본 포스팅은 아래의 출처를 참고하여 정리한 것입니다.
https://www.youtube.com/watch?v=PIidtIBCjEg&list=PLsMufJgu5933ZkBCHS7bQTx0bncjwi4PK&index=1
이진트리 (Binary Tree)
- 자식 노드가 많으면 트리의 삽입/삭제 등의 연산이 복잡해지기 때문에 자료구조로서 이진트리를 가장 많이 활용하고 있다.
- 이진트리의 표현법
-
배열, 리스트 ➡️ 힙(Heap)
- 다만, 메모리 상의 낭비가 있다.
-
노드와 링크로 직접 연결
- Node, BT(Binary Tree) class 선언하여 직접적으로 표현
- 각 노드에 필요한 요소: key 값, 왼쪽/오른쪽 child의 link (없을 시 None), 부모 노드 link
- 루트 노드빼고 모든 노드는 부모 노드를 가짐 (부모노드=None이면 루트 노드구나 알 수 있음)
-
노드와 링크 class 예시
class Node:
def __init_(self, key):
self.key = key
self.parent = self.left = self.right = None
def __str__(self):
return str(self.key)
a = Node(6) #루드 노드
b = Node(9)
c = Node(1)
d = Node(5)
a.left = b
a.right =
b.parent = c.parent = a
b.right = d
d.parent = b이진트리 순회(Traversal)
- 이진트리 노드의 key 값을 어떤 순서에 따라 빠짐없이 출력하는 방법
- M(자신의 위치), L(left subtree), R(right subtree)
- 즉 M, L, R을 어떤 순서로 방문할 것인지에 따라 아래의 3가지 방법이 나뉨
- 이때 항상 L > R의 순서
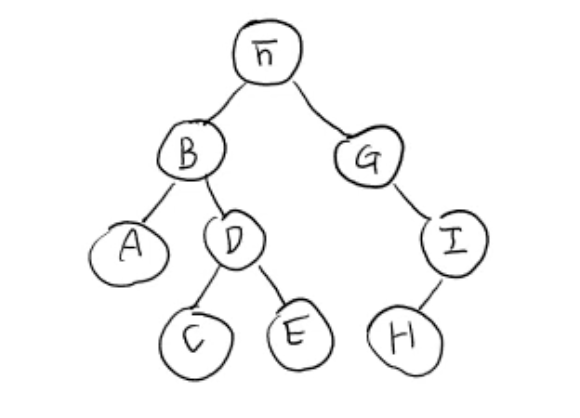
1. preorder
- M ➡️ L ➡️ R
- F B A D C E G I H
2. inorder
- L ➡️ M ➡️ R
- A B C D E F G H I
3. postorder
- L ➡️ R ➡️ M
- A C E D B H I G F
코드 구현
class Node:
def __init__(self, key):
self.key = key
self.parent = self.left = self.right = None
def preorder(self): # 현재 방문 중인 노드=self
if self != None:
print(self.key) # 자기 자신 방문 = key 값 출력
if self.left:
self.left.preorder() # 왼쪽 노드에 대해 다시 preorder 재귀 호출
if self.right:
self.right.preorder()
def inorder(self):
if self != None:
if self.left:
self.left.preorder()
print(self.key)
if self.right:
self.right.preorder()
def postorder(self):
if self != None:
if self.left:
self.left.preorder()
if self.right:
self.right.preorder()
print(self.key)-
만약 어떤 이진트리가 있는데 모양을 모르는 상태
-
이때 preorder로 방문했더니 F B A D C E G I H
-
inorder로 방문했더니 A B C D E F G H I
-
이 정보를 바탕으로 모양을 모르는 이진트리를 reconstruct(복원)할 수 있다
🌟 이진탐색트리 (Binary Search Tree, BST)
-
이진트리 중에서도 가장 일반적으로 쓰이는 트리
-
이진트리의 key 값을 저장한 후에 어떤 key 값이 있는지 search할 때 효율적으로 할 수 있도록 조직화되어 있음
-
이진탐색트리의 규칙/조건
-
각 노드의 왼쪽 subtree의 key 값은 노드의 key 값보다 작거나 같다
-
각 노드의 오른쪽 subtree의 key 값을 노드의 key 값보다 커야 한다
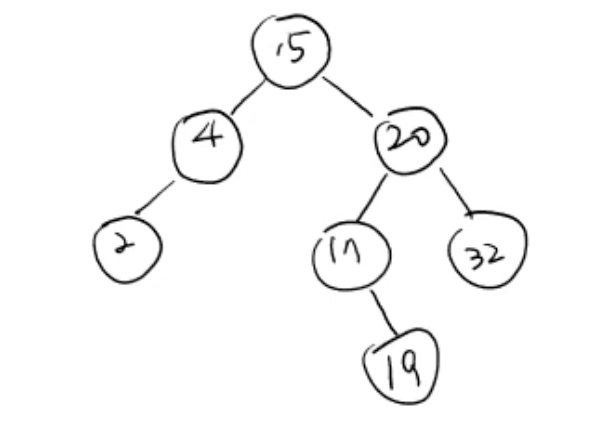
-
-
ex)
search(19): 루트 노드의 key와 비교하여 더 크면 오른쪽 subtree로 이동하여 왼쪽의 subtree는 안 봐도 되는 것- None에 도달하면 내가 찾고 싶은 key가 트리에 없는 것
-
search 시간이 트리의 높이 h, 시간 ➡️ 효율적인 서치 가능
-
높이를 최대한 작게 하도록 유지
BST Class
class BST:
def __init__(self): # 초기화
self.root = None
self.size = 0
def __len__(self):
return self.size
def __iter__(self): # 차례대로 방문
return self.root.__iter__() # class Node의 iter을 호출 -> 미리 정의되어야겠지, e.g. preorder, inorder 등등- 이제 insert, search 등의 연산이 BST Class에 추가될 것임
- ex)
T = BST()T.insert(15)T.search(4)
Search 함수
find_loc(): BST의 어떤 key 값의 위치를 찾는 함수
def find_loc(self, key): # key 값 노드가 있다면 return, 없다면 노드가 삽입될 부모노드 return
if self.size == 0: # 빈 트리 -> 부모노드도 없어
return None
p = None # 부모 노드
v = self.root # 루트노드부터 차례대로 방문할 노드
while v != None:
if v.key == key: return v
elif v.key < key:
p = v
v = v.right
else:
p = v
v = v.left
# while문 빠져나왔다는 것은 찾고자하는 key 값이 없어 -> 부모노드 return
return p
def search(self, key):
v = self.find_loc(key)
if v == None:
return None
else:
return vInsert 함수
insert(16)호출find_loc(16)을 호출하여 들어갈 위치를 찾음v=Node(16)으로 노드를 만들고- link를 업데이트한다 (부모, 자식 노드)
- BST의 size +1
def insert(self, key):
p = self.find_loc(key)
if p == None or p.key != key
v = Node(key)
if p == None: # BST 자체가 empty, 즉 내가 삽입하고자하는 key가 루트노드
self.root = v
else: # p != None, p.key != key (중복이 아니라는 것)
v.parent = p
if p.key >= key: # 들어갈 위치는 알았고, 부모노드의 왼쪽/오른쪽 위치를 구분하기 위한
p.left = v
else:
p.right = v
self.size += 1
return v # 새롭게 insert한 노드 return
else: # key가 중복된 것 -> 이미 트리 자체에 있음
print("key is already in tree")
return p # p = None-
find_loc이 이고, 나머지 코드는 if 문으로 상수 시간 ➡️insert함수도 시간 -
트리의 height가 작을 수록 insert가 빨라진다
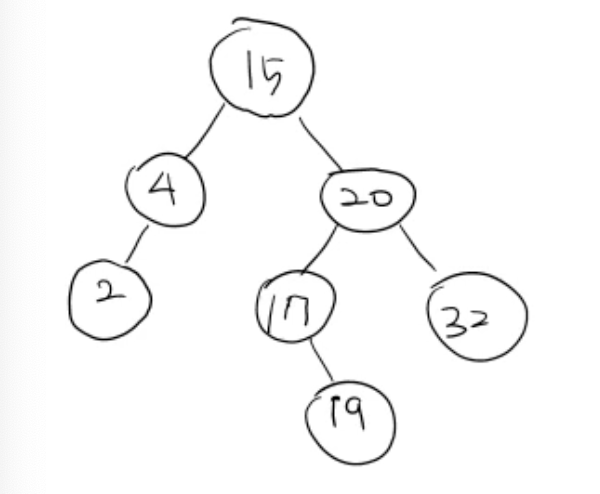
Delete 함수
- 삭제연산 (delete):
deleteByMerging,deleteByCopying
deleteByMerging
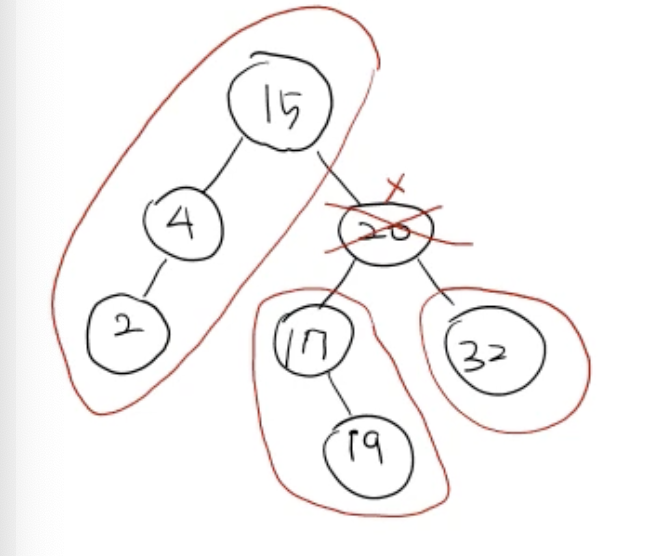
- 20이 없어져도 그 밑의 자식 노드들은 BST를 유지해야 함
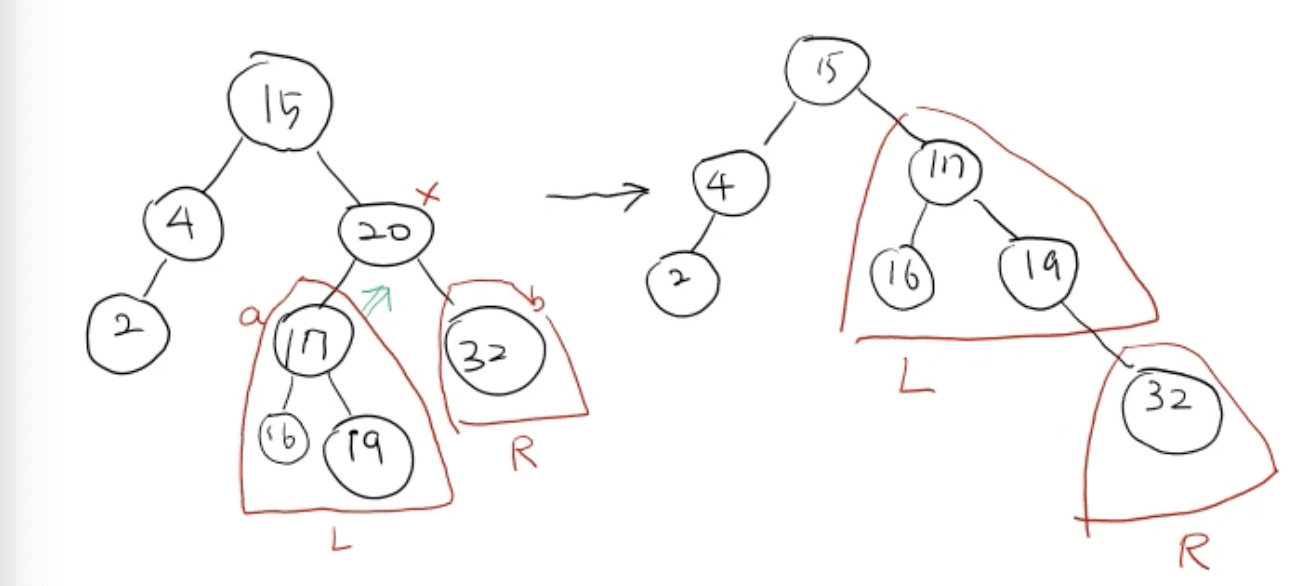
-
deleteByMerging은 20의 위치에 L(왼쪽 subtree)을 올리고 -
L의 key < R의 key
- 즉, L의 노드 중 가장 큰 key 값을 가진 노드의 오른쪽 child로 붙음
- 따라서 위 그림의 R은 19의 오른쪽 child로 붙음
-
즉, 지우고자 하는 x 노드의 자리에 x의 L이 오도록 하고, L에서의 가장 큰 key 값의 오른쪽 child로 x의 R을 연결
-
a의 부모노드 (L) = x의 부모노드 ➡️ 링크도 수정 필요
* 특별한 경우
- a == None
- a가 없으므로 x 자리에 b가 대체됨
- x == Root
- 루트 노드를 업데이트
deleteByMerging 코드
def deleteByMering(self, x): # 지우고자하는 노드 x
a = x.left, b = x.right
pt = x.parent
# 아래의 c, m은 경우에 따라 정의가 달라짐
# c = x 자리를 대체할 노드
# m = L에서 가장 큰 노드
# 1. a == None / a != None
if a != None:
c = a
m = a
while m.right: # a에서 오른쪽 child를 계속 내려가면서 살펴봄
m = m.right
if b != None:
b.parent = m
m.right = b
else: # a == None
c = b
# 2. x == Root
# x의 parent 링크 업데이트
if pt != None:
if c:
c.parent = pt
if pt.key > c.key: # pt의 자식이 left/right 인지 구분하여 연결
pt.left = c
else:
pt.right = c
else: # pt == None, 즉 x == root
self.root = c
if c: c.parent = None
self.size -= 1deleteByCopying
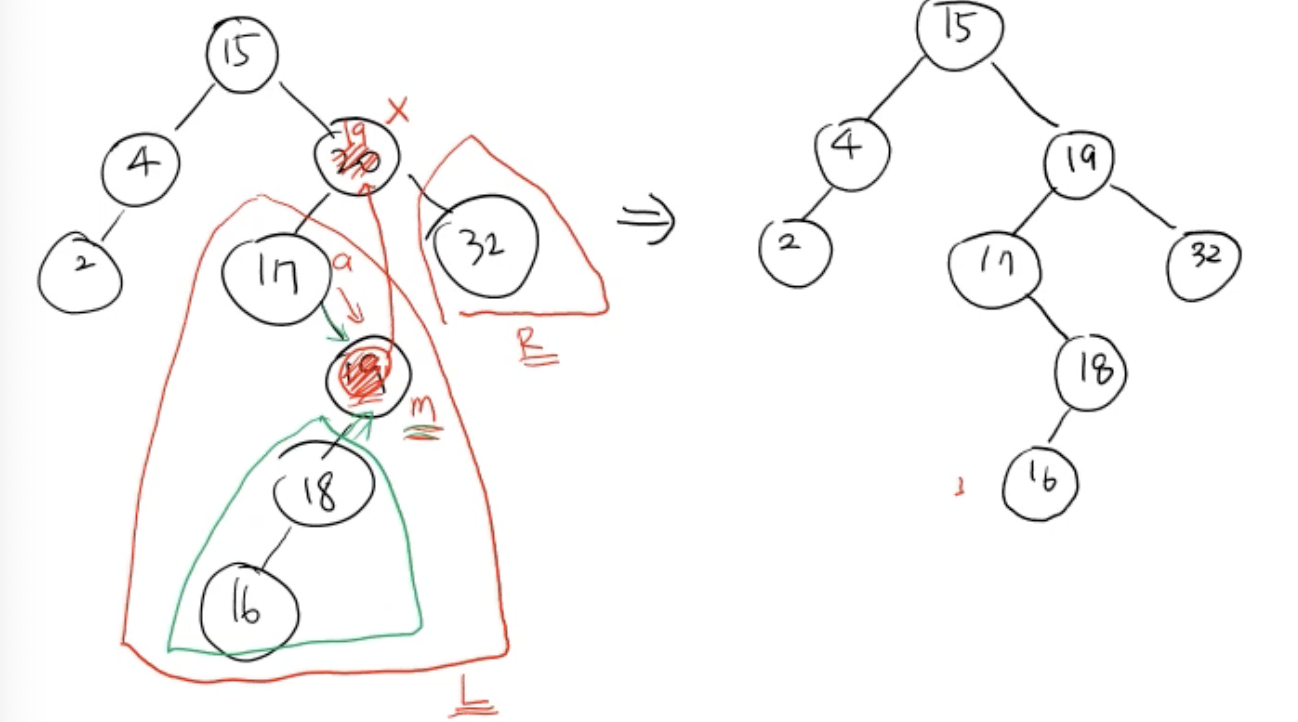
- L에서의 가장 큰 값 m을 x의 key로 copy한다 (노드를 삭제하는 것이 아님)
- L은 R보다 작아야하므로 (BST의 조건) x 자리에 올 값은 L에서의 가장 큰 값이어야 함
- 그리고 m의 왼쪽 subtree를 L의 루트(17)의 오른쪽 child로 붙임
deleteByMerging과 deleteByCopying의 수행 시간
-
deleteByMerging: m을 찾는 작업이 L의 마지막 오른쪽 child로 계속 내려감- 내려갈 수 있는 최대 높이는 최악의 경우 전체 트리의 높이(h)만큼 내려갈 수 있음
- 즉, m을 찾는 작업이 대부분의 시간을 차지함 (나머지 링크 업데이트는 상수 시간에 가능)
- 내려갈 수 있는 최대 높이는 최악의 경우 전체 트리의 높이(h)만큼 내려갈 수 있음
-
deleteByCopying: 마찬가지로 m을 찾는 작업이 대부분의 시간을 차지함 -
따라서 두 함수 모두 의 시간
연산별 수행 시간 정리
- insert:
- search(=find_loc):
- delete
- deleteByMerging:
- deleteByCopying:
