[논문 리뷰] Representation Online Matters: Practical End-to-End Diversification in Search and Recommender Systems by pinterest
추천시스템
목록 보기
6/6

pinterest에서 FAccT 2023에 제출한 논문으로, 특별히 새로운 아이디어는 없지만 장기적으로 사용자를 꾸준히 만족시키는 건강한 추천시스템을 만들기 위한 운영적인 노하우를 얻을 수 있는 논문입니다. 추천시스템의 고질적인 문제인 다양성/효용성 최적화에 대해 고민중인 분들에게는 괜찮은 시작점이 될 수 있을 것 같습니다.
한국어 의역을 최대한 하려고 했으나, 영어가 더 맞는 전문 용어들은 왠만하면 그대로 두었습니다.
0. Abstract
- 여러 인종이 온라인 플랫폼을 사용할 때, 사람들은 자신의 인종이 콘텐츠에서 대변되기를 원한다. 이러한 대표성을 검색/추천 결과에서 보장하기 위해서 retrieval부터 ranking까지 다양한 컨텐츠가 장애물 없이 이어질 수 있도록 하는 end-to-end 다양화를 제안한다.
- 여기서 제안되는 내용은 확장 가능(scalable)하며, 실제 서비스 환경에서 실험되었다.
- 미용/패션 분야에서 여러 피부색을 가진 컨텐츠가 다양하게 추천될 수 있도록 하였다.
- 다양화는 크게 세 가지 구성요소로 이뤄진다.
- 다양화를 필요로 하는 요청을 확인한다.
- 거대한 코퍼스에서 다양한 컨텐츠가 1차로 추출될 수 있도록 한다.
- 다양성-효용성 간의 균형이 이뤄질 수 있도록 랭킹 단계에서 조절한다.
- 추천의 각 단계는 아래처럼 발전되었다.
- Retrieval 단계(1단계)는 Strong-OR 논리 연산자 사용부터 버킷화된 retrieval 사용까지 발전되었다.
- Ranking 단계(2단계)는 greedy reranking 사용부터 determinaltal point process(dpp)를 활용한 다양한 목표에 대한 최적화로 발전되었다.
- 이 실험은 다양성 지표를 크게 개선하였으며, 효용성 지표에 대해서도 중립 혹은 긍정적인 영향을 미쳤고(즉 부정적 영향 없음), 양적/질적으로 사용자의 만족도를 개선하는 것이 확인되었다.
1. Introduction

- 다양한 인종이 온라인 플랫폼을 사용하기 시작하면서, 이들을 모두 대변할 필요성이 커졌으나, 검색 결과나 소셜 미디어에서는 아직 그러한 기능이 부족하다.
- 이러한 다양성에 집중하여 좀더 포용적이고 공정한 온라인 경험을 유도하는 것이 필요하다.
- 다양한 사용자를 대변하면 그들의 플랫폼에 대한 만족도와 믿음이 높아지며, 비즈니스적으로도 긍정적인 영향을 미친다.
- 이 논문에서는 대규모 검색/추천 시스템에서 다양화를 적용하기 위한 실험을 다룬다. 그 중에서 특히 핀터레스트에서 시각적 탐색 과정에서의 다양화에 대해 다룬다.
- 핀터레스트의 검색, 연관 상품 추천, 신규 유저 홈피드 세 지면에서 다양성을 적용하는 데에 집중하였다.
- 특히, 시각적인 피부톤을 사용하여 scalable한 다양화 시스템을 서빙한 경험을 다룬다.
- end-to-end 다양화 과정은 세 가지 구성요소로 이뤄져있다.
- 다양화 과정을 필요로 하는 요청
- 대규모 컨텐츠 코퍼스에서 다양한 컨텐츠가 뽑힐 수 있도록 보장하는 다양화 로직
- 사용자의 효용과 다양성 사이의 균형을 맟출 수 있는 다양화가 반영된 랭킹 로직
- Multi-stage 다양화는 retrival부터 랭킹까지 전 과정에서 다양화가 이뤄질 수 있도록 해야한다. 즉, 이 중 어느 한 단계라도 다양화가 빠지면 최종적으로 사용자에게 전달되는 지면은 다양성을 가질 수가 없다.
- 추천 시스템의 다양성 대변 분야에서 여러가지 새로운 공헌을 하였다.
- 처음으로 실서비스에서 피부색 다양화를 이뤄냈으며, 이를 통해 대규모 검색/추천 시스템에서 이들에 대한 대변성을 강화하였다.
- retrieval(1단계)와 ranking(2단계)에서 모두 다양성이 보장되는
multi-stage diversification system을 개발하였다.- 랭킹에서는
greedy reranker와determinaltal point process(dpp)를 활용한 multi-objective optimization을 개발하였다. - 후보군 생성(retrieval) 단계에서는
Strong-OR을 활용하여 토큰 기반 인덱스에 대한 검색을 하였고,Overfetch-and-Rerank and Bucketized-ANN을 활용하여 임베딩 기반의 인덱스에 대한 검색을 하였다. - 실제로 다양성을 반영한 추천 시스템을 대규모 사용자에게 서빙했을 때 배운 점을 공유한다.
- 사용자의 다양성과 효용성에 대한 수요를 효과적으로 충족한 실증적인 결과를 공유한다.
- 랭킹에서는
- 전체 랭킹 파이프라인 과정에서 최종 단계의 다양성은 앞선 과정에서의 다양성으로부터 상한선을 얻게 된다. 따라서 앞선 후보군 생성(retrieval) 단게예서의 다양성이 매우 중요하다.
2. Related work
- 신선함(novelty)와 다양성(diversity)를 가진 랭킹은 information retrieval(IR) 분야에서 오랫동안 관심의 대상이었다. 다양성을 평가하기 위한 메트릭도 많이 제안되었다. 아래 메트릭들을 최적화하는 것은 일반적으로 NP-hard 하지만, 목적함수를 submodular하게 바꿔서 사용할 수 있는 경우들도 있다.
- 추천된 subtopic의 갯수를 세는 precision/recall
- Discounted Cumulative Gain (DCG)에 기반한 information nugget - 어느 토픽 하나를 너무 많이 추천하는 것에 대해 패널티 부여
- 전통적인 IR 매트릭
- 검색 및 추천시스템 분야에서 다양성과 효용성 간의 균형을 맞추기 위한 기술은 많이 제안되어왔다.
- 휴리스틱한 greedy reranking
- 우선순위를 사용하기
- 기존에 선택된 결과들과 관련성 및 maximal marginal relevance(mmr)을 pariwise하게 비교하여 다음 추천 아이템을 고르는 방법
- DPP와 같이 다양한 목적에 대한 최적화를 하는 확률적 방법
- DPP는 MMR보다 다양화에 더 효과적이라고 알려져있다. MMR은 바로 직전 아이템과만 비교하는 반면, DPP는 전체 pair에 대해서 비교하기 때문이다.
- DPP는 NP-hard하지만, submodular한 특성 때문에 효율적으로 근사할 수 있다.
3. MULTI-STAGE DIVERSIFICATION IN SEARCH AND RECOMMENDER SYSTEMS
3-1. Background
- 대규모 검색/추천 시스템은 다양한 구성요소를 가지고 있다. 이들은 대부분 인풋 쿼리/컨텐츠/사용자/과거활동 등을 받아서 특정한 목적함수에 대해 최적화된 결과를 뱉는 ML 모델들로 구성되어 있다.
- 위와 같은 시스템은 대부분 2단계(retrieval + ranking)으로 구성되며, 때로 맨 뒤에 추가적인 비즈니스 로직이 붙는다.
3-1-1. Retrieval(후보군 생성)
- 하나 또는 그 이상의 후보군 생성 모델들로 이뤄져있다(역자 주: 편의상 후보군 생성으로 뭉뚱그려 칭하겠음). 이들은 거대한 아이템 코퍼스에서 더 작은 아이템 집합으로 후보를 추리는 역할을 한다.
- recall이 높으면서 레이턴시가 낮아야하기 때문에, 많은 경우에 인덱스 기반 검색을 수행하는데, 이때 인덱스는 각 아이템의 정보를 담고 있도록 한다.
- 토큰 기반의 인텍스는 말 그대로 토큰을 사용한다. 예를 들면 특정 단어가 쿼리에 들어가 있는지 같은 걸 볼 수 있다.
- 임베딩 기반의 인덱스는 여러 개의 연속형 변수(dense) 값을 사용하며, k-nearest neighbor 같은 근사적인 방법을 사용한다. 이러한 임베딩은 matrix factorization, GNN 등의 결과물로 나온 값들이 사용된다.
- recall이 높으면서 레이턴시가 낮아야하기 때문에, 많은 경우에 인덱스 기반 검색을 수행하는데, 이때 인덱스는 각 아이템의 정보를 담고 있도록 한다.
- 일반적으로 추천 시스템은 다양한 후보군 생성 모델들로 이뤄져 있고, 다음 단계로 넘어가기 전에 합쳐지는 과정을 거친다.
3-1-2. Ranking
- 랭킹 단계에서는 특정 목적함수 혹은 목적함수의 결합을 최대화하는 아이템의 순서를 정한다.
- 이때 목적함수는 효용 함수, 다양성 함수, 추가적인 사업상의 목적 함수 등이 될 수 있다.
- 효용성 지표는 어디에 적용하느냐에 따라 크게 달라지지만 랭킹은 그와 무관하게 단순히 각 item에 대한 점수를 메기는 point-wise를 주로 사용한다.
- 모델은 각 아이템이 구입될 확률, 클릭될 확률 등을 예측하고, 이러한 다양한 목적을 잘 섞어서 최종 랭킹 리스트를 만든다.
- 일반적으로 섞는 방법은 가중합을 많이 사용하고, 혹은 이를 섞기 위한 모델을 추가로 학습하는 경우도 있다.
3-2. Diversity in Recommendations
3-2-1. Diversity Dimension
- 다양화라는 것은, 시스템이 노출시키는 아이템들이 사용자의 관심사에 대한 다양성의 차원을 다양하게 구성하는 것을 목표로 하는 것이다. → 그니까, 관심사를 여러 차원으로 섞어주는 것을 의미한다.
- 이런 다양화의 차원은 성별, 연령 같은 인구학적 특성부터 국가 언어, 피부색, 음식의 종류 등과 같이 명확하게 구분이 되는 경우가 있으나, 그렇지 않은 경우도 있다. 이때는 일반적으로 임베딩이나 군집을 통한 잠재 변수로 구분된다.
- 이 논문에서는 피부색에 대한 다양화만 다루지만, 여기서 제안되는 방법은 이러한 한 가지 차원이 아닌 다양한 차원의 다양화도 가능하다.
- 전체 다양화 차원의 집합을 라고 하고, 각각의 그룹을 로 표기한다.
3-2-2. Diversity Metric
- 쿼리의 집합 Q에 대하여 랭킹 시스템 R의 상위 k개에 대한 다양성은 아래와 같이 정의된다.
- 위에서 I는 indicator function이다.
- 즉, 쿼리들이 주어졌을 때, 모든 다양성의 차원이 등장한(어찌 보면 존중된) 쿼리가 평균적으로 몇 %나 되는가를 나타낸다.
- 모든 다양성의 차원이 top-k에 등장해야한다는 점에서 어찌보면 강력한 metric이다.
- 우리의 관심이 되는 다양성의 차원에 들어가지 않는 아이템은 제외된다. 예를 들어 우리가 관심 있는 건 피부색인데, 피부가 존재하지 않는 포스트(e.g. 장난감)이 나왔다면 이는 다양성 계산에 고려되지 않는다.
- 이 논문은 위에서 제안하는 Div@k(R)을 주요한 다양성 지표로 사용하며 추가적인 지표들도 이해를 돕기 위해 사용한다.
- normalized entropy of the distribution with respect to the diversity dimension in top-k items 도 그 중 하나의 지표이다.
3-2-3. Multi-stage diversification
- 후보군 생성(retrieval)과 랭킹 단계 모두 최종 노출되는 컨텐츠의 다양성에 영향을 미친다. 그 중 후보군 생성 단계의 다양성 정도는 최종 랭킹 결과물의 다양성의 상한선(upper bound)로 작용한다.
- 따라서, 후보군 생성 단계에서는 랭킹 단계에서 다양한 추천을 할 수 있는 아이템이 존재할 수 있게 충분한 다양성이 보장된 후보군 집합을 뽑아내야 한다.
- 물론 그렇게 넘겨줘도 랭커는 일반적으로 사용자의 효용에 좀더 집중하기 때문에 다양성이 보장되지 않는다. 때문에 랭커도 다양성을 고려한 랭킹을 명시적으로 매겨야한다.
- 이후 section 7에서 다양한 서비스에서 다양화를 적용했을 때의 결과를 확인할 수 있다. 이때 다양화 지표를 올리면 사용자의 서비스 사용량(engagement) 등 효용성 지표들이 중립 혹은 긍정적인 반응을 얻었다. 즉, 적어도 부정적 영향은 없었다.
- 이는 다양성을 늘리면서 효용은 감소시키지 않았기 때문에, 기존의 추천 시스템은 다양성과 효용 간의 파레토 효율점에 위치하지 않았다고도 볼 수 있다.
- 전체 추천 파이프라인에서 보면 뒷 단계의 다양성은 그 이전 단계의 다양성에 상한되어 있다(upper bounded). 따라서 후보군 생성(retrieval) 단계에서의 다양성 증가, 혹은 컨텐츠 코퍼스 그 자체의 다양성 증가는 위처럼 파레토 효율적인 추천 시스템으로 변화시킨다.
- 한편으론 후보군 생성과 랭킹 모델이 아무리 다양성을 추구해도 컨텐츠 코퍼스 자체가 다양하지 않다면 말짱 도루묵이라는 것이다. 이 때는 더 많은 컨텐츠를 소싱할 필요가 있다.
3-2-4. Triggering logic
- 현실 세계의 검색/추천 시스템은 다양한 카테고리에 대한 요청을 받는다. 이때 사용자의 관심사에 대한 다양성의 차원은 현재 요구되는 게 어떤 분야인가에 따라 달라지게 된다.
- 예를 들어, 이 논문에서 계속 말하는 피부색은 패션이나 미용 분야에 대해서는 적용 가능하지만, 인테리어 같은 관심사에는 적용될 수가 없다.
- 따라서 처음 요청이 들어왔을 때, 다양성 로직을 적용할 수 있는 분야인가를 결정할 필요가 있다. 이걸 결정하기 위해선 해당 쿼리의 카테고리를 예측하는 모델을 써도 되고, 어떤 지면에서 들어온 요청인지 등등 휴리스틱한 방법을 쓸 수도 있다.
- 사람에 따라 기대하는 개인화와 다양화의 정도는 다를 수 있다.
- 누군가는 검색 결과와 연관 검색 항목, 자신의 홈피드(추천 메인 화면)에서 모두 다양화된 결과를 원할 수도 있지만, 누군가는 홈피드만큼은 다양화가 적었으면 할 수도 있다.
- 이 논문에서는 사용자의 피드백, 사용자에 대한 조사, 피부색과 관련된 쿼리를 수정해서 날렸던 기록이 있는지에 대한 분석 등을 토대로 어떤 카테고리와 어떤 페이지에서 다양성 조건이 발현될지를 결정하였다.
- 검색, 연관 항목, 새로운 사용자의 홈피드(coldstart)의 패션 및 미용 카테고리에 대해서만 다양화 조건이 발현되도록 하였다.
- 이를 발전시키면 사용자가 다양성의 정도를 자신이 직접 원하는 때에 조절하도록 할 수도 있을 것이다.(아직은 안 했다)
4. DIVERSIFICATION AT THE RANKING STAGE
- 먼저 전체 추천 시스템의 마지막 단계이자 가장 직접적인 영향을 미치는 랭킹 단계에서의 다양화를 다룬다.
- 가장 일반적이고 쉬운 방법은 현재 덜 나온 다양성 차원의 컨텐츠의 score에 가중치를 곱하는 방법일 것이다.
- 하지만 이는 처음에만 조절하여 사용하면 미래에 어떤 영향을 미칠지 모르며, 여러 가중치를 사용하게 되면 이를 결합하여 조절해야하는 문제가 발생한다. → 기술부채이다.
- 위처럼 단순한 방법 대신 효용성 점수와 다양성 차원이 결합된 아이템 리스트를 받으면, 이를 두 가지 목적에 맞게 잘 정렬하여 리턴하는 랭킹 단계를 만들고자 한다. 이러한 다양성이 고려된 랭킹을 위해 두 가지를 제안한다.
- Round-Robin
- Determinaltal point process
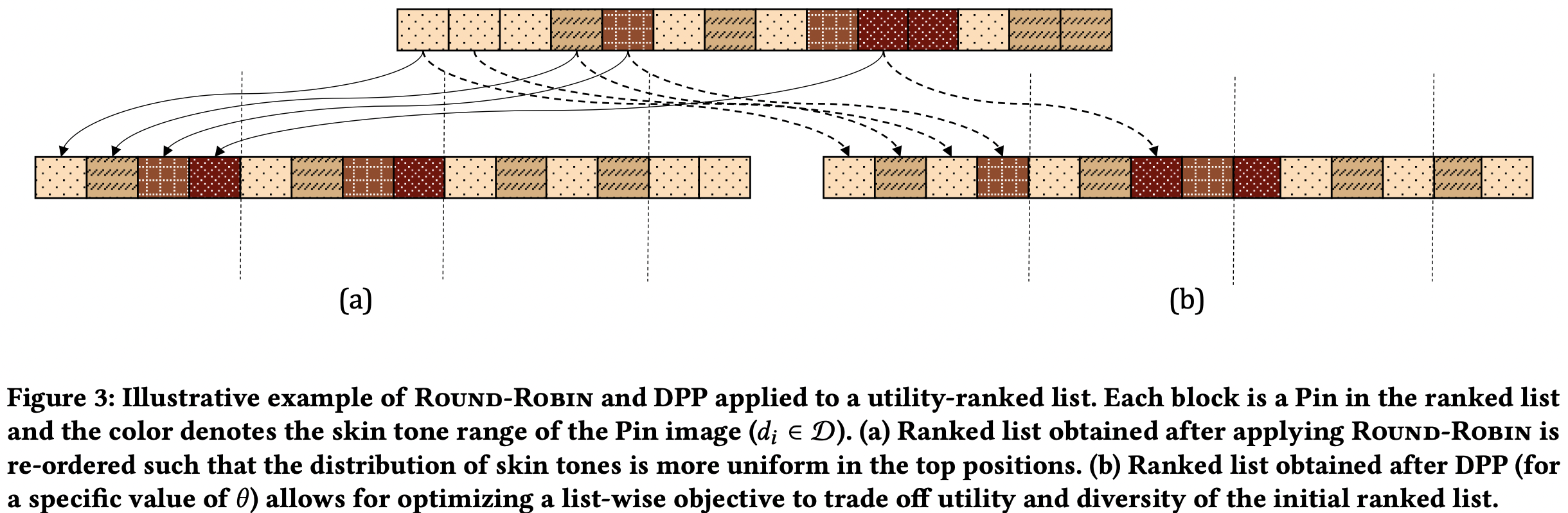
4-1. Round-Robin(RR)
- 아래 순서로 진행한다.
- 예측된 효용 점수(utility score)를 기반으로 의 정렬된 리스트를 만든다.
- 위의 리스트를 각자의 다양성 차원에 해당하는 개의 정렬된 sublist로 만든다. 이 때 효용 점수가 일정 임계치 이상인 것들만 담는다.
- 각 리스트의 top item을 하나씩 꺼내서 리스트를 재구성한다.
- 어떠한 다양성 차원에도 속하지 않거나, 임계치 이하의 점수를 가지고 있던 아이템들은 원래의 위치에 둔다.
- 위의 figure 3-a를 보면 RR의 결과를 볼 수 있다. 4 개의 그룹에 대하여 상위권에서 균등하게 분포가 이뤄질 수 있도록 한다.
- window size 안에서(위의 경우 4) 순서를 섞는 약간의 커스텀도 가능하다. 즉 위처럼 계속 똑같은 사이클이 아니게 해서 사용자가 좀 덜 지루하게 할 수 있다.
- 각 sublist별 갯수가 다르기 때문에 어느 하나가 더 빨리 끝나게 된다. 이 땐 여러 방법이 가능하다.
- 아직 남아 있는 sublist에서 계속 RR 하기
- 남아있는 sublist끼리 짝지어 결합하고 RR하기.
- e.g. {d1, d2} vs, {d3, d4} 로 RR하기.
- RR은 간단하고 직관적인 다양화 방법이지만, 다양성과 효용성 간의 균형을 제대로 맞추는 방법은 아니며, 여러 차원의 다양성이 존재하거나, 여러 종류의 효용성을 합쳐야하는 경우 알맞게 동작하지 않는다.
4-2. Determinantal Point Process (DPP)
- Determinantal Point Process는 원래는 입자 물리학에서 사용되던 확률적 모델이며, 최근에는 추천 시스템에서 많이 사용된다.
- DPP는 특히 ML 분야 중에서 다양성과 대표성이 큰 부분집합을 찾는 문제에서 많이 사용된다. 이 논문에서는 다양성을 고려한 reranking에 어떻게 사용할 수 있는지 다룬다.
- 역자 주: DPP는 사실 내용 자체가 책 한 권 짜리라 여기서 한 파트만으로 설명되긴 무리가 있습니다. 그냥 그런 좋은 게 있다 정도로 이해하면 되고, 좀더 알고 싶으신 분은 제 블로그의 DPP 포스팅을 추천드립니다.
- N의 크기를 갖는 집합에 대하여 Y라는 부분집합을 정의해보자. 이때 N에 대하여 정의될 수 있는 모든 부분집합 중에 Y라는 해당 집합을 선택할 확률을 모델링해볼 수 있을 것이다. DPP는 이러한 모든 부분집합에 대해 정의되는 probability measure이다. DPP는 다양성이 더 높은 부분집합에 더 높은 확률 값을 부여한다.
- DPP의 가장 큰 특징은 P(Y)가 어떠한 kernel matrix 에 대하여 해당 matrix의 행렬식(determinant)에 대응된다는 점이다.
- 여기서 L은 kernel function이며, 해당 함수는 각 아이템의 효용 및 다른 아이템 간의 유사성을 요약하는 함수이다. 는 부분집합 Y에 대해 이러한 kernel function을 적용한 kernel matrix이다.
- 는 kernel function L에 의해 정의되는 특정 공간에서 Y라는 점들이 얼마나 퍼져있는가를 측정하는 measure로 생각할 수 있다.
- 대각성분 는 각 아이템의 효용을 나타낸다.
- 나머지 성분 는 서로 다른 아이템들 간의 유사도이다.
- kernel은 L은 positive semi definite(PSD) 행렬이면서 cholesky decomposition을 가져야한다. 따라서 아래처럼 다시 쓸 수 있다.
- 각 item i의 효용 를 요약하는 대각 행렬.
- 는 효용과 다양성 간의 tradeoff를 조절하는 파라미터
- , 는 각 i번째 아이템의 feature vector.
- 어차피 는 symmetetric similiarity 행렬이니 S로 다시 쓸 수 있다.
- 위를 정리하면 아래처럼 쓸 수 있다.
- - ( eq. 4)
- log determinant를 뜯어보면 효용항과 다양성 항의 가중합으로 이뤄진 것을 알 수 있다.
- 즉, 위에서 말한 determinant를 max 시키면 우리가 원하는 효용성과 다양성의 tradeoff를 최적화 하는 선택이라는 의미가 된다.
- 이때, 와 kernel matrix L이 주어지면 우리 목표인 행렬식을 최대화 시키는 부분집합을 구할 수 있을 것이다.
- 정의한 kernel matrix에 대해서 해당 는 효용성과 다양성을 가장 잘 균형맞춘 subset이 될 것이다.
- 문제: 를 찾는 것은 NP-hard 이다.
- 다행인 것은 이것이 submodular한 특성을 가지고 있기 때문에 greedy algorithm이 사용 가능하다는 점이다. 에서 시작해서 아래 방식으로 추가해나간다.
- w는 sliding window size이며, 가장 마지막 w개의 아이템만 계산한다는 의미이다. 정확성이 떨어지지만 계산의 효율성을 위해 사용한다.
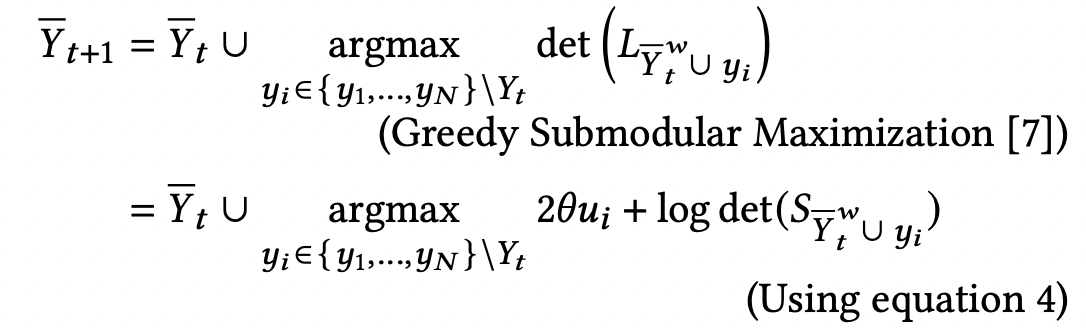
- 정리하자면, DPP를 사용하면 효용-다양성 trade-off가 근사적이지만(greedy) 가장 균형 잡힌 subset을 얻을 수 있게 된다.
- 의 역할
- 클 경우: 효용성 중시
- 작을 경우: 다양성 중시. 매우 작아지면 RR과 유사한 결과를 엊게 됨
- 추가적인 고려 사항
- kernel matrix L을 뉴럴넷으로 학습하는 경우도 있다.
- 는 grid search 를 통해 튜닝할 수 있다.
- DPP의 추가적인 장점은 다양성의 기준이 여러가지일 때도 사용 가능하다는 것이다. 이를 합쳐서(jointly) 요약할 수 있는 유사도 행렬 만 정의해주면 똑같이 dpp가 적용될 수 있다.
- 더 간단하게는 4번 식에 또다른 유사도 행렬의 log det도 더해주는 방법도 가능하다.
5. DIVERSIFICATION AT RETRIEVAL STAGE
- 위에서 설명한 랭킹 단계의 다양성은 앞선 후보군 생성(retrieval)단계의 다양성에 상한되어 있다. 따라서 뒤이은 랭킹 단계의 reranking 방법론들이 빛을 발하기 위해 후보군 생성 단계에서 충분한 다양성이 보장되어야 한다.
- 이 장에서는 세 가지 방법론을 다룬다.
- Overfetch-and-Rerank
- 모든 retrieval 방법론에 적용 가능하지만, 현실 세계에 적용하기 어려운 경우가 있다
- Strong-OR logic
- Bucketized-ANN Retrieval
- Overfetch-and-Rerank
5-1. Overfetch-and-Rerank at Retrieval
- 가장 간단한 방법 - 후보군을 더 많이 뽑아서 다양성을 높인다.
- 예를 들어, KNN을 이용한 후보군 생성의 경우, K개를 뽑을 걸 K
(K>K) 개를 뽑은 뒤 여기에 round robin을 적용하여 K개로 줄인다.
- 예를 들어, KNN을 이용한 후보군 생성의 경우, K개를 뽑을 걸 K
- 문제는 속도가 느려진다. 이를 해결하기 위해 K-max를 정해서 속도 저하량을 제한하는 방법과, 각 다양성 차원의 갯수에 대한 최소 임계값을 정해서 그 이상의 아이템이 뽑히면 K-max 도달 전에 RR 적용하는 방법이 있다.
5-2. Bucketized-ANN Retrieval
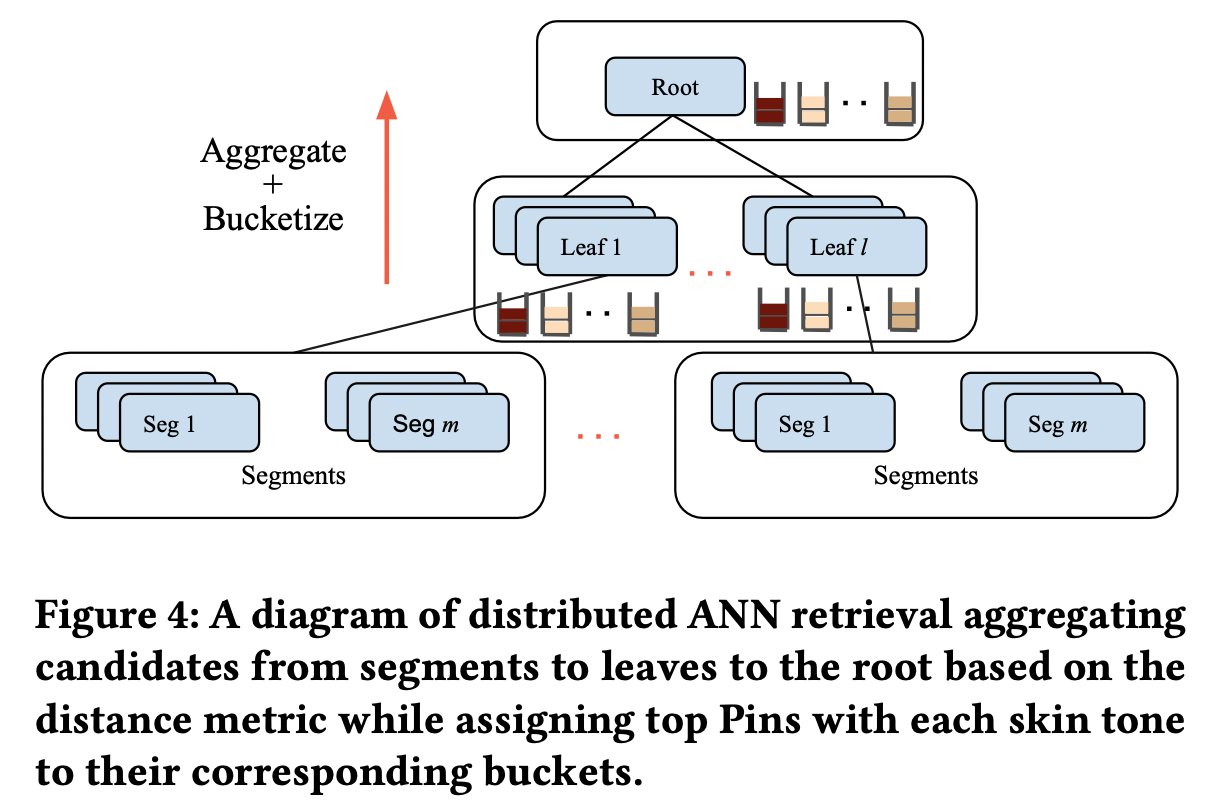
- 임베딩 기반의 후보군 생성에 가장 많이 사용되는 것은 approximate nearest neighbor(ANN)이다.
- 전체 query-item 쌍에 대해서 거리를 구하는 것은 실시간 추천에서 불가능하기 때문에 일반적으로 근사 알고리즘을 사용하며, 대표적으로
k-Dimensional Tree,Locality-sensitive Hasing(LSH),Hierarchical Navigable Small Worlds(HNSW)방법들이 사용된다. - 위의 방법들은 대부분 임베딩을 특정 부분 공간으로 나눈 뒤에 그 안에서 검색을 수행한다.
- 아이템 갯수가 10억 개를 넘어가는 매우 거대한 추천 시스템의 경우, 위 방법들을 분산 환경에서 수행한다.
- 전체 query-item 쌍에 대해서 거리를 구하는 것은 실시간 추천에서 불가능하기 때문에 일반적으로 근사 알고리즘을 사용하며, 대표적으로
- 일반적은 ANN 검색 시스템은 아래 세 종류의 구성요소를 갖는다.
- root node:
- leaf node로 요청을 보낸다.
- leaf들이 찾은 L*K개에 대하여 최근접 K개만 추린다.
- leaf node(L개):
- segment로 요청을 보낸다
- segment들이 찾은 M*K개의 임베딩 중에서 최근접 K개만 추려서 root로 보낸다.
- segment(M개):
- 전체 임베딩 공간의 부분 공간 내에서 주어진 query의 근접 이웃을 찾는다.
- 찾은 K개의 근접 이웃을 leaf로 보낸다.
- root node:
Bucketized-ANN Retrieval은 조금 다르다.- root와 leaf의 aggregate 단계에서 K개를 추리는 대신, 각 다양성 그룹 별로 개의 후보군들을 추려낸다.
- 한 번에 추려내다보면 각 그룹별 다양성이 존중되지 못할 수 있는데 이 방법이면 그룹별 다양성이 보존되기 때문에
overfetch방법론에 비해 우위가 있다. - 따라서 각 aggregation 단계에서 최대 개의 후보군을 추린다.
5-3. Strong-OR Retrieval
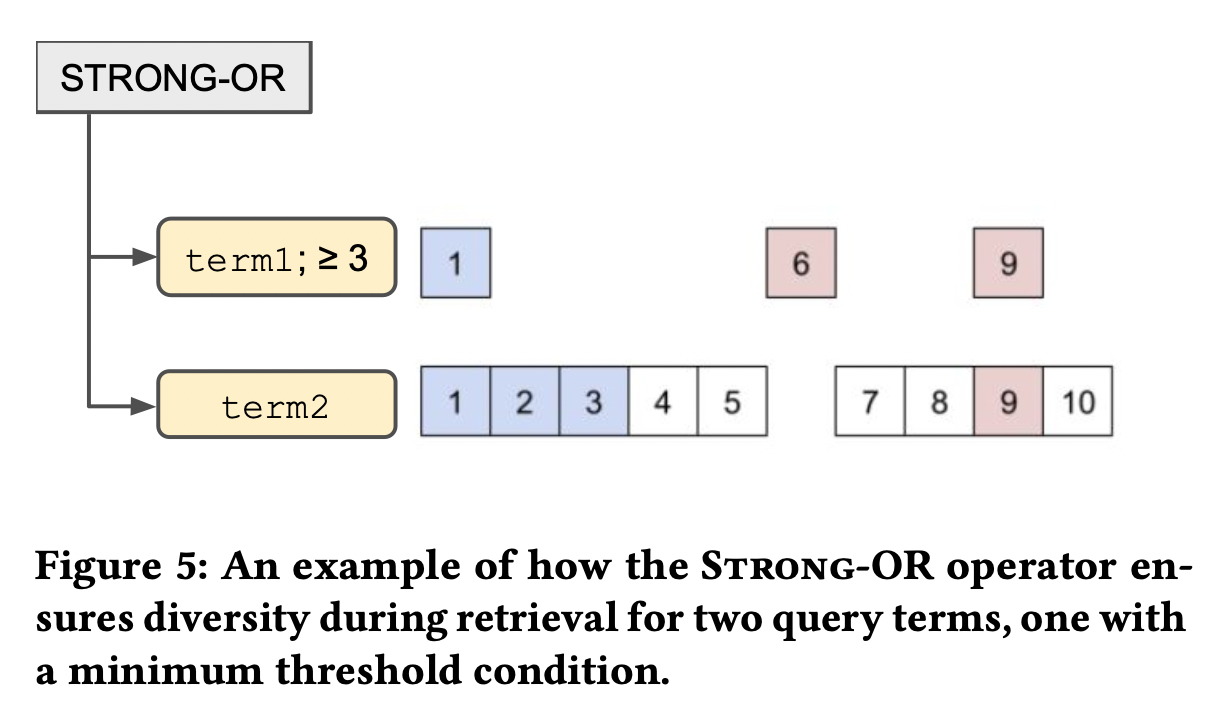
- 검색에서 쿼리를 이해하는 단계는 전체 과정 중 가장 중요한 구성 요소 중 하나이며, 이때 문자열 쿼리는 structured query(s-query)로 변환된다.
- 이는 쿼리에 포함된 단어들 간의 관계를 논리연산자로 표현하는 것이다. 따라서 이를 통해 retrieval system이 결과 집합을 조절할 수 있다.
- e.g. 검거나 붉은 드레스를 찾아줘 → dress AND (red OR black).
- 다양성 차원에서 주목받지 못하는 그룹들의 결과도 포함시켜주는 것이 목적이기 때문에
STRONG-OR이라 불리는 특별한 논리 연산자를 사용한다.- OR연산과 기본적으론 비슷한데 여기에 어떤 조건ㅇ르 추가하는 것이다. conditional OR이라고 생각해도 된다.
- 추가되는 조건을 로 명시한다.
- 위의 figure-5의 경우, 아래와 같다.
- = term1≥p%, (뽑으려는 갯수), K=10
- 즉, top 10개를 뽑았을 때 이중 OR 조건을 만족하는 5개를 1등부터 순서대로 뽑아가는 것이다.
- 4,5는 6보다 순위가 높지만 term1이 3개 이상 뽑혀야 한다는 조건 때문에 뽑히지 못했다.
- K라는 최대 스캔 갯수가 명시 되었기 때문에 전체 코퍼스에서 이와 같은 strong-OR스캔을 하진 않았다. → 너무 느려지는 걸 방지하기 위함인 듯.
6. PRODUCTIONIZATION CONSIDERATIONS FOR A LARGE SCALE RECOMMENDER SYSTEM
- 핀터레스트의 검색, 신규 유저 홈피드, 연관 상품 지면에서 실험해보았다.
- 검색: 말 그대로 검색해서 원하는 핀 찾는다.
- 신규 유저 홈피드: 처음 가입하고 보는 최초의 홈피드
- 연관 상품: 사용자가 선택 핀과 유사한 핀들을 나열해준다. (마치 인스타그램 유사 피드)
6-1. Indexing
- Retrieval 단계에서 임베딩 기반 혹은 토큰 기반으로 다양성을 반영하기 위해선 일단 각 pin(item)의 다양성 차원을 표시(indexing) 해두어야한다.
- 각 핀에 대하여 피부 색을 비젼 모델을 활용하여 offline batch로 라벨링한다. 모델이 주기적으로 돌면서 db에서 각 pin 에 대해 label을 다는 것이다.
- 이는 retrieval 단계와 ranking 단계에서 모두 사용된다.
- ranking의 경우, retreival에서 넘어온 라벨을 사용할 수도 있고, 스토리지나 캐시에서 직접 읽어올 수도 있다.
6-2. Latency and Scaling Considerations
- 앞서 말한 RR은 다양한 문제가 있다.
- Round-Robin은 다양성 차원이 하나(e.g. 인종)인 경우엔 선형 복잡도라 레이턴시 문제가 크지 않지만 하나 이상의 다양성(e.g. 패션, 뷰티, 인테리어와 같은 핀 카테고리도 고려하고 싶다)을 함께 고려하는 경우 가능한 조합의 갯수가 늘어나기 때문에 레이턴시 문제가 커진다.
- 이러한 다양한 차원 전체에 대해 적용하는 우선순위 큐가 대안이 될 수 있다.
- 또한 RR은 다양성/효용성 간의 trade-off에 대한 명확한 기준이 없다.
- 어떠한 다양성 차원에도 속하지 않는 아이템은 상대적으로 막 다룬다(e.g. 피부가 아예 없는 이미지)
- 원래 위치에 그대로 두거나, 이것들도 RR에 포함시켜서 주기적으로 랜덤 샘플링 할 수도 있을 것이다.
- RR을 전체 다에 적용하면 느리니까 상위 몇 개까지만 RR 적용하는 것도 고려해볼 수 있다.
- 사용자가 실제로 정말 관심없는, 최하위권에 위치한 pin인데 RR 때문에 위로 올라오고 그 반대가 될 수도 있다.
- 공정한 랭킹 모델이 무엇인지 평가할 지표의 필요성을 제기한다.
- Round-Robin은 다양성 차원이 하나(e.g. 인종)인 경우엔 선형 복잡도라 레이턴시 문제가 크지 않지만 하나 이상의 다양성(e.g. 패션, 뷰티, 인테리어와 같은 핀 카테고리도 고려하고 싶다)을 함께 고려하는 경우 가능한 조합의 갯수가 늘어나기 때문에 레이턴시 문제가 커진다.
- DPP의 경우, 랭킹 대상이 되는 핀들의 유사도 행렬이 서빙 시점에 계산되며, 이를 greedy하게 연산하는 과정은 O(wBN)의 시간 복잡도를 가진다. 이러한 레이턴시를 줄일 수 있는 방법을 제안한다.
- batch_size와 window size 조절하기
- 전체 N개 다 DPP로 reranking 하지 말고, 상위 B개(batch_size)만 reranking 한다. → 기본적으로 하위권은 사용자들이 덜 보니 덜 신경 써도 된다는 기조가 전반적으로 있는듯하다.
- 위에 DPP 식에서 언급한 sliding window w도 조절한다.
- depth size 조절하기
- N개를 DPP에 넣지 말고, 에 해당하는 N` 개의 subset을 DPP에 넣는 것. 이 경우 kernel matrix 크기 자체가 작아질 것이다.
- 위의 batch_size 조절은 early stopping에 가깝다면, 이것은 search space를 줄이는 것에 가깝다. 따라서 depth size 조절은 batch_size 조절보다 다양성 정도에 좀더 큰 영향을 미칠 수 있다.
- Batch parallelization
- 사용자가 스크롤을 하면 그 다음 B개의 batch를 다양화 적용하여 뱉어낸다.
- 일종의 mini batch diversification이라 볼 수 있겠다.
- 이 방법을 사용하면 초기 로딩 시간을 크게 줄일 수 있고, 스크롤이 내려감에 따라 실시간으로 다양화를 적용할 수 있다.
- batch_size와 window size 조절하기
6-3. Qualitative evaluations
- 테스트 사용자들의 주관적인 감상평 및 전문 평가자들의 평가를 받아보았다.
- 전세계의 사용자들에게도 평가받아보았다.
7. RESULTS IN PRODUCTION
- 검색 및 추천 시스템에서 이러한 적용이 성공적인지를 평가하기 위해선 몇 가지 고려할 사항이 있다.
- 다양성에 대한 적절한 평가 지표 및 비즈니스적으로 심각한 피해가 일어나지 않도록 모니터링할 가드레일 지표가 필요하다.
- 여러 지면에서 실험을 진행하기 때문에 이를 합쳐서 생각하기 쉬운데, 각 지면마다 고유의 특성이 있기 때문에 이를 나눠서 해당 특성을 고려하여 평가해야 한다.
- 각 지면의 다양성 지표 변화를 직접적으로 비교하긴 힘들다.
- 그럼에도 불구하고, 대부분의 경우 다양성 지표가 올랐으며 가드레일 지표에는 중립 혹은 긍정적(부정X) 영향이 있었다.
- 이 논문에서 제공하는 지표는 미국 혹은 글로벌 마켓에서 3주 이상의 ABT를 한 결과이다. 아래에서는 이러한 적용을 했을 때 다양성 지표 (Div@𝑘(𝑅))에 얼마나 영향이 있었는가를 보인다.
7-1. Search

- 미용, 패션 분야에 적용
- 검색에 RR을 적용했을 때
- 다양성 250% 상승
- 사용자 사용량 증가
- RR을 DPP로 교체
- 다양성 지표에는 큰 영향 없음.
- 사용자의 사용량 증가 및 사용자 수 증가
- 미국이 아닌 해외에도 적용했을 때 200~400%의 다양성 증가
- DAU, WAU, 전체 사용 시간 증가 확인
- Strong-OR 적용
- DPP는 그대로 둔 상태에서 적용
- 14%의 다양성 지표 상승 및 검색 사용량 증가
7-2. Related Products

- 패션, 웨딩 분야에 적용
- 기존(control) vs. RR(treatment)
- Div@𝑘 = 10(𝑅) 로 평가한 다양성 지표가 270% 증가
- 사용량은 기존 대비 변화 없음
- 상위 pin의 다양성이 높아짐에 따라, 사용자가 실제 눌러보는 핀의 다양성도 증가함을 확인
- RR(control) vs. DPP(treatment)
- Div@𝑘 = 10(𝑅) 로 평가한 다양성 지표는 소폭 감소
- DPP는 utility와의 tradeoff를 최적화하니까 이런 현상 발생 가능
- 사용자의 구매 1.3% 증가
- 클릭, 긴 클릭, 저장 등 긍정 반응 지표 5% 이상 증가
- 최종적으로 DPP 배포
- Div@𝑘 = 10(𝑅) 로 평가한 다양성 지표는 소폭 감소
- Bucketized-ANN Retrieval 적용
- pin 임베딩 공간에서 ANN을 수행하는 기존 retrieval 대비 8%의 다양성 지표 상승
- 최종 랭킹 결과가 아닌 retrieval 단계
- 최종 랭킹까지 했을 때는 1%의 다양성 지표 상승
- retrieval 단계 뿐만 아니라 랭킹 단계에서도 다양성을 위한 hyperparameter 조절이 필수적이다
- pin 임베딩 공간에서 ANN을 수행하는 기존 retrieval 대비 8%의 다양성 지표 상승
- 이 실험 외에 위에서 언급한 테스트 유저를 대상으로 한 질적(주관적) 실험에서 상위 핀에 대한 랭킹 성능 자체는 전혀 문제 없음을 확인했음
- 위의 figure-1이
DPP + Bucketized-ANN Retrieval을 적용한 결과임.
7-3. New User Homefeed
- 사용자가 처음 서비스에 들어왔을 때 모두가 존중받고 있다는 긍정적 경험을 주기 위해 초기 사용자의 홈피드에 다양성을 적용하기로 함
- 우선 순위 큐를 사용하는 두 차원의 RR 적용
- 핀 카테고리의 다양성을 RR로 적용함
- 피부색 연관 카테고리에 해당하는 pin은 피부색에 대한 우선순위 큐가 적용됨. 다음에 카테고리 다양성에 의해 해당 카테고리에 해당하는 핀이 들어갈 차례엔 여지껏 등장한 갯수에 반비례하는 우선순위 원칙에 따라 덜 나온 피부색의 핀이 rerank됨
- ABT
- 피부색에 연관된 패션, 미용 카테고리에 대해서만 적용
- 전체 핀 카테고리 다양성, 사용자 사용량(engagement), 성장 지표는 변함 없었으나, 피부색 다양성 지표가 109% 상승
- 단순 피부색 기반 RR 대신 two-dimensional RR을 전체 적용(4주간 적용)
- 아예 다양화 적용 안 했을 때 대비 650%의 다양성 지표 상승
- 사용자의 사용량 관련 지표는 변화 없음
- Overfetch-and-Rerank 적용(4주간 적용)
- 피부색 다양성 지표 63% 상승
- 레이턴시 변화 없음
- (마지막) DPP 적용(4주간 적용)
- retreival 다양성만 적용했을 때보다 462%의 다양성 지표 상승
- 신규 사용자 홈피드의 경우
Overfetch-and-Rerank + DPP가 베스트
8. ETHICAL CONSIDERATIONS
- 피부색 다양화는 서빙 시점에 리랭킹으로 사용되지만, ML 모델의 학습용 인풋으론 사용되지 않는다.
- 피부색은 핀의 특성일 뿐 사용자의 특성이 아니다.
- 각 사용자의 사생활을 존중한다.
- 한 마디로 각 사용자가 선호하는 피부색 같은 걸 학습하거나 기록해두거나 하진 않으니 걱정하지 마시라.
9. CONCLUSIONS AND FUTURE WORK
- 대규모 추천 시스템에서 multi-stage diversification을 적용해보았다. 여기서 논의된 방법들은 scalable하며 여러 차원의 다양성을 동시에 적용할 수 있다.
- 다양성을 적용할 요청을 모델을 이용하여 파악하는 작업을 추후 해볼 수 있을 것이다.
- 다양성 뿐만 아니라 다양한 목적에 대해서 동시에 최적화 된 랭킹도 해볼 수 있을 것이다.
- retrieval단계에서는 애초에 임베딩 자체에 fairness를 반영하여 임베딩 기반 retrieval 그 자체가 fair 해지는 걸 생각해 볼 수도 있다.
- 최근에 word embedding이 성별의 편견 등을 그대로 학습하기 때문에 이를 없애는 연구가 계속되고 있는데, 그걸 아예 랭킹에도 적용해보자는 아이디어.

메신저 회사에서 추천시스템을 개발하는 ML 엔지니어로 일했습니다. 현재는 금융권에서 다양한 분야의 모델링 및 서빙을 하는 ML Engineer로 일하며 흥미를 넓혀가고 있습니다. 추가적인 프로필은 메인에 첨부한 링크드인에서 확인해주세요.