0. Abstract
Determinaltal Point Process(DPP)는 밀어내기 용도로 요약, 검색 등에서 다양하게 쓰이는 확률 모델이다. 하지만 한 가지 문제는 DPP에 대한 MAP 추정은 NP-hard라는 것이며, 대안으로 널리 쓰이는 greedy algorithm 역시 연산량이 많기 때문에 실시간 환경에서 사용하기 힘들다는 것이다. 이를 해결하기 위해 이 논문은 DPP에 대한 greedy MAP 추정을 제안한다. 또한 근방에 위치한 아이템들끼리만 밀어내기를 하는 경우도 가능케 한다. 이 알고리즘은 실험결과 현재의 SOTA보다 빠르며, 더 좋은 relevance-diversity trade-off를 보인다.
1. Introduction
- DPP는 열평형에서 페르미온 입자 간의 밀어냄의 정도를 모델링할 때 사용했으며, 양자 역학을 넘어 이제 기계학습에서도 쓰이고 있다. 다른 확률 모델들(e.g. graphical model)과 다르게, DPP는 conditioning, sampling 등 다양한 추론을 polynomial하게 수행하는 알고리즘을 갖는다는 장점이 있다.
- 다만 문제는, 가장 큰 확률값을 갖는 아이템 집합을 찾는 MAP inference는 NP hard라는 것이다. 즉 일단 실행은 빨리 할 수 있는데 최선의 값을 찾는 게 오래 걸린다. 따라서 대안으로 DPP에 대한 근사적인 MAP 추론을 활용한다. 현시점 최고는 gradient 기반의 방법인데 계산 복잡도가 매우 높으며, 이에 따라 실시간 사용은 불가하다. 대안으로 DPP set의 log-probability는 submodular 하다는 특성을 활용하는 greedy 알고리즘 방법이 있다. Greedy의 경우 이론적 뒷받침이 미약하지만 성능이 좋다. 다만, greedy를 제대로 하려면 O(M^4)의 복잡도를 가지며, O(M^3)의 복잡도로 이를 근사할 수 있다. 이 논문에서는 exact greedy를 O(M^3)의 복잡도로 수행한다.
- DPP의 가장 큰 특징은, 다양성이 보존되는 아이템 집합에 높은 확률을 부여한다는 것이다. 또한 아이템을 나열하는 형식으로 서비스를 제공하는 경우, 특정 범위 내의 아이템 끼리만 다양성이 보장되길 바라는 경우도 있다. 논문에서는 이러한 특별한 경우에도 사용 가능한 알고리즘을 제공한다.
- 이 논문은 크게 아래 세 가지를 만들었다.
- 이 논문에서 제시하는 알고리즘은 DPP에 대한 greedy MAP 추정 속도를 매우 크게 높인다. Cholskey factor를 incremental하게 업데이트하는 방식으로 복잡도를 O(M^3)으로 낮추며, N개의 아이템(N<M)만 추천해도 되는 경우에는 O(N^2*M)의 복잡도를 가진다. DPP에 대해서 이처럼 빠르게 exact greedy MAP inference를 수행한 논문은 이게 처음이다.
- 특정 sliding window(반경) 내에서만 다양성이 필요한 상황에 맞는 알고리즘도 개발하였다. Window size w<N이면 계산 복잡도는 O(wNM)으로 줄어든다. 즉 긴 sequence를 추천하는 경우 sliding window를 적용하면 더 빠르게 연산이 가능하다.
- 실제 추천 과제에 적용하고 metric으로 평가했으며, online A/B test도 수행해보았다. 그 결과 DPP를 적용했을 때 상대적으로 좋은 relevance(연관성)-diversity(다양성) trade-off를 보였다.
2. Background and Related Work
- Notation
- 대문자(Z): 집합(sets)
- #대문자(#Z): 집합 원소 갯수
- 볼드 대문자: 행렬
- 볼드 소문자: 백터
- : submatrix. X는 row들 집합, Y는 column들 집합
- : 행렬식.
2-1. Determinantal Point Process
- 임의의 이산형 집합(discrete set) Z={1,2,...,M}에 대한 DPP 는 Z의 모든 부분집합의 집합인 에 대해 정의되는 probability measure이다. 이때 real & positive semidefinite(PSD) 이며, Z의 성분과 대응되는 에 대해 아래 수식을 만족한다.
- 위와 같은 분포 하에서 marginalization, conditioning, sampling 등의 추론은 polynomial하게 가능하지만, 아래의 MAP 추론만큼은 불가하다. 즉 아래 수식을 만족하는 Y만 찾으면 게임 끝인데 찾을 수가 없다.
- 이러한 MAP 추론을 아예 안 하고 fast sampling을 이용해서 여러 sample을 뽑은 뒤 그중 가장 큰 확률값 갖는 부분집합을 리턴하는 대체 알고리즘도 있다. 하지만 알고리즘 자체 복잡도가 O(N^2*M)이며, L을 고유값 분해(eigen decomposition) 해야하기 때문에 O(M^3) 복잡도가 추가되고, sampling을 여러번 해야 greedy 알고리즘 정도의 성능이 보장되기 때문에 또 복잡도가 추가된다. 즉, 오래 걸린다.
2-2. Greedy Submodular Maximization
- 에 대해 정의되는 real-valued function을 set function이라 한다. 위식과 같이 marginal gain이 non-increasing한 set function 를 submodular라 한다. DPP에 대한 log probability 는 submodular라는 것이 알려져있다. Submodular maximization은 이러한 submodular function에서 최대값을 갖는 집합을 찾는 것이며, 우리가 원하는 DPP의 MAP inference는 곧 submodular maximization과 같다.
- 어쨌든 gain이 추가되니까 전체 set Z가 곧 submodular maximization이 아닌가 생각했는데, 아래와 같은 경우를 생각해보니 이해가 되었다. margin은 음수일 수도 있다.

- 어쨌든 gain이 추가되니까 전체 set Z가 곧 submodular maximization이 아닌가 생각했는데, 아래와 같은 경우를 생각해보니 이해가 되었다. margin은 음수일 수도 있다.
- 안타깝게도, submodular maximiation은 NP-hard이며, 즉 MAP inference of DPP는 NP-hard problem이다. 이를 해결하기 위해 공집합에서부터 출발하는 greedy 알고리즘을 사용하곤 한다. 이는 최대 margin이 음수가 되거나, 부분집합의 크기에 대한 제약 조건을 만족하기까지 계속된다.
- Greedy 알고리즘 자체의 특성상, approximation for maximum coverage는 제약되어 있다. 그냥 쉽게 얘기하자면, greedy하게 submodular maximization을 수행하면 모든 가능한 부분집합을 고려하는 건 아니다. 그럼에도 사용하는 이유는 실제 성능이 잘 나오기 때문이다.
2-3. Diversity of Recommendation
- 기계학습 분야에서 추천 결과의 다양성을 보장하기 위한 많은 연구들이 진행되어 왔으며, 특히 관련성-비유사성(다양성) 간의 trade-off를 최적화하기 위한 노력들이 많았다. 문제는 대부분 pairwise similarity만 고려했으며 다양한 관계(e.g. A + B = C)는 고려 대상이 아니었다. 또한, diversity 자체를 모델을 통해 학습하려는 시도도 있었으나, 이는 model-specific하기에 기존에 존재하는 추천시스템에 포괄적용하기 어렵다.
- 유사성을 정의하기 위해 기존에 알고 있는 분류 정보를 사용하는 경우도 있으나, 해당 정보가 없는 경우도 많으므로 적절치 않다. 또한 다양성을 평가하기 위한 metric으로 clustering, feature space 등에 기반을 둔 많은 방법이 제시되었다.
- 이 논문은 DPP 모델을 잘 적용할 수 있는 알고리즘을 제시하며, 이를 통해 optimal한 relevalce-diversity trade-off를 찾아낸다. 이때 비유사성(다양성)을 평가하기 위해 아이템의 feature space를 활용한다. 또한 여기서 diversity는 aggregate diversity와 다르며, 후자는 그냥 인기 없는 아이템을 추가해서 다양성만 단순하게 높이는 상황이 발생한다.
3. Fast Greedy MAP Inference
- 위에서 submodular maximization을 하면 MAP of DPP를 찾을 수 있다는 것을 알게 되었고, greedy algorithm을 활용하면 submodular function을 approximiation 제약 안에서 탐색이 가능하단 것을 배웠다. 그렇다면 이제 submodular + greedy의 이론적인 가능성이 아닌, 실제 MAP를 찾아내고자 한다.
- DPP에 대한 greedy MAP inference 는 매 iteration마다 위 식을 만족하는 아이템 j를 추가한다. 이때 L은 PSD 행렬이므로 L의 principal minor(행, 열 세트로 뽑는 submatrix) 역시 PSD이다. 만약 이면, 아래와 같은 cholskey decomposition이 가능하다.
- cf) cholskey decomp: V는 lower triangular matrix. 현재 L이 PSD이므로 unique decomposition은 아니다. PD의 경우엔 대각 성분이 양수이지만, PSD이므로 대각성분은 0보다 크거나 같다.
- cf2) 이고, 이므로, V는 역행렬이 존재한다.
- 이때 새로운 item이 추가되는 경우, 아래의 cholskey docomposition을 유도할 수 있다.이를 풀어보면 새롭게 정의한 행백터 *스칼라 * 는 아래를 만족해야 함을 알 수 있다. V는 역행렬이 존재하므로, 새로운 cholskey factor에 필요한 를 손쉽게 구할 수 있다.
- 또한 lower triangular matrix의 행렬식은 대각 성분의 곱이기 때문에 아래처럼 새로운 행렬식을 유도할 수 있다.이에 따라 위의 submodular + greedy 식을 아래처럼 바꿀 수 있으며, 위에서 보았듯 가 쉽게 구해지므로 greedy 계산이 쉬워진다.따라서 이제 쉽게 다음에 추가할 아이템 j를 찾을 수 있으며, 그 결과 아래 행렬을 얻을 수 있다.
- 다 좋은데 를 모든 후보군에 대해 이렇게 계산하는 것은 연산이 너무 크기 때문에 이것도 incremental하게 업데이트 할 방법을 찾는다. j가 추가된 상황에서 i가 또 추가되는 상황을 생각해보자. 위에서 유도해두었던식을 통해 새로 추가된 에 대해서 를 아래처럼 쓸 수 있다. 쉽게 생각하면 새롭게 바뀐 cholskey factor에 대한 동일한 연산이고, 그것의 i번째 컬럼을 보는 것이다.로 정의하고 위의 연산을 하면 아래처럼 를 유도할 수 있다.역시 손쉽게 구할 수 있다. 따라서, 이제 를 추가할 때 행렬 연산을 할 필요 없이 이전에 추가된 에 대해서만 연산해주면 되는 것이다.
- 처음 iteration을 시작할 때 이므로, 가 되며, 즉 처음에는 가장 큰 대각 성분에 해당하는 원소를 추가한다. 그 뒤 위의 과정을 반복하면 된다. 이 되거나 원하는 item갯수가 다 차면 iteration을 멈춘다. 이 알고리즘은 O(M^3)의 복잡도를 가지며, 갯수를 N으로 제한하는 경우 O(N^2M)의 복잡도를 가진다.

4. Diversity withiin Sliding Window
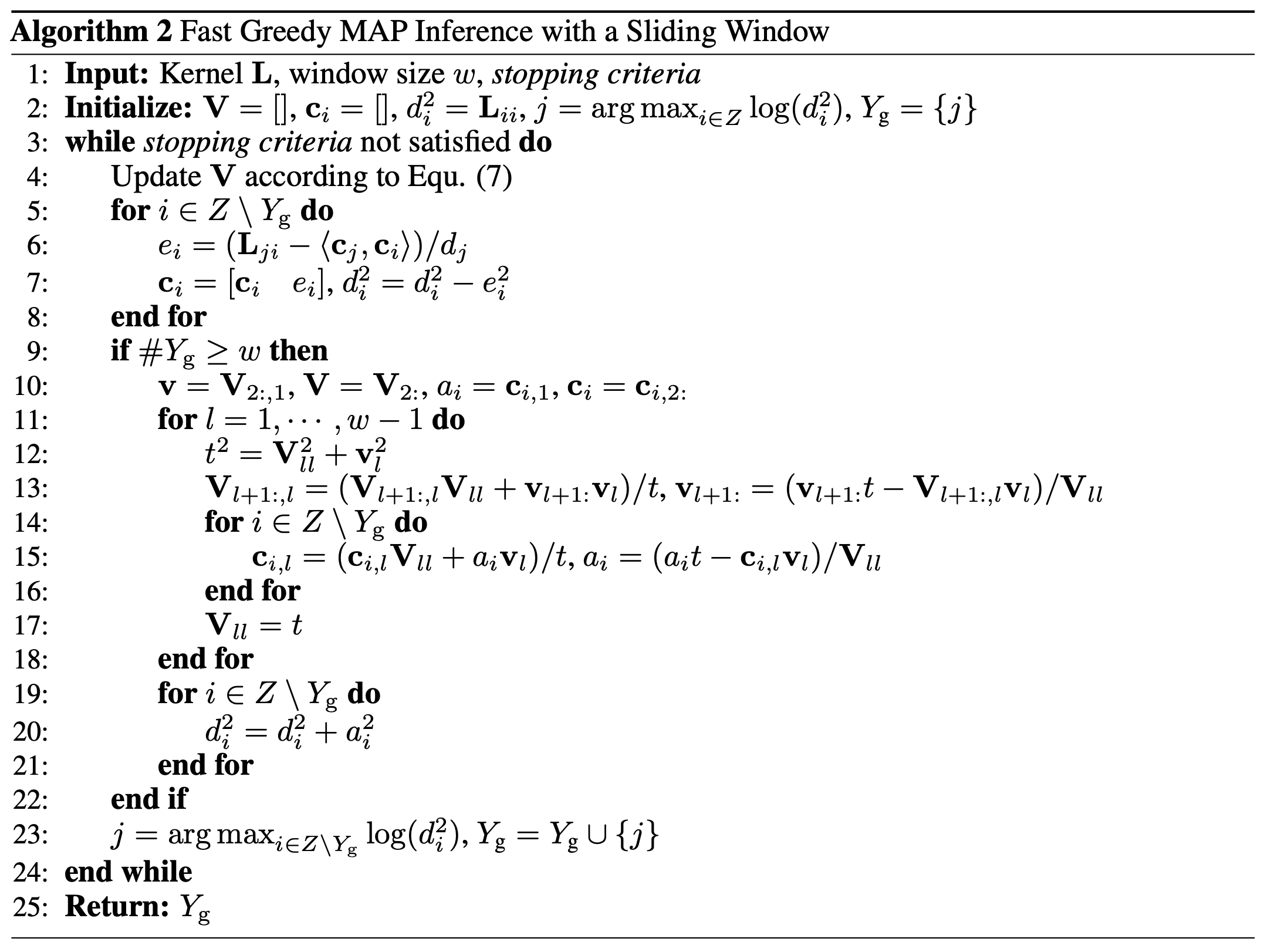
- 특정 범위(w) 내에서만 diversity가 보장되길 바라는 경우도 생각할 수 있다. 그럼 위에 나온 greedy submodular 식을 아래처럼 수정할 수 있다. 단순하게 V가 이젠 의 cholskey factor라 생각하고 위 과정을 수행하면 된다. 에 item을 추가하고 빼는 과정에서 약간의 추가적인 것이 있긴 하지만 여기선 생략한다.
- 전체 시간 복잡도는 O(wNM)으로, 위의 전체에서의 diversity를 추구할 때보다 훨씬 시간이 빠르다.
5. Improving Recommendation Diversity
- 그럼 이제 DPP를 풀어내는 방법을 알았으니, DPP를 이용해서 어떻게 추천 시스템의 relevance-diversity trade off를 조절하는지 알아보자. user가 기존에 선호한 item 를 활용해서 새로운 추천 아이템 를 만든다고 가정하자. 이를 위해서는 아래 세 가지가 필요하다.
- : candidate item set. 추천시스템에서 얻을 수 있음
- : 의 item들 각각에 대한 score vector. 추천시스템에서 얻을 수 있음
- : item pair 간의 similarity를 담은 행렬. item의 특성으로부터 얻음.
- DPP는 kernel matrix를 이용해서 추천시스템에 적용할 수 있다. 기존 연구에서 kernel matrix는 형태의 Gram matrix로 만들 수 있음이 알려졌으며, 이때 B의 각 column은 각 item을 의미한다. 이를 다시 item score , normalized vector 를 이용해서 아래 형태로 L을 정의하는 것도 가능할 것이다.여기서 를 item간의 similarity를 의미하는 지표로 생각한다면, 로 대치할 수 있다. 이렇게 새롭게 정의한 user u의 kernel matrix L은 아래 형태로 쓸 수 있다.이를 이용해서 위에서 계속 사용했듯 log-probability 형태로 를 다시 써주면 아래와 같다.위 식은 결국 relevance(첫 번째 항)과 diversity(두 번째 항)을 적절히 조합해야 max값을 가진다. 특히 두 번째 항은 의 item representation이 orthogonal해야 max가 된다. 따라서 이제 DPP를 max하는 것은 relevance-diversity를 적절히 조절하는 문제가 된다.
- 또한 이전의 연구를 바탕으로 relevance-diversity trade-off를 조절하는 parameter 를 추가하여 위 수식을 아래처럼 변경할 수 있다.를 이렇게 정의할 경우, 아래 kernel을 이용하는 DPP와 동일해진다.submodular 형태로 사용하기 위해 marginal gain of log probability를 다시 아래처럼 정의할 수 있고, 이걸 기존 알고리즘을 약간 수정하여 kernel matrix를 S로 해서 그대로 결합할 수 있다.확실하진 않지만 추정컨데 아래 형태일 것 같다.
- 추가적으로, similarity 의 제약이 필요하며 0에 가까울 수록 diverse, 1에 가까울 수록 similar를 나타낸다. kernel matrix로 S를 사용하기 때문에 determinant>0이라는 기존 조건을 만족시키기 위해선 negative를 제약해야한다. Nonnegativity를 보장하기 위해 S를 그대로 PSD matrix로 유지하면서 아래 linear transformation을 할 수도 있다.
6. Experimental Results
- synthetic dataset, real-world dataset에 대해 평가해본다.
6-1. Synthetic Dataset
-
랜덤하게 데이터를 생성하고, 를 정규분포로 만들었다. 아래 세 가지 알고리즘을 비교했다.
- FaX: 논문에서 제시한 fast, exact 알고리즘
- Lazy: schur compliment combined with lazy evaluation
- ApX: faster approximate algorithm
-
결과가 아래와 같다.
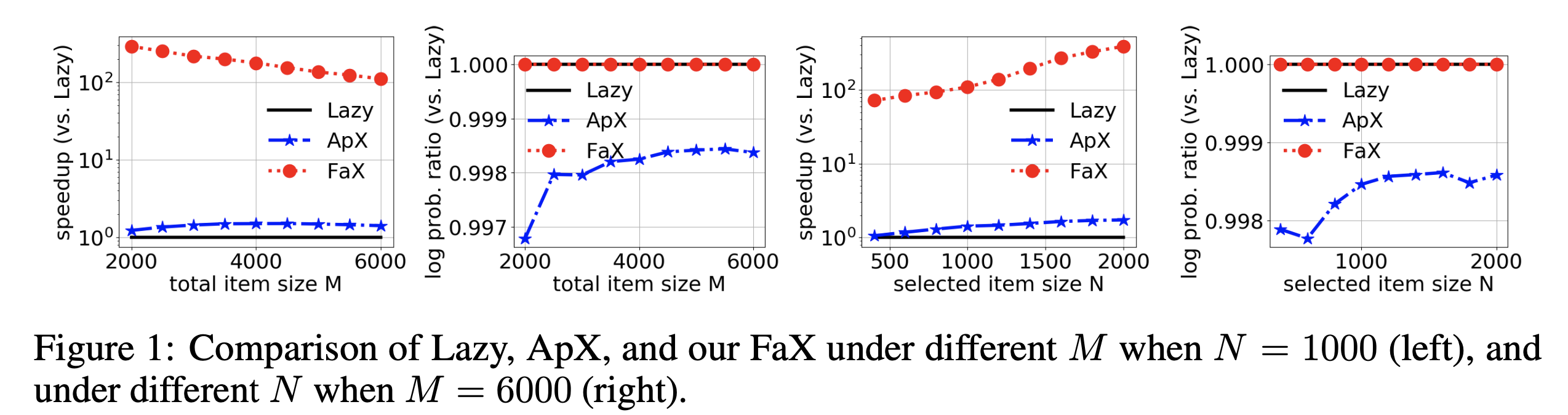
speed up(속도 향상 정도)과 정확성(log-probability)는 모두 Lazy대비로 구했다. 예를 들어 log-probability는 형태다. FaX는 현시점 SOTA fast greedy MAP inference of DPP 알고리즘인 FaX보다 빨랐으며, accuracy가 Lazy와 같았다. 즉, 더 빠르고 정확했다.
6-2. Short Sequence Recommendation
-
Netflix Prize, Million Song Dataset을 활용하여, 짧은 sequence of item 추천에서의 성능을 알아본다. item-based 추천을 사용하며, train-set을 통해 PSD similarity matrix S를 학습한다.
-
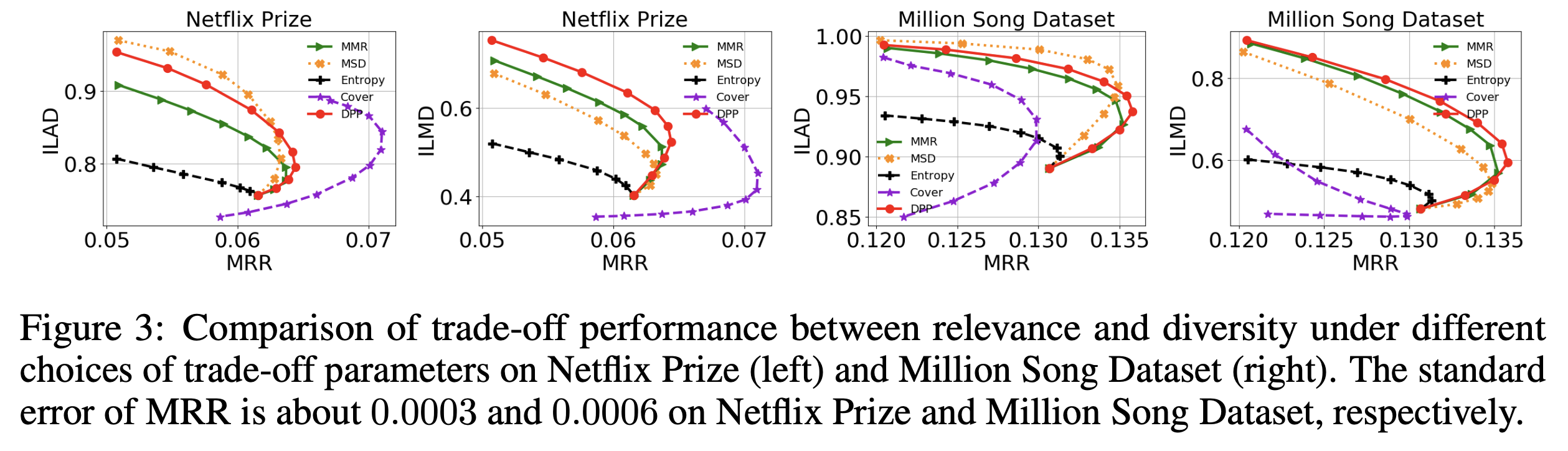
Performance metric으로는 mean reciprocal rank(MRR), intra-list average distance(ILAD), intra-list minimal distance(ILMD)를 사용한다.
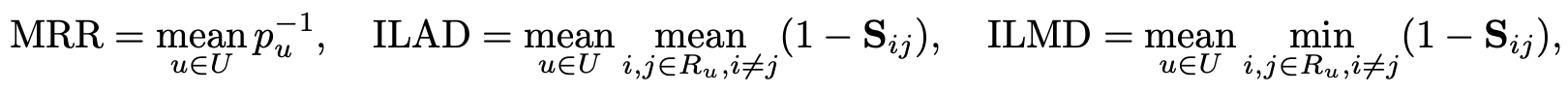
위에서 는 test set의 가장 높은 순위(숫자로는 가장 작은) 값이다. MRR은 relevance, ILAD, ILMD는 diversity를 평가한다.
-
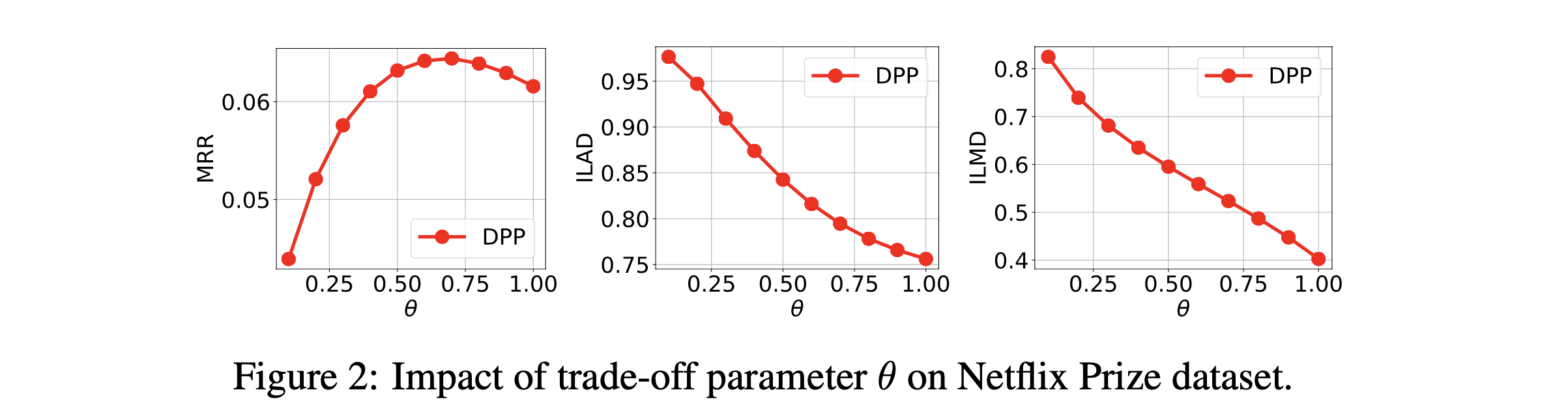
처음 평가한 것은 relevance-diversity trade-off parameter 의 영향이다. 아래서 확인할 수 있듯 가 커지면 relevance가 높아지고 diversity가 줄어든다. 하지만 일정 수준 이상이 되면 relevance가 줄어든다. 따라서 이를 통해 적절한 수준의 로 trade-off 정도를 조절해야함을 알 수 있다.
-
또한 relevance-diversity trade-off를 조절할 수 있는 tunable parameter를 가지고 있는 다른 알고리즘들과도 비교했다.
-
MMR: maximal marginal relevance
-
MSD: max-sum diversification
-
Entropy: entropy regularizer
-
Cover: coverage based algorithm. saturation function의 로 조절

-
서로 다른 알고리즘이 미슷한 MRR값을 갖는 범위에서 비교해보았다. Cover는 netflix에서 좋은 효과를 보여줬지만, million song dataset에서 성능이 가장 낮아서 뺐다. 이 경우 DPP가 가장 relevance-diversity trade-off가 좋았다. 즉, 가장 높은 MRR을 가질 때 diversity가 가장 높았다. 또한 DPP가 가장 빠른 건 아니었으나, 99% 확률로 2ms 안쪽으로 돌았으므로 real-time 활용이 가능했다.
-
online A/B test 역시 진행해보았으며, DPP가 diversity 없는 경우 & MMR을 통해 diversity를 추가한 경우 두 가지보다 성능 향상이 높았다.

-
6-3. Long Sequence Recommendation
-
dataset은 위 그대로. 100개의 item을 추천하는데, window size w=10 안에서 diversity를 추가하는 것으로 해보았다. 일반적으로 w는 한 번에 유저가 보는 item의 갯수로 잡는다.

sequence라 nDCG를 이용해서 평가해보았다. diversity metric을 intra-list로 바꿨으며, 수식은 아래와 같다. 역시 클 수록 좋은 것이다.
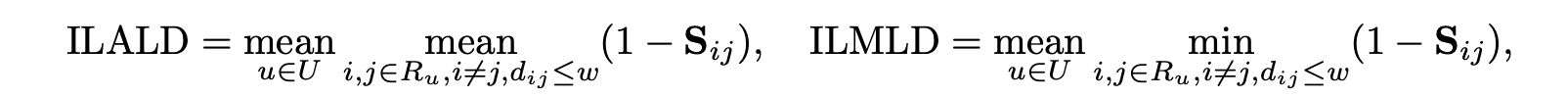
위에서와 마찬가지로 동일한 nDCG 수준에서 더 높은 diversity metric을 갖는 것을 확인할 수 있다.
7. conclusion and future work
- Greedy MAP inference for DPP를 제안했으며 이는 빠르고 exact하다.
- 여기서 제안한 것은 PSD 행렬의 log determinant가 objective function에 포함된 모든 모델에 사용 가능하다.
