0. Abstract
Double-descent는 모델 크기를 점차적으로 키울 때 성능이 떨어지다가 다시 개선되는 현상을 말한다. 이 논문은 여러 딥러닝 과제들에서 나타나는 “double-descent” 현상을 실험하였다.
이 논문은 또한 double-descent가 모델 크기 뿐만 아니라 epoch 수와도 관련 있음을 보였다. 나아가서 generalized double descent와 새로 정의한 값인 effective model complexity 사이의 관계를 분석하였다. 이 값을 사용하여 train sample 수를 증가시켜도 모델 성능이 떨어지는 구간도 찾아낼 수 있었다.
1. Introduction
전통적으로 우리가 알고 있는 bias-variance trade-off 개념에 따르면, 처음에 모델의 크기가 커지면 bias가 작아지면서 모델 성능이 개선되지만, 일정 크기를 넘어가면 variance가 증가하며(overfit) 결과적으로 모델 성능이 감소한다. 즉, 전통적인 통계학의 개념에 따르면, 특정 임계치를 넘어가는 순간 “큰 모델은 더 나쁘다”
하지만 최근의 뉴럴넷 모델들을 보면 위 개념은 더이상 적용되지 않으며, 실제 모델을 구현하는 사람들은 큰 모델이 더 낫다는 경험적인 믿음을 갖게 되었다. 또한 학습시간에 대한 논쟁 역시 있는데, train error가 0이 될 때가지 오래 학습하는 모델 vs early stopping이 그것이며, 이는 케바케인 것으로 보인다. 하지만 한 가지 변하지 않는 사실은 데이터는 다다익선이라는 것이다.
이 논문은 위처럼 전통적인/경험적인 개념에 대해 실험으로 규명해보려고 한다. 이 논문에서는 많은 딥러닝 모델들이 아래와 같은 두 가지 regime(구간)을 갖는다고 말한다.
-
under-parameterized regime
- 모델 복잡도가 train sample에 비해 작은 구간
- 이 구간에선 bias-variance tradeoff 개념에 맞게, 복잡도와 test error 간에 U 형태의 관계를 보인다.
-
over-parameterized regime
- 모델 복잡도가 충분히 커서 interpolate(train_error 0) 할 수 있는 구간
- 이 구간에선 복잡도를 올리면 test error는 계속 감소하게 된다. 즉, larger models are better
즉, 전통적인 관점과 최근의 관점 모두 구간에 따라 맞는 말이며, 이는 double-descent란 이름으로 기존에도 다양한 모델에 대해 분석되었다. 이 논문은 여기서 한 발 나아가서 여러 task, 구조, optimization 방법론과 double descent의 관계를 분석해본다.
또한 effective model complexity(EMC)를 정의하는데, 이는 training error를 0으로(interpolate) 만들 수 있는 최대 training sample의 수를 의미한다. EMC는 데이터 분포, 모델 구조, 학습 시간에 영향을 받는다는 사실 역시 알아내었다.
이 논문은 double descent가 EMC값의 함수로 표현될 수 있다고 가정한다. 실험적으로 보인 “epoch-wise double descent”의 경우를 보면, EMC가 샘플 수보다 작은 경우, epoch을 늘리면 U 커브를 보이며 성능이 감소한다. 하지만 EMC가 학습 샘플 사이즈보다 충분히 큰 경우 epoch을 늘리면 성능이 지속적으로 상승한다. 즉, 학습 시간과 double descent 간에 관계가 있음을 보였으며, 이게 EMC의 함수로 표현될 가능성이 있음을 확인한 것이다.
위 내용을 바탕으로 보면, 모델의 테스트 성능은 학습 샘플 사이즈의 함수로 표현될 수도 있겠다는 생각을 갖게 한다. test error는 EMC가 샘플 사이즈와 같을 때 최대값을 가지며, 샘플 사이즈를 키울 수록 우측으로 이동한다. 즉 이 피크가 어디 있냐에 따라 샘플 사이즈를 키울 수록 성능이 하락할 수도 있다.
2. Our Results
effective model complexity(EMC)는 아래와 같이 정의된다.
- 전체 학습 과정(모델 크기, 학습시간 등을 포괄): T
- input data:
- output: T(S)
- T에 대한 EMC(w.r.t. distribution D)는 T가 0에 매우 가까운 training error를 얻을 수 있는 최대 샘플 사이즈 n으로 정의된다.

이렇게 정의된 EMC를 이용하여 이 논문의 핵심 주장을 아래와 같이 가정할 수 있다.

즉, 정리해보자면 어떤 학습 과정 T가 있다고 했을 때, 이게 n 크기의 training set을 충분히 학습할 수 없는 복잡도라면(EMC<n), 복잡도를 더 올리면 오히려 모델 성능이 떨어진다는 것이다. 하지만 이게 임계점을 넘어서 training set을 충분히 학습할 수 있는 복잡도를 넘어가게 된다면 그때부턴 복잡도를 올리는 게 모델 성능을 높여준다.
위 정의와 가정은 값을 정하지 못한다는 것과(보통 0.1) sufficiently 가 어느 정도인지 정하지 못했다는 점에서 조금은 애매한 부분이 있다. 또한 위 가정을 보면 EMC(T)=n 근처에 critical interval이 존재하는데, 이 구간의 너비는 데이터 분포와 학습 과정 T에 영향을 받는 것으로 보이지만 역시 아직 해결하지 못했다. 대신 이걸 파악해보기 위해 다양한 실험을 해봤다.
3. Related Work
double descent에 대한 연구는 기존에도 있었지만, 이 논문은 아래 두 가지에서 차이점이 있다.
- 단순히 모델 parameter 수와의 관계가 아닌, 학습 과정 T 전체와의 관계를 EMC를 통해 분석한다.
- double descent를 최근에 만들어진 여러 모델 구조, 데이터, optimization 방법론 에 대해 적용해본다.
4. Experimental Setup
세 가지 모델 구조로 실험을 진행하였다.
- ResNets
- convolutional layer의 width(필터 갯수)를 [k, 2k, 4k, 8k]로 바꿔가며 parameter 수를 조절하였다.
- 일반적으로 k=64가 기본 세팅이다.
- Standard CNN
- 5-layer CNN을 사용하였고, 마찬가지로 4개의 convolution layer에 대해 width를 [k, 2k, 4k, 8k]로 바꿔가며 parameter 수를 조절하였다.
- 마찬가지로 k=64를 이용하면 CIFAR-10 데이터셋에서 괜찮은 성능 보인다.
- Transformers
- 6-layer encoder-decoder 모델을 사용하였다.
- embedding dim 과 fcn dim 을 이용하여 parameter 수를 조절하였다.
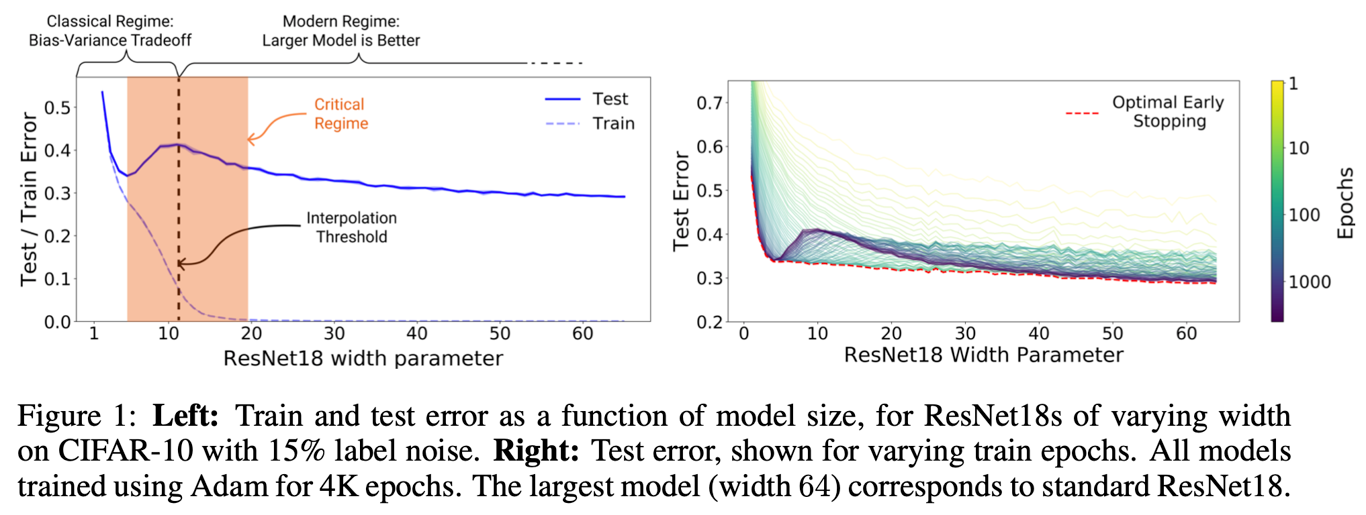
Lable noise에 관한 실험 역시 진행하였다. 위의 왼쪽 그림은 15%의 noise가 낀 상황인데 label noise의 영향으로 double descent 현상이 크게 나타남을 볼 수 있다. 물론 noise가 없는 경우에도 이런 현상이 발생함 역시 뒤에서 보인다.
5. Model-wise Double Descent

noise label 이 있는 경우, noise의 비율이 증가함에 따라 peak(interpolation threshold)가 높아지고 더 오른쪽으로 이동하는 것을 알 수 있다. 즉, double descent의 정도가 심해지고 더 큰 모델이 필요해진다. 또한 위에서 train error가 0이 되는 점이 test error peak가 발생하는 부분과 일치한다는 사실을 확인할 수 있다.
noise label이 존재하는 경우에 대한 해석은 직관적으로 해볼 수 있다. interpolation이 시작되는 지점에서는 해당 크기의 모델로 interpolation이 가능한 구조는 하나 혹은 매우 적을 것이다. 때문에 이미 한계치인 모델에 noise가 들어올 경우 모델이 더 버티지 못하고 무너지게 된다. 하지만 over parameterize 된 모델에서는 interpolation이 가능한 구조가 여러가지이기 때문에 noise가 들어와도 optimizer가 noise를 분리해낼 수 있도록 학습시켜준다.
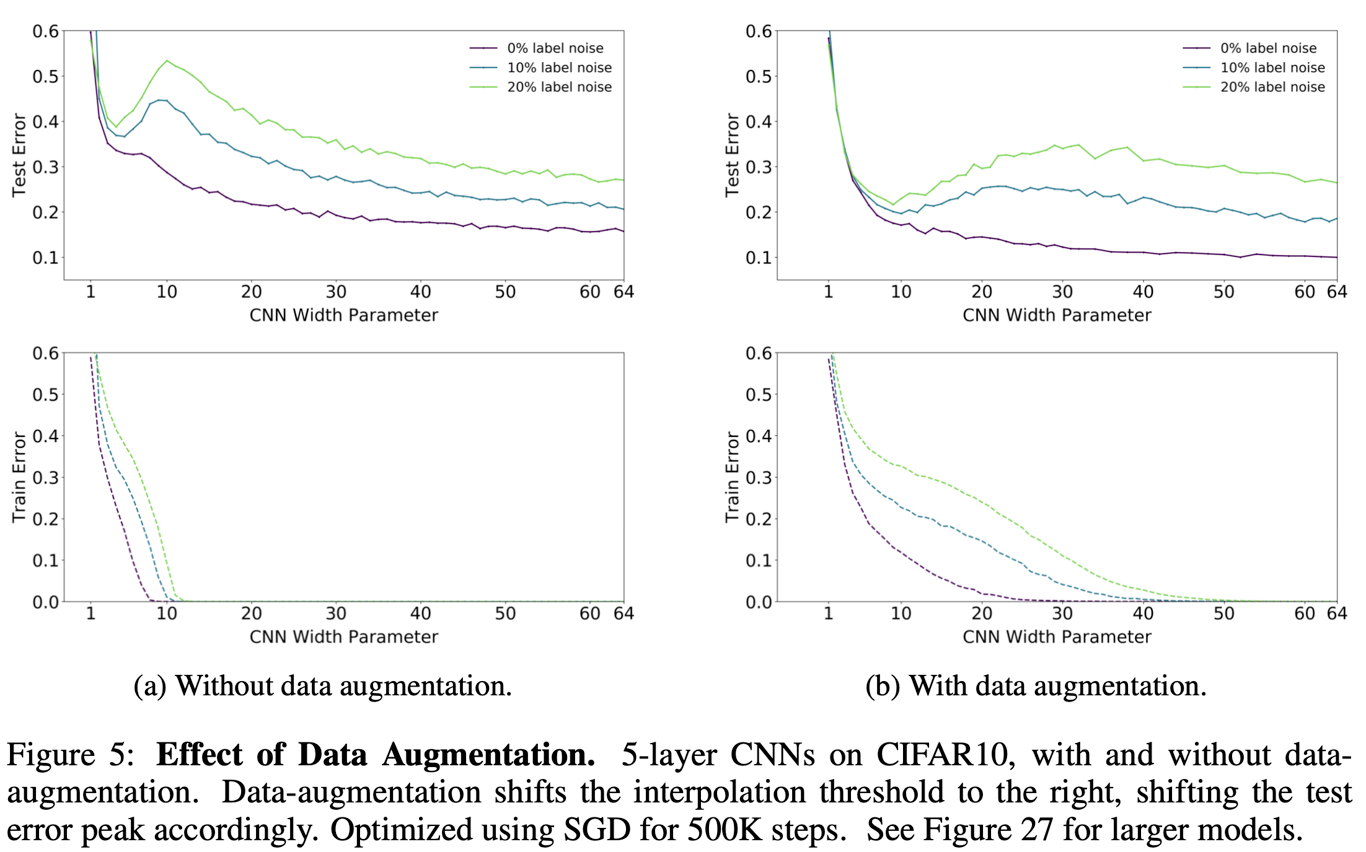
data augmentation 역시 noise label과 마찬가지로 peak를 오를쪽으로 이동시킨다. 이는 학습 샘플의 증가이기 때문에 EMC < n의 효과를 내기 때문으로 보인다.
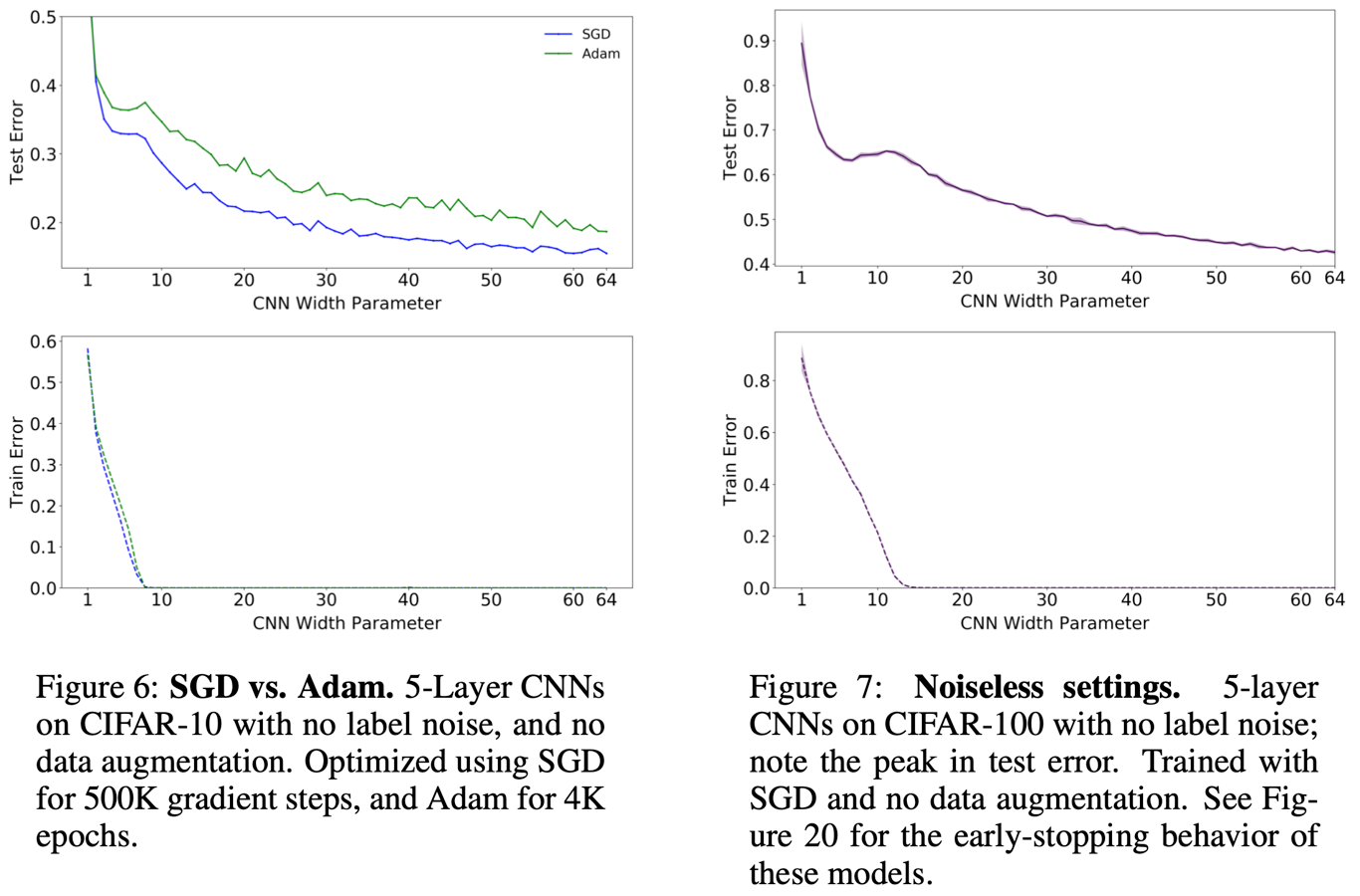
위 그림의 왼쪽은 optimizer의 차이를 보여준다. 즉, optimizer 역시 double descent에 영향을 주며, CNN의 경우에는 SGD가 더 좋았다.
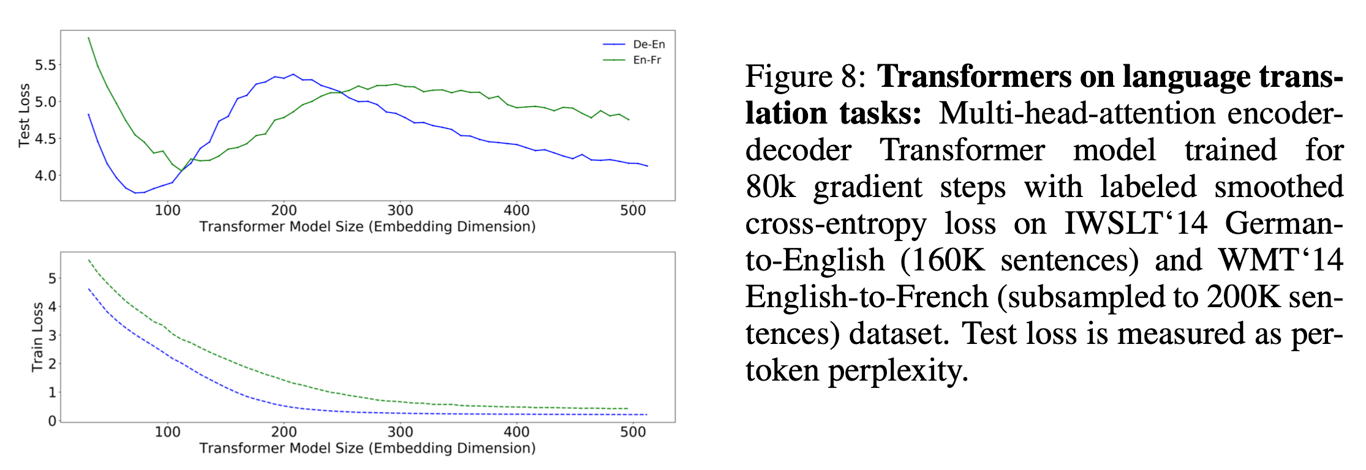
transformer의 경우에는 데이터가 더 적은 De-En이 오히려 peak가 왼쪽에 위치한다. 즉 단순히 샘플 사이즈로만 볼 수 없고, task 종류 및 데이터의 분포 역시 영향을 미치는 것이라 볼 수 있다.
6. Epoch-wise Double Descent

epoch 수를 늘리는 것은 EMC를 증가시키는 것과 동일하다. 즉, 동일 모델 크기에서 더 많은 수의 학습 데이터에 대해 0에 가까운 error를 가질 수 있다. 이는 곧, 충분히 큰 모델이라면 epoch 수가 증가함에 따라 under-parameterized로 여겨졌던 모델이 오히려 over-parameterized가 될 수 있다는 의미이다.
위 그림을 보면 large model에서 가장 먼저 double descent가 발생하고 있다. intermediate model은 아직 U 형태를 벗어나지 못했지만, 모델의 크기가 충분하다면 double descent가 추후에 발생할 수도 있을 것이다(형태상 그럴 가능성은 낮아보인다). small 모델은 U 곡선 중 앞부분(under-parameterized)에 위치해있어서 epoch 수를 늘림에 따라 test error는 계속 줄어든다. 하지만 더 오래 학습시키면 U곡선 위로 올라오게 될 가능성도 배제할 수 없다. 즉, 어떻게 조합하냐에 따라 오히려 작은 모델이 중간 모델보다 나을 수 있다.
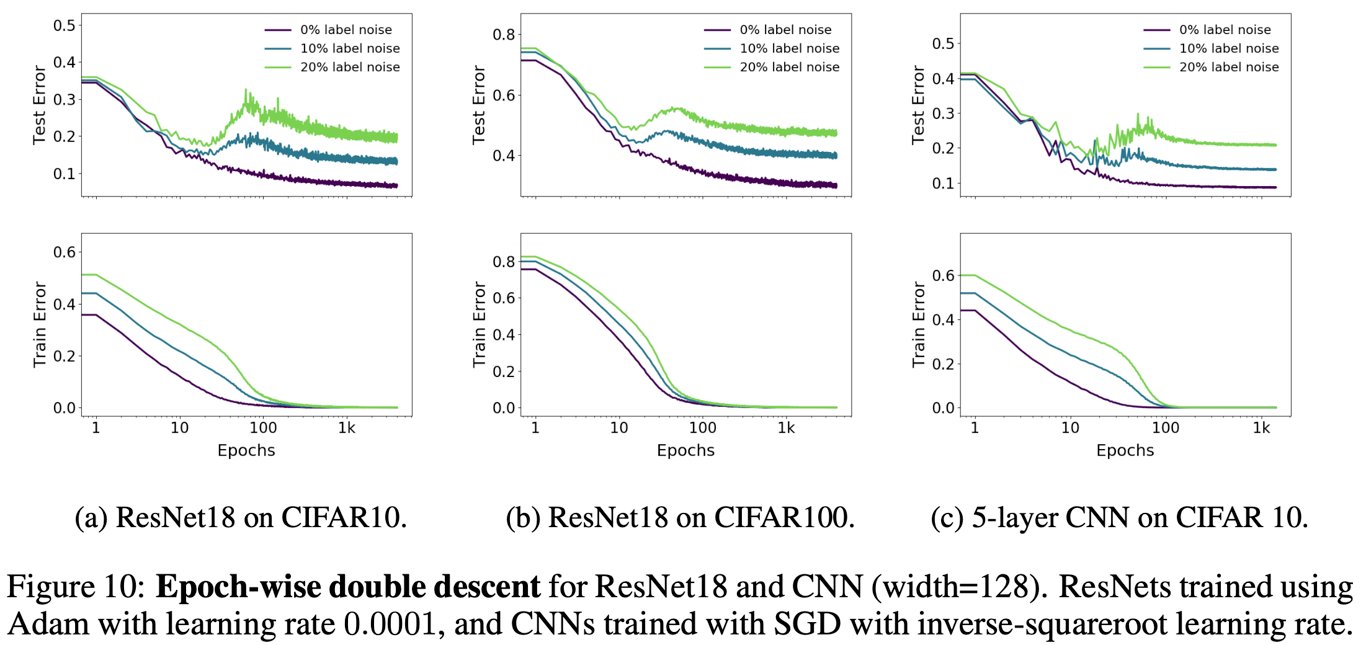
이러한 epoch-wise double descent는 여러 모델, 여러 데이터에 대해서 광범위하게 나타나는 것을 위의 figure 10에서 확인할 수 있다.
전통적으로 우리는 모델의 학습이 진행됨에 따라 generalization이 가능한 모델에서 이것이 불가능한 overfit 모델로 변화되어간다고 생각했지만 실험해보니 그게 항상 맞는 건 아니라는 사실이 드러났다. 위에서 10% noise label의 경우를 보면 epoch 10-100 언저리에서 이런 전통적인 현상이 나타나지만, 조금만 더 인내심을 가지고 기다리면 다시 test error가 낮아지는 것을 통해 이를 유추할 수 있다.
7. Sample-wise Non-monocity
위의 model,epoch-wise는 인 critical regime이 EMC가 변함에 따라 어떻게 달라지는가를 다뤘다면, 여기서는 샘플 사이즈 n이 변함에 따라 어떻게 달라지는가를 다룬다. 위의 epoch과 반대로, 학습 샘플 사이즈 n을 증가시키면 over-parameterized 모델이 under-parameterized 모델로 점점 변하게 된다.
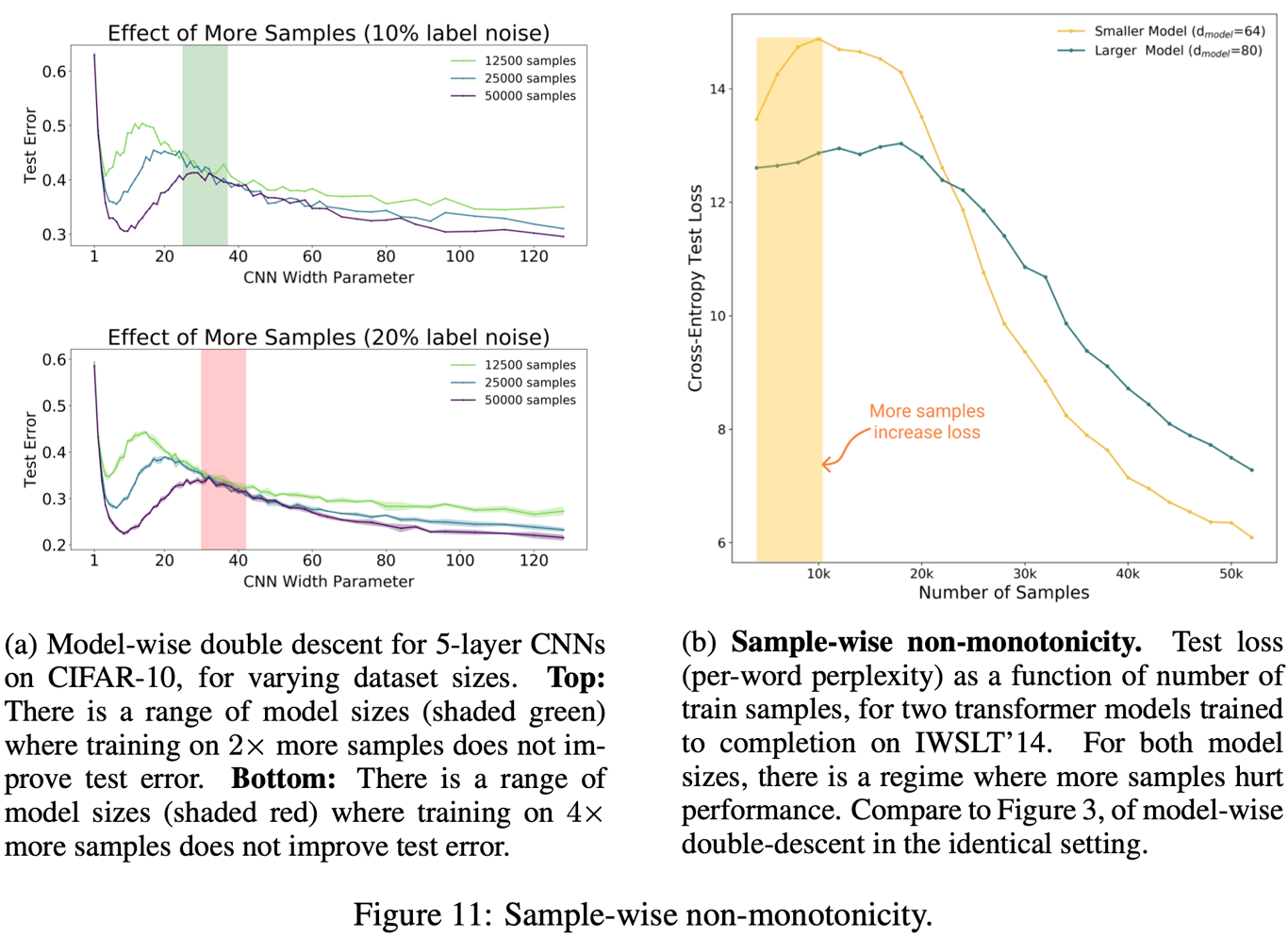
샘플 사이즈를 늘리면 두 가지 효과가 있다.
- 그래프 밑부분 넓이가 줄어든다. 즉, peak가 낮아진다.
- peak가 우측으로 이동한다. 즉, double descent를 경험하려면 모델 복잡도를 더 키워야한다.
이때 주목할 점은 아래와 같다.
- 샘플 사이즈를 늘려도 아무 효과가 없는 구간이 있다.
- 그 외에는 샘플 사이즈를 늘리는 게 훨씬 낫다
물론 이게 항상 맞는 것은 아니다. 11-b를 보면 이게 운 나쁘게 교차될 경우 오히려 샘플 사이즈 키우는 게 loss를 높일 수도 있음을 보여준다. 실제로 아래를 보면 대체로 샘플 사이즈를 키우면 test error가 줄지만, intermediate model에서는 그렇지 않은 구간도 존재한다.
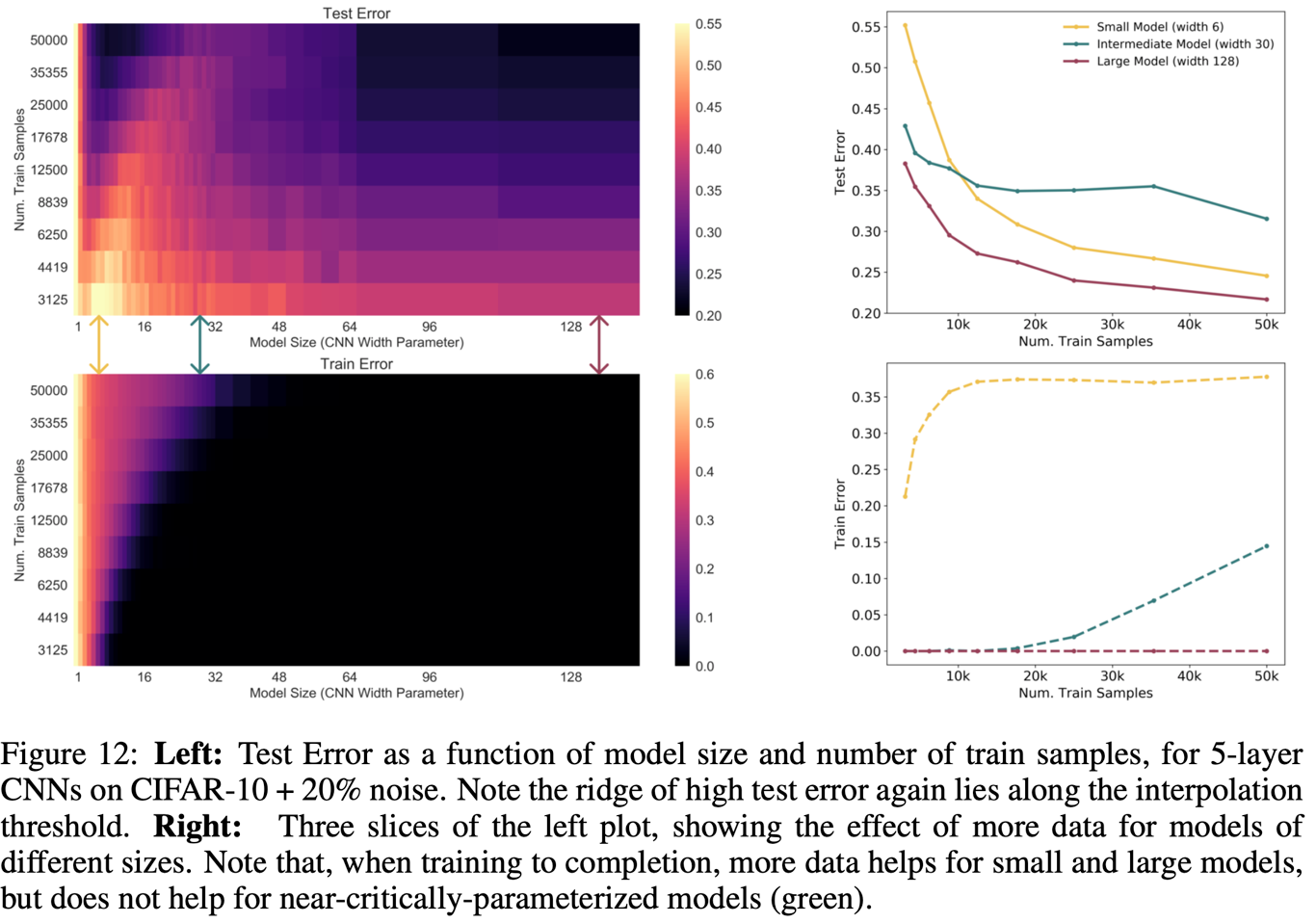
8. Conclusion and Discussion
EMC가 학습 샘플 사이즈와 비슷한 경우에는 상식과 다른 결과가 나올 수 있다는 generalized double descent 가정을 소개하였다. 이는 DNN 전반에서 나타나는 문제이며, 모델 구조/데이터셋/학습과정과 무관하게 일반적으로 나타나는 현상임을 실험적으로 확인하였다.
- model-wise double descent를 실험하며 실제로 큰 모델이 오히려 안 좋은 구간을 확인해보았다.
- epoch-wise double descent를 실험하며 epoch과 test error의 관계가 기존 생각처럼 단순하지 않음을 보였다.
- sample-wise double descent를 실험하며, 데이터가 많으면 역으로 모델 성능이 줄어드는 구간이 생길 수도 있음을 보였다.
또한, 현재 모델이 train set에 대해서도 충분히 fitting 되지 못하는 상황이라면(underfit), 학습 과정에 대한 약간의 변화도 예상치 못한 결과를 초래할 수 있음을 보였다.
- 예를 들어 모델 사이즈를 약간 키우면 U 커브의 후반부에 들어가서 오히려 test error가 증가할 수 있다.
- 한편으론 open AI라 그런가 결국 over parameterized된 모델이 여러모로 안정적으로 best라는 주장를 한다는 느낌도 있다.
Early Stopping
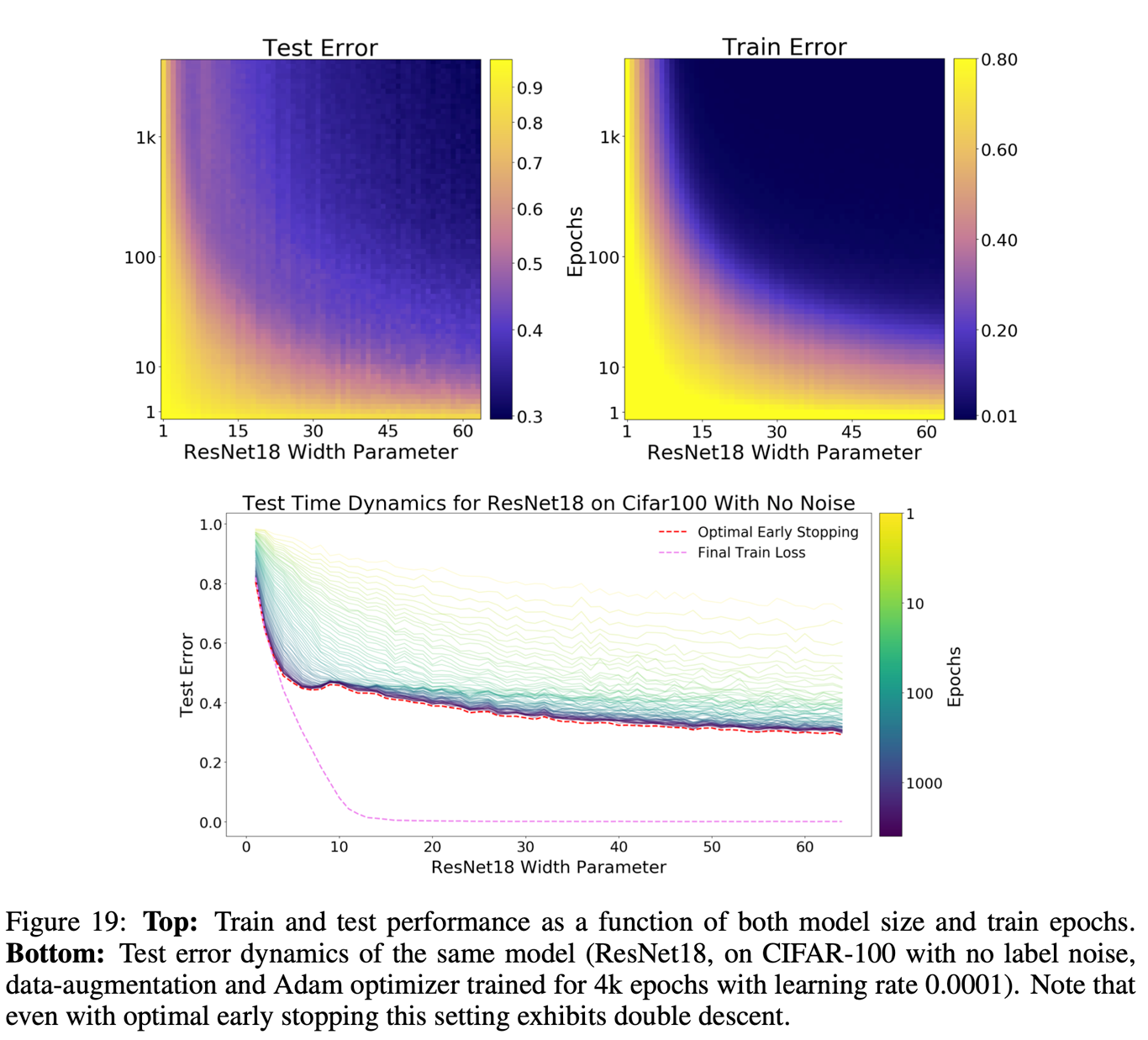
optimal한 early stopping을 할 경우, 당연하게도 위에서 실험한 현상들은 나타나지 않는다. train error가 0이 되기 전에 멈추기 때문이다.
하지만 항상 그런 건 아닌게 위 그림중 아래를 보면 optimal early stopping 하에서도 double descent가 나타남을 확인할 수 있다. 이 부분은 아직 연구가 좀더 필요하다.
Label Noise
label noise가 있는 경우 double descent가 가장 심하게 나타났지만, 이건 기본적으로 label noise가 아닌 model mis-specification 문제이다.
noise가 추가되는 건 distribution이 더 학습에 어려워진다는 의미이고, model이 이를 제대로 예측할 방법을 찾을 수가 없는 misspecification이 발생하는 것이다.
Other Notions of Model Complexity.
EMC는 기존의 complexity measutre인 Rademacher complexity와 유사하지만 아래 차이가 있다.
- EMC는 데이터 분포의 true label에 의존성을 갖고 있다.
- EMC는 단순히 모델 구조뿐 아니라 학습 과정 전반에 의존성을 갖고 있다.
