(논문 리뷰) DeepRecSys: A System for Optimizing End-To-End At-scale Neural Recommendation Inference 설명
추천시스템

하버드와 메타가 함께 발표한 논문으로, 여러 추천 모델에 특화된 효율적인 추천 시스템을 설계하기 위한 방법론을 제안한다.
0. Abstract
- 딥러닝 기반 추천시스템의 효율화는 전체 인프라의 자원을 아끼는 데에 중요하다
- 이 논문에서는
DeepRecInfra를 제안한다- end-to-end 모델링 인프라이다.
- 알고리즘과 시스템을 결합해서 디자인할 수 있는 방법론을 제안한다.
- 추천시스템의 특성을 기반으로 동적인 스케줄러인
DeepRecSched를 제안한다- 쿼리의 크기와 요청의 패턴, 추천 모델 구조, 사용 중인 하드웨어를 분석하여 latency-bounded throughput을 최대화 할 수 있다.
- 위 과정을 거치면 여덟 개의 유명 모델에 대하여 시스템의 처리량(throughput)이 두배로 늘어난다
- 데이터 센터에서 수백대의 머신으로 design, deployment, evaluation을 거친 결과 30%의 레이턴시 감소를 확인하였다.
1. Introduction
-
추천 성능을 높이기 위해 추천 모델은 점점 복잡한 딥러닝 모델을 사용하게 되었다.
-
페이스북의 추천 시스템은 일반적인 비전이나 nlp 모델보다 inference 시에 10배의 자원을 필요로 한다.
- 모델이 커서라기 보다는, 워낙 다양한 모델이 사용되고 있고 여러 곳에 사용되고 있어서 널리 많이 쓰인다를 의미하는 것으로 보인다.
-
결과적으로 페이스북 데이터센터에서 수행되는 inference 작업 중 70% 이상은 추천/랭킹에 관련된 것이다.
-
이처럼 추천에 많은 자원을 쓰지만 추천의 아키텍쳐를 최적화하기 위한 노력은 적었다. 추천 모델은 다른 모델들과 다른 특성을 가지고 있기 때문에 그에 맞는 고유의 해결책을 요구하기 때문이다.
-
첫째로, 추천 모델은 각자 고유의 연산, 메모리, 데이터 재사용 특성을 가지고 있다.
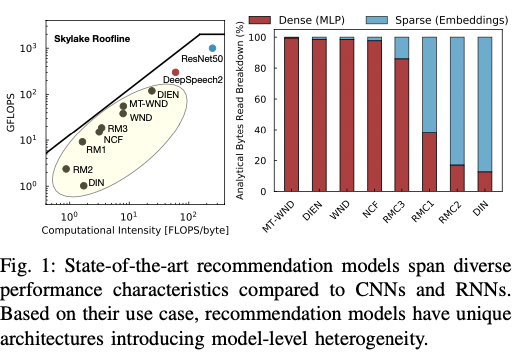
- 추천 모델들은 CNN, RNN 계열 모델에 비해 연산량은 적지만, 메모리 사용량은 더 높다. 또한, 추천 모델은 더 많은 저장 공간을 필요로 하며 불규칙한 메모리 접근 형태를 보인다.
- 위와 같은 특성의 원인은 추천 모델이 연속형 변수뿐 아니라 범주형(categorical) 변수를 사용하기 때문이다. 범주형 변수는 연속형 변수와 다른 연산을 사용하게 되며 이에 따라 추천 모델의 효율적 추론을 위해서는 새로운 시스템 구조를 디자인해야 한다.
-
둘째로, 대부분의 추천 모델은 크기가 다르며, 즉 추천 모델 간에도 차이가 존재한다. fig 1-b를 보면 각 모델별로 다른 특성을 가짐을 확인할 수 있다. 상대적으로 dense feature를 많이 가진 모델은 규칙적인 메모리 접근이 자주 일어날 것이지만 그렇지 않은 모델은 불규칙적인 메모리 접근이 일어날 것이다.
- 이처럼 모델마다도 차이가 있기 때문에 각 모델 특성에 최적화된 시스템 디자인이 필요하다.
-
마지막으로, 추천 모델은 웹서비스에 배포되기 때문에 데이터 센터에서 큰 규모로 실행되는데, 이의 영향을 고려해야한다.
- 웹 기반 서비스의 요청량(request arrival)은 포아송 분포를, 작업 집합 크기(working set size/연산을 위해 필요한 메모리 량)는 로그정규 분포를 따른다고 알려져있다.
- 추천에서도 요청량은 비슷한 분포를 따르지만 작업 집합 크기는 상대적으로 꼬리가 더 두터운(heavy tail) 분포를 따른다.
- 추천 쿼리의 이러한 특성은 대규모 추천 추론(inference)에 특화된 다양한 최적화 전략이 새롭게 필요함을 의미한다.
- 로그정규가 아닌 이런 특화된 분포에 대해 최적화하면 대규모 추천 추론의 처리량(throughput)이 1.7배 높아진다.
-
-
DeepRecInfra다양한 추천 모델에 대한 디자인 최적화를 위해 이 논문에서 제안하는 end-to-end infrastructure.
- 상업용 비디오 추천, 이커머스, 소셜 미디어를 포괄하는 8개의 최신 추천 모델에 대해 심층적인 특성 분석을 수행한다.
- 실제 프로덕션 데이터센터의 추천 서비스를 프로파일링하여 추천 쿼리를 모델링하기 위한 추론 부하 생성기(inference load generator)를 만들었다.
-
DeepRecSched추천 모델과 동적 쿼리 도착 패턴(빈도 및 크기)의 성능 특성화를 목표로 설계된 hill-climbing 기반의 스케줄러.
- 쿼리 크기와 도착 패턴, 추천 모델, 사용하는 하드웨어 플랫폼에 맞춰 쿼리를 미니 배치로 분할할 수 있다.
- 요청(request)과 batch-level 병렬화를 절충하여 엄격한 테일 레이턴시(tail latency) 아래 시스템 부하를 최대화할 수 있다.
- tail-latency는 latency의 max값 정도로 이해함.
- 특성화된 하드웨어 가속기가 어느 정도의 영향력이 있는지도 평가할 수 있다.
-
이 논문은 크게 세 가지 기여를 했다.
- 새로운 end-to-end 인프라인
DeepRecInfra를 제안한다.- 다양한 추천모델에 대한 시스템 디자인 및 최적화를 할 수 있다.
- 실제 데이터센터에서 관찰된 쿼리의 도착 및 크기에 대한 패턴을 반영하였다.
- 효과적인 scheduler인 DeepRecSched를 제안한다.
- DeepRecInfra와 결합시 특정 레이턴시 제한 아래에서 시스템 쓰루풋을 두 배로 늘릴 수 있다.
- 모든 요청 쿼리가 동일한 쿼리가 아닌 추천 추론하에서 gpu 가속기는 때로 도움이 된다. 다양한 추천 모델을 다양한 시스템 부하 및 레이턴시 제약 하에서 돌릴 때, 동적으로 최적화된 configuration을 설정할 수 있도록 하였다.
- 새로운 end-to-end 인프라인
2. Neural Recommendation Models
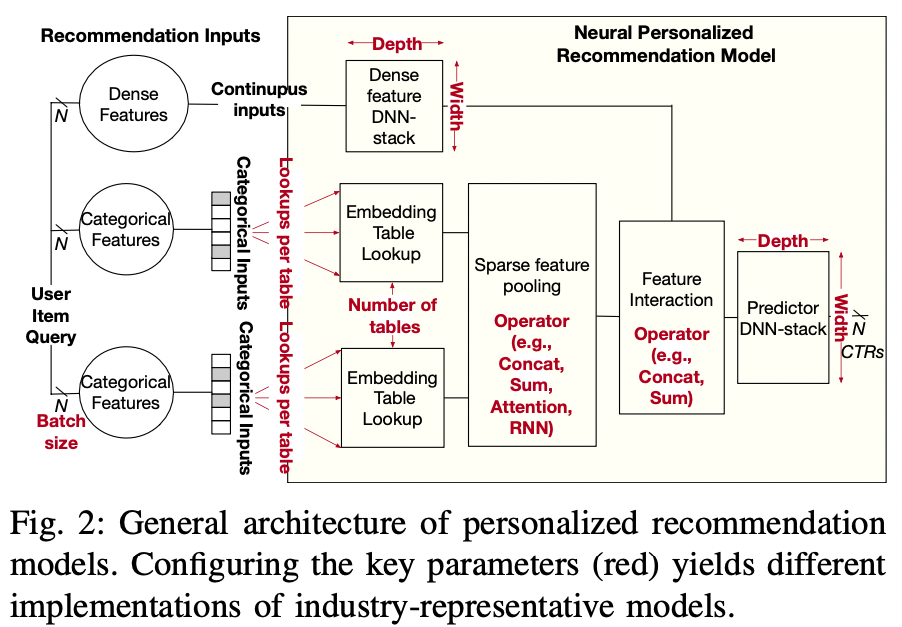
- 추천 모델들은 dense와 sparse 변수를 동시에 사용한다
2-a. Key Components in Neural Recommendation Models
- 변수(features)
- dense: 연속형 변수이며, 일반적으로 MLP 층을 쌓아서 처리한다.
- sparse: 범주형 변수이며, 사용자가 과거 구입한 아이템 등이 대표적이다. 일반적으로 긍정적인 반응은 전체 아이템 중 매우 적은 수를 차지하므로 이를 binary vector로 나타내면 매우 sparse해진다.
- 임베딩 테이블
- sparse feature에 대응되는 임베딩 테이블. 테이블의 행 수는 카테고리 갯수와 같기 때문에 수십억개까지 늘어날 수 있다.
- 임베딩 테이블은 수십 GB를 차지하는 경우가 흔하다.
- 임베딩 테이블에 대한 접근
- 임베딩 테이블 자체는 dense하지만, 이를 활용한 연산은 불규칙적인 메모리 접근을 발생시킨다.
- 일반적으로 sparse feature를 활용하여 임베딩 테이블에 접근한 뒤, 이를 합치는 pooling 연산을 하는 식으로 활용된다.
- sparse 행렬과 임베딩 행렬의 곱으로 연산할 수도 있지만, table lookup 뒤에 pooling 하는 게 좀더 효율적인 연산이다.
- Feature Interaction
- dense와 sparse feature 에서 얻어진 값들은 그 다음 레이어로 넘어가기 전에 합쳐진다. 일반적으로 concatenate, sum, averaging을 활용한다.
- Product Ranking
- 사용자와 item 쌍들에 대하여 CTR을 예측하는 것이 모델의 최종 아웃풋이며, 일반적으로 서빙을 위해 수천 개의 아이템을 각 사용자에 대해 평가한다. 그 뒤 CTR 순으로 정렬되어 top-N 개가 추천된다.
- 이처럼 추천 모델은 한 개 이상의 배치 사이즈에 대해 돌아갈 수 있도록 배포된다.
3. DeepRecInfra: at-scale recommendation
- 추천 모델만의 특성에 맞는 디자인 시스템 솔루션을 위해
DeepRecInfra를 개발하였다.DeepRecInfra는 다양한 추천 모델로 확장 가능하도록 개발되었다. 크게 아래 세 가지 구성요소를 가지고 있다.- 업계를 대표하는 추천 모델 모음
- 업계를 대표하는 적용 단계에서의 레이턴시 제약(tail latency target)
- 데이터 센터에서 실제 사용되는 추천 모델을 프로파일링하여 얻은 요청 빈도(arrival rate)와 작업 집합 크기(working set size) 하에서의 실시간 쿼리 서빙
3-A. Industry-scale recommendation models
- 최근의 추천 모델은 figure-2의 일반적인 추천 모델을 특성에 맞게 일부 변형하여 사용한다.
3-A-1. state of the art neural recommendation models
DeepRecInfra는 여덟 개의 sota 추천모델을 구성한다. 아래와 같다.
- Neural Collaborative filtering
- mlp를 사용하여 matrix factorization을 일반화한 모델. one-hot encoded된 sparse feature만 사용하고 dense는 사용하지 않는 것이 특징이다.
- 네 개의 임베딩 테이블(사용자 2, 아이템 2)를 사용한다. embedding에 대해 sparse pooling 적용 후 최종 MLP layer를 거친다.
- NMF 논문에서 사용한 MF user vector와 MLP user vector를 의미하는 거로 생각됨
- Wide and Deep(WnD)
- sparse와 dense 둘 다사용한다. dense feature를 FC 레이어를 거친 뒤 나온 값과 sparse를 embedding lookup한 값을 concat하여 사용한다. 최종 FC 레이어들을 거쳐서 CTR을 예측한다.
- Multi-Task Wide and Deep(MT-WnD)
- WnD를 multitask로 확장한 형태. CTR, 댓글 작성률, 좋아요, 별점 등을 동시에 예측.
- Deep Learning Recommendation Model (DLRM RMC1, RMC2, RMC3)
- 페이스북의 추천모델로, 앞선 모델들과의 가장 큰 차이는 임베딩 룩업이 매우 큰 규모로 수행된다는 점.
- 임베딩 테이블 룩업을 몇 번 수행하느냐 등으로 RMC1~3 모델로 구분됨
- Deep Interest Network(DIN)
- 사용자의 관심사를 모델링하기 위하여 attention을 활용한다.
- dense input을 사용하지 않으며, 수십 개의 임베딩 테이블을 다양한 크기로 조합하여 사용한다.
- 작은 임베딩 테이블은 사용자/아이템 one-hot 임베딩 룩업에 활용되며, 큰 거는 multi-hot으로 사용된다.
- multi-hot으로 얻어진 임베딩들은 attention 과정을 거친 뒤 다른 feature들과 concat되어 최종 레이어로 들어간다.
- Deep Interest Evolution Network (DIEN)
- 시간이 지남에 따라 진화하는 사용자의 관심사를 DIN을 GRU로 보강하여 찾고자 한다. 인풋으로는 one-hot 인코딩 된 sparse feature이다.
- 임베딩 룩업 뒤에 attention 기반의 다층 GRU를 거친 뒤, 나머지 임베딩 벡터와 concat 후 FC 레이어를 거친다.
3-A-2) Operator diversity
위처럼 추천 모델은 다양한 형태를 띄기 때문에 다양한 성능적인 병목 현상을 야기한다. 위의 모델들을 동일 환경에서 동일 조건으로 추론 속도를 실험했을 때 fig-3과 같은 결과를 확인할 수 있다.
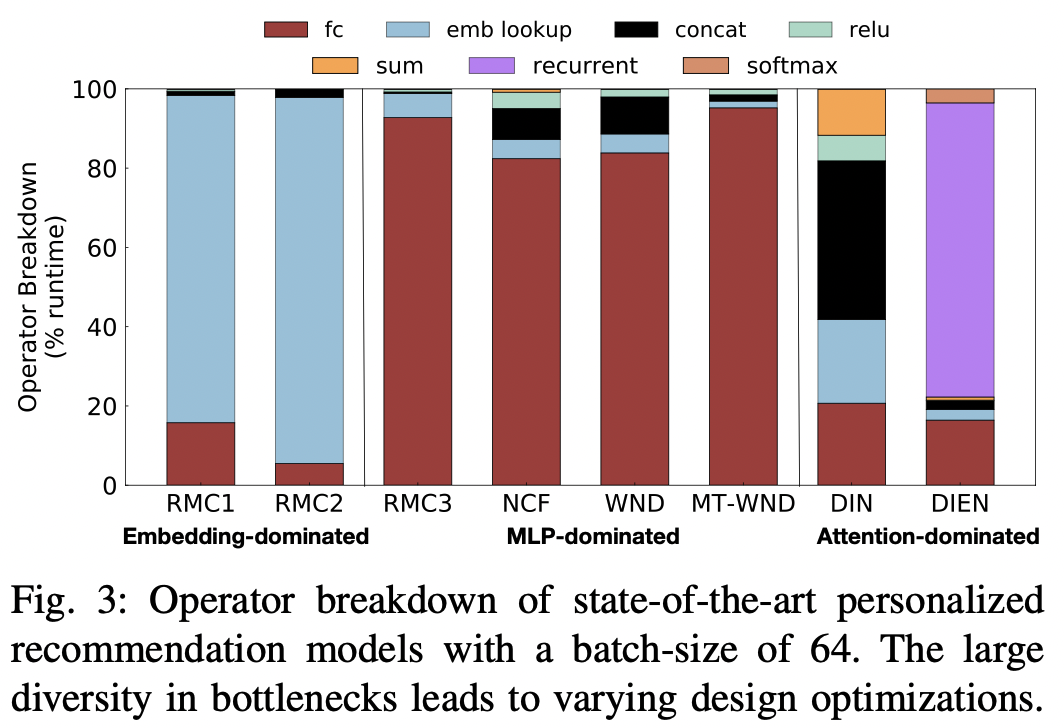
- dense feature를 많이 사용하는 모델(DLRM-RMC3, NCF, WND, MT-WND)은 추론 시간의 대부분이 MLP(fc)에서 소요된다
- sparse feature를 많이 사용하는 모델(DLRM-RMC1, DLRM-RMC2)은 임베딩 룩업이 대다수의 시간을 차지한다.
- attention을 사용하는 DIN, DIEN은 FC와 임베딩 룩업이 아닌 다른 연산에서 시간 소요가 크다.
- DIN은 연산들에 대해 전반적으로 고르게 나뉘는 것을 확인할 수 있다. DIN은 구조부터 이를 고르게 사용하는 형태이다.
- DIEN은 DIN보다 임베딩 룩업이 적고 대신 GRU를 사용하기 때문에 해당 부분에서 큰 시간을 소요하는 것을 알 수 있다.
3-A-3) Acceleration opportunity with specialized harware
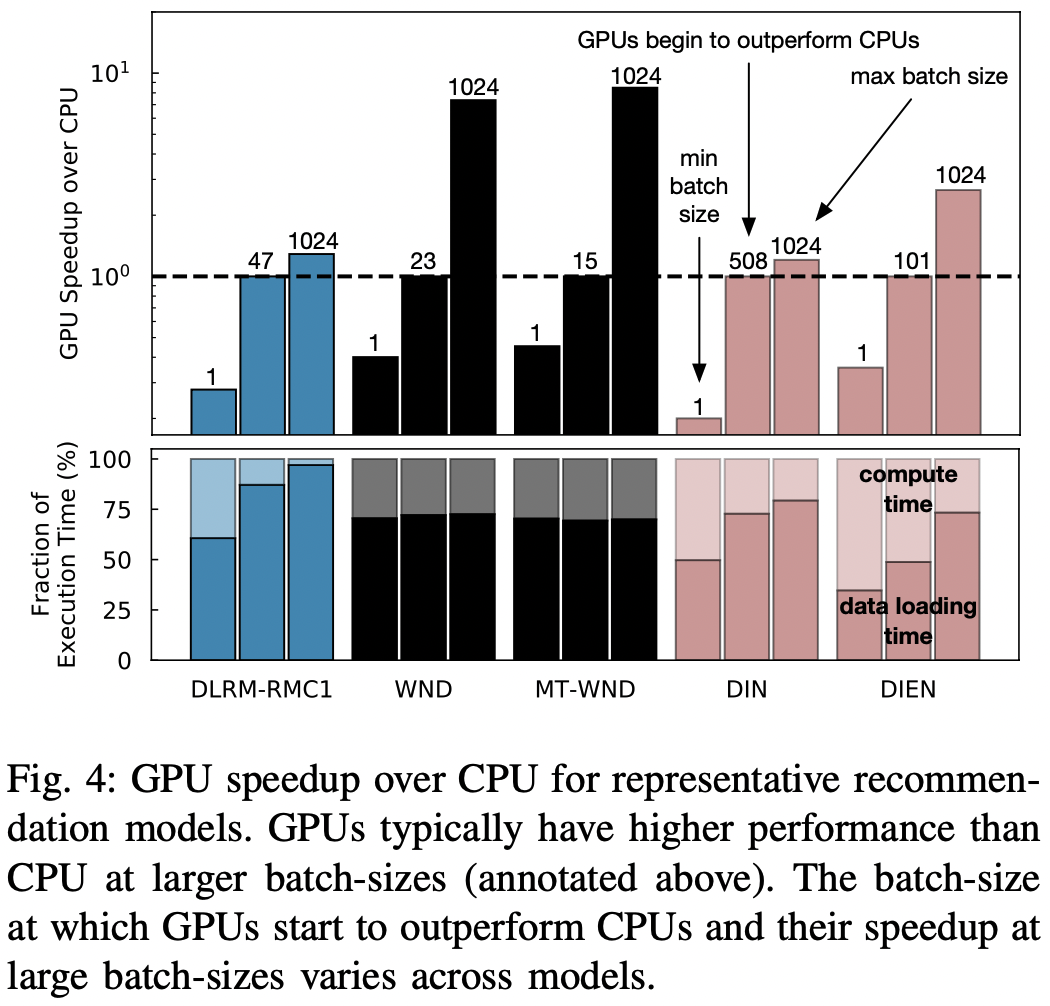
- fig-4를 통해 여러 모델들을 다양한 배치 사이즈로 돌릴 때 cpu 대비 gpu에서의 속도 향상을 확인할 수 있다.
- 위에서 확인할 수 있듯, GPU는 더 높은 연산 집약도와 메모리 대역폭을 제공하여 빠르지만, CPU에서 GPU로 인풋을 전송해야하기 때문에 이 과정에서 오히려 시간이 소요될 수 있다.
- GPU를 통한 추론 시간 중 60~80%는 CPU로부터의 인풋 전송 시간이 잡아먹었다.
- 그럼에도 gpu는 배치 사이즈가 커질 수록 속도 향상의 폭이 크며, 특히 연산 집약적인 모델인 WND 계열 모델에서 그 향상 폭이 컸다.
- 정리하자면 아래와 같다.
- gpu를 사용하면 배치사이즈가 클 때 속도 향상이 크다
- cpu 대비 gpu 사용시의 속도적인 이득을 볼 수 있는 배치사이즈는 모델별로 크게 차이가 났다.
- 즉, 충분한 고려 없이 내 모델은 무조건 GPU 서빙해야 한다고 생각하지 말고, 내가 어떤 종류의 모델을 쓰고 서빙시 배치 사이즈가 어느 정도일지를 파악하는 게 우선이다.
3-B. Service level requirement on tail latency
❓ p95 tail latency? 응답 시간을 나열했을 때 상위 95%에 해당하는 응답시간. 즉 분포상 하위 5%에 위치하는 매우 느린 응답시간에 대해서 그보다도 느린 응답은 제대로 응답된 게 아니라는 가정을 하는 것.개인화 추천 모델은 터이터센터에서 수많은 요청을 처리해야 하며, 이때 서비스 수준 협약(SLA)에 따라 설정된 엄격한 레이턴시 목표(latency target)를 충족해야 한다.
아래에선 처리량(thoroughput)을 p95 테일 레이턴시(tail-latency) 요건 하에서 처리할 수 있는 초당 쿼리 수(QPS)를 사용하여 측정해보았다.
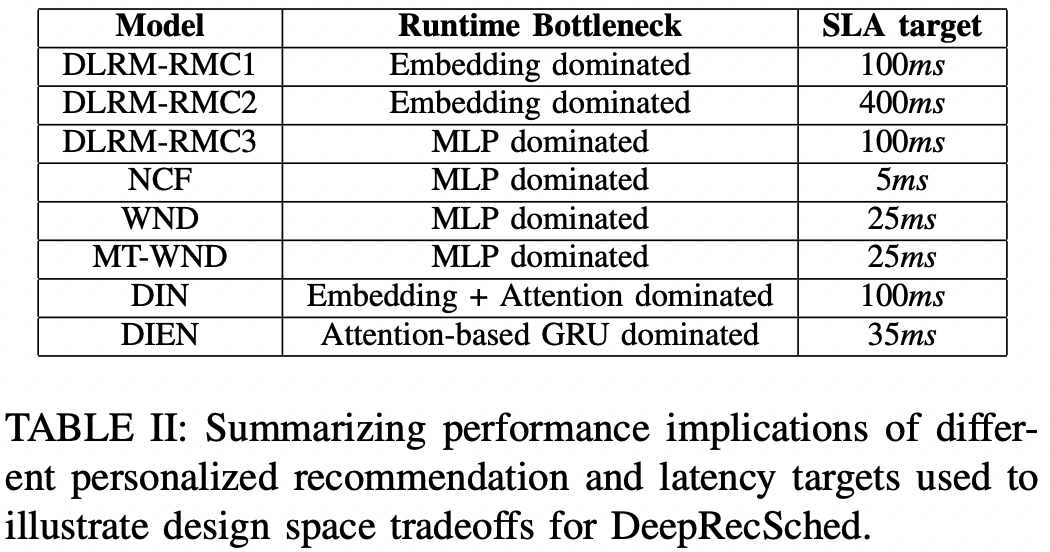
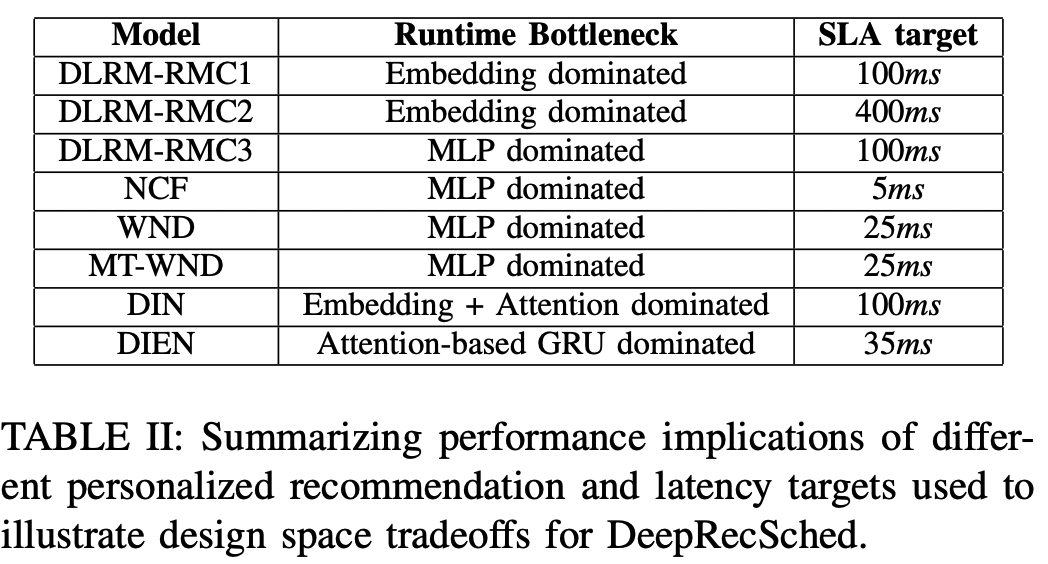
- 추천 모델은 어떤 서비스에 사용되는지, 해당 서비스의 서비스 수준 계약(SLA)에 따라 레이턴시 목표가 달라진다. 위의 표2에서 각 모델을 사용하는 서비스에서 얼만큼의 레이턴시 목표를 설정해두었는지 확인할 수 있다.
- WND는 구글 플레이스토에서 사용되는데 수십 밀리초의 제약임을 확인할 수 있다.
- FB에서 사용하는 DLRM은 수백 밀리초로 상대적으로 여유로운 제약이 있다.
- 이 논문은 각 서비스에서 발표한 목표값을 사용하며, Intel Broadwell CPU 하에서 각 목표를 달성하도록 모델들을 프로파일 한다. 그 뒤 최적화 전략 및 인프라 효율성을 레이턴시 목표와 결합하여 설계한다.
3-C. Real-Time Query Serving for Recommendation Inference
DeepRecInfra는 실시간 쿼리 서빙에서 중요한 두 부분을 반영하였다.
- 요청률 (arrival rate)
- 작업 집합 크기(working set size)
3-C-1) Query Arrival Pattern
- 쿼리 도착 시간은 연속된 요청 사이의 시간 간격으로 정의된다.
- 이때 도착 간격은 고정값, 정규 분포, 푸아송 분포 등 다양한 분포로 모델링 할 수 있다.
- 분포를 어떻게 정의하느냐에 따라 서로 다른 시스템 설계 최적화가 이뤄지기 때문에 중요하다.
- 데이터 센터에서 서빙중인 웹 서비스의 추천 모델을 분석한 결과, 포아송 분포를 따르는 것을 확인할 수 있었다.
3-C-2) Query Working Set Size Pattern
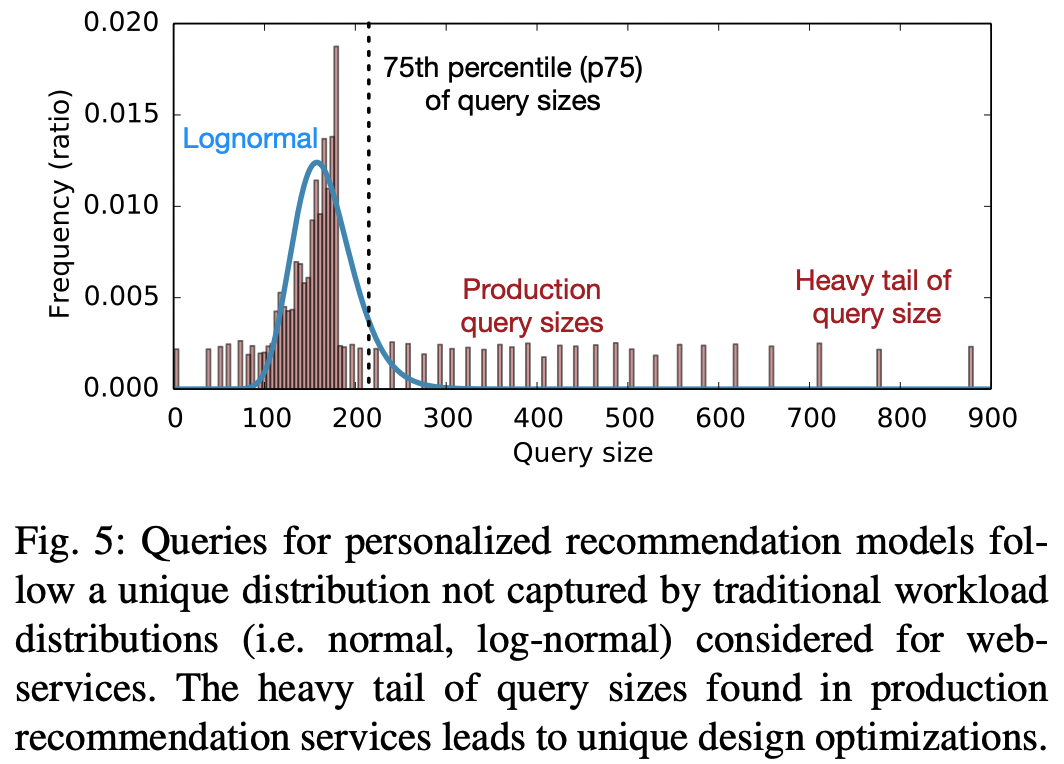
- 추천 모델 쿼리의 크기는 사용자에게 제공되는 잠재적 아이템의 갯수에 따라 달라지며, 이는 사용자와 해당 웹서비스 간의 상호작용의 정도에 영향을 받는다.
- 즉, 2-stage 기준으로 candidate generation 단계에서 정해진 갯수를 뽑지 않고 사용자에 따라 가변적인 갯수를 뽑는 상황을 가정하는 것으로 보인다.
- 웹 서비스용 시스템 솔루션을 설계하는 관련 연구에서는 일반적으로 쿼리의 작업 집합 크기(working set size)가 고정, 정규 또는 로그 정규 분포를 따른다고 가정한다.
- 하지만 fig-5를 보면 추천 모델의 쿼리 크기는 단순 로그 정규에 비해 꼬리가 더 두꺼운(heavier tail) 형태를 가지고 있다.
DeepRecInfra는 여러 쿼리 분포를 지원하지만, 논문 전체에서는 이러한 heavier tail 기준으로 설명한다
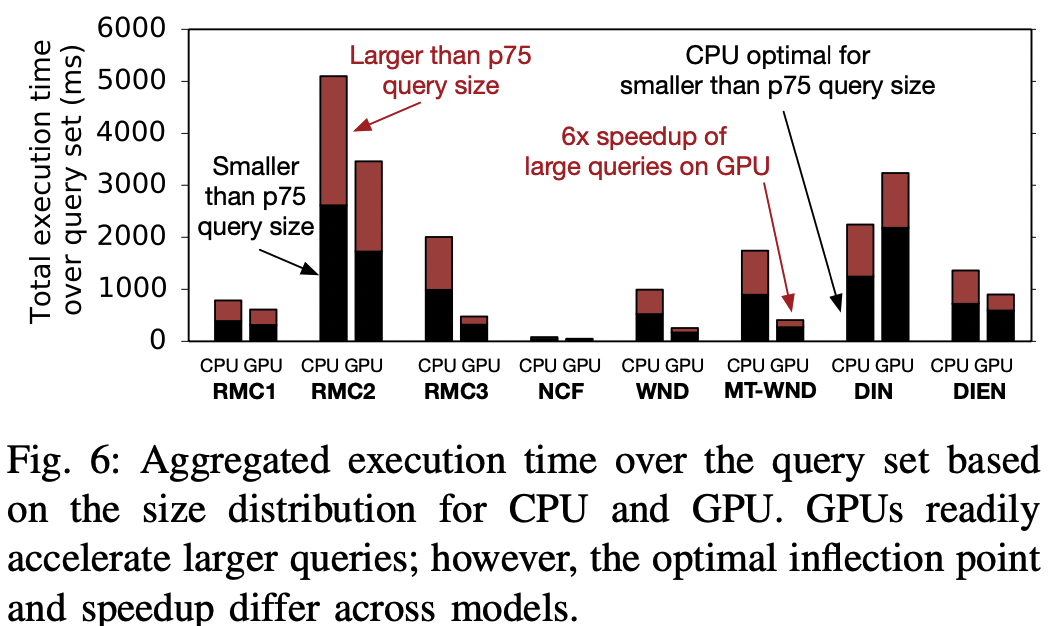
- fig-6을 통해 특정 쿼리 집합을 추천 모델에 넣었을 때, 쿼리 크기가 하위 75%인 경우 vs 상위 25%인 경우에 대한 실행 시간 분포를 확인할 수 있다.
- 작은 쿼리들의 집합이 CPU 실행 시간의 절반 이상을 차지하며, 상위 25%의 대형 쿼리가 전체 실행 시간의 거의 50%를 차지한다.
- GPU에 넣어보니, 이러한 대형 쿼리에 소요되는 시간을 크게 단축함을 확인할 수 있다. → 즉 gpu는 큰 사이즈의 쿼리에 대한 모델 추론에 적합하다.
- 빨라진다는 것은 확인했으나, 빨라지는 정도는 모델에 따라 다르다는 것 역시 확인했다. 예를 들어 DIN의 경우, p75 이하의 쿼리는 오히려 cpu에서 더 빠르다.
- 따라서 이를 모델에 맞게 자동적으로 튜닝할 수 있는 방식이 필요하다
3-D. Subsampling datacenter fleet with single-node servers
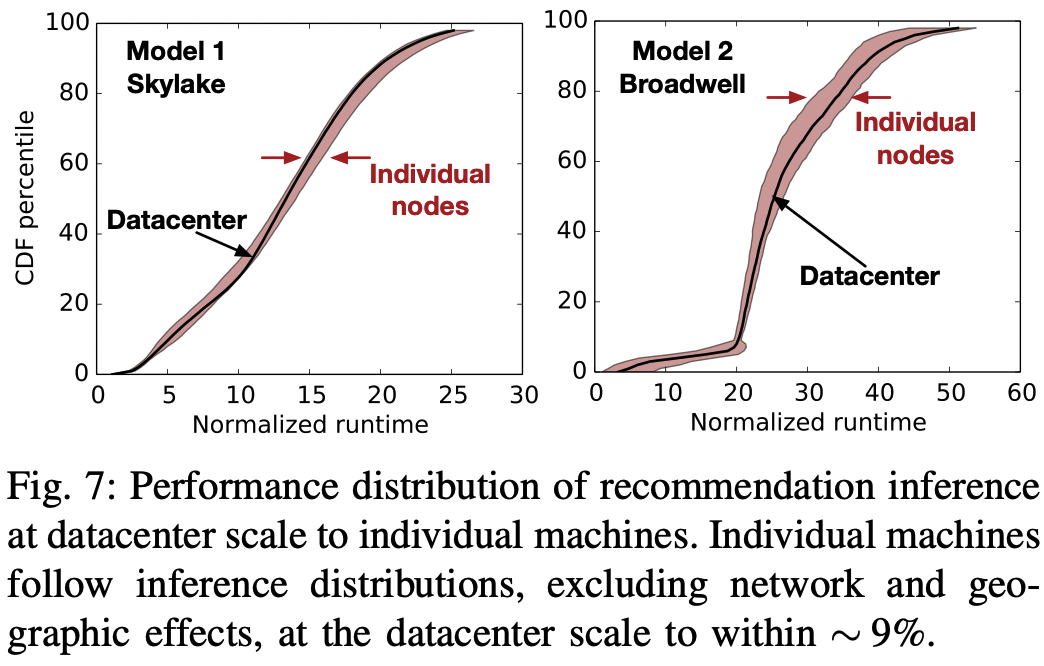
- 추천 모델은 수천 대의 머신에서 돌아가지만, 프로덕션 규모의 데이터센터에서 설계를 최적화하여 배포하는 것이 항상 가능한 것은 아니다.
- 그니까 데이터 센터에 직접 접근 권한이 없을 수도 있고, 거대 규모에서 최적화 자체가 어려운 일일 수도 있다는 뜻으로 이야기한 것으로 보인다.
- 이 논문은 소수의 머신을 사용하여 추천 모델의 추론에서 tail performance를 올릴 수 있음을 보인다.
- fig -7에서 두 개의 다른 모델을 Intel Skylake, Broadwell 머신에서 각각 돌려보았다.
- 데이터 센터 규모에서의 성능은 소수의 머신들로 측정한 성능 분포와 비슷한 양상을 보인다.
- 특히 tail 부분에서는 그 구간이 상당히 좁아서 데이터 센터 측정값 대비 10% 오차로 분포 구간을 얻을 수 있다. → 즉 이걸로 tail에 대한 최적화를 하면 데이터센터 규모에서도 잘 될 것이다.
3-E. Putting it Altogether
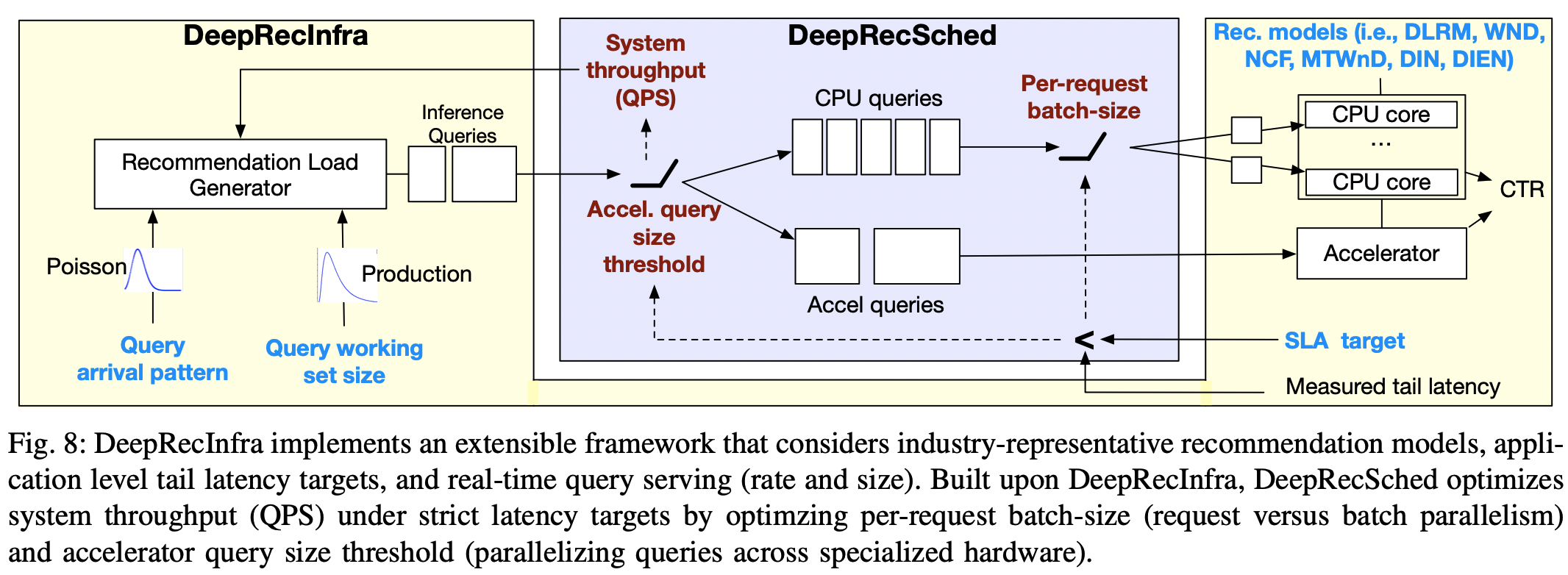
- 대규모로 사용되는 추천의 특성을 이해하려면 이를 대표할 수 있는 인프라를 이해해야한다. 이를 위해 3장에서는 아래를 보았다.
- 대표적인 추천 모델
- 쿼리 도착률(query arrival rate) 및 쿼리 작업 집합 크기(work set size)의 분포
- 위 분석을 바탕으로 fig-8의
DeepRecInfra를 개발하였다.- 쿼리 도착 비율 및 사이즈의 패턴을 모델링 할 수 있는 확장 가능한 부하 생성기(load generator)를 탑재하였다.
- 즉 load generator를 이용하여 실제와 유사한 쿼리 형태를 계속 날림으로써 이에 대한 최적화된 전략과 구조를 짜고자 한다.
4. DeepRecSched Design
- 앞서 언급한 내용들(e.g. model architectures, tail latency targets, real-time query serving, hardware platforms)을 고려하기 위해 fig-8과 같이
DeepRecInfra를 기반으로DeepRecSched를 설계, 구현 및 평가하였다.DeepRecSched는 앞서 언급한 추천의 특성을 고려하여 시스템 처리량을 극대화하는 동시에 추천 서비스의 엄격한 레이턴시 목표(latency target)를 충족하도록 설계되었다.
DeepRecSched의 핵심은 추천 쿼리의 작업 집합 크기(working set size)의 분포가 heavy tail을 갖는다는 것에서 출발한다.- 큰 쿼리는 처리 시간이 길기 때문에 특정 레이턴시 목표 하에서 시스템의 처리량(QPS)를 제한하는 원인이 된다. → 이거에 자원을 몰아줘야 레이턴시 안 걸리니 상대적으로 다른 애들은 그동안 처리 못함
DeepRecSched는 두 가지 주요한 설계 최적화를 통해 위와 같은 병목 현상을 해결한다.- 큰 쿼리는 병렬 코어에서 처리되는 작은 배치 단위로 분할한다.
- 이를 위해서는 batch-level과 SIMD-level의 병렬 처리, 캐시 경합, 더 작은 크기의 요청이 많을 때 발생할 수 있는 대기열 지연의 잠재적 증가 사이의 균형을 신중하게 조정해야 한다.
- 대규모 추천 추론을 가속화하기 위해 대규모 쿼리는 특수 AI 하드웨어(GPU)로 보낸다.
- 큰 쿼리는 병렬 코어에서 처리되는 작은 배치 단위로 분할한다.
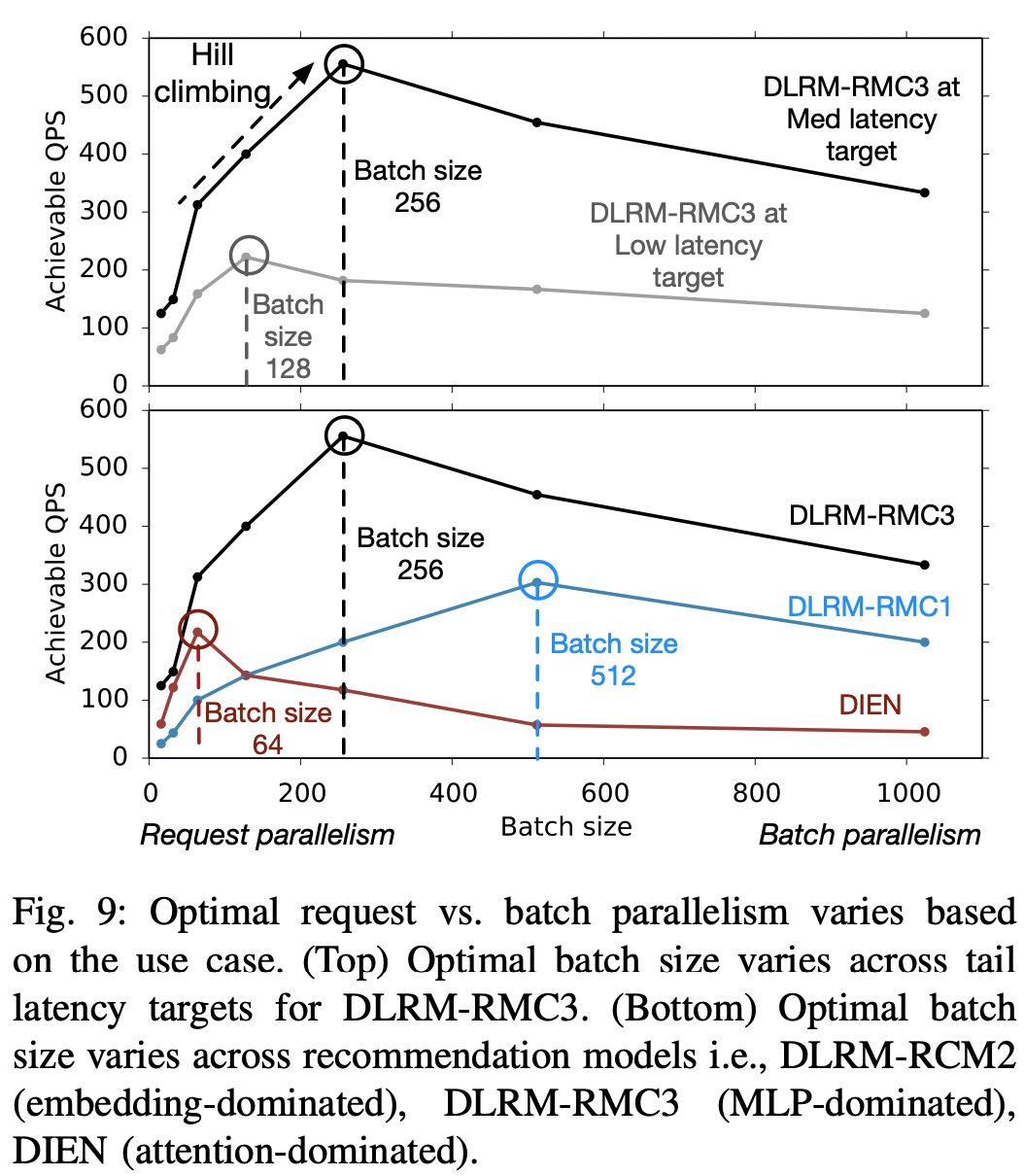
4-A. Optimal batch size varies
- 쿼리를 여러 코어로 분할하면 병렬 처리를 할 수 있는 장점이 있기 때문에,
DeepRecSched는 쿼리를 개별 요청(request) 단위로 분할한다. 물론 이 경우 요청(request)마다의 배치 사이즈가 작아지기 때문에 요청 내에서의 병렬화는 작아진다.- 즉, 배치를 한 번에 연산하는 병렬화의 이득은 작아지지만, 이를 아예 여러 코어로 나눠서 마치 여러 요청이 들어온 것마냥 처리를 해준다.
- 용어가 좀 헷갈리게 사용되고 있는데, 쉽게 생각하면 아래와 같다.
- query: 최초에 들어온 요청. 2단계 추천시스템에서 랭커에게 들어오는 candidate 수라고 봐도 좋을 듯.
- request: 위에서 나온 candidate는 한 유저의 요청이지만 이를 마치 여러 유저의 요청인 양 특정 배치 사이즈로 잘게 분할한 요청. epoch과 mini batch 간의 관계처럼 이해해도 좋다.
- 시스템 QPS 처리량(throughput)을 최대화하는 최적 배치 사이즈는 (1) 테일 레이턴시 목표와 (2) 추천 모델에 따라 달라진다. fig-9에서 이를 확인할 수 있다.
- 서버에서 사용하는 CPU가 무엇이냐도 request level 과 batch level 병렬화 간의 trade-off 최적화에 영향을 준다.
- 인텔 브로드웰은 AVX-256을 기반으로 SIMD 유닛을 구현하는 반면 스카이레이크는 AVX-512를 구현한다. 따라서 skylake은 넓은 SIMD 유닛을 가지고 있기 때문에 배치 사이즈를 좀더 키우는 것에 이점이 있다.
- 인텔 브로드웰은 포괄적인 L2/L3 캐시 계층 구조를 구현하는 반면 스카이레이크는 배타적인 캐시 계층 구조를 구현한다. 포괄 계층의 경우 병렬 처리에 좀더 취약하다는 것 같은데, 자세한 건 모르겠고 아무튼 cpu마다의 차이도 고려해야한다는 것으로 받아들인다.
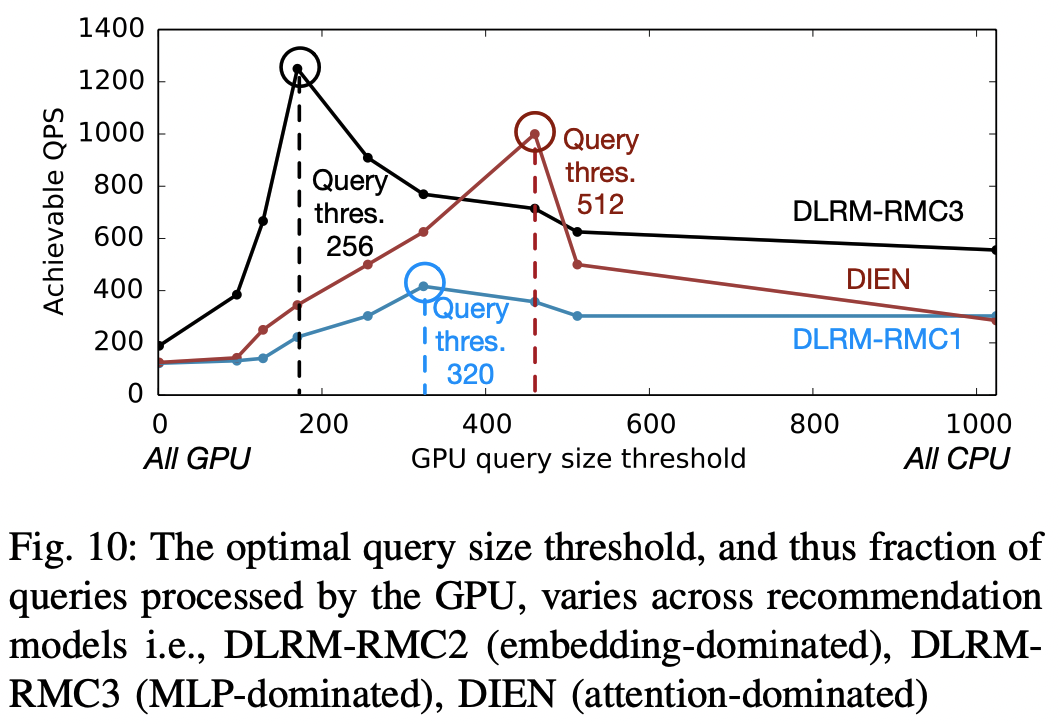
4-B. Leverage parallelism with specialized hardware
- CPU 내에서의 병렬화 뿐 아니라, GPU와 CPU 간에도 최적화할 수 있다. GPU가 상대적으로 이득을 볼 수 있는 쿼리를 CPU가 아닌 GPU로 넘겨준다.
- 앞서 fig-4에서 보았듯 GPU는 CPU 대비 더 큰 배치 사이즈를 처리하는 데에 강점이 있지만, cpu에서 데이터를 전송해주는 오버헤드가 발생하였고, 이득을 보기 위해선 상당히 큰 배치사이즈여야 했다.
- 따라서
DeepRecSched는 일정 임계치 이상의 큰 쿼리는 GPU로, 그 이하는 CPU 코어에서 처리하도록 한다. 마찬가지로 이 임계값은 모델 및 테일 레이턴시 목표에 따라 달라진다.
4-C. DeepRecSched
- 균형적인 batch/request-level 병렬화를 할 수 있는 최적의 배치 사이즈를 찾는 방법 중 하나는 제어 이론(control-theoretic)적 접근을 하는 것이다.
- fig-9,10에서 볼 수 있듯 간단한 hill-climbing 알고리즘을 통해 다양한 추천 모델 및 하드웨어에 대하여 최적의 배치 및 쿼리 요청 크기를 찾을 수 있다.
DeepRecSched가 최적화하는 과정은 아래와 같다- 단일 배치 사이즈에서 시작하여
DeepRecInfra로부터 오는 쿼리를 처리한다. 이때 테일 레이턴시 목표를 지키면서 처리량을 올리기 위해 QPS가 떨어지기 전까지 조금씩 배치사이즈를 키운다. - gpu를 사용하기 위한 쿼리 사이즈의 임계치를 마찬가지로 단일 사이즈(즉 전부 gpu 처리)에서부터 QPS가 떨어지기 전까지 조금씩 올린다.
- 위를 자동으로 튜닝하면 다양한 추천 모델, 테일 레이턴시 목표, 쿼리 사이즈 분포, 하드웨어 하에서 최적의 대규모 추천을 할 수 있게 된다.
- 단일 배치 사이즈에서 시작하여
5. Methodology
DeepRecSched와DeepRecInfra를 다양한 하드웨어 환경에서 실험한다.
DeepRecInfra
- 앞서 설명한 대로
DeepRecInfra는 세 개의 요소로 구성되어 있다.- Model Implementation
- 앞서 언급한 대표적인 추천 모델들을 Caffe2로 구현했다.
- CPU, GPU 각각 Intel MKL library 및 CUDA/cuDNN 10.1 을 사용했다.
- 단일 Caffe2 워커 및 Intel MKL 스레드로 실험했다.
- SLA 레이턴시 목표
- 표-2 에서 설명한 대로 각 모델은 서로 다른 SLA 목표를 갖고 있다.
- 다양한 레이턴시 목표 하에서 실험하기 위해 레이턴시 목표를 low, medium, high로 나눠서 실험해 보았다. high, low는 medium의 +-50% 이다.
- 실시간 쿼리 패턴
- 앞서 말했듯
DeepRecInfra는 쿼리 패턴을 arrival rate/query size 로 나눠서 고려한다. - arrival rate는 포아송 분포로 근사하고, query size는 fig-5와 같은 꼬리가 두터운 log normal로 근사한다.
- 앞서 말했듯
- Model Implementation
Experimental System Setup
- 데이터센터의 다양한 하드웨어를 고려하기 위해 Intel Broadwell, Skylake 두 종류의 CPU에서 실험한다. 상세 제원은 생략한다.
- GPU 역시 실험하기 위해 NVIDIA GTX 1080Ti 를 사용하며 cuDNN을 활용하였다.
Production-scale baseline
DeepRecSched를 고정된 배치 사이즈를 활용하는 베이스라인과 비교하였다.- 고정된 배치 사이즈는 큰 쿼리가 들어올 때 이를 사용가능한 코어의 갯수만큼 균일한 갯수로 자르는 방식을 의미한다. 예를 들어 40개의 intel 코어가 있는 서버에 1000개의 쿼리가 들어온다면, 이를 25개로 잘라서 cpu에 분배한다.
6. DeepRecSched Evaluation
이 장에서는
DeepRecInfra,DeepRecSched를 결합하여 효율성 측면에서 베이스라인을 능가하는 과정을 보여준다.
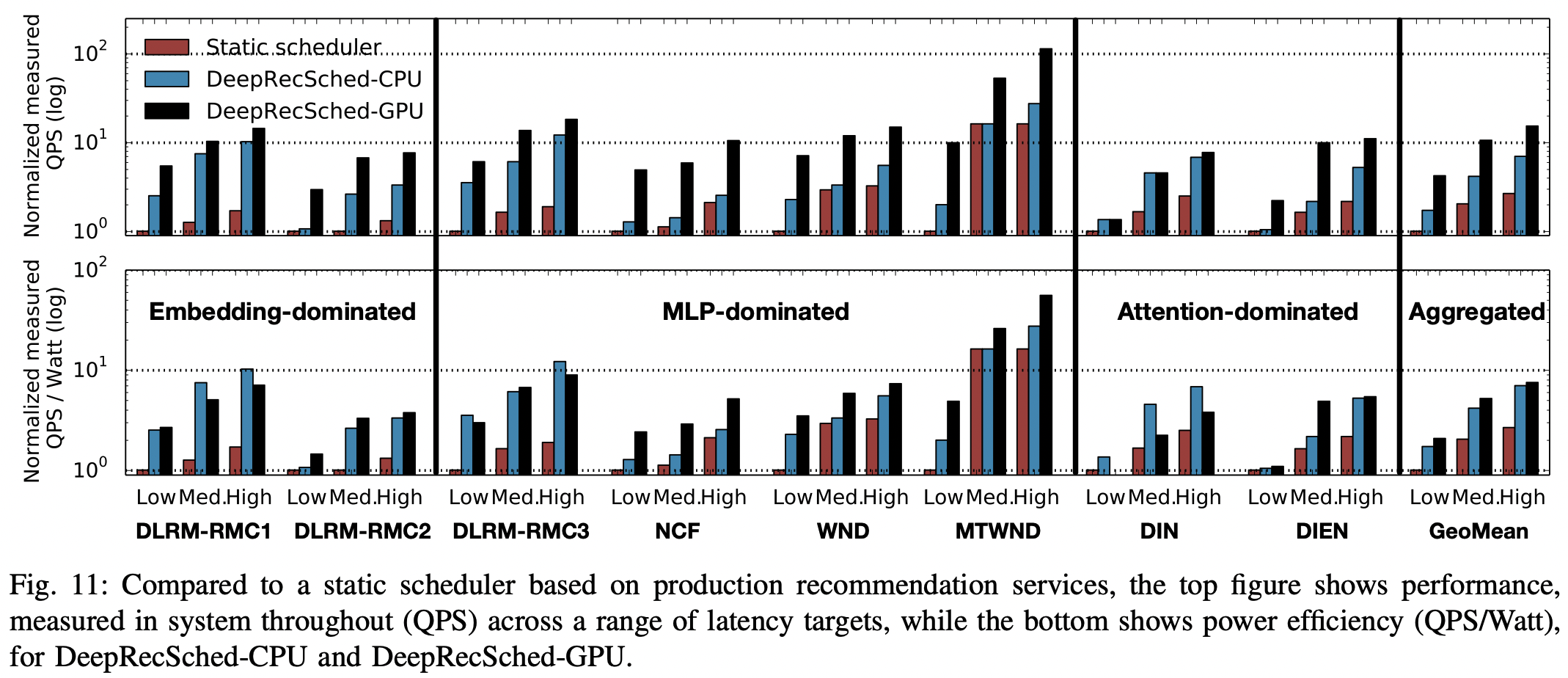
Performance
- fig-11은 세 종류의 tail letency(low, med, high) 하에서 DeepRecSched-CPU와 DeepRecSched-GPU를 baseline과 비교하였다.
- 모든 모델에서 DeepRecSched-CPU가 low, med, high tail latency에서 baseline 대비 1.7, 2.1, 2.7배 높은 QPS를 달성했다. 즉, 최적의 batch_size를 구한 것이 도움이 되었다.
- DeepRecSched-GPU는 4.0, 5.1, 5.8 배 개선하였다. 즉, cpu와 gpu 간의 병렬화를 하는 것이 크게 도움이 되었다.
Power efficiency
- fig-11의 아래 그림에서 와트당 QPS(QPS/Watt ), 즉 해당 QPS를 달성하기 위해 전력을 얼마나 소모했는가를 볼 수 있다.
- 마찬가지로 DeepRecSched 사용시에 개선되는 것을 확인할 수 있다. 다만 GPU를 사용할 경우 성능 개선 때보단 개선의 정도가 적었으며, 일부 사례에선 CPU만 사용하는 것보다 안 좋기도 했다.
- 특히 DLRM-RMC1, RMC2 같이 메모리 집약적 모델의 경우, 모델을 gpu로 옮길 때의 오버헤드가 크기 때문에 전력 효율이 낮았다.
- 따라서 대규모 추천 시스템의 전력 효율을 고려하고자 하는 경우 어떤 모델인지도 생각해야할 필요가 있다.
6-A. Balance of Request and Batch Parallelism
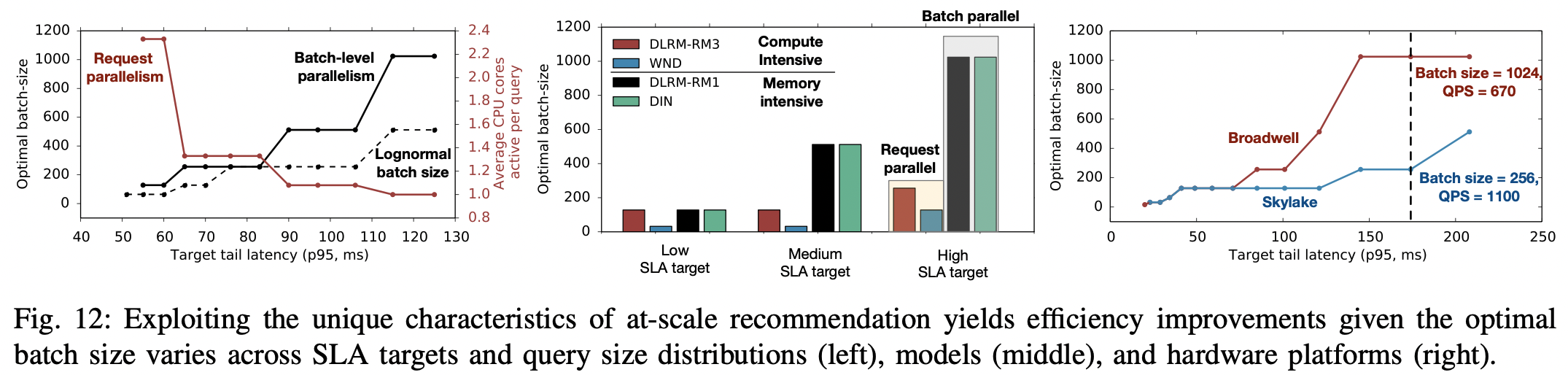
- 위처럼 DeepRecSched-CPU가 baseline 대비 높은 QPS 성능을 보인건 다양한 환경에서 request-level 과 batch-level 간의 병렬화 균형을 잘 맞췄기 때문이다. 어떻게 했을까?
- Optimizing across SLA targets
- fig-12-a에서 다양한 target tail latency 하에서 request-level 과 batch-level parallelism 간의 tradeoff를 확인할 수 있다.
- 낮은(즉 더 빡빡한) 테일 레이턴시 목표 하에서는 배치사이즈가 작은 것이 optimal 하였다. 즉, 쿼리를 작은 단위의 request로 나눠서 병렬화하는 것이 좋았다.
- 덜 빡빡한 테일 레이턴시 목표로 갈 수록 최적의 배치사이즈는 증가하였고, 즉 한 코어 안에서 더 큰 배치를 처리하는 batch-level 병렬화가 좋았다.
- 즉, DeepRecSched-CPU 가 알고리즘적으로 optimize 되었을 때 어떤 방식을 선호하였는가를 확인할 수 있다. 참고로 fig-12는 DLRM-RMC1 모델로 실험하였다.
- Optimizing across query size distributions
- fig-12-a에서 최적의 배치 사이즈가 작업 집합 크기(working set size) 분포에 따라 달라지는 것 역시 확인할 수 있다.
- 일반적으로 알려진 로그 정규 분포를 가정했을 경우, 최적의 배치 크기는 실제 서비스 분포(두꺼운 꼬리)를 이용하여 구한 값보다 작게 구해지는 것을 확인할 수 있다.
- 이 결과를 실제 서비스에 적용해보니 DeepRecSched-CPU의 성능이 저하되는 것을 확인할 수 있었다. 즉, 실제 분포는 꼬리가 두꺼운 분포이며 이를 통해 request/batch-level 간의 최적 균형을 찾는 것이 실제 서비스에서도 좋았다.
- Optimizing across recommendation models.
- fig-12-b에서 볼 수 있듯 모델별로 최적의 배치 사이즈는 다르다.
- 컴퓨팅 집약적인 모델(DLRM-RMC3, WnD)의 경우, 메모리 집약적 모델(DLRM-RMC1, DIN) 대비 낮은 배치 사이즈에서 시스템 처리량이 최대가 된다.
- 메모리 집약적 모델들이 높은 배치사이즈를 갖는다는 건, requeset-level의 병렬화를 선호하지 않는다는 의미이다. 그 이유는 큰 임베딩 테이블을 가진 모델의 성능적인 병목은 DRAM 대역폭 사용률에서 발생하기 때문이다. 즉 연산 자체보단 메모리에서 임베딩을 가져오는 게 좀더 시간을 잡아먹는다.
- 높은 SLA target을 설정할 경우, 코어 자체적인 데이터 병렬화를 사용하는 것이 상대적으로 이득으로 여겨져서 배치 사이즈가 커지는 것을 확인할 수 있다.
- 컴퓨팅 집약적인 모델(DLRM-RMC3, WnD)의 경우, 메모리 집약적 모델(DLRM-RMC1, DIN) 대비 낮은 배치 사이즈에서 시스템 처리량이 최대가 된다.
- fig-12-b에서 볼 수 있듯 모델별로 최적의 배치 사이즈는 다르다.
- Optimizing across hardware platforms
- fig-12-c는 DLRM-RMC3을 다양한 서버 하드웨어 하에서 실험하였다.
- 인텔 브로드웰이 스카이레이크보다 최적 배치 사이즈가 높은 것을 확인할 수 있다. 이걸 우리의 뛰어난
DeepRecSched는 잡아낸다 - 정리하자면,
DeepRecSched는 다양한 테일 레이턴시 목표, 쿼리 크기 분포, 추천 모델뿐만 아니라 기본 하드웨어 플랫폼에 걸쳐 요청과 배치 수준의 병렬 처리 간에 미세한 균형을 찾
6-B. Tail Latency Reduction for At-Scale Production Execution
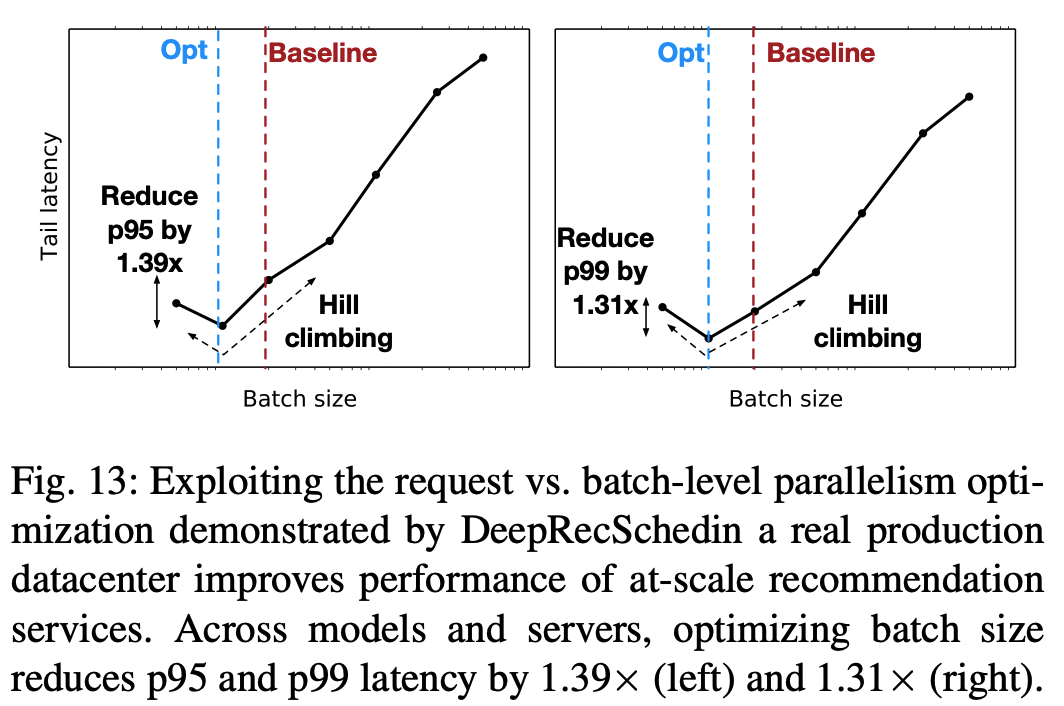
DeepRecInfra를 사용한 최적화가 서버 한 대에선 잘 됐는데, 데이터 센터에 배포해도 잘 될까? → 잘 된다- fig-13에서 수백대의 서버로 이뤄진 클러스터에서의 실험 결과를 볼 수 있다.
- 일간 및 하루 중의 트래픽 변화를 모두 반영하기 위해 DeepRecSched를 24시간 동안 돌렸다.
- 베이스 라인으로 구한 배치 사이즈에 비해 최적화한 배치사이즈에서 tail latency가 감소하는 것을 확인할 수 있다. → 즉 QPS를 늘릴 수 있다.
6-C. Leverage Parallelism with Specialized Hardware
GPU까지 사용해서 효율화를 높이자
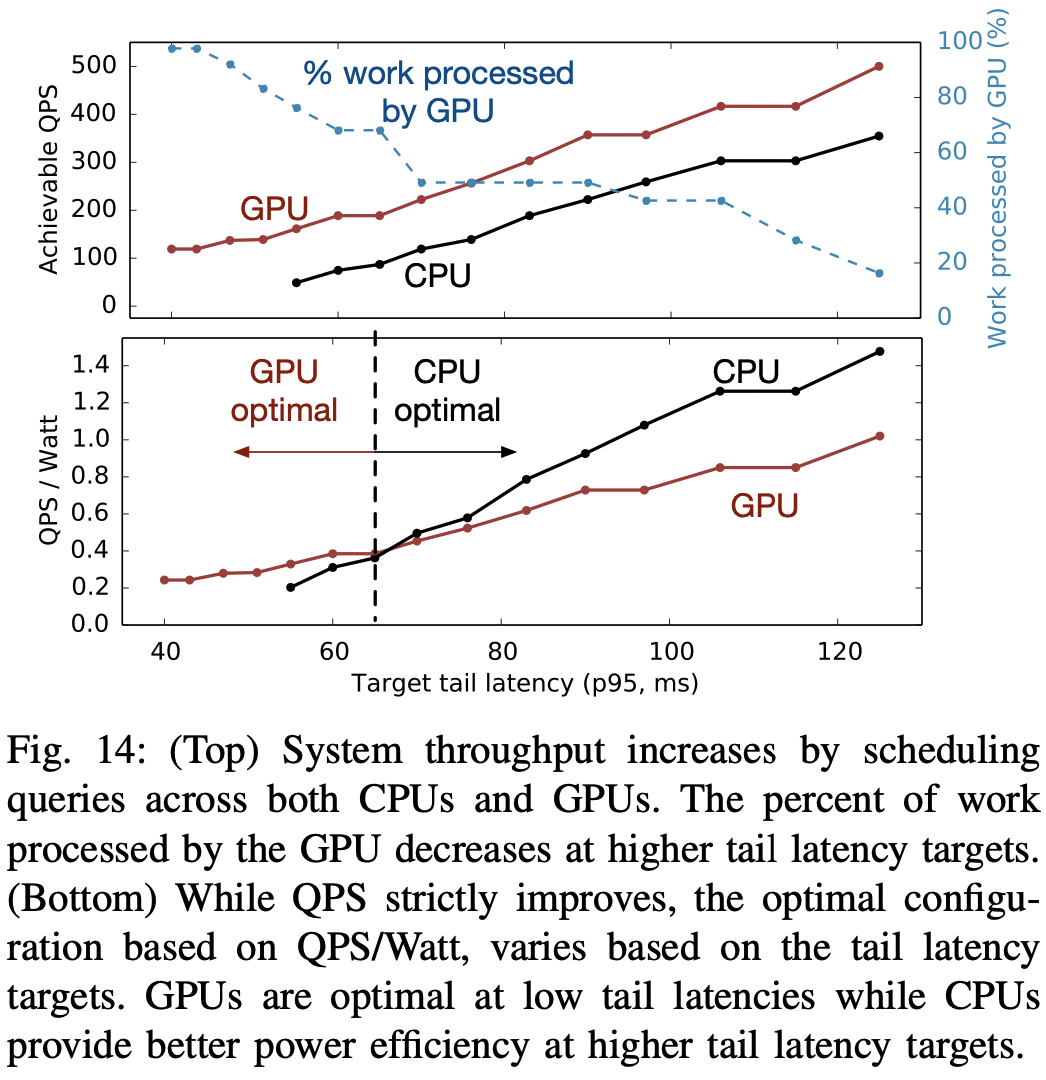
Performance improvements
- 14-a를 보면 DLRM-RCM1에 대하여 GPU와 CPU의 QPS를 볼 수 있다. 여기서 CPU가 달성 가능한 target tail latency(x축)는 57ms인 반면, GPU는 41ms이다. 즉 GPU는 CPU에서 달성할 수 없던 tail latency target을 달성할 수 있다.
- 14-a에서 알 수 있듯 같은 target tail latency 하에서 GPU는 CPU보다 높은 QPS를 낼 수 있다. target tail latency가 커질 수록(즉 쉬워질수록)
DeepRecSched가 GPU에 작업을 배분하는 정도는 줄어드는데, 이는 latency 기준이 빡빡할 수록DeepRecSched-GPU를 활용해야만 달성할 수있으나, 기준이 널널해질 수록 CPU만으로도 충분해지기 때문이다.- 결과적으로, latency 기준이 널널해짐에 따라 gpu로 보내기 위한 쿼리 크기의 임계치는 높아진다.
Infrastructure efficiency implications.
- 14-b를 보면 target tail latency가 낮을 수록 GPU의 전력 효율성이 좋고, 높을 수록 CPU의 전력 효율성이 좋다.
- 한 마디로 레이턴시 기준이 빡빡할 수록 GPU로 더 많이 가는 게 낫다
- 물론 이것은 어떤 추천 모델을 사용하는가 등과도 깊게 연관되어있다.
7. Related work
기존에도 시스템적으로 딥러닝 모델의 추론에 대한 효율화는 많이 연구되어 왔지만 대규모 추천 모델에 특화된 연구는 적었다. 뭐 아무튼 우리 말고는 아무도 이렇게 대규모로 서빙되는 추천 모델에 특화되어 연구한 기존 연구는 없었다.
8. Conclusion
- 현대의 추천 모델은 다양한 서비스에 사용되며 데이터 센터의 대다수의 서빙 자원을 사용한다.
- DeepRecInfra를 제안했다.
- 확장 가능한 인프라이며, 8가지 최신 추천 모델, SLA 목표, 쿼리 패턴으로 구성되어 있다.
- DeepRecSched를 제안했다.
DeepRecInfra를 기반으로 만들어졌으며, 처리량을 극대화하기 위해 대규모 추천의 다양한 특성을 반영하였다. 이를 통해 tail latency 제약 하에서 시스템처리량을 최적화하였다.
- 다양한 SLA 목표와 8가지 대표적인 추천 모델에 대하여
DeepRecSched은 시스템의 처리량을 두배 늘릴 수 있다.- 이를 실제로 데이터 센터에서 서빙했을 때도 성능 향상을 보였다.
DeepRecSched는 CPU 간에, 혹은 CPU와 GPU 간의 분산화를 통해 시스템의 처리량을 최적화하였다.
