아래 사이트에서 일부를 정리한 글입니다.
https://www.jeremyjordan.me/autoencoders/
Autoencoder란
-
representation learning task를 위해 신경망을 활용하는 비지도학습 기법
-
구체적으로, 기존 input의 압축된 지식 표현(Compressed knowledge representation)을 강제하는 네트워크에서 bottleneck(병목 현상)을 발생시키는 신경망 아키텍처를 고안하는 것
-
만약 input features가 서로 독립적이라면, 이 압축(compression)과 이후의 재건축(subsequent reconstruction은 매우 어려운 task가 된다.
- 그러나 input features 사이의 상관관계가 존재한다면, 이 구조는 네트워크의 bottleneck를 통해 input을 강제할 때 학습되고 결과적으로 활용될 수 있다.
Bottleneck; 병목현상
- 얼마나 많은 데이터를 동시에 처리할 수 있느냐의 문제
- 즉, 한 번에 처리할 수 있는 데이터의 양보다 처리할 수 있는 능력이 충분하지 않을 경우 발생하는 문제
- 딥러닝에서 layer마다 자유도(Neuron의 수)가 Output으로 갈수록 점점 작아질 때, 한 번에 크게 작게 하여 큰 정보손실을 가져오게 만드는 현상
- ex) layer 수가 512 -> 10 (갑자기 줄임)
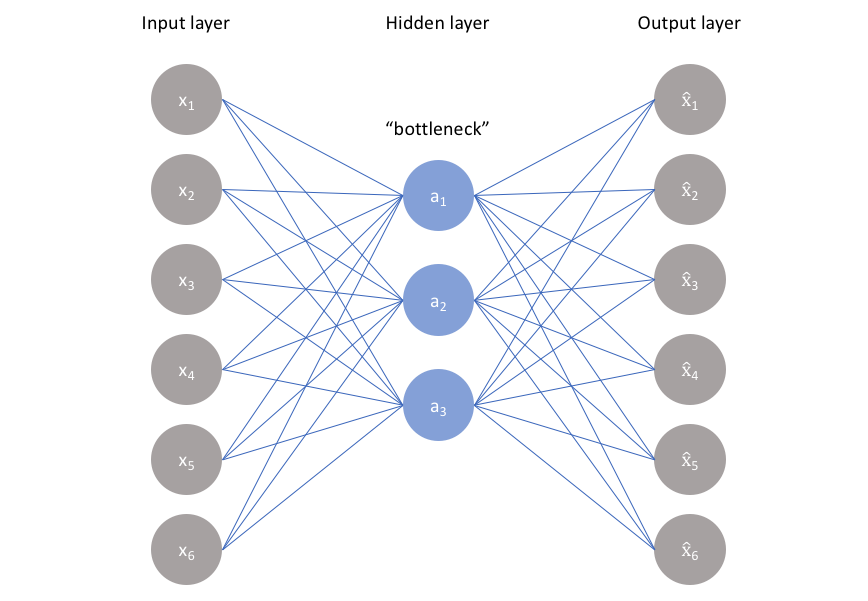
- 왼쪽 그림에서 볼 수 있듯이, unlabeled dataset을 가져와 기존 input 의 재건축(reconstruction)인 을 만드는 지도 학습 문제로 frame할 수 있다.
- 이 네트워크는 reconstruction error인 를 최소화함으로써 학습된다.
- 기존 input과 reconstruction된 결과의 차이를 측정
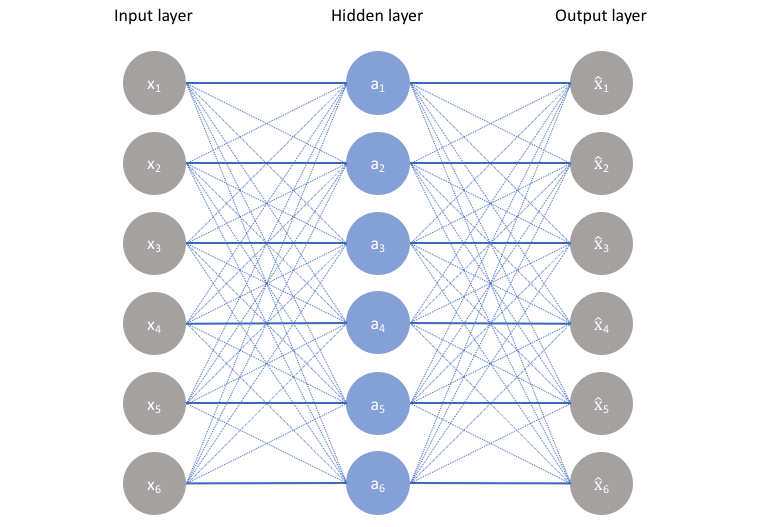
- bottleneck은 이 네트워크 설계에서 중요한 속성으로, 정보 bottleneck(information bottleneck)이 없다면 오른쪽 그림과 같이 네트워크를 따라 통과함으로써 input 값을 단순히 기억한다.
- bottleneck은 학습된 입력의 압축을 강제하면서 full network를 가로지를 수 있는 정보의 양을 제한한다.
이상적인 autoencoder 모델은 다음을 유지
- reconstruction을 정확하게 구축할 수 있을 만큼 입력에 민감하다.
- 모델이 단순히 학습 데이터를 기억하거나 학습 데이터를 과적합하지 않을 정도로 입력에 민감하지 않다.
- 이러한 trade-off는 모델이 입력 내 중복성을 유지하지 않고 입력을 재구성하는 데 필요한 데이터의 변형만을 유지할 수 있도록 한다.
- 이때 대부분의 경우, Loss 함수에 memorization와 overfitting을 억제하는
regularizer텀을 추가한다.
- 이때 대부분의 경우, Loss 함수에 memorization와 overfitting을 억제하는
불완전한 autoencoder

- autoencoder를 만드는 데 가장 단순한 구조는 네트워크를 통해 흐를 수 있는 정보의 양을 제한하기 위해 hidden layer의 노드 수를 제한하는 것이다.
- reconstruction error에 따라 네트워크에 패널티를 줌으로써, 모델은 input data에서 가장 중요한 속성과 "encoded" 상태로부터 기존 input을 재건축하는 가장 좋은 방법을 배울 수 있다.
- 이상적으로 이러한 encoding은 input data의 latent(잠재된) 속성을 배우고 설명할 수 있다.
PCA와의 차이
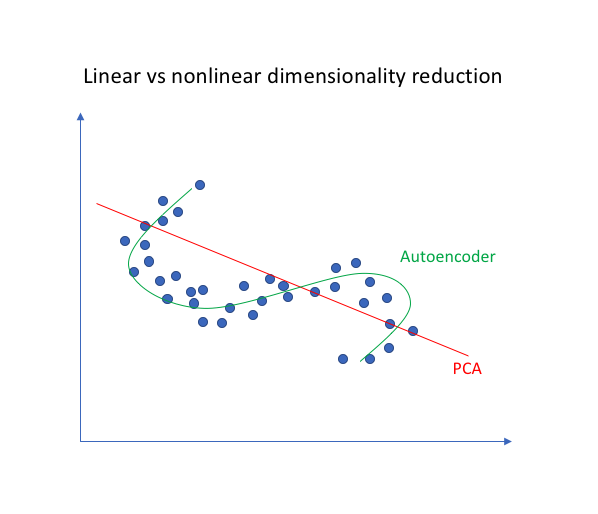
- 신경망은 nonlinear 학습이 가능하기 때문에 더 강력한 (nonlinear) PCA의 일반화라고 생각될 수 있다.
- PCA는 기존 데이터를 설명하는 더 낮은 차원을 발견하려고 시도하는 반면, autoencoder는 nonlinear manifolds의 학습이 가능하다.
manifold: 연속적이고 비굴절적(non-intersecting)인 표면
- 불완전한 autoencoder는 명시적인 정규화 term이 없고, 단지 reconstruction loss에 따라 모델을 훈련시킨다.
- 따라서, 모델이 input data를 기억하지 않도록 하는 유일한 방법은 hidden layer의 노드 수를 충분히 제한하는 것
- 데이터 내에서 모델이 잠재된 속성을 발견하기를 원한다면, autoencoder 모델이 단순히 훈련 데이터를 기억하는 효율적인 방법을 학습하지 않도로 하는 것이 중요하다.
- 지도학습 문제와 유사하게, 좋은 일반화 특성을 가지기 위해 네트워크에서 다양한 정규화 form을 사용할 수 있다.
