Mitigating the Impact of Outlier Channels for Language Model Quantization with Activation Regularization

1. Background
LLM의 특징
- LLM은 이상 채널, 즉 다른 특성들보다 수십 배 더 높은 값을 갖는 특성들이 존재함. 이러한 이상 채널은 모델의 성능에 결정적인 역할을 함.
- 하지만 Quantization(특히 PTQ) 측면에서는 한계가 존재.
Quantization
Quantization 정의
- Higher precision bits(32bit Float Tensor) 를 lower precision bits로 매핑하는 것을 의미.
- 대표적인 Higher precision bits (32bit float tensor)는 부호(1bit), 지수부(8bit), 가수부(23bit)로 총 32bit를 사용함.
- Quantizing의 대상은 Weight, Activation임.
- Inference 과정만 Quantization의 대상임.
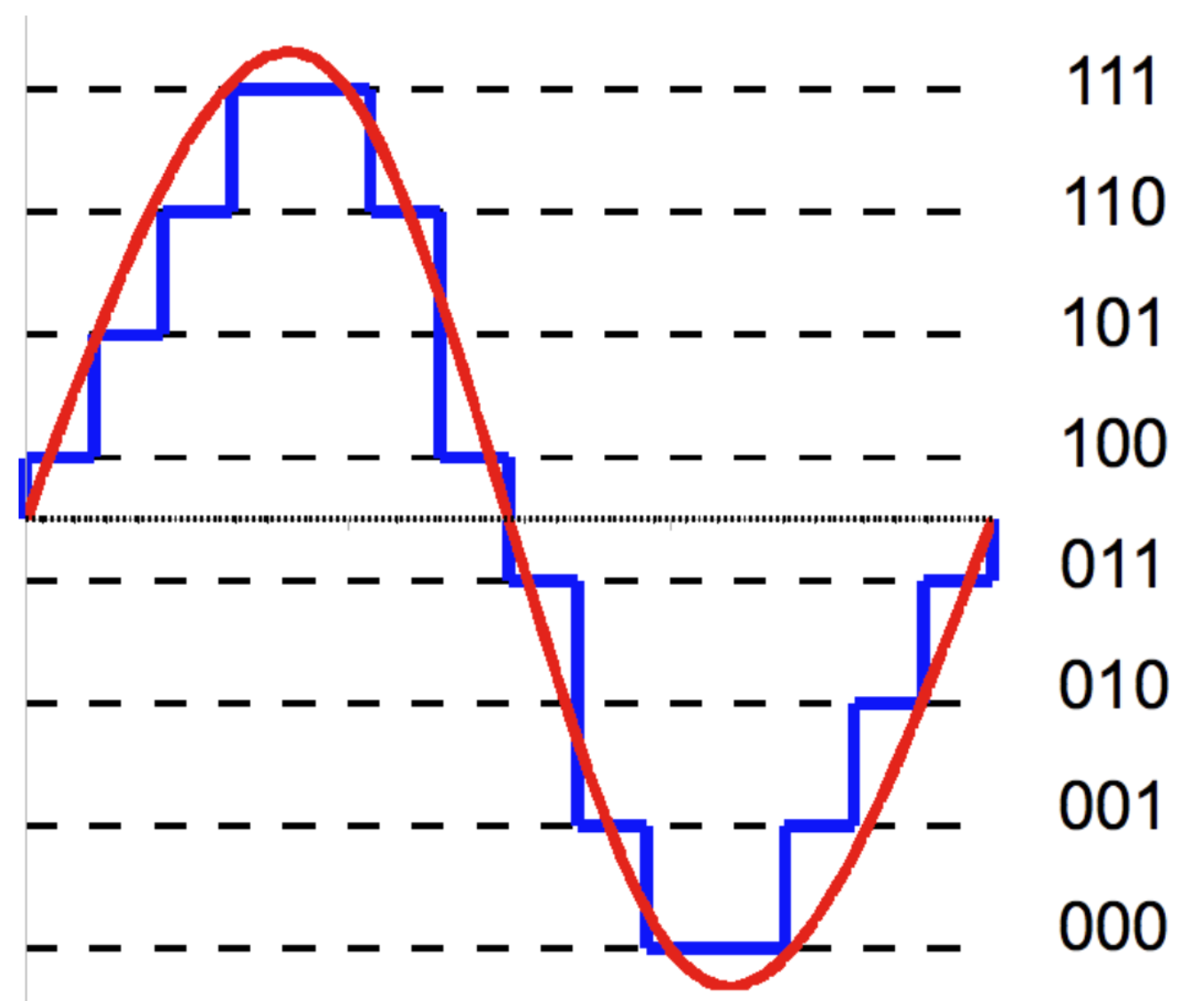
- 위 그림의 파란선은 4bit quantization 을 의미.
- 붉은선: 32bit float tensor
- 파란선: 4bit int tensor
Quantization 유형
-
1. Uniform vs NonUniform
-
NonUniform : input을 output으로 변환했을 때 output값들의 차이가 일정하지 않음.
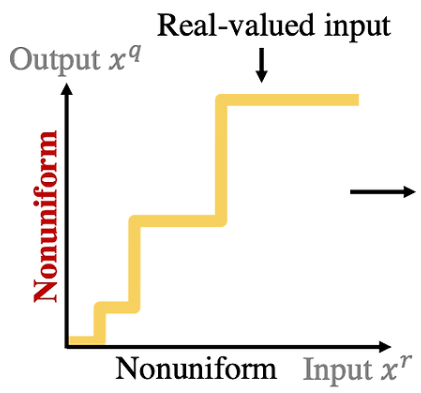
-
Uniform : input을 output으로 변환했을 때 output값들의 차이가 일정.
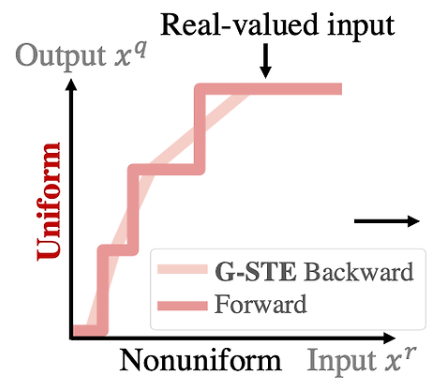
-
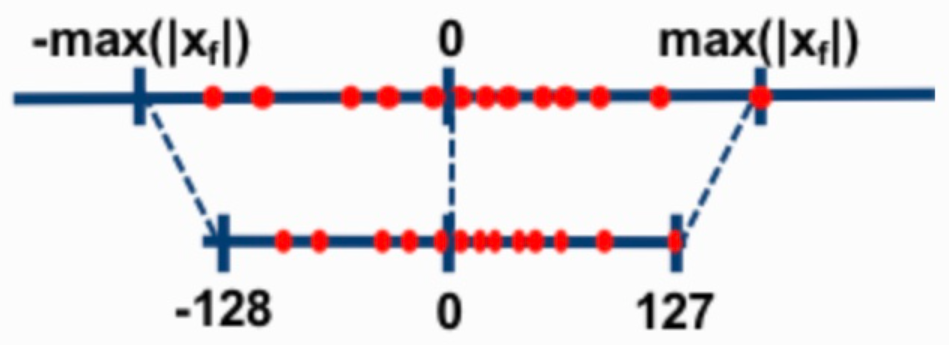
2. Symmetric vs Asymmetric
-
Asymmetric : output의 range를 정하는 min, max값의 절댓값이 동일하지 않은 경우
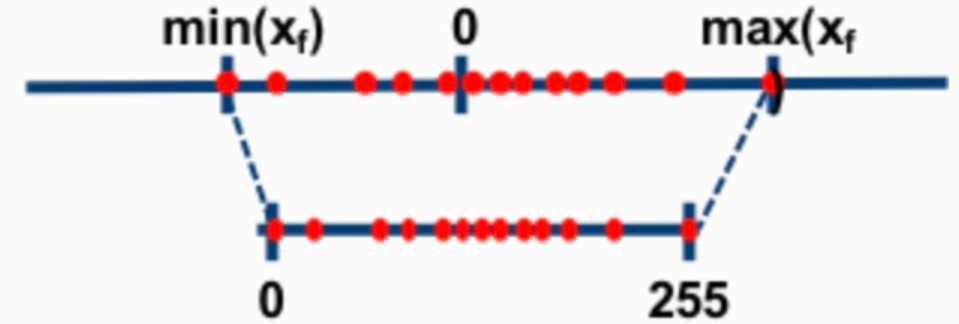
-
Symmetric : output의 range를 정하는 min, max값의 절댓값이 동일한 경우
Quantizing Method
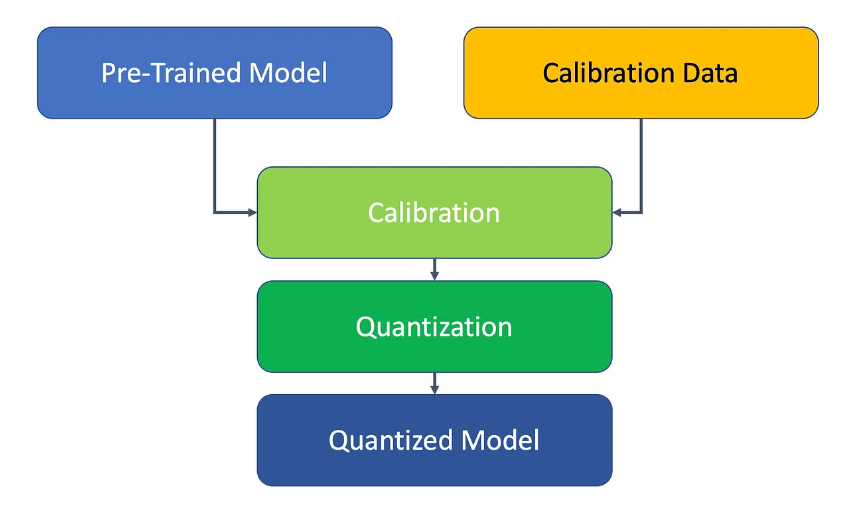
- PTQ (Post-training quantization)
-
모델이 학습된 이후에 Quantizing 진행
-
Inference 단계에서 Weight, Activation 이 원본 LLM의 Weight, Activation의 분포를 따르도록 quantizing 진행.
-
Calibration data가 PLM에 들어왔을 때 각 layer마다 scale을 저장해놓고, 이를 이용해 양자화.

-
어떤 것을 어느 과정에서 양자화하는지에 따라 2가지 방법 존재
Dynamic Quantization
학습이 끝난 모델의 weight는 미리 양자화를 진행하고, activation은 inference 시에 동적으로 양자화
Static Quantization
학습이 끝난 모델의 weight와 activation 모두 미리 양자화
- QAT (Quantization-aware training)
- 양자화로 인한 데이터 손실을 학습
- PLM에 양자화/역양자화 모듈을 달아서 Fine-Tuning 수행하면서 Quantizing Loss를 학습하여 Clip Value(Scale) 를 획득.
- 해당 Scale을 이용하여 PLM을 Quantize

PTQ의 한계
- Lower Precision Bits의 matrix multiplications 연산을 하려면 Activation과 Weight 둘 다 양자화해야함.
- Activation에서 높은 이상치는 양자화 오류를 발생시키며, 이는 PTQ 정확도 저하로 이어짐.
정교한 4bit Quantizing Method 제안
문제점
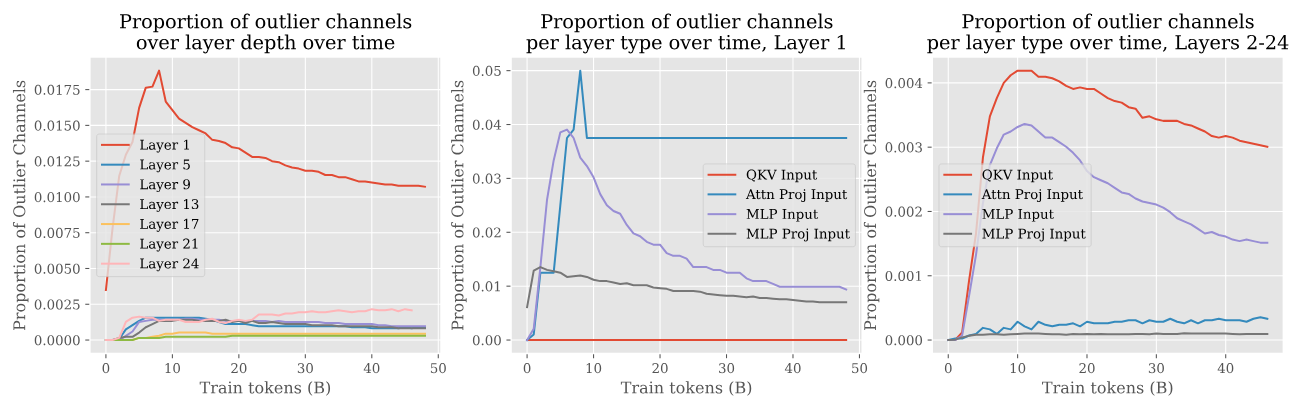
- 이상 채널(특징)은 상대적으로 훈련 초기에 나타남.
- 이상 채널은 특히 첫 번째 Layer의 activation과 kv-Linear 계층에서 특히 두드러짐.
제안 방법
- QAT
낮은 비트에서도 원래의 성능에 가깝게 동작하도록 하게끔 이용. 즉, 양자화 성능을 위한 목적으로 사용.- Activation Kurtosis Regularization
activation을 구하는 수식에 정규항을 추가해줌으로써, activation의 분포를 정규화된 형태로 유지해줌
모델 학습 동안 activation의 첨도를 최적화하여 이상 채널의 발생을 감소시킴.
Method
QAT
- W16A16 모델을 W16A4 모델로 Activation 만 Quantizing 수행.
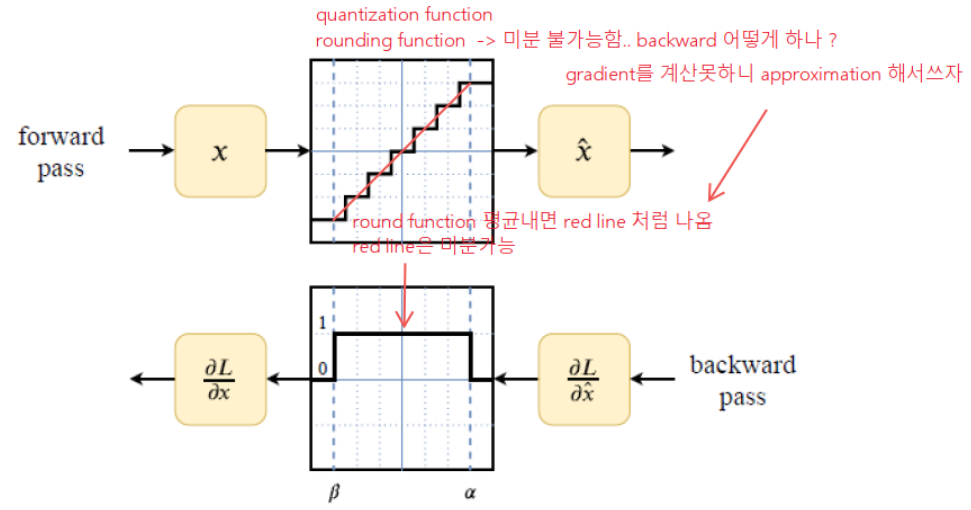
State-Through Estimator(STE) 방법을 사용하여 QAT 수행. - STE : quantization에 사용되는 round operation은 미분 불가능하기 때문에 gradient 값을 구할 수 없고 backward가 되지 않는 문제가 있음. 이를 해결하기 위해 round function 의 평균으로 approximate 하여 이 함수를 미분하여 backward 를 수행
Activation Kurtosis Regularization
- QAT 모델에서는 W16A4 → W4A4로 가중치를 양자화했을 때 이상 채널이 Weight의 특정 행으로 전이되면서 성능 저하가 심각하게 발생한다는 문제점이 발견됨.
- 이상 채널이 Weight로 전이되면 Column-Wise Weight PTQ가 더 어려워짐.
- 그렇다고 Weight를 정규화하면 성능이 대폭 감소함.
- Activation의 첨도를 정규화해줌으로써 Weight의 조정 없이 모델 출력의 분포를 조절하고, 따르게 만듬. 이는 간접적인 정규화 전략으로 볼 수 있음.
- 손실 함수에 첨도 항을 추가하여 구현
- Loss = C.E Loss + Lambda * Kurtosis Penalty
PTQ
- Activation 정규화 이후 W16A4 모델을 학습을 진행한 후, W4A4 모델로 변환.
- W16을 W4로 변환시키는 방법으로 2가지 방법 적용.
- RTN (Round-to-Nearest)
각 weight를 가장 가까운 quantization grid로 매핑
매우 간단하고, 성능 저하가 심하다고 알려져있지만, RTN으로 양자화했을 때 성능 저하가 덜 발생한다는 점을 보임으로써, activation regularization이 효과가 있다는 것을 증명. - GPTQ (Post-Training Quantization for GPT Models)
작은 양의 Callibration Data를 사용하여 가중치를 양자화
Result
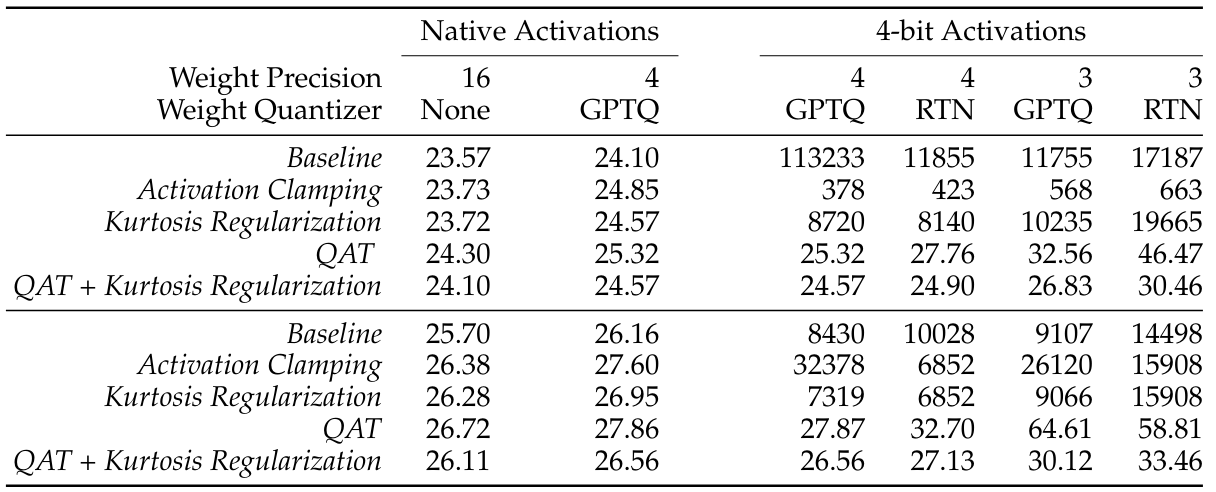
- 가중치가 점점 더 양자화됨에 따라 QAT 모델과 QAT를 하지 않은 모델 간의 성능 차이가 매우 두드러짐. (Perplexity)

고려대학교 인공지능학과 SLP Lab 석사과정생