SpeechGPT-Gen: Scaling Chain-of-Information Speech Generation
0. 들어가기 전에
- 해당 논문은 SpeechGPT 의 후속 논문임.
- 이전에 제가 포스팅했던 SpeechGPT 리뷰를 꼭 보고 와주세요.
- https://velog.io/@hyunku/Paper-Review-SpeechGPT
1. Background
이전 연구의 한계
- 이전 연구인 SpeechGPT 에서는 Speech로 자연스러운 대화가 가능하였음.
- 하지만 음운, 음색 등의 정보는 학습하지 못하고, 하나의 목소리로만 대화가 가능하였음.
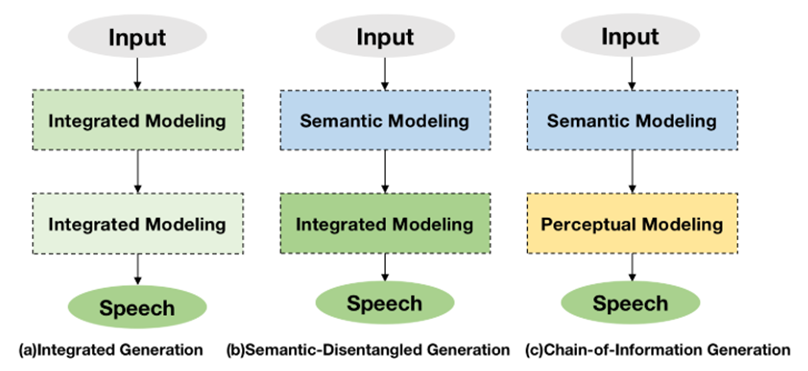
음성 처리 모델링의 한계
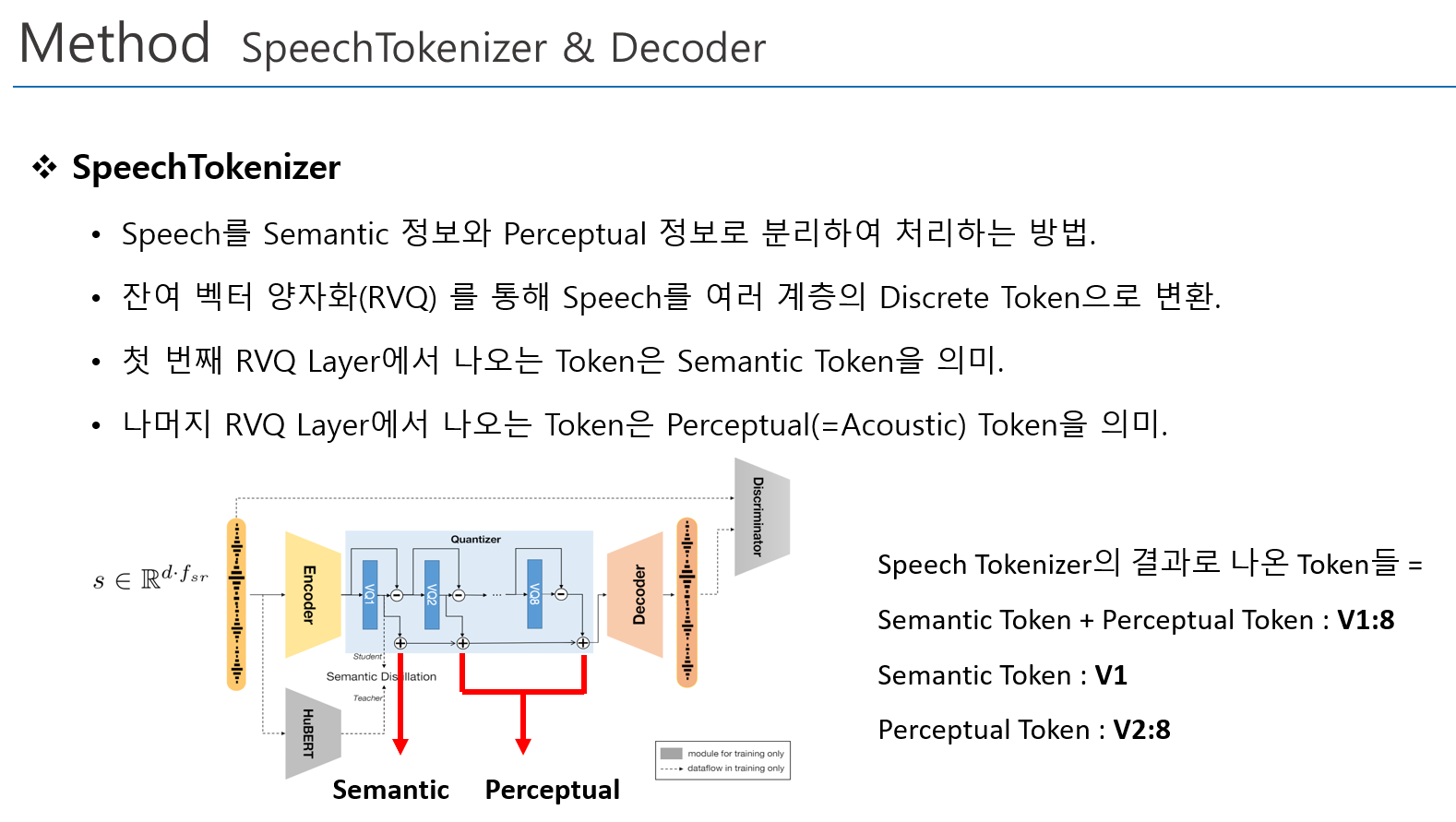
- Integrated - 의미(Semantic) 정보와 지각(Perceptual,Acoustic) 정보를 한꺼번에 모델링
- Semantic Disentagled - semantic 모델링 이후에 perceptual 정보를 합쳐서 모델링
- 두가지 방법 모두 semantic 과 perceptual 정보를 통합하는 과정에서 정보의 중복된 학습과 이에 따른 비효율성 초래
대규모 데이터 모델링의 한계
- Auto-Regressive (AR) - Next Token Prediction 으로 Token들을 학습
- Non-Auto-Regressvie (NAR) - Diffusion, Flow Matching 등 분포를 학습
- 두가지 방법 모두 semantic 과 perceptual 정보를 통합하는 과정에서 정보의 중복된 학습과 이에 따른 비효율성 초래
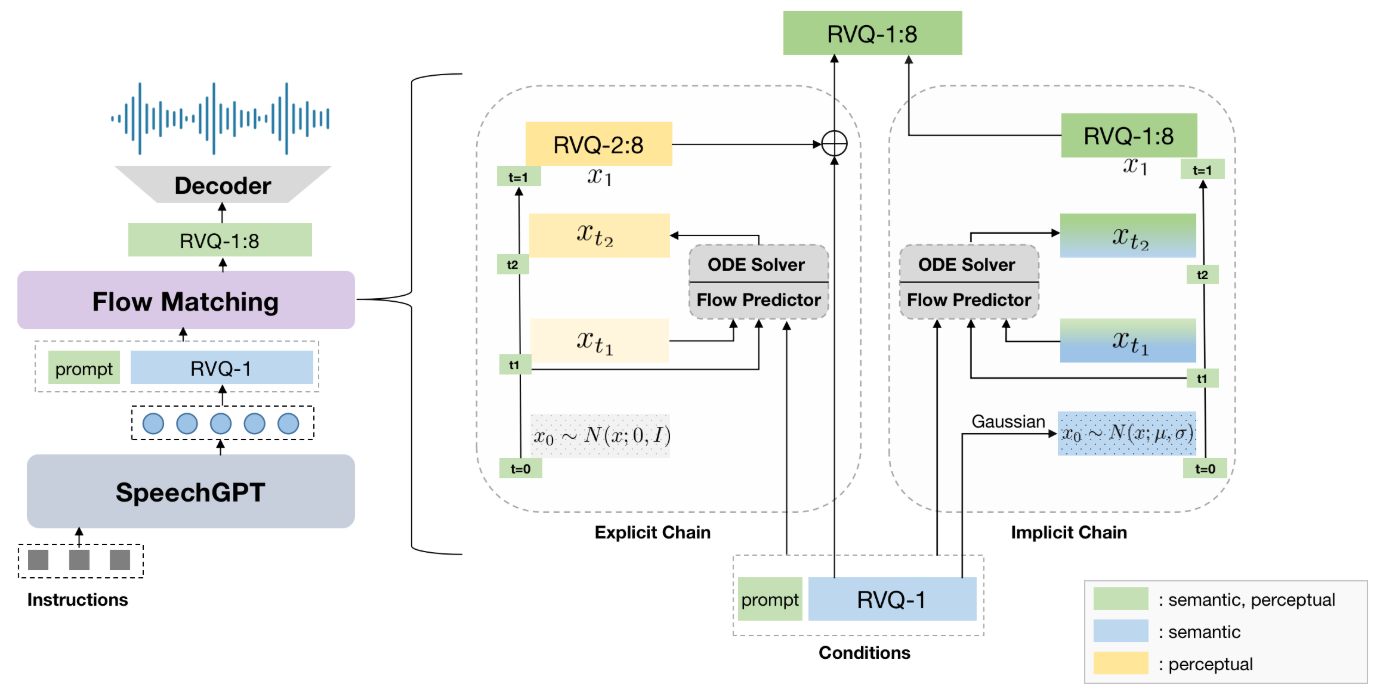
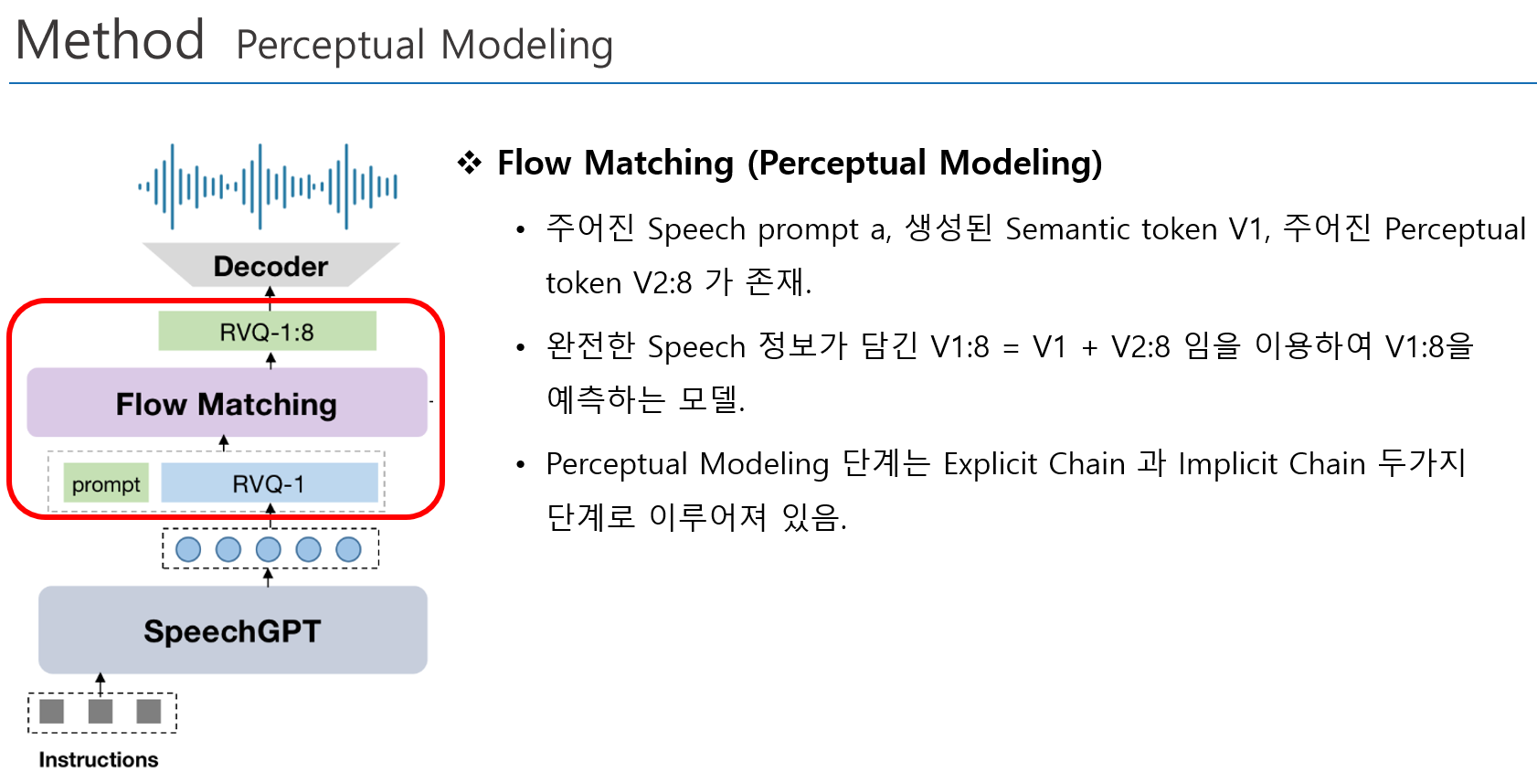
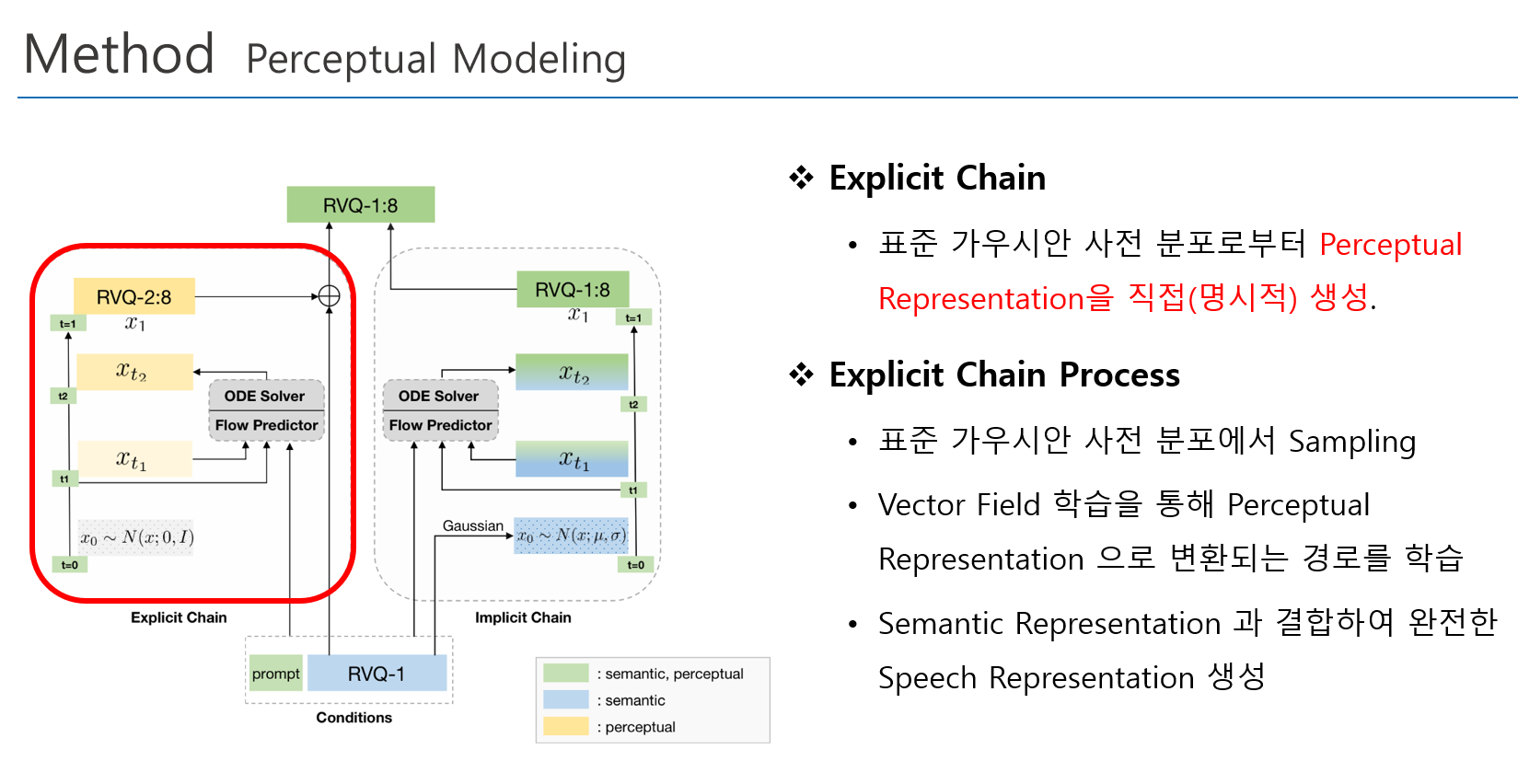
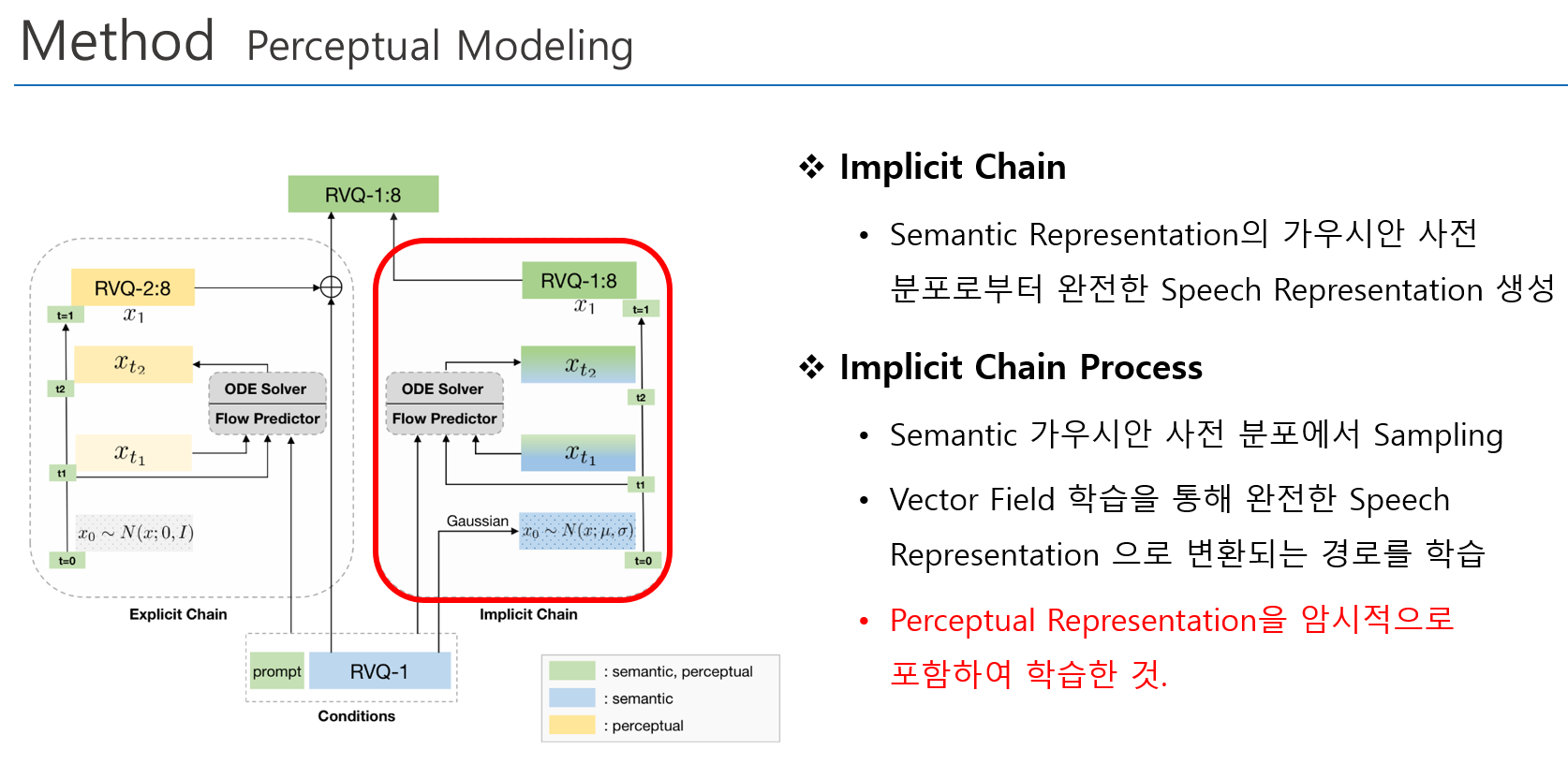
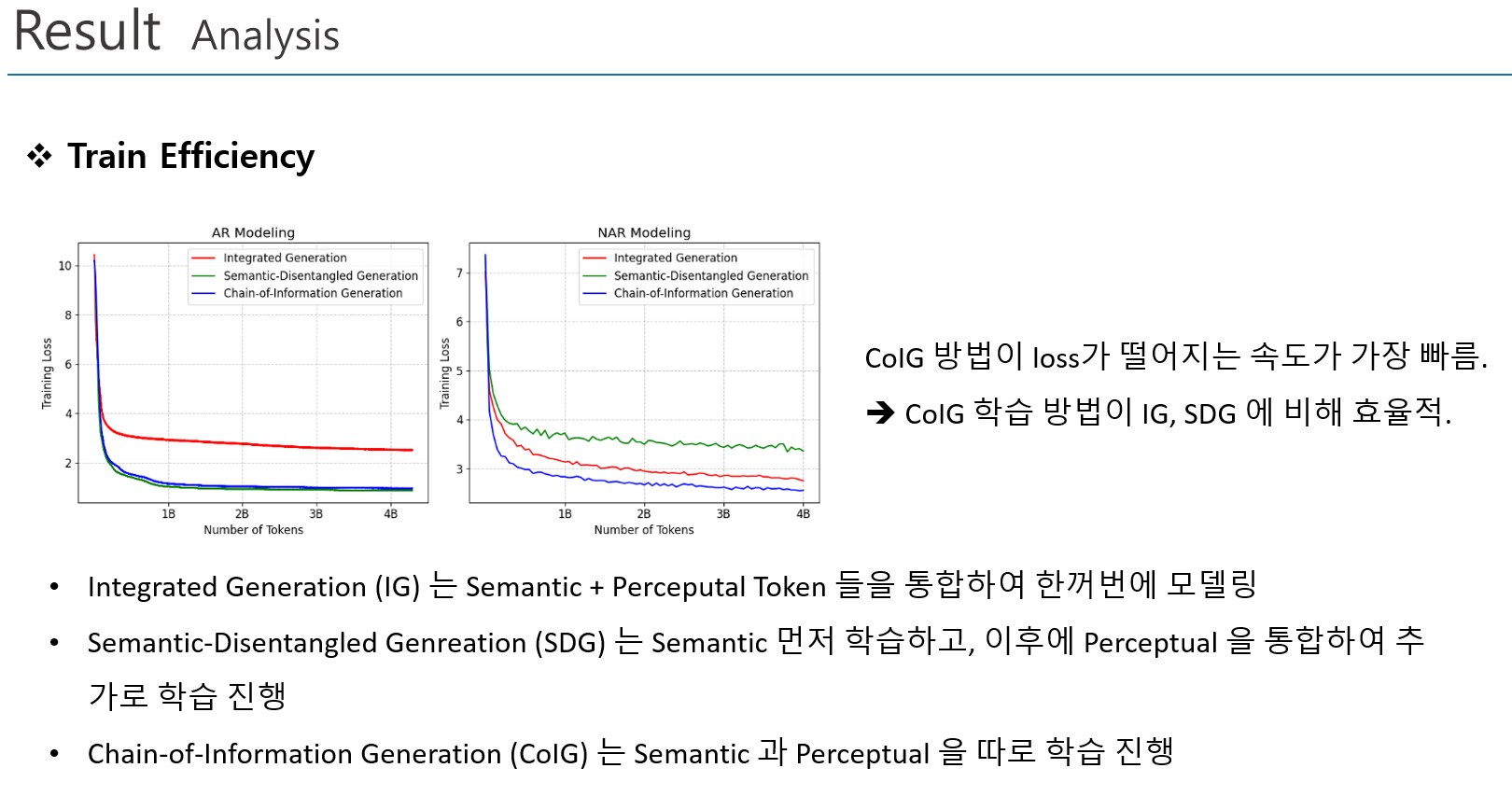
Chain-of-Information Generation (CoIG) 제안
- Semantic 정보와 Perceptual 정보를 분리하여 순차적으로 모델링 수행
- Semantic Modeling, Perceptual Modeling 을 순차적으로 수행
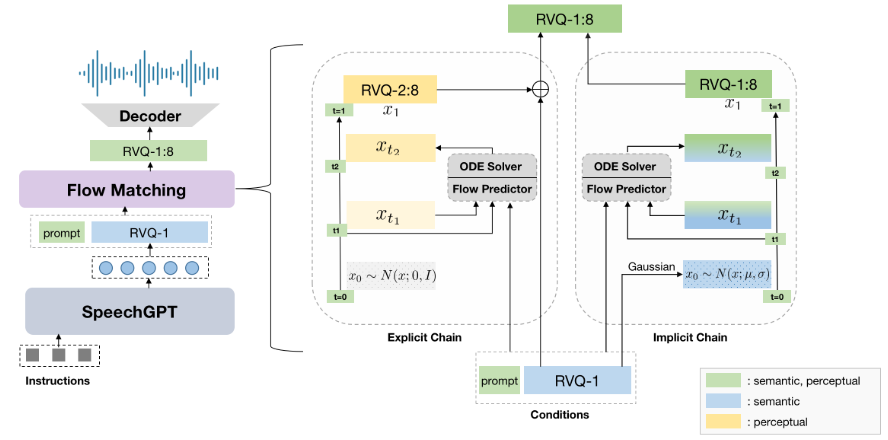
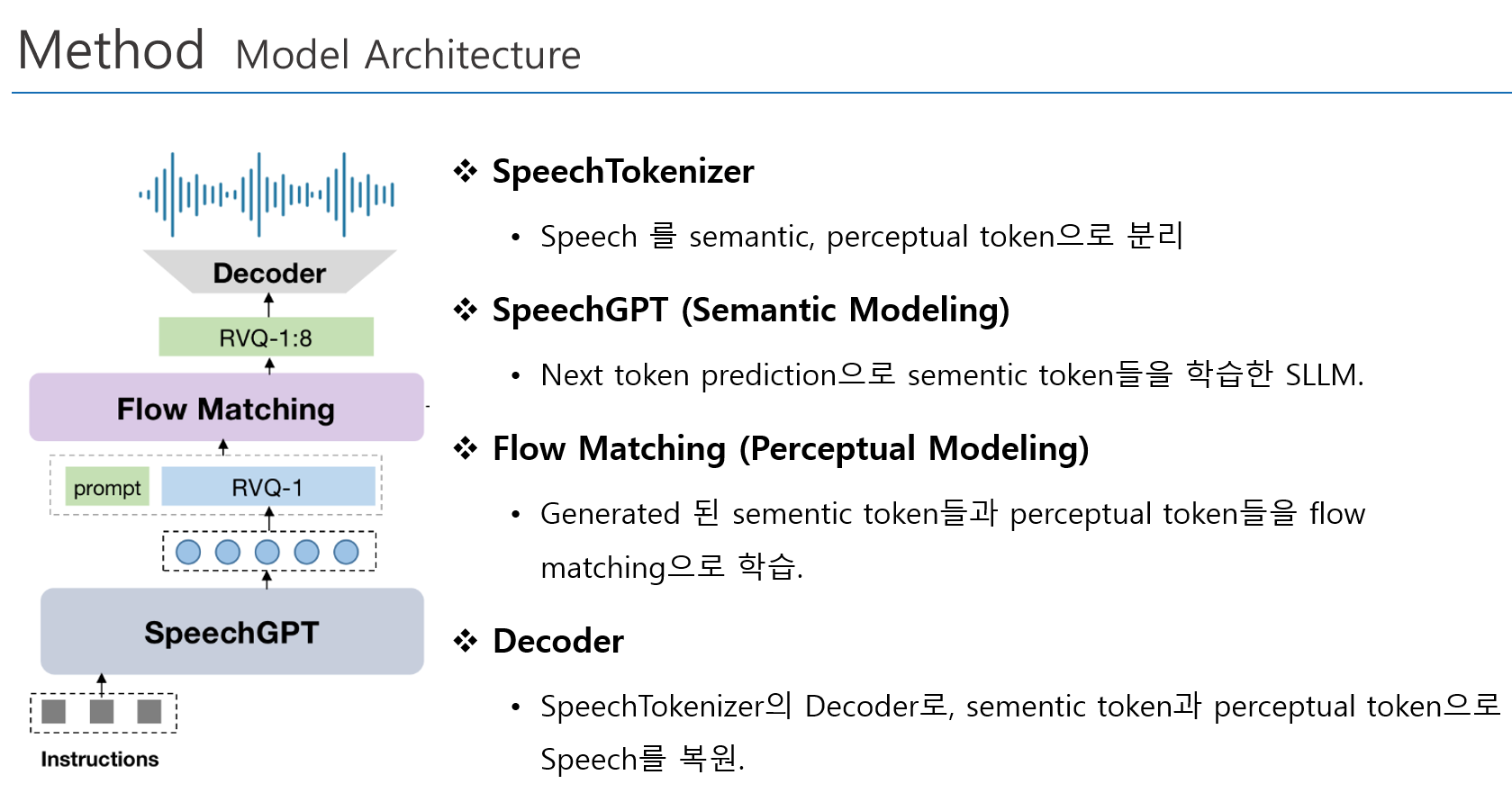
2. Model Architecture

3. Train



4. Result
About Evaluation Metrics
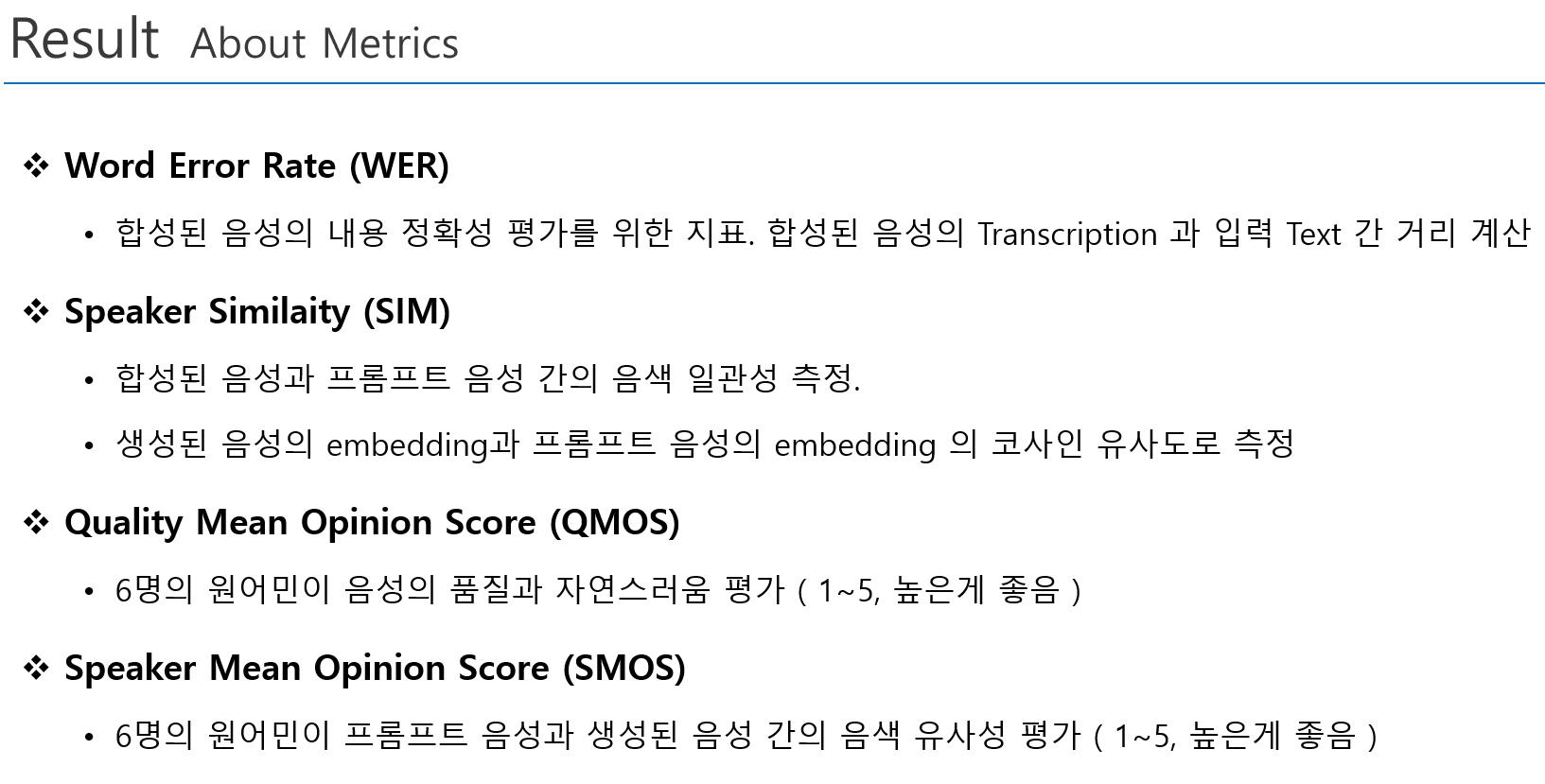

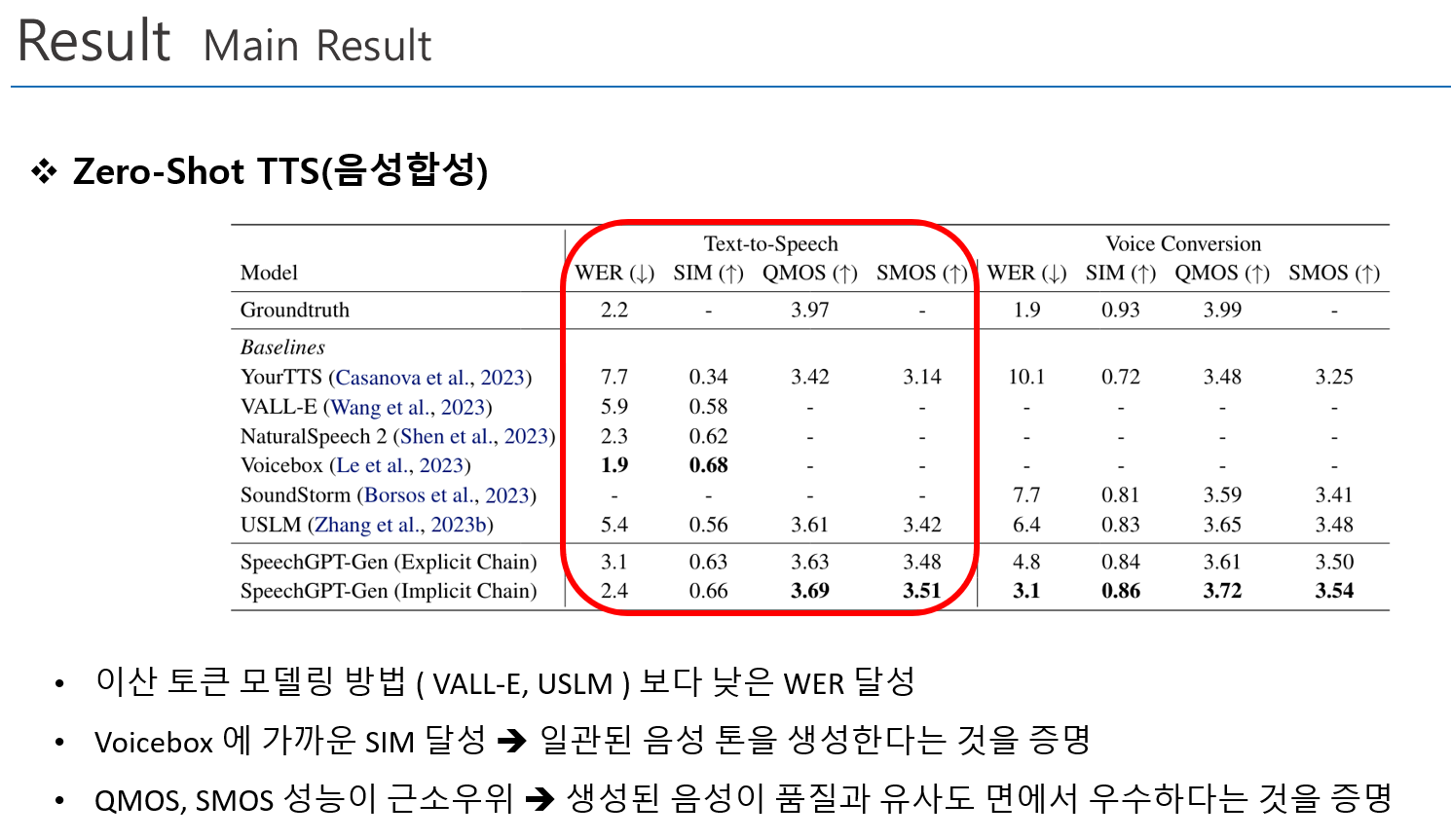
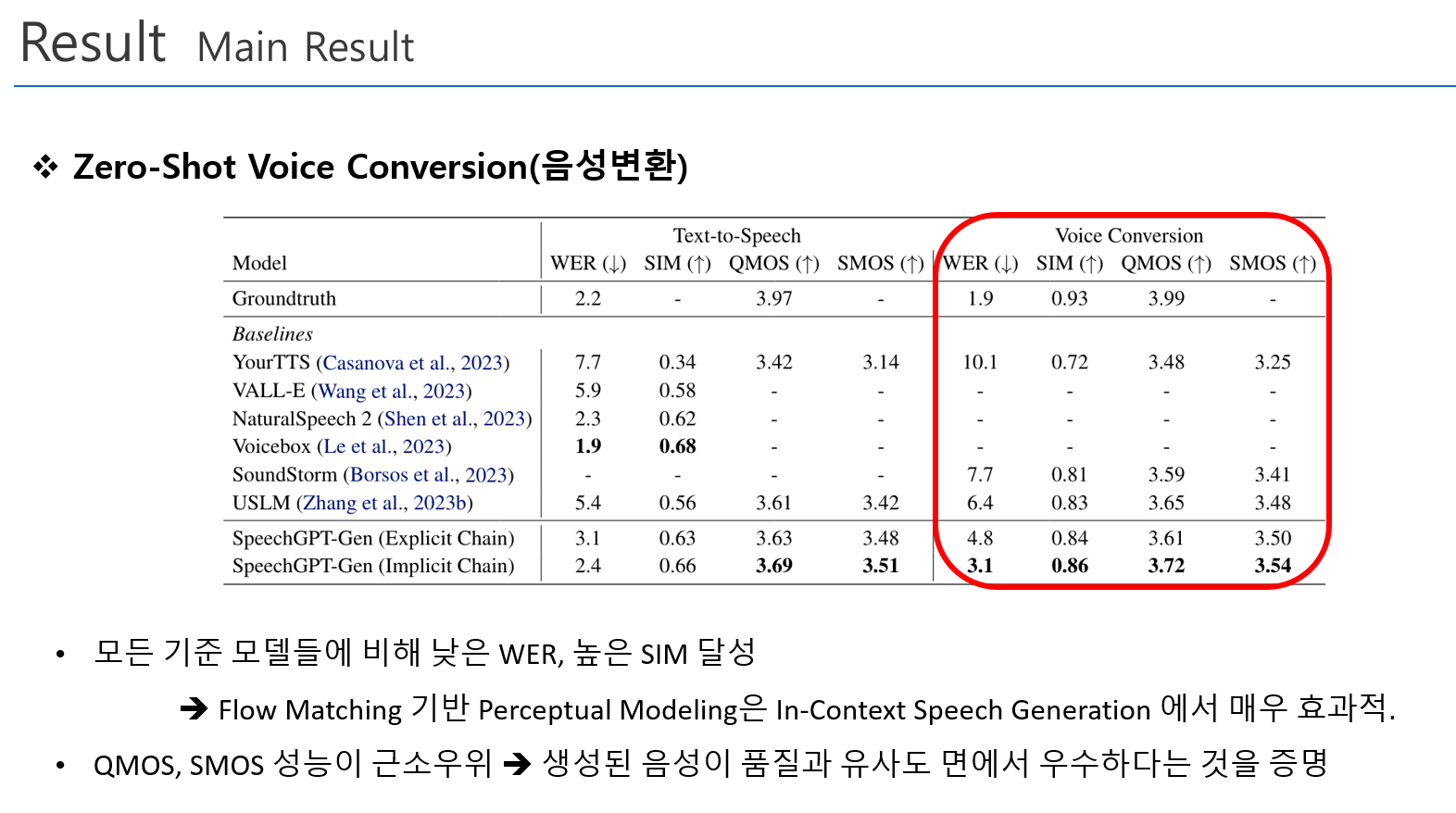
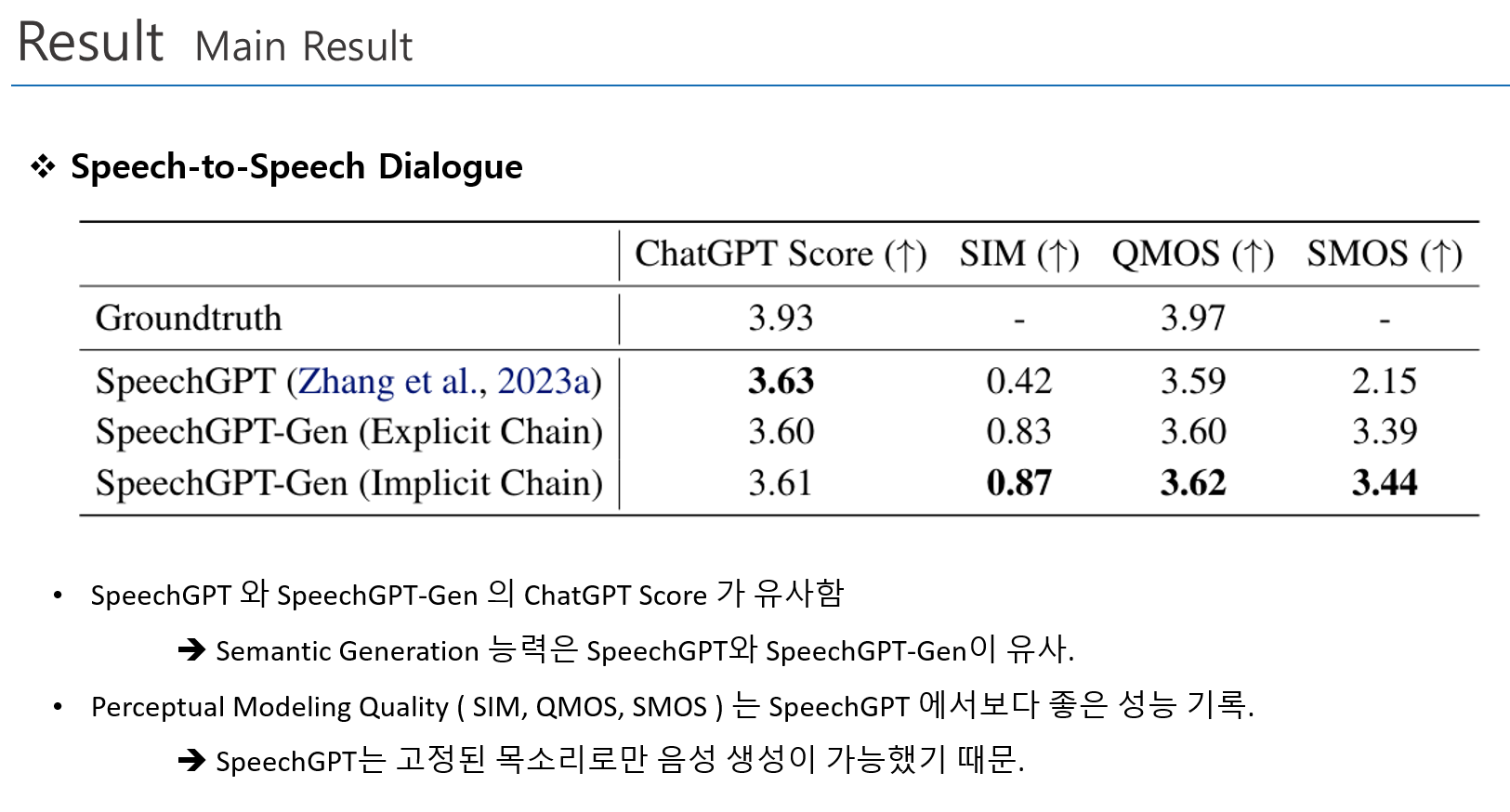
Main Result
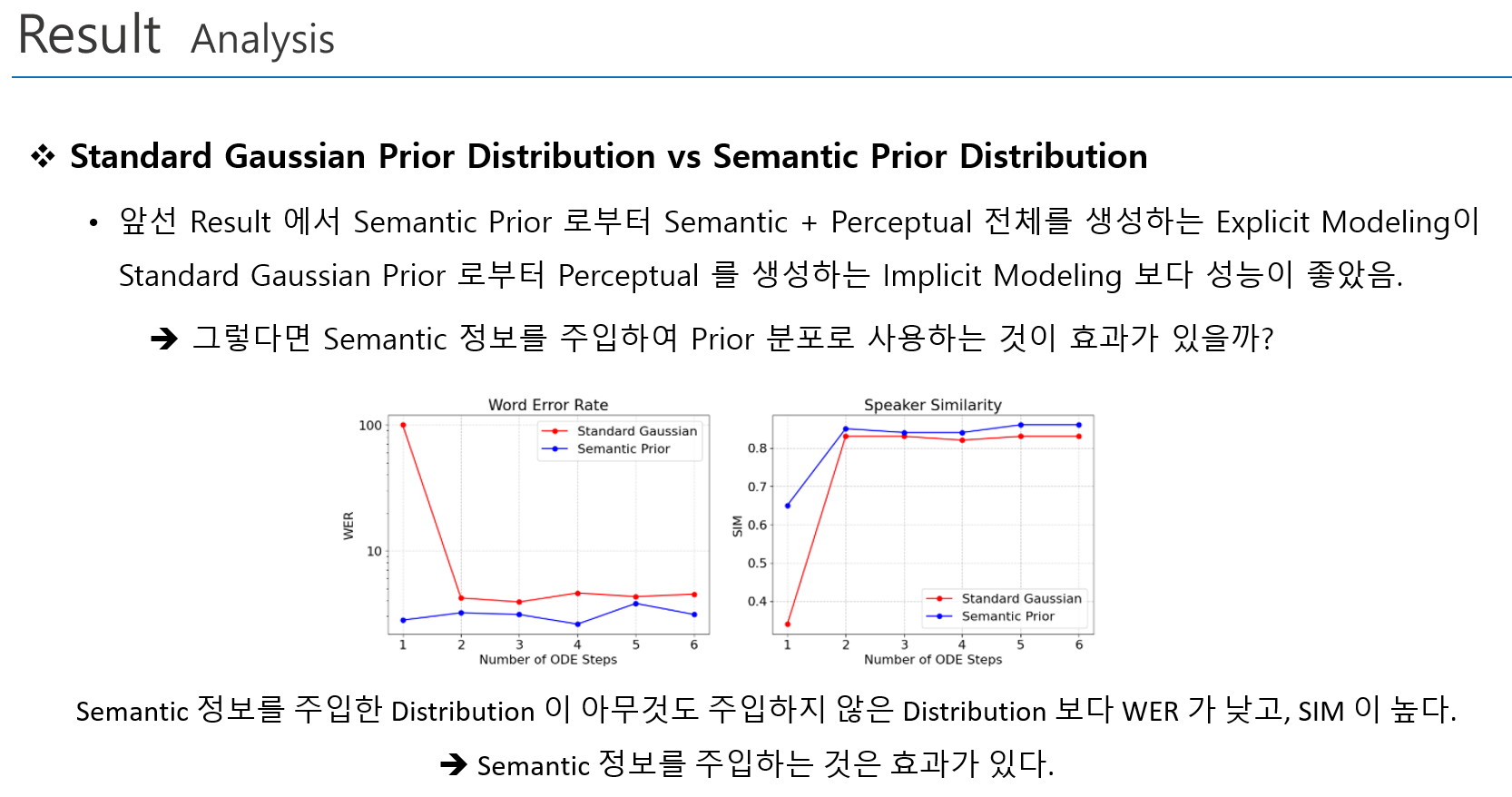
Analysis
5. Conclusion
Summary
본 논문에서는 효율적인 학습과 정확도의 개선을 위하여 CoIG 모델링 방법을 제안하였음.
- Semantic, Perceptual 분리하여 모델링 -> 높은 효율성, 높은 정확성
- Zero-Shot TTS, 음성변환, 음성대화 능력에서 우수한 성능 기록
- Semantic 정보를 주입을 통한 Flow-Matching 의 효율성을 개선
Opinion
- Implicit Module, Explicit Module 두개가 존재하고, 두 모듈의 비교는 좋은데, Sensitive Study로 각 모듈을 사용하였을 때와 두 모듈을 다 사용하였을 때의 성능 평가도 있었으면 싶다.

고려대학교 인공지능학과 SLP Lab 석사과정생