ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
1. Background
최근 연구 동향
- NLP 분야는 Transformer based Algorithm 으로 굳어짐
- Transformer 구조는 주어진 모든 단어들 간의 관계를 조사함으로써, 문맥적 의미를 매우 잘 나타냄.
- RNN과는 달리 병렬화가 가능, CNN에 비해 더욱 긴 token sequence를 다룰 수 있음
Transformer 구조의 한계
- Transformer 구조 기반의 PLM은 위치 정보를 잘 나타내지 못함
- Absolute Position Encoding(절대 위치 인코딩): 토큰마다 다른 고정된 벡터값 합쳐주기
- Relative Position Encoding(상대 위치 인코딩): 인접 토큰 임베딩 벡터의 위치를 인덱스로 고정된 벡터 생성
- 대부분의 방법이 context에 위치정보를 단순 더해주기만 해서, 위치 정보를 잘 나태내지 못함
RoPE 제안
- token vector 의 절대 위치(Absolute Position)에 회전 행렬을 적용시켜 인코딩 수행(위치 정보 효율적으로 학습)
- 상대 위치(Relative Position) 또한 attention 과정 중 명시적으로 먹임(절대, 상대 위치 모두 적용)
- seuqence length에 유연. (e.g. 거리가 멀어질수록 토큰간 종속성 감소) (위치 정보 효율적 학습)
2. Base Knowledge
Absolute Position Encoding
- 절대 위치 인코딩: 입력 sequence의 각 token에 대해 고유한 고정된 위치 벡터를 할당
- 보통 sin, cos으로 벡터를 생성
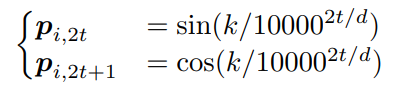
- i는 위치, k는 index, d는 transformer의 dim을 의미
- 결국, 특정 위치에 의해 position encoding vector P가 생성됨.
- 학습 가능한 파라미터로 고정되지 않은 벡터값을 할당하기도 함.
Relative Position Encoding
- 상대 위치 인코딩: token들 간 상대적 거리를 인코딩하여, 학습 가능한 파라미터로 사용함.
- 예시) "안녕", "나는", "현구야." => 1,2,3 이라는 ABP를 생성하였을 때, "안녕"을 기준으로 하였을 때, 0,1,2 라는 RPE가 생성됨. ("안녕"과 "현구야"의 거리 인덱스 차이는 2임)
- 본 논문에서는 상대 위치 인코딩과 관련된 다양한 접근 방식을 소개하였음
1. Basic Approach
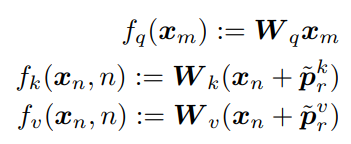
- q,k,v는 transformer의 query,key,value vector를 의미
- W는 가중치, Xm, Xn은 m,n번째 토큰의 임베딩 벡터
- Pm-n는 m-n의 차이값에 대한 토큰 position encoding 벡터
- f는 qkv생성에 사용되는 linear projection
- 즉, qkv w를 만들 때, k와 v에는 임베딩 벡터에 차이 벡터를 합친 벡터를 linear projection 함으로써, qkv를 생성함
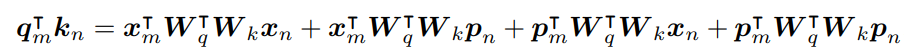
- Basic Approach를 전개한 결과. ABP를 적용하였음.
- 단어 m과 단어 n의 관계 + 단어 m과 n의 위치간 관계 + 위치 m과 단어 n 의 관계 + 위치 m과 위치 n의 관계 네가지 term으로 분해됨
2. Modified Approach

- Basic Approach의 전개 수식에서 수정하였음.
- Basic Approach에서는 ABP를 적용하였으나, Modified Approach에서는 RPE로 수정됨.
- 단어 m과 단어 n의 관계 + 단어 m과 위치m,위치n의 차이와의 관계 + 단어n의 bias + 위치m,위치n의 차이의 bias 네가지 term으로 수정하였음.
- u,t는 trainable한 파라미터.
3. Added Bias Approach
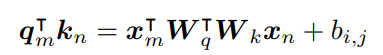
- Modified Approach에서 단어에 bias term을 주고, 위치의 차이에 bias term을 부과한 것을 합쳐서 하나의 bias term으로 통합하였음.
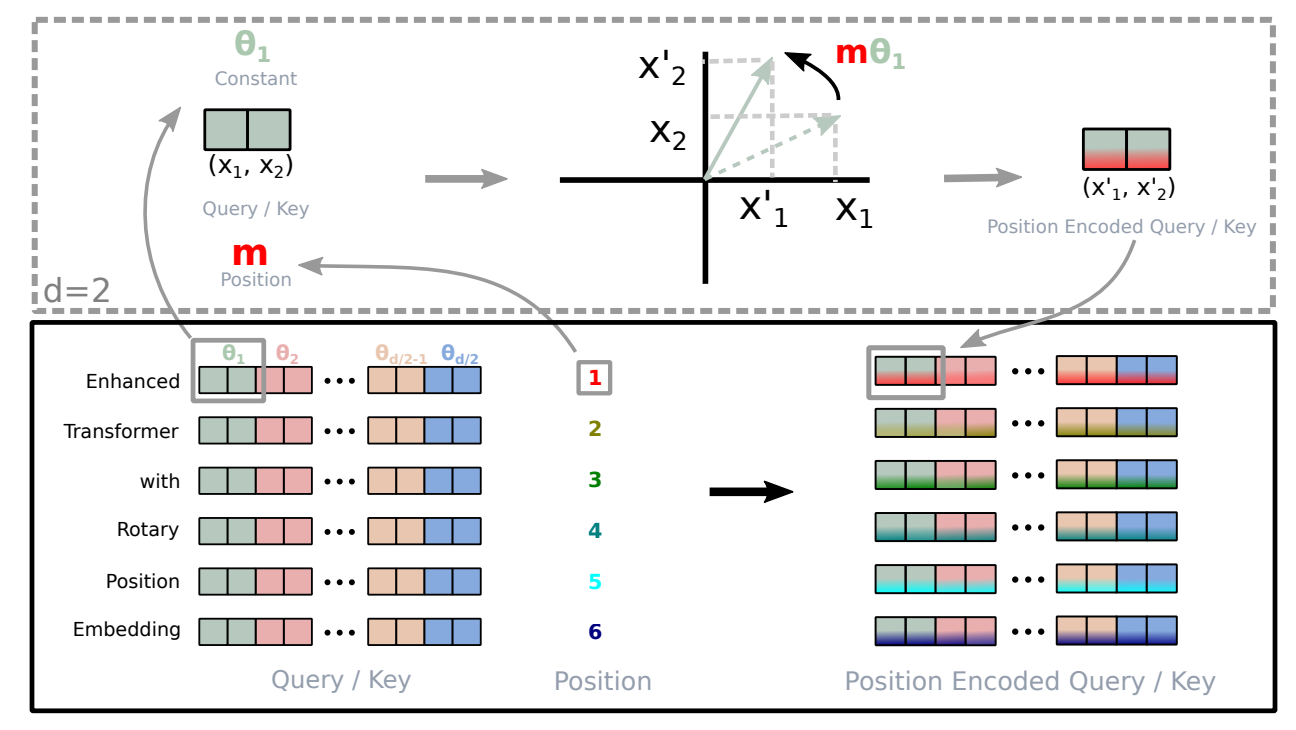
3. Method (RoPE)
- Absolute, Relative Position Encoding을 결합한 매우 효과적인 position encoding 방법
- 위치가 증가함에 따라, 토큰 종속성 감소 (Long-Term Decay) -> 토큰 간 거리가 멀어질수록 self attention에서의 내적값을 감소시켜줌
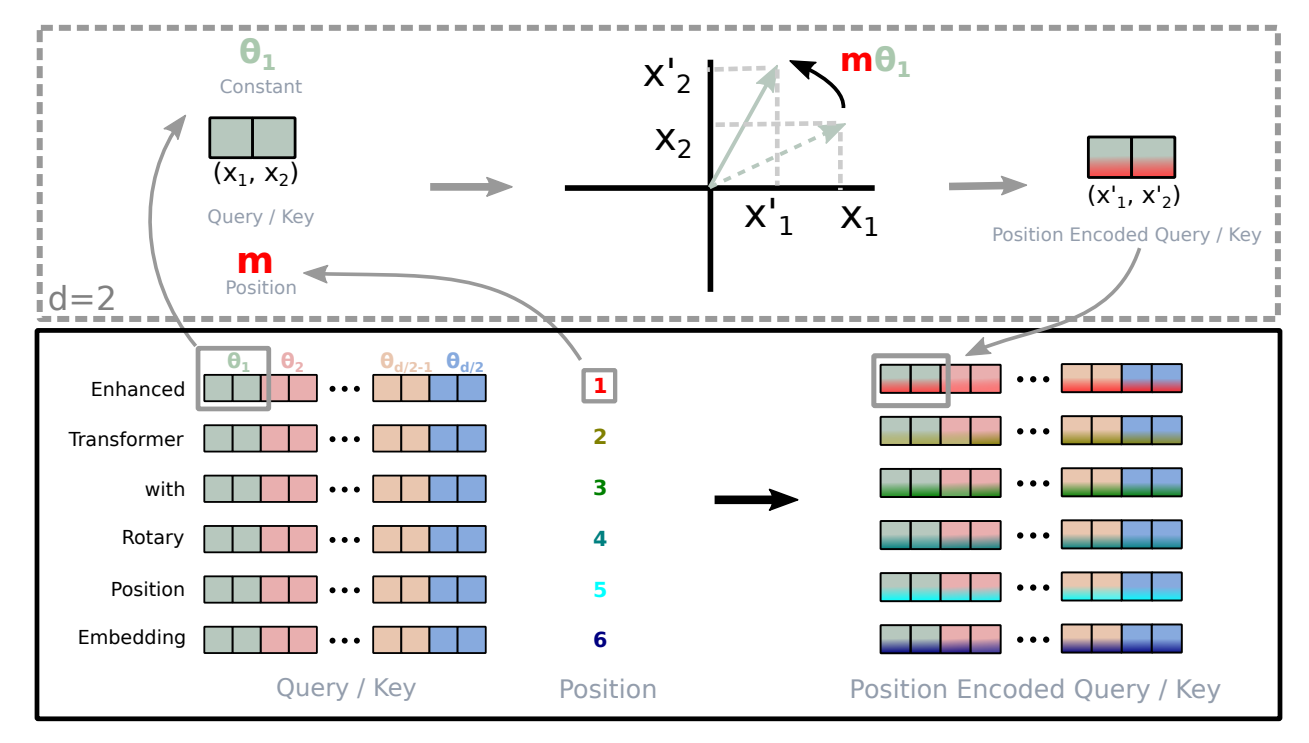
1. Absolute Position Encoding Vector 생성
- 해당 수식으로 Absolute Position Encoding Vector 생성
- 즉, 위치를 의미하는 고정 벡터 생성
2. Apply Affine Matrix
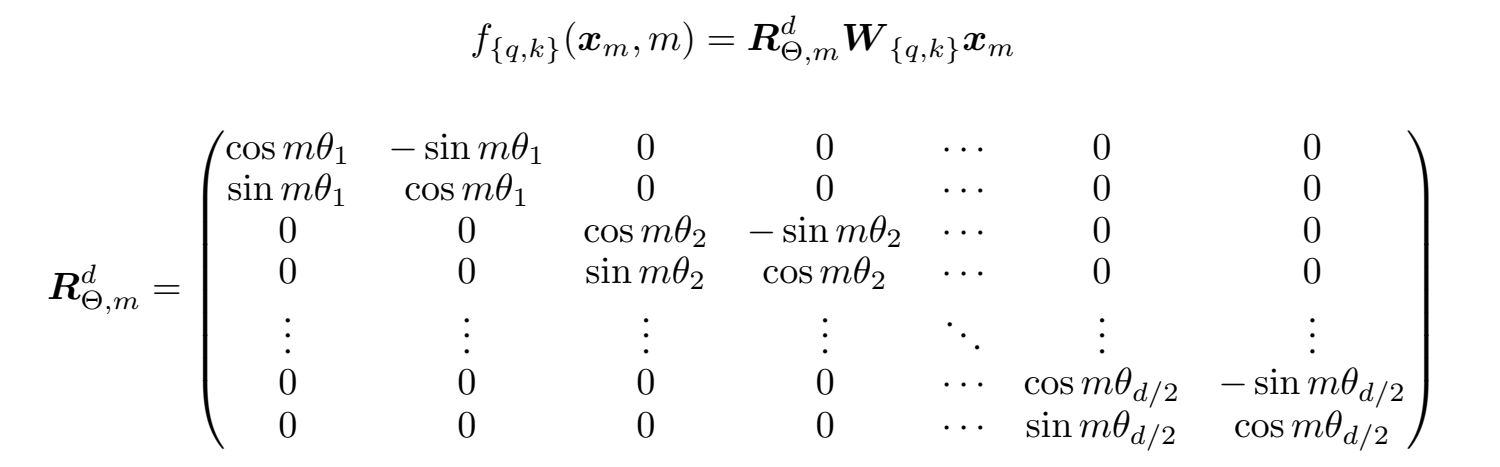
- 생성한 Absolute Position Encoding Vector에 위 행렬 R의 Affine 행렬을 곱해주어 Affine 변환을 수행
3. Apply QKT
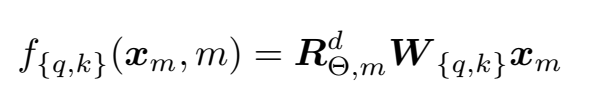
- 해당 수식처럼 변환된 위치 벡터를 q, k, v에 곱해줌
4. Integrate into Self-Attention

- 생성된 q,k,v로 attention 수행함.
Summary
- sin/cos로 절대위치벡터 생성
- affine matrix로 절대위치벡터를 회전시킴
- 변환된 벡터를 input에 각각 곱해서 linear projection 수행하여 최종 qkv를 생성
My Opinion
- 이전까지는 학습하는 컨셉의 파라미터를 적용하는 경우에, 일반 sin/cos 절대위치벡터를 학습시키는 것이 정론이였다.
- 하지만 RoPE에서는 절대위치벡터에 affine 변환을 수행함으로써, 이 qkv 벡터들이 학습을 하면서 절대위치벡터들도 조정이 일어나게 되어, 벡터들이 학습으로 인해 조정되는 각도를 학습하겠다는 의미를 갖게 된다.

고려대학교 인공지능학과 SLP Lab 석사과정생