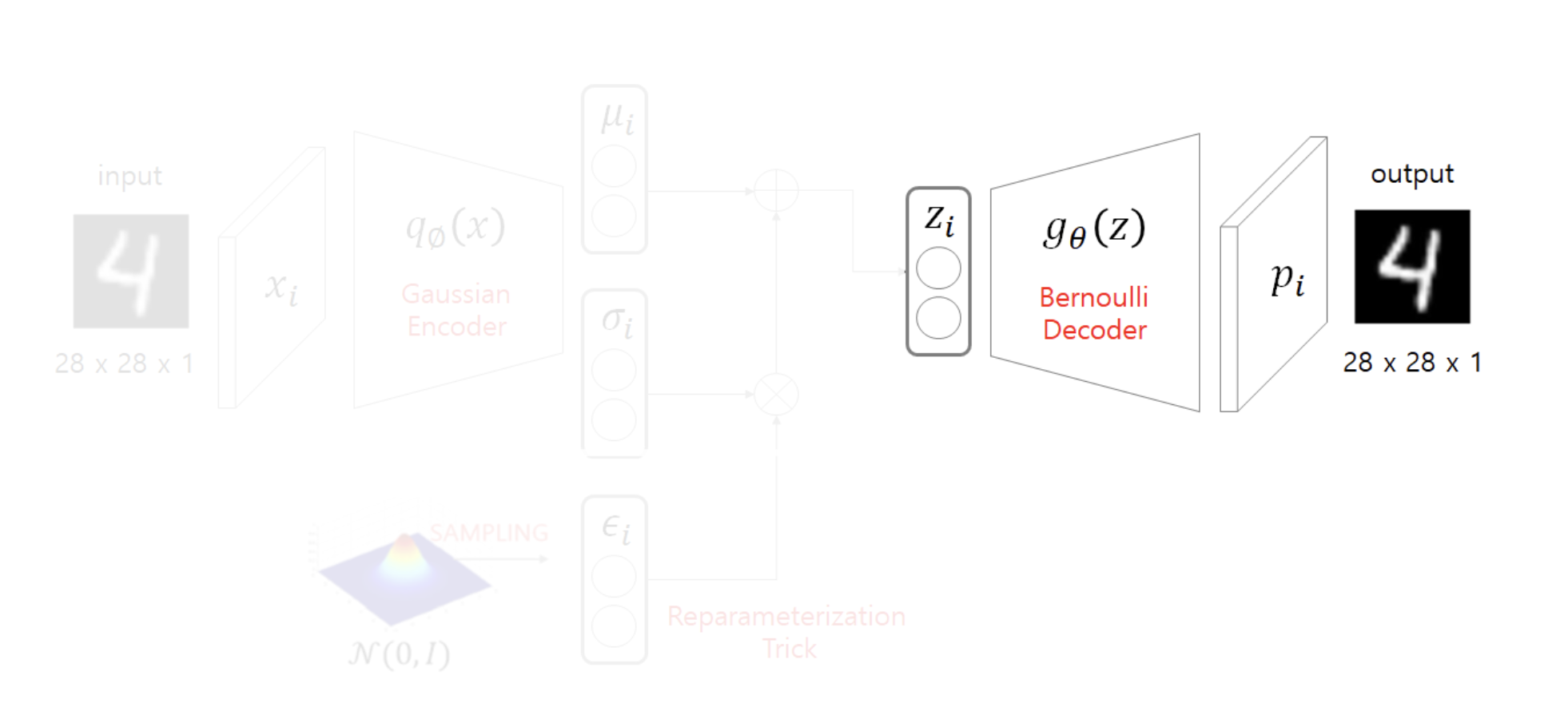
z를 디코더를 거쳐 아웃풋을 생성한다.
이때 x의 분포를 베르누이, 혹은 가우시안으로 가정할 수 있는데, 저자들은 베르누이로 가정했다.
따라서 뒤의 Loss Function을 정의할 때, Cross Entropy를 사용한다.
가우시안 분포로 가정했을 시에는 Mean Squared Error를 사용한다.
Loss Function

목적 함수는 두가지 수식의 합으로 나타난다.
1. Reconstruction Error: Generative model이기 때문에 X와 output(new X)의 error를 줄여야 한다. 이때 베르누이 분포로 가정을 했기 때문에 cross entropy를 구하게 된다.
2. Regularization: 를 정규분포에서 추출했기 때문에, 는 정규분포를 따른다는 가정이 들어가야 한다. 이를 최적화에 넣기 위해 해당 수식을 사용한다. 인코더를 통해 나온 정규분포를 따르는 와 의 KL Divergence를 구하는 식으로 도출된다.
https://judy-son.tistory.com/11
https://taeu.github.io/paper/deeplearning-paper-vae/
https://www.youtube.com/watch?v=GbCAwVVKaHY&t=716s
