[논문리뷰] Empowering Long-tail Item Recommendation through Cross Decoupling Network (CDN) 요약
추천시스템
목록 보기
3/6
들어가며
- KDD 2023
- google brain이 작성한 논문
- 추천 시스템에서 빈번하게 발생하는 long tail 문제를 해결하고자 한다.
0. Abstract
- 추천 시스템은 일반적으로 소수의 아이템이 대부분의 사용자 피드백을 받는 매우 왜곡된 longtail 아이템 분포를 갖는다. 이로 인해 사용자와의 상호작용이 적은 아이템군에 대해서는 추천 성능이 떨어진다.
- 이러한 longtail 문제를 해결하기 위한 기존 학계의 연구는 현업에 적용되긴 힘든 경우가 많았다.
- 가장 큰 문제는 이를 해결하면 오히려 전체 모델의 성능은 떨어진다는 것과, 학습 및 배포가 어렵다는 점이었다.
- 이 논문에서는 전체 성능은 유지하면서 학습/배포가 쉬운 longtail 문제 해결법을 찾고자 하였다.
- 이를 위해 먼저 longtail 분포 하에서 사용자 선호를 예측하는 경우 편향(bias)이 발생함을 보인다. 이러한 편향은 학습 시점과 서빙 시점에 모델이 받는 데이터가 크게 두 측면에서 차이가 있기 때문에 발생한다.
- 아이템의 분포가 다르다.
- 아이템이 주어졌을 때 사용자의 선호가 다르다.
- 대부분의 연구는 아이템 분포의 차이에 집중하면서 사용자의 선호가 다름은 무시한다. 이를 통해 기존 연구들은 suboptimal로 수렴하게 된다.
- 이 문제를 해결하기 위해
Cross Decoupling Network(CDN)을 개발하여 위의 두 측면에서의 차이를 줄이고자 하였다.- mixture-of-expert 구조를 활용하여 아이템 학습 중에 memorization/generalization 두 과정을 따로 구분한다.
- 정규화된 양방향 네트워크(
regularized bilateral branch network)를 활용하여 서로 다른 분포에서 발생한 사용자 표본들을 분리한다. - 새로운 어댑터를 활용하여 위에서 분리했던 벡터들을 합치고 자연스럽게 학습 과정의 attention을 낮은 빈도의 아이템(tail item)으로 옮긴다.
- CDN은 여러 벤치마크 데이터셋에서 SOTA를 이겼다. 또한 구글의 대규모 추천시스템에 실제 적용한 예시도 공유한다.
1. Introduction
- 현업의 추천 시스템에서 사용자와 상호작용하는 아이템의 분포는 longtail 분포를 따른다. 즉, 소수의 아이템(head items)이 사용자의 관심의 대부분을 차지하며, 나머지 아이템(tail item)이 매우 적은 상호작용을 하게 된다.
- 이러한 추천 로그 데이터를 사용하여 모델은 다시 학습되기 때문에, 빈익빈부익부가 발생하게 되며, 장기적으론 사용자의 만족도를 떨어뜨리게 된다.
- 따라서 이를 해결하는 것이 현업 추천 모델의 중요한 관심사이다.
logQ 보정법(correciton),재표본추출(re-sampling)과 같이 이러한 longtail 분포의 문제를 해결하기 위한 성공적인 방법들이 기존에도 제안되어 왔다. 하지만 현업에서 그 이상의 개선은 여러 이유로 제한적이었다.- long-tail 아이템에 대한 성능 개선은 인기 아이템(head items)와 전체 추천 시스템의 성능을 손상시켰고, 비즈니스 지표 하락으로까지 연결될 수 있었다.
- 현업의 추천 모델은 실시간 추론(realtime inference)이므로 매우 엄격한 레이턴시 제약이 있다. 따라서 서빙하기에 너무 시간이 오래 걸리는 복잡한 방법은 사용이 불가하다.
- 현업 모델은 적용 및 유지 보수의 편의성을 위해 간단 명료한 것을 선호한다.
- 위와 같은 이유들로 meta-learning, transfer learning 등은 사용이 힘들다.
- 이 논문은 비인기 아이템(tail item)에 대한 추천 성능을 개선함과 동시에 전체 추천 성능은 유지하며, 학습/서빙이 용이한 방법론을 제안한다.
- 이를 위해 최근 컴퓨터 비젼에서 사용되는 방법론(Decoupling representation and classifier for long-tailed recognition. ICLR (2020))을 사용한다. 해당 논문에선
representation learning과classification learning이 필요로 하는 데이터의 분포가 다르다는 것을 보였다. 하지만 기존 모델들은 이러한 모델 파라미터의 decoupling의 필요성을 고려하지 않았다. - 위 논문에서 제안되는 모델은 아래와 같은 2-stage decoupling 학습 전략을 제안한다.
- 원래의 long-tail 분포를 갖는 데이터를 활용하여 item representation learning 수행
- re-balanced 데이터를 활용하여 tail item에 대한 예측 성능 개선
- 하지만 이를 추천에 실제로 적용해보니 망각 문제(forgetting issue)가 발생했다. 즉, 첫 단계에서 학습된 아이템(특히 head item)에 대한 정보가 두번째 단계에서 다른 아이템에 좀더 집중하면서(특히 tail item) 잊혀지는 현상이 생겼다.
- 이와 더불어 2단계 학습 방법은 실제 적용사례에서 한 번만 학습하는 것에 비해 번거롭다.
- 이를 반영하여 실제 대규모 추천시스템에 적용가능한 decoupling 방법론을 제안하고자 한다.
- 이를 위해 최근 컴퓨터 비젼에서 사용되는 방법론(Decoupling representation and classifier for long-tailed recognition. ICLR (2020))을 사용한다. 해당 논문에선
- decoupling 방법론은 전체 추천 성능을 떨어뜨릴 수 있으며, 이 논문은 그 이유를 이론적으로 분석해보았다. 결과적으로, 사용자의 아이템에 대한 선호가 편향되어있다는 것을 확인하였다. 이러한 편향은 학습시점/서빙시점 데이터가 두 가지 측면에서 서로 다르기 때문에 발생하였다.
- 아이템 분포 - 대부분의 기존 모델들이 다루는 부분
- 주어진 아이템 하에서의 사용자 선호 - 기존엔 주로 무시되었고 이 논문에선 중점적으로 다루는 부분
- 위 모든 이론적 깨달음을 바탕으로 Cross Decoupling Network(CDN)을 제안한다. 아이템과 사용자 두 가지 측면 모두에 decoupling을 적용하는 방법론이다.
- 아이템 측면
- 위에서 tail item을 학습하는 2단계 시점에 head item에 대한 기존 학습을 망각하는 것이 문제라고 말했다. 즉, tail item으로 일반화(
generalization)하는 시점에 head item에 대한 정보를 기억(memorization) 하는 것이 중요하다. - 따라서 item representation 시에
generalization과memorizationexpert를 따로 두고, 그에 필요한 feature 역시 따로 사용한다. 이를 등장 빈도 기반의 gating을 활용하여 결합한다. - 위와 같은 mixture-of-expert 구조를 활용하여
memorization/generalization균형을 유지한다.
- 위에서 tail item을 학습하는 2단계 시점에 head item에 대한 기존 학습을 망각하는 것이 문제라고 말했다. 즉, tail item으로 일반화(
- 사용자 측면
- 정규화된 양방향 네트워크(
bilateral branch network)를 활용하여 두 개의 서로 다른 분포로부터 나온 표본을 학습한다.main branch: 기존 분포를 그대로 학습하여 고품질의 representation learning을 수행regularizer branch: tail item 정보를 좀더 학습하기 위한 re-balanced 분포를 학습
- 위 두 브랜치는 일부 레이어를 공유하여 동시에 학습되며, 이를 통해 망각 문제를 해결한다.
- 정규화된 양방향 네트워크(
- -adapter
- 위의 아이템 측면/사용자 측면에서 학습된 벡터를 합치는 역할
- 파라미터를 조절하여 tail item에 얼마나 더 집중할지 조절.
- 아이템 측면
- CDN은 tail item에 대한 성능을 높이면서 전체 추천 성능을 유지한다. 또한 동시 학습 방법이기 때문에 학습/유지보수가 쉽다. 이 논문의 기여는 아래 네 가지이다.
- long-tail 분포가 아이템/사용자 두 측면에서 어떻게 추천 성능을 낮추는지 이론적 분석
- CDN 방법론을 제안
- CDN이 성능이 좋음을 실제 데이터셋에서 보임
- CDN을 실제 구글의 대규모 추천 시스템에 적용. online/offline 모두에서 개선됨을 보임
2. LONG-TAIL DISTRIBUTION IN RECOMMENDATION AND MOTIVATION
Problem Settings
- 사용자의 long-tail 아이템에 대한 반응(click, install 등)을 예측하는 것이 목표
- notation
- 사용자의 각 아이템에 대한 클릭(긍정반응 그냥 편하게 이렇게 쓰겠음.) 빈도 는 long-tail 분포를 갖는다.
- 아이템이 받는 관심에 대한 불균형을 평가하기 위한 지표로
imbalance factor(IF)를 사용한다.- IF:
- 현업의 경우, 아이템의 IF는 매우 크며, 100000 이상으로 커지기도 한다.
- 아이템이 받는 관심에 대한 불균형을 평가하기 위한 지표로
Theoretical Analysis and Model Design Motivations
- long-tail 분포의 영향이 두 가지 관점에서 발생함을 베이즈 정리를 바탕으로 이해해볼 수 있다.
- 학습과 서빙 데이터에서 아이템 분포의 불일치: 훈련 데이터와 서빙 데이터 세트 간의 아이템 분포가 다른 경우가 많으며(a.k.a training / serving skew), 이를 아이템 사전 확률(prior probability)
p(i)의 불일치라고 한다. 이로 인해 모델이 학습 데이터에 잘 맞더라도 서빙 데이터에 대해서는 큰 편향이 발생한다. - 훈련 데이터와 서비스 데이터 간의 항목별 사용자 선호도 불일치: 롱테일 분포 하에서 추정된 사용자의 선호는 편향될 수 있으며, 이를 조건부 확률(conditional probability)
p(u|i)의 불일치라고 한다. 특히 훈련 데이터가 부족하여 과소 적합되는 long-tail 아이템에 대해 이러한 경향이 더 높으며, 이는 학습 데이터와 서빙 데이터 모두에 대해 편향을 유발한다.
- 학습과 서빙 데이터에서 아이템 분포의 불일치: 훈련 데이터와 서빙 데이터 세트 간의 아이템 분포가 다른 경우가 많으며(a.k.a training / serving skew), 이를 아이템 사전 확률(prior probability)
- 추천시스템의 목표는 사용자 u의 아이템 i에 대한 선호를 가깝게 추정하는 것이며, 일반적으로 선호는 softmax로 나타낸다.
- s(u,i)는 사용자 u의 아이템 i에 대한 실제 선호이며, user embedding과 item embedding의 내적으로 구해진다.
- 베이즈 정리를 활용하여 학습 데이터를 기반으로 를 아래처럼 구할 수 있다.
- , 는 long-tail 학습 데이터(즉 그냥 본연의 데이터)를 학습하여 추정한 확률이다.
- 가 실제 값 에 근사하기 위해서는 prior와 conditional probability가 실제 분포에 근사해야한다. 즉, ,
3. Cross Decoupling Network
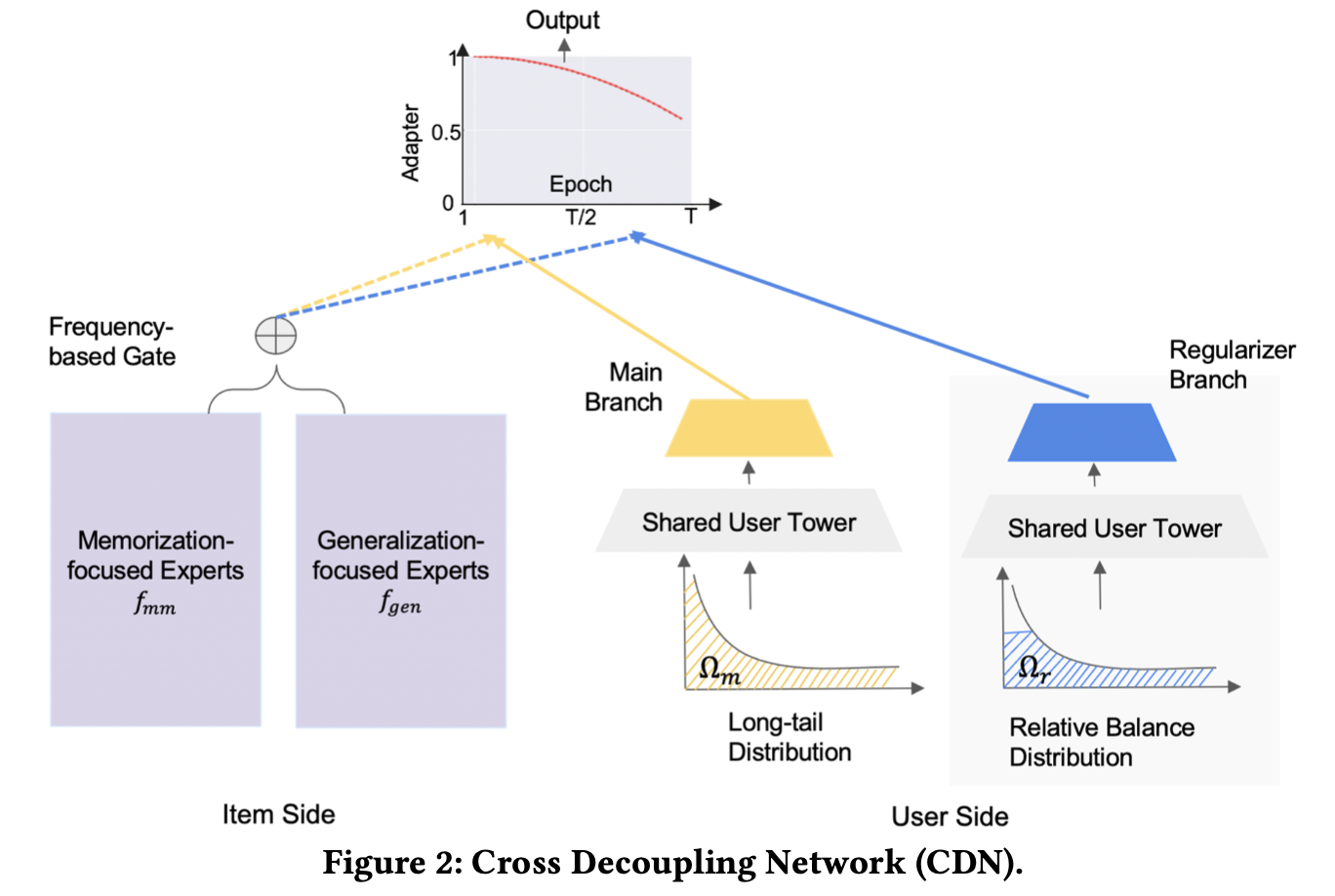
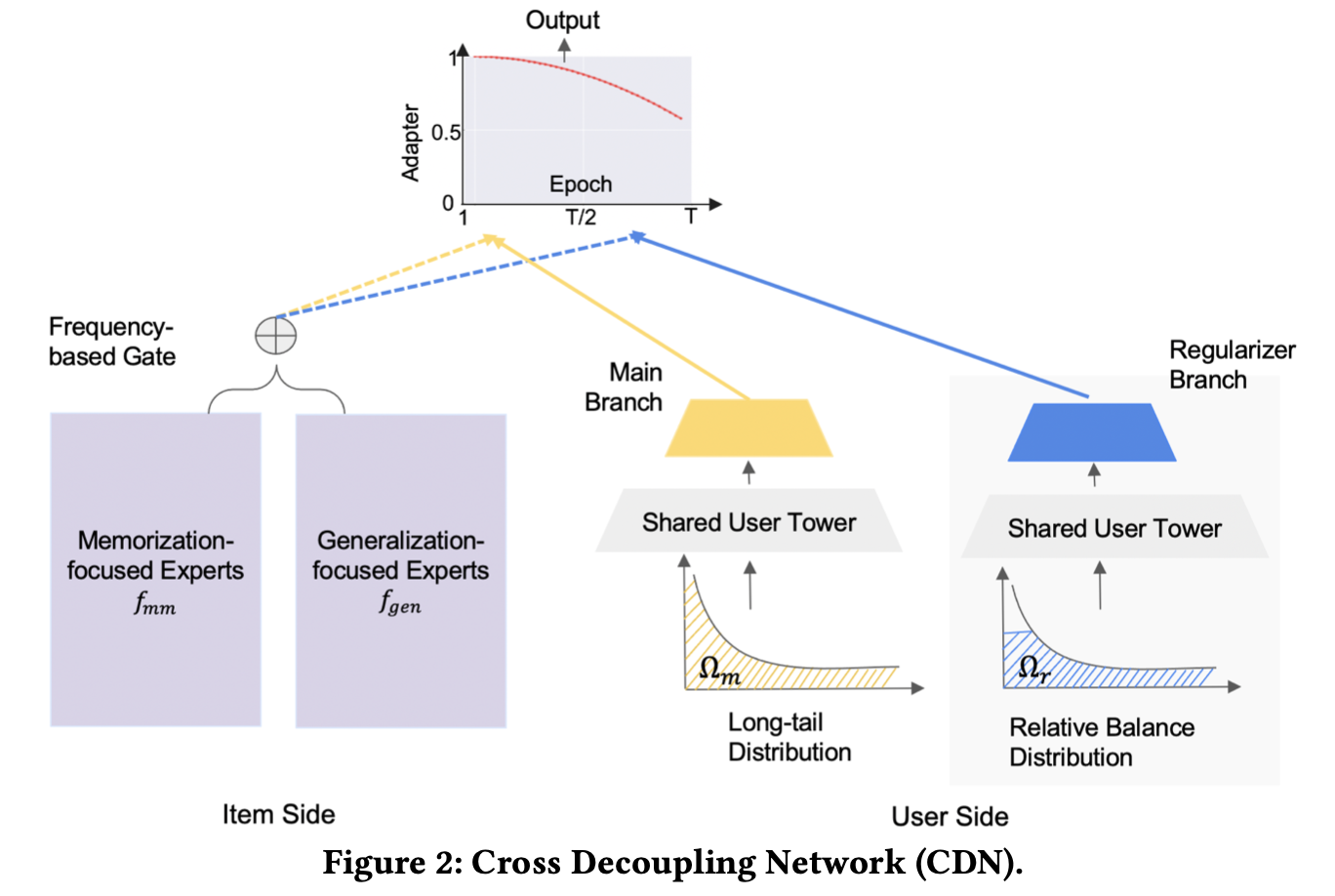
- 아이템 측면
- memorization(head item)과 generalization(tail item)을 분리하여 representation learning 수행. 이를 위해
gated mixture of expert(MOE)모델을 활용한다. - memorization expert에는 그와 관련된 피쳐를, generalization expert에는 content 피쳐를 넣어준다. 최종 gate는 item representation을 위해 memorization과 generalization expert 간의 weight를 조절한다.
- memorization(head item)과 generalization(tail item)을 분리하여 representation learning 수행. 이를 위해
- 사용자 측면
- 사용자 샘플링 방식을 조절하기 위한
bilateral branch network- main branch: 전체 사용자의 선호를 학습
- regularizer branch: 사용자의 tail item에 대한 적은 반응을 보정함
- 사용자 샘플링 방식을 조절하기 위한
- -adapter
- 사용자와 item으로 부터 얻은 결과를 교차합한다. 이를 통해 long tail 분포 하에서 사용자의 head/tail item에 대한 선호를 알 수 있다.
3-1. Item Memorization and Generalization decoupling
3-1-1. Features for memorization and generalization
- 일반적인 산업 추천 시스템은 수백개의 피쳐를 모델 인풋으로 사용한다. 이걸 일단 memorization과 generalization 두 종류의 피쳐로 분류해본다.
- Memorization features
- 학습 데이터에 존재하는 사용자와 아이템 간의 상호작용을 기억하도록 돕는다(e.g. 아이템 ID). 대체로 이러한 피쳐는 아래 조건을 만족하는 범주형 변수들이다.
Uniqueness- feature space 에 대하여 를 만족하는 일대일 함수(injective function) 이 존재한다.
Independence- 에 대하여 의 변화는 에 영향을 주지 않는다.
- 한 마디로 아이템 각자와 일대일 매핑이 되고, 서로 간에 독립적인 범주형 변수이므로, 위에 언급한 것처럼 ID 형태가 가장 적합할 것이다. 이러한 feature들은 실제 사용시 일반적으로 임베딩 형태로 사용된다.
- 임베딩 벡터는 각 아이템에만 대응되며 다른 아이템의 임베딩과는 정보 공유가 안 되므로 memorization에 적합한 feature이다.
- 한편으론 본적 없는 다른 아이템에 기존 아이템의 벡터를 사용할 수 없다.
- 위의 Uniqueness + Independence 특성을 가진 feature가 long tail 분포를 더 강화시킨다고 볼 수도 있을 것이다. 이들은 parameter가 적게 업데이트 되며, 다른 아이템의 해당 feature에서 얻어오는 정보도 없기 때문이다.
- 학습 데이터에 존재하는 사용자와 아이템 간의 상호작용을 기억하도록 돕는다(e.g. 아이템 ID). 대체로 이러한 피쳐는 아래 조건을 만족하는 범주형 변수들이다.
- Generalization features
- 사용자의 선호와 아이템 feature 간의 상관 관계를 학습할 수 있는 피쳐들이다.
- 서로 다른 아이템 간에 정보를 공유할 수 있도록 한다(e.g. 아이템 카테고리)
- 따라서 기존에 보지 못한 아이템들에 대해서 일반화시킬 수 있으며, 결과적으로 tail item에 대한 representation learning을 돕는다.
3-1-2. Item representation learning
- mixture of expert(MOE) 구조를 활용, 빈도수 기반의 gating을 활용하여 memorization과 generalization 피쳐를 분리한다.
- 학습 샘플 (u,i)가 주어졌을 때, item embedding은 아래와 같이 구해진다.
- : memorization 역할을 하는 experts. input으로 위에 설명한 memorization 피쳐 를 받음
- : generalization 역할을 하는 experts. input으로 위에 설명한 generalization 피쳐 를 받음
- : gating function. 는 이것의 k번째 성분을 의미한다. 즉
- gate는 item 에 대응됨에 주의
- gating은 동적으로 memorization 과 generalization 간에 균형을 조절하도록 사용될 수 있다. 가장 직관적인 방법으론, item 의 등장 빈도를 input으로 사용하는 방법이 있을 것이다.
- , 는 학습되는 행렬
- 그 외에 다른 feature도 넣어줄 수 있으며, 실험적으로 아이템 인기도를 넣어주는 것이 도움이 되었다.
- 제안되는 decoupling 방법은 long-tail 분포 하에서 head item은 더 오래 기억되도록, tail item은 더 일반화되도록 하는 임베딩을 만들 수 있으며, 이러한 서로 다른 목표를 동시에 달성하여 전체 성능을 높인다.
- 위를 통해 개선된 item representation learning은 와 간의 차이를 줄이는데 도움을 준다.
- 또한 memorization expert를 명시적으로 둠으로서, tail item만 추가로 학습하는 기존의 방법론보다 forgetting 문제가 적다.
3.2 User Sample Decoupling
regularized bilateral branch network제안(figure 2 우측)main branch: 기존의 skewed된 long-tail 분포() 사용하여 학습. 즉 전체 데이터가 사용됨.regularizer branch: 상대적으로 균형을 좀더 맞춘 분포() 사용하여 학습. 즉 일부 head item 관련 로그와 전체 tail item 관련 로그가 사용됨.- head item 샘플링 시에는, 평균적으로 가장 높은 빈도의 tail item 정도의 빈도를 가지도록 조절.
- shared tower를 통해 두 branch 간의 양을 조절함.
- 학습 과정은 아래와 같다.
- 매 학습 스텝마다 , 두 샘플이 각각 main/regularizer 브랜치로 들어간다.
- 위를 통해 user representation vector , 를 구한다.
- 이때, f(.)는 공유되는 레이어고, 는 각자 갖는 레이어다.
- 각 브랜치의 역할은 아래와 같다.
main branch는 기존의 분포의 특성을 그대로 학습하여 user representation을 생성하며, 이는 regularizer branch가 학습을 하는 데에 일종의 초석이 된다.regularizer branch는 tail item의 정보를 좀더 모델에 반영할 수 있도록 하며, 그 와중에도 모델이 tail item에만 너무 집중하지 않도록 regularized adapter를 이용하여 조절한다.- 위 두 브랜치는 동시에 학습된다. 또한 서빙 시점에는 main branch만 사용된다.
3.3 Cross Learning
-
head item과 tail item 간의 격차를 줄이기 위해 앞서 user/item 에서 각각 분리(decouple)해둔 정보들을 -adapter`를 이용하여 교차 학습한다.
- -adapter는 기존에 학습한 정보들을 융합하며, tail item에 대한 추가적인 학습을 돕는다.
- bilateral branch에서 얻어진 user embedding 과 이를 이용하여 얻어진 item embedding를 사용하여 아래처럼 다시 쓸 수 있다.4
- 위에서 는 -adapter 이며, 매 epoch t마다 업데이트된다. T는 총 epoch수, 는 정규화 파라미터
- epoch이 늘어남에 따라 t는 증가하기 때문에, 처음에는 전체적인 정보를 위주로 학습하고 시간이 지날 수록 tail item에 집중된 정보를 학습한다.
- 가 1보다 크기 때문에 main branch는 언제나 학습의 대상은 되며 이에 따라 forgetting 문제가 줄어든다.
-
위에서 얻어진 logit 를 이용하여 아래와 같은 사용자의 전체 item에 대한 선호를 softmax로 구할 수 있다.
-
실제 적용시에는 아이템 수가 매우 크므로 batch softmax를 사용한다.
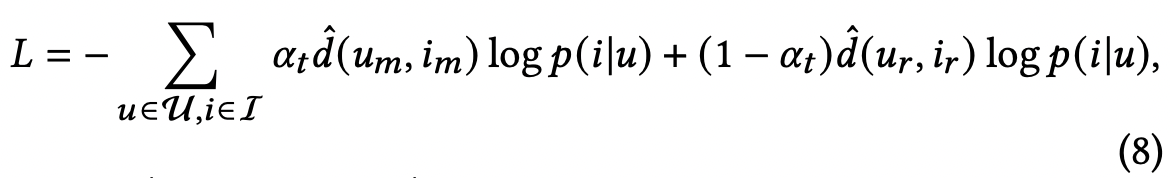
- 은 main/regularizer branch에서 나온 user feedback이다. 즉, 같은 아이템에 대해 여러 다른 반응이 있었을 수 있으니, 그걸 결합하기 위함이다.
-
서빙 시점에는 main branch의 추정량만 이용해서 softmax를 구한다. 즉 위의 는 학습 시점에만 사용되고, 서빙 시점에는 를 사용한다.
regularizer branch는 train 시점 데이터에 대해서 정규화된 것이기 때문에 test 시점의 분포와는 또 다르므로 이를 사용하면 또 다른 편향이 발생하기 때문이다.
-
-
CDN은 위에서 볼 수 있듯이 추가적인 연산이 적고, 특히 서빙시점은 기존의 모델과 동일하다.
4. Experiment
- 6가지 실험 수행
- RQ1: 기존의 decoupling sota 대비 CDN이 얼마나 성능이 좋은지
- RQ2: CDN이 사용자/아이템 각각에 어떤 식으로 작동하는지
- RQ3: MOE의 구성요소인 expert, gating이 성능 및 tail/head 균형에 어떤 영향을 미치는지
- RQ4: -adapter`의 영향
- RQ5: 실제로 tail item 벡터가 잘 학습되고 있는지
- RQ6: CDN의 실제 적용
4-1. Experimental Setup
- Dataset
- public
- MovieLens 1M
- BookCrossing
- production
- 구글 앱 광고 설치 로그 데이터
- 다섯번 독립 시행 후 평균과 표준편차로 평가
- public
- Evaluation Criteria
- Hit Ratio at top K (HR@K): 등장 여부 평가용
- NDCG at top K (NDCG@K): 등장 순위 평가용
- head/tail 분리 기준
- Pareto 기준사용
- MovieLens1M: 상위 20% 아이템
- BookCrossing: 0.1% 아이템
- Baselines
- Two-tower Model
- 비슷한 학습/서빙 시간을 가지고 있고 동일한 two-tower 형식임.
- scalable하고 efficient함.
- Re-balance stratigies
- user 측면에선 re-balancing이 들어가니 이를 비교하기 위함
- ClassBalance
- 불균형된 class에 대해 적합한 표본 갯수를 계산하고 이를 loss function의 가중치로 사용한다.
- LogQ
- 아이템 등장 빈도와 관련된 변수를 만들어서 softmax logit을 조절하며, 이를 통해 학습 과정에서 head/tail item의 가중치를 조절한다.
- Decoupling
- NDP
- 컴퓨터 비전 쪽에서 long-tail 문제를 해결하기 위한 모델로 최근 sota이다. 이미지 분류에 사용되던 것을 추천 용도로 개선했다.
- Bilateral-Branch Network(BBN)
- 마찬가지로 branch가 두 개인데 대신 uniform 샘플링 + reversed sampling을 사용한다.
- 추정컨데 reversed가 빈도의 역수에 비례하는 것으로 보이니, CDN보다 tail에 좀더 많이 집중될 것으로 보임.
- NDP
- Two-tower Model
4-2. Recommendation Performance(RQ1)
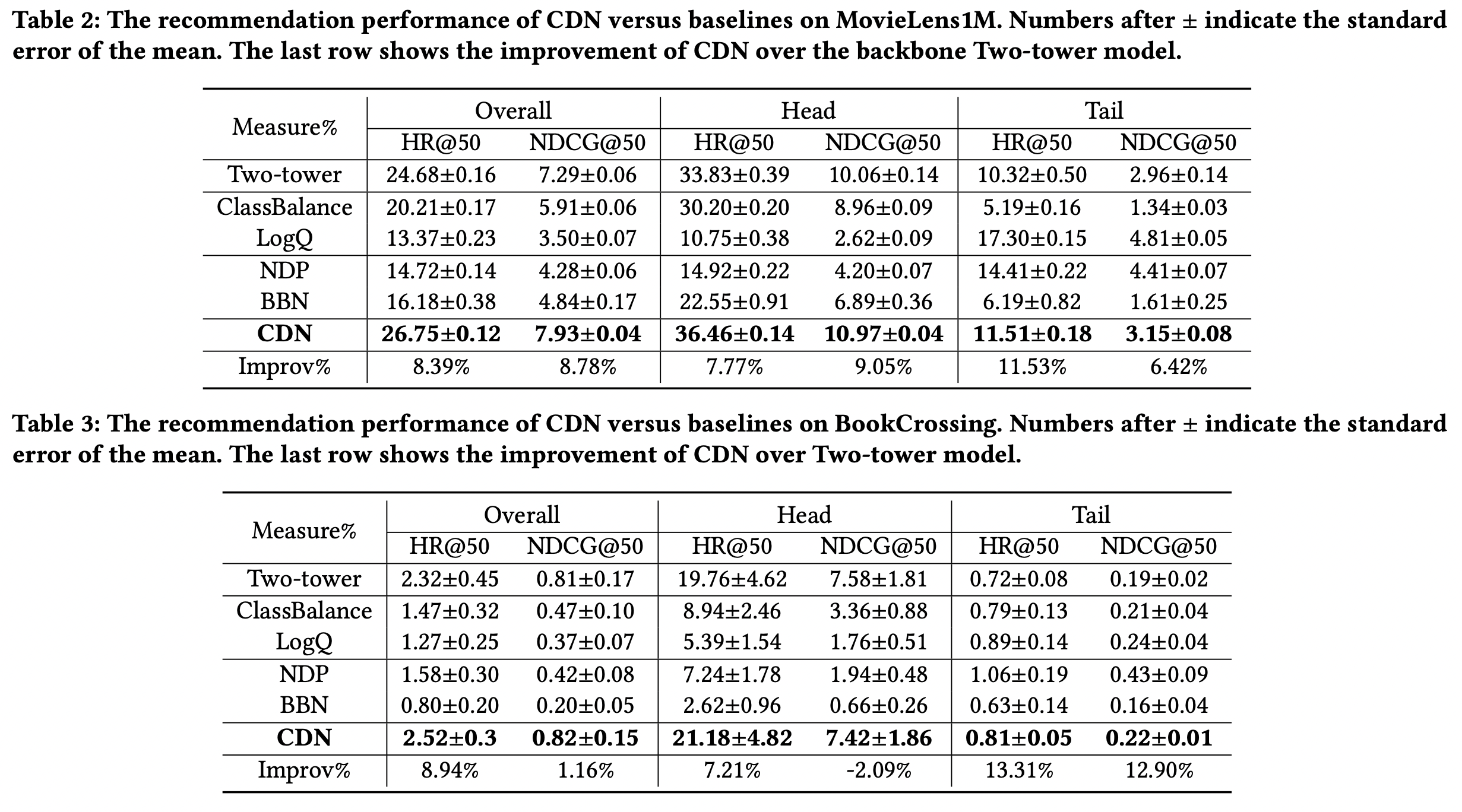
CDN성능이 제일 좋으며, tail 뿐만 아니라 head item에 대한 성능도 올라갔다. 대부분의 다른 방법은 tail에서 상승하면 head는 감소하였다. 즉, tail에 집중하면 head 성능이 떨어지는 게 일반적이다.NDP는 decoupling을 2-stage 방식으로 수행하는데, 이때문에 forgetting 문제가 커서 head의 성능이 CDN 보다도 높았으나, head 에서의 성능이 매우 떨어졌다.BBN은 head/tail 모두에서 성능이 감소하였다. 이는 BBN이 위에 설명하였듯 uniform 샘플링이 가장 중점적으로 사용되는데 현실에서는 inference시에 만나는 데이터도 불균형하기 때문에 추천시스템에서의 현실과 동떨어졌기 때문으로 보인다.CDN은 이와 달리BBN의 uniform에 해당하는 regularized 분포를 부수적으로 사용하고 원본 데이터 분포를 main branch에 놔두기 때문에 훨씬 현실에 적합하다.- 또한 이때문인지
CDN은 평균 성능의 표준편차가 작다. 이는 tail item에 대한 오버피팅이 적어진 것이 원인으로 생각된다.
4-3. Cross-Decoupling(RQ2)
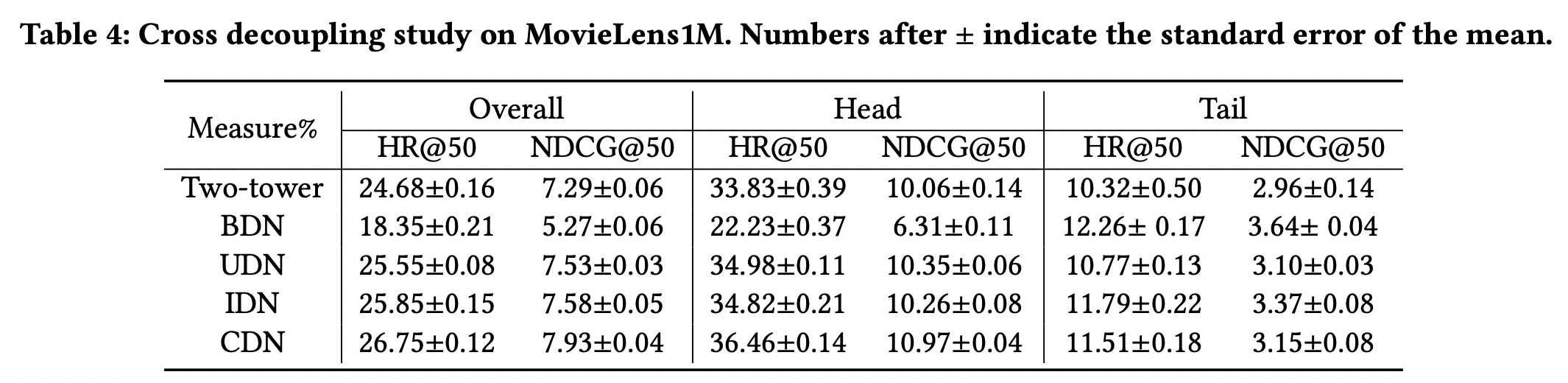
- ablation study
BDN: main/regularizer branch 결합시 사용하는 제거UDN: user만 decouple, item 쪽의 memorization/generalization 제거IDN: item만 decouple.
BDN을 제외하고는 모두 baseline 대비 성능 상승- skewed 분포에 대한 집중은 원본 데이터와 균형을 잘 맞춰서 학습하는 것이 중요하다.
4-4. Comparison of Expert Design (RQ3)
- memorization/generalization의 분리가 head/tail item의 다른 특성을 잘 추출해내는가
- 다른 두 가지 모델과 비교함. 각 레이어는 원래처럼 expert + gating의 moe구조 활용
- user쪽과 비슷하게 balanced/unbalanced 두 데이터로 분리 학습
- balanced만 학습하는 expert + unbalanced만 학습하는 expert
- head/tail 데이터 분리 학습
- head expert 따로, tail expert 따로 해서 gating 한다는데, 이건 애초에 서로 item set이 겹지치 않게 될 것 같은데 왜 gating 하는지 의문.
- user쪽과 비슷하게 balanced/unbalanced 두 데이터로 분리 학습
- 다른 두 가지 모델과 비교함. 각 레이어는 원래처럼 expert + gating의 moe구조 활용
4-4-1 Recommendation performance
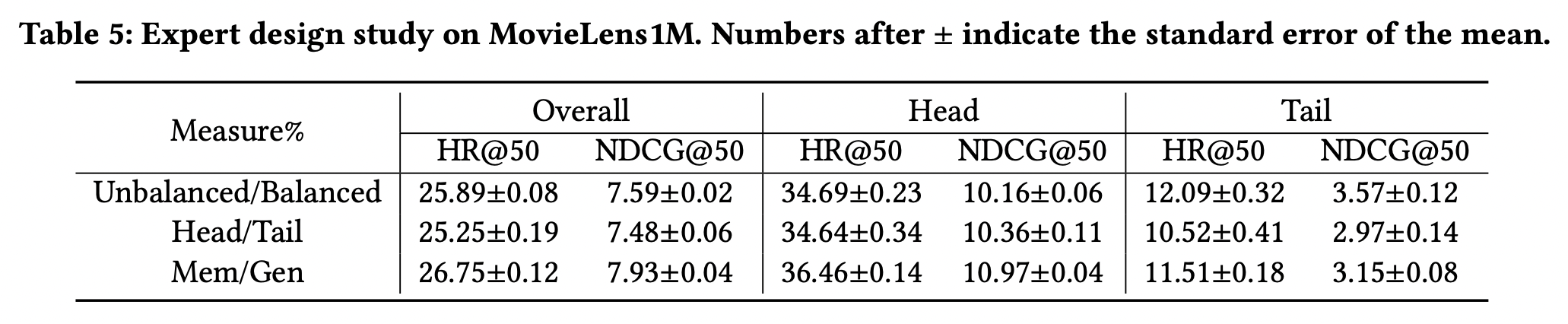
- 4-3의 table4에 나오는 UDN에 item쪽의 변경을 추가했다고 생각하면 됨.
- Head/Tail 방법은 UDN에 추가적인 item 연산이 들어가는 형태인데도 tail 성능이 떨어짐 → tail에 너무 오버피팅 되어 test 성능이 떨어지는 것으로 추정.
- 즉, 명시적으로 head/tail을 나눠서 학습하는 것보다 mem/gen으로 역할을 나눠서 학습하는 게 낫다.
4-4-2. Memorization vs Generalization

- head item은 memorization expert에 대한 gate 비중이 더 높고, tail item은 generalization에 대한 비중이 더 높다. 따라서 우리가 의도한 대로 moe가 역할을 하고 있음을 확인할 수 있다.
- generalization이 memorization보다 모든 아이템에 대해 비중이 더 높다. 이는 보통 추천 데이터셋이 아이템이 매우 많으며 기본적으로 반응이 sparse 하기 때문에 일반화를 더 많이 해야하기 때문이다.
- 그럼에도 head item은 상대적으로 tail보다 로그가 많기 때문에 memorization 좀더 수월한 것.
4-5. -Adapter (RQ4)
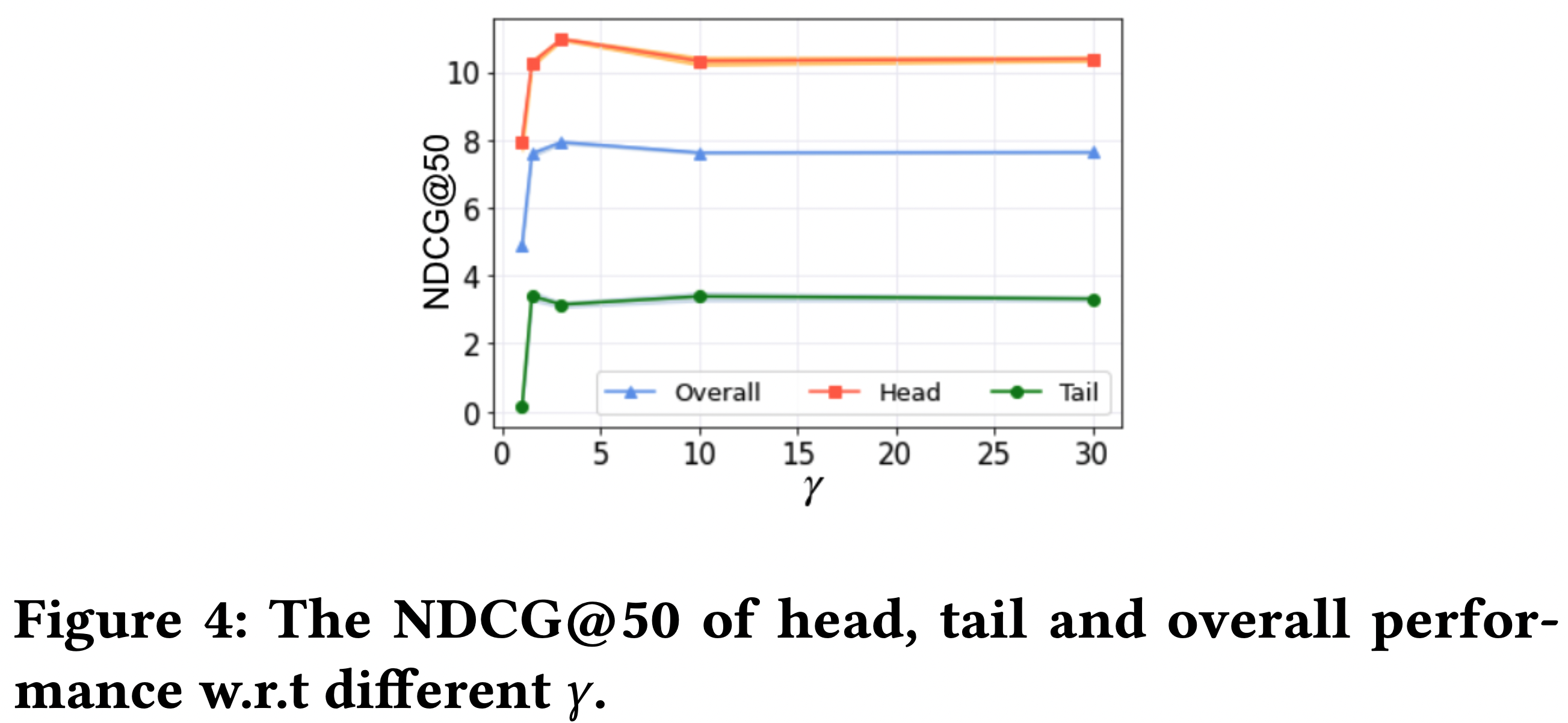
- 위에 언급한 대로 어댑터 함수의 가중치 조절 속도에 영향을 주며, 가중치 하한의 역할도 한다.
- 가 커질 수록 main branch에 가중치가 높아진다.
- 가 5보다 작을 때 를 증가시키면 성능이 증가한다.
- 즉, main branch를 1순위로 고려해야하며, regularizer 브랜치는 말 그대로 regularizer로, 조미료 같은 것이다.
- 그렇다고 를 계속 증가시켜도 성능은 상한이 있다. 특히 tail item은 를 증가시킬 수록 성능이 떨어진다. → regularizer branch가 필요는 하다.
4-6. Representation Visualization (RQ5)
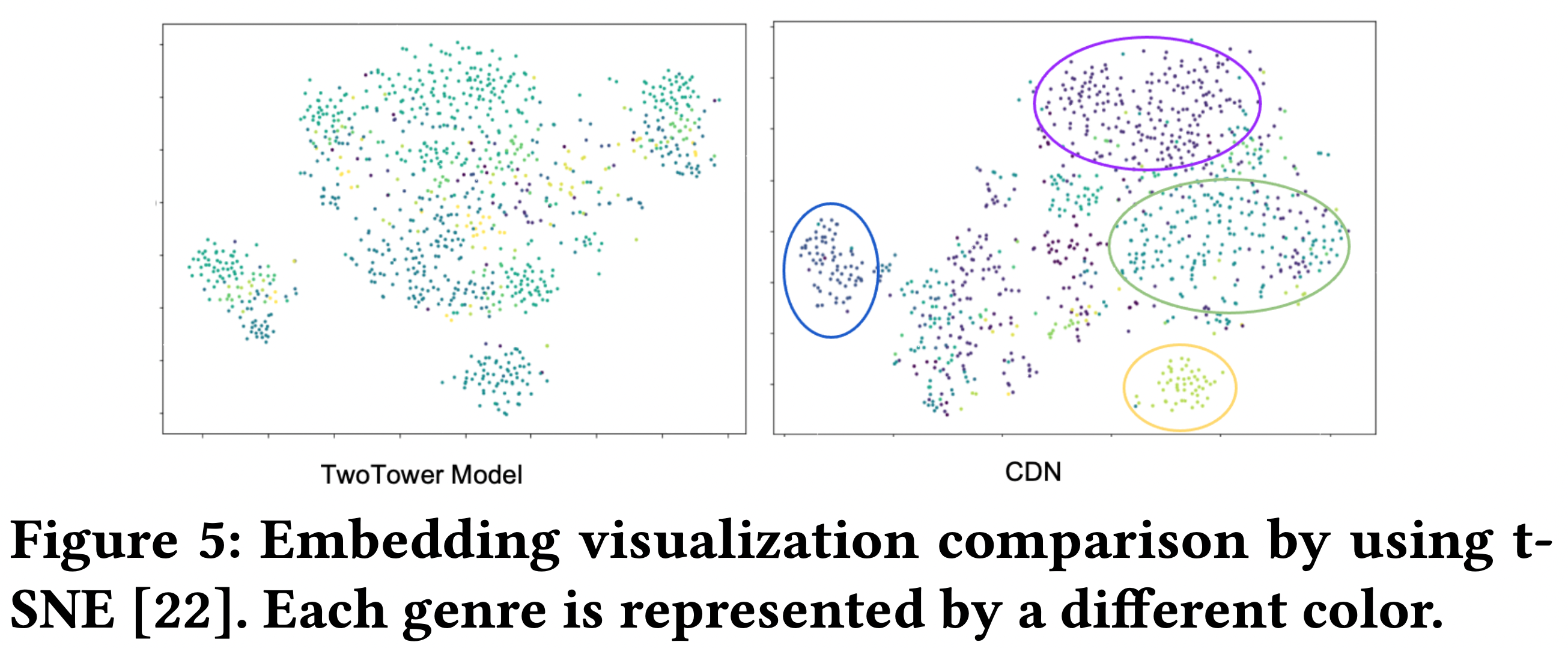
- CDN 과 baseline의 embedding 공간 비교
- CDN이 같은 장르의 영화끼리 군집을 잘 이루는 것을 확인 가능
4-7. Experiments in a Google System(RQ6)

- 현실 데이터에 적용해봤을 때 현업의 scale과 제약사항에 잘 맞는 걸 확인했고, offline/online A/B test에서 좋은 성능을 보였다.
- 사용자가 해당 앱을 설치할 가능성을 추정하는 문제였다.
- 용어 설명
- Dense/Sparse: 위에서 head/tail로 나오던 것으로 생각하면 됨. 해당 서비스 기준으로 기존 head/tail과 나누는 기준이 좀 달라져서 이렇게 명시함
- AUCLoss = 1-AUC
- 해당 서비스에선 0.1% 상승이면 큰 상승으로 간주된다고 함.
5. Related Work
- Long-tail Problem
- 기존 접근은 resampling/reweighting을 활용한 resampling이 대부분이었으며, 이는 tail item에서의 성능 상승에만 집중하여 head item은 상대적으로 무시되었다.
- 최근 연구에서는 이러한 rebalancing이 head item의 embedding에 대한 왜곡을 유발함을 보였다.
- 대부분의 연구는 컴퓨터 비전쪽에서 많았고, 추천쪽은 잘 없었다.
- 그나마 meta-learning을 활용하는 방법이 추천쪽에서 제안되었고 성능은 좋았으나, 막상 해보니 학습 시간이 실제 서비스 제약 기준보다 2배나 더 걸렸다.
- 또한 기존에는 tail item에 대한 성능을 올리기 위해 cold-start 문제를 해결하는 방식으로 가고자 했으나, 이는 이 논문에서 수행한 long-tail 분포 문제와는 조금 결이 다르다. long-tail 분포를 가지는 데이터에서 long-tail 아이템에 대한 성능을 높임과 동시에 head item의 성능은 유지되어야 하는 것이다.
- 기존 접근은 resampling/reweighting을 활용한 resampling이 대부분이었으며, 이는 tail item에서의 성능 상승에만 집중하여 head item은 상대적으로 무시되었다.
- Memorization and Generalization
- 그간 memorizing은 모델 성능에 필수적인 것으로 연구되어 왔다. 최근에는 generalization이 큰 관심을 받고 있고 대표적으로 meta-learning과, reinforcement learning에서 그 관심이 크다.
- 연구들을 보면 generalization은 sparse 데이터 혹은 불충분한 데이터 상황에서 중요하다고 한다.
- 모델이 얼마나 잘 generalize 하는가는 모델의 구조와 관련이 있으며, wide and deep 이 대표적으로 이를 보였다.
6. Conclusion
- CDN 제안
- 현실의 long-tail 분포를 잘 적합함
- item 측면의 memorization/generalization decoupling
- user 측면의 샘플링 방법 decoupling
- adapter를 활용한 점진적인 tail item 추가 학습

메신저 회사에서 추천시스템을 개발하는 ML 엔지니어로 일했습니다. 현재는 금융권에서 다양한 분야의 모델링 및 서빙을 하는 ML Engineer로 일하며 흥미를 넓혀가고 있습니다. 추가적인 프로필은 메인에 첨부한 링크드인에서 확인해주세요.