[NLP] Attention : Neural Machine Translation by Jointly Learning Align and Translate
PaperReview
ABSTRACT
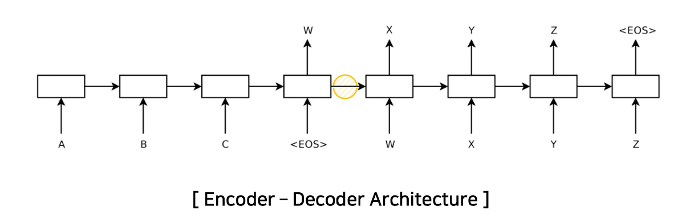

신경망을 이용한 기계 번역의 최근 모델들은 기본적으로 인코더 디코더 구조를 가졌다.
소스 문장을 인코더를 거쳐 고정된 길이 벡터로 변환하고,
이를 디코더의 인풋으로 사용해 번역을 하는 구조.
본 논문에서는, 고정된 길이의 벡터의 병목현상의 문제점을 가정하고, context vector 생성 시 Attention의 개념을 도입했다.
Target 단어를 예측할 때, 소스 문장과의 관련성을 자동적으로 서칭해 Attention Value를 계산하는 방식.
Introduction

병목현상이 문제점이 되는 이유는 학습에 사용된 corpus에서보다, 더 긴 문장에 대한 번역을 테스트할 때 나타나게 된다.
본 논문은 이를 해결하고자 어텐션 개념을 도입했고,
이를 통해 고정된 길이의 벡터를 만들지 않아도 된다는 장점을 주장하고 있다.
Background
Neural machine translation
신경망을 이용한 기계 번역은 기존의 phrase based model에서 발전했다.
또 인코더 디코더 구조를 가지고, end to end라는 효율적인 특징을 가지고 있다.
확률론적인 관점에서 번역은 소스 문장 x가 주어졌을 때, 타겟 문장 y에 대한 가장 높은 조건부 확률을 찾는 것과 같다.
즉, x가 주어졌을 때 y에 대한 조건부확률을 Maximize 하는 방향으로 학습된다고 보면 되겠다.
Nerral machine translation에서는 parallel한 training corpus로부터, 문장 쌍을 이용해 앞서 말한 과정을 수행한다.
번역 모델에서 이 조건부 확률이 잘 학습되었을 때 주어진 소스 문장에 대한 번역, 즉 타겟 문장은 조건부 확률을 최대화 하는 해당 문장의 쌍을 찾는 방식으로 생성된다.
RNN Encoder Decoder
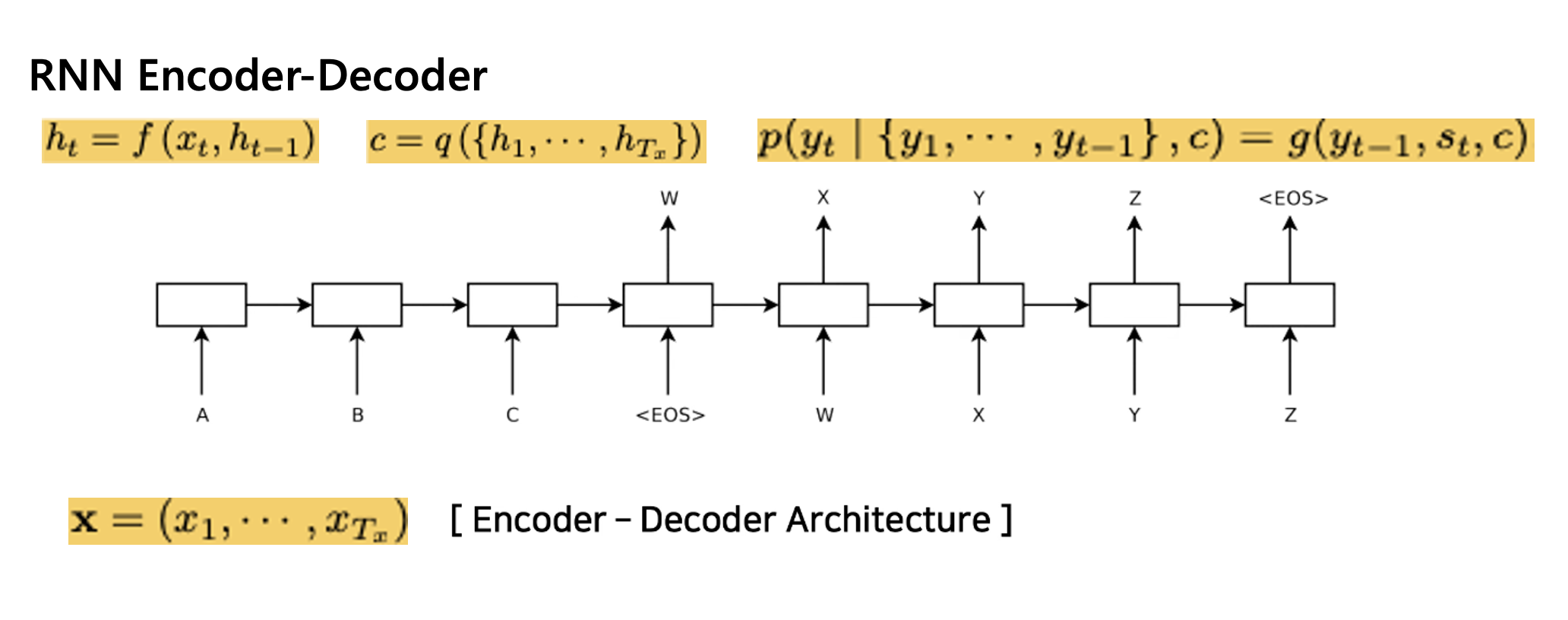
본 논문에서도 base가 되고, Neural machine translation에서 많이 사용되는 RNN Encoder-Decoder 구조에 대해 간략히 설명하겠다.
왼쪽의 인코더에서, 소스 문장이 인풋으로 들어가게 된다.
이때 소스 문장은 벡터 형태로 임베딩이 되어서 들어간다.
시점에서 RNN의 아웃풋인 hidden state는 이전 시점의 hidden state, 그리고 임베딩된 인풋 벡터를 통해 계산된다.
이런 과정을 거친 후 인코더의 마지막으로 나오는 hidden state 는, 소스 문장에 대한 정보 즉 문맥 정보를 가지는 고정된 길이의 context vector이다.
참고로 이때 사용되는 는 비선형 함수이다.
디코더는 이전 시점에서 예측한 타겟 단어 y hat과, 이 context vector의 joint probability를 최대화 하는 시점의 타겟 단어를 생성한다고 보면 되겠다.
즉 context vector , 이전 시점의 hidden state, 그리고 이전 시점의 hat의 연산을 통해 계산된다.
Method
그렇다면 해당 논문에서는 고정된 길이의 벡터를 생성하지 않기 위해 어떤 방식으로 어텐션이라는 메소드를 사용했는지 살펴보자.
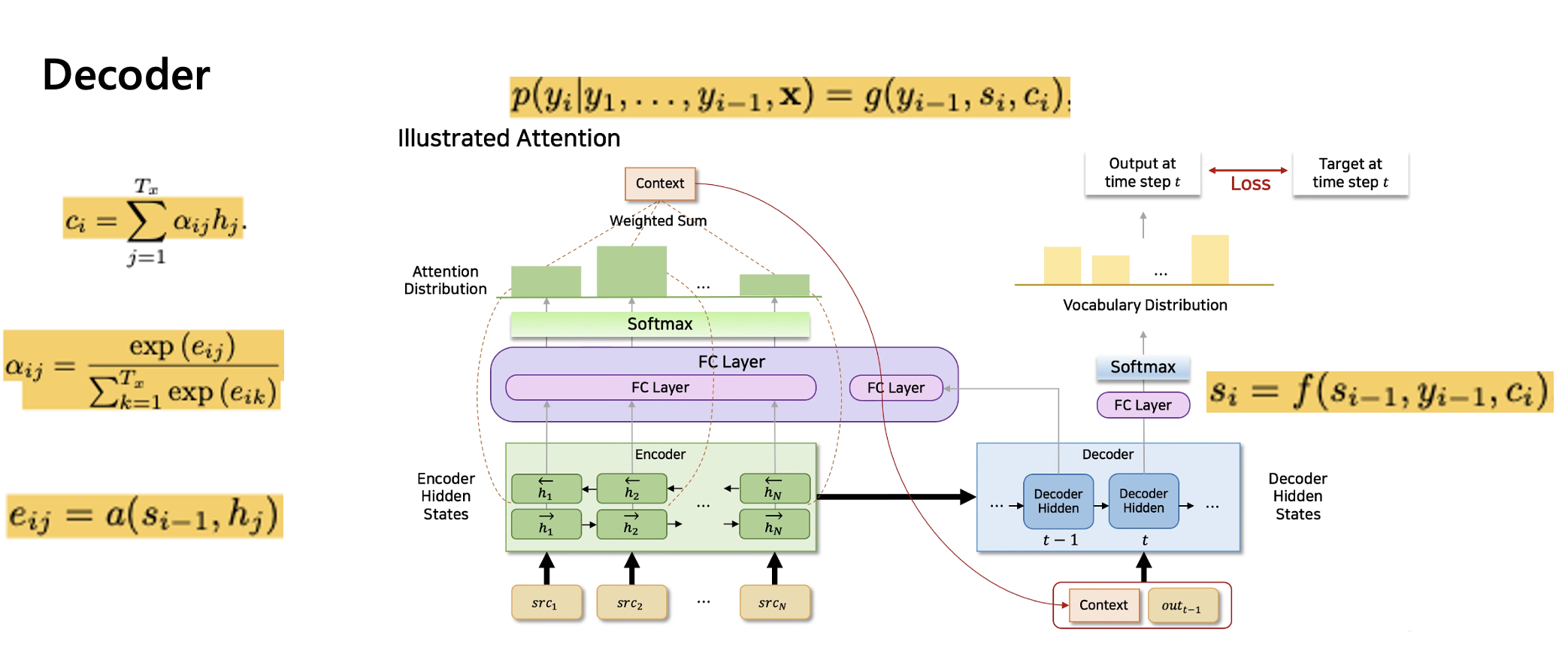
우선 디코더에서, 맨 위와 같은 식을 각 시점마다 조건부 확률 계산을 해준다.
이때 context vector 는, 위와 같은 하나의 고정된 길이의 벡터가 아닌, 타겟 단어 의 시점마다 개별적인 context 벡터를 사용한다.
Context vector 는 인코더의 인풋 문장에 대한 hidden state 값들과, 디코더가 예측한 타겟 단어와의 스코어를 통한 가중 합 계산으로 생성된다.
Transformer에서의 query, key, value 관점으로 본다면, 디코더 아웃풋에서 query, encoder hidden state들에서 key의 연산을 통해 결정된다고 이해하면 되겠다.
FC layer안에서 디코더가 예측한 타겟 단어와, encoder의 hidden state들과의 concat,
그리고 비선형 연산을 통해서, 디코더가 예측한 타겟 문장에 대한 hidden state들의 softmax값들의 가중합으로 계산이 된다.
이렇게 나온 context 벡터와, 이전 시점의 hidden state, hat 값들의 연산을 통해 디코더의 시점에 대한 예측값이 생성된다.
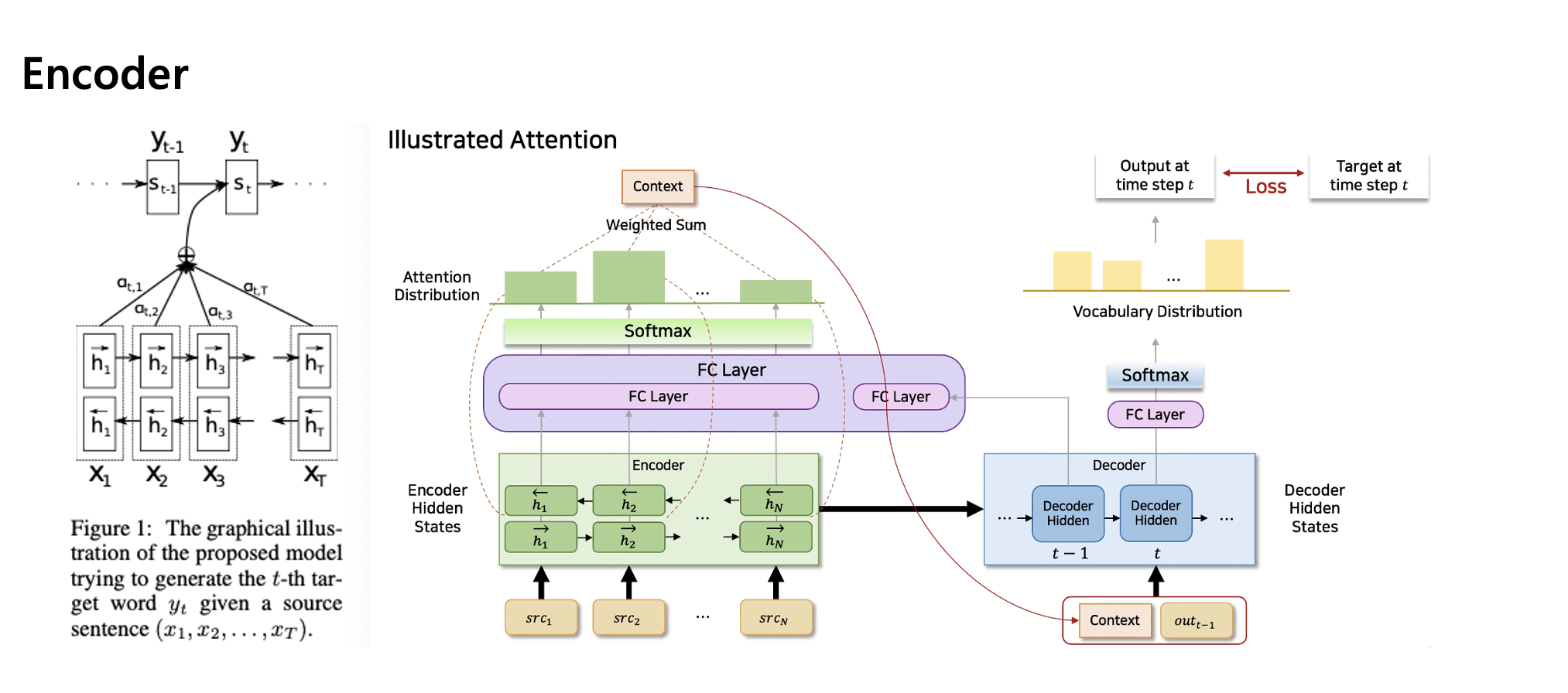
인코더 구조에서는, bi-directional하게 양방향으로 rnn을 사용했다.
이전 단어에서 정보를 뽑고, 또 이후에 나오는 단어들에서도 정보를 추출한다고 보면 되겠다.
각 방향에 대한 hidden state를 concat해서 사용했다.
Experiments
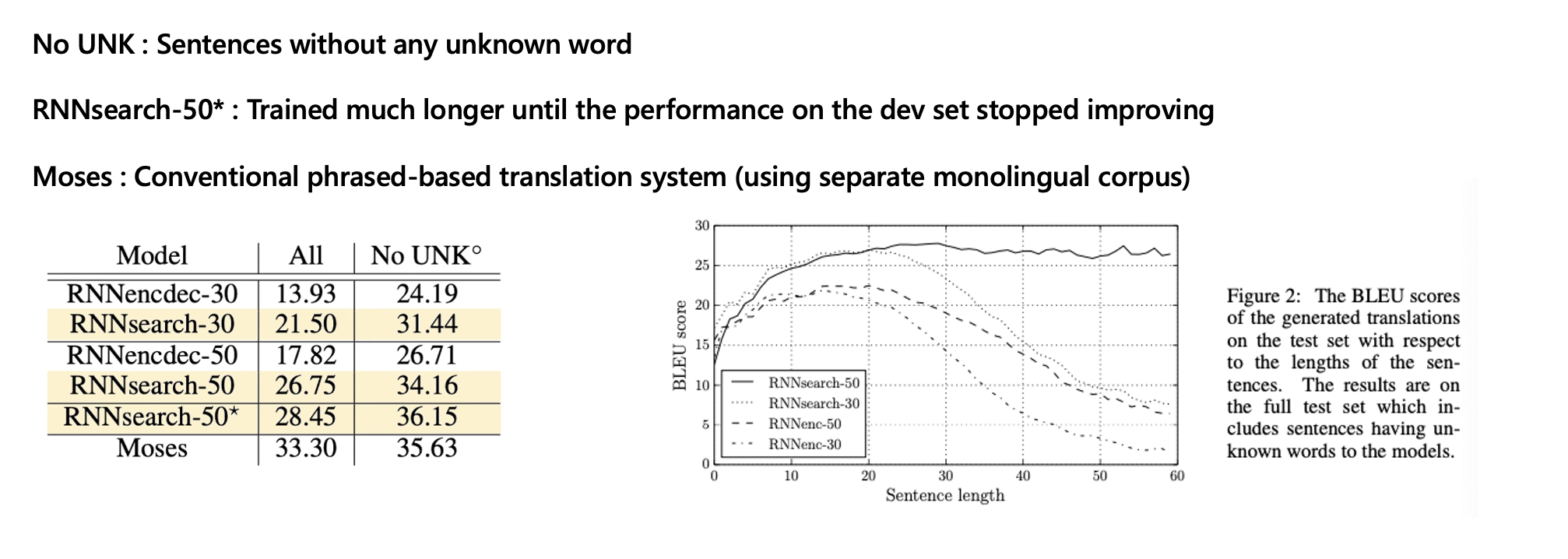
실험 부분을 간략하게 설명하자면,
영어 프랑스어 parallel corpus를 데이터로 사용했다.
RNN encoder decoder 모델이 베이스 모델이고, search라고 써있는 것이 논문에서 제안한 어텐션을 적용한 모델이다.
숫자는 max length, 즉 입력 단어들이 최대로 들어갈 수 있는 length라고 보면 되겠다.
Bleu score는 generated된 문장의 단어들이 정답 문장에 포함되는 정도를 계산해서 나오는 score값이라고 참고하자.
주목할 만한 점은 베이스 모델의 max length50보다, 어텐션을 적용한 max length30이 더 성능이 좋았다는 점.
Conclusion

기존의 basic encoder decoder 구조의 병목 현상을 해결하고자
타겟 문장과 인코더를 통과한 인풋 단어들의 annotation을 search해서 set 쌍을 찾는, 즉 어텐션을 적용했다.
따라서 고정된 길이의 벡터를 생성할 필요가 없어졌고, 이로 인해 발생하는 문제들을 개선할 수 있었다.\
reference
