YOLO = You Only Look Once
객체 탐지(Object Detection) 알고리즘 중 하나
이미지에서 사람, 자동차, 강아지 등 여러 객체를 한 번에 탐지함
기존 방식들과 달리, 이미지를 한 번만 보고 객체 위치와 종류를 동시에 예측함
목차
- YOLO의 구조와 원리
- YOLOv1 구조 예시
- YOLOv2 – Anchor Box로 1 Cell에서 여러 객체 탐지
- YOLOv3 – 멀티 스케일 예측 + Feature Pyramid 구조
- YOLOv4 – 정확도와 속도 모두 강화한 실용적 모델
- YOLOv4 – 정확도와 속도 모두 강화한 실용적 모델
- YOLOv5 – 경량화 + PyTorch 기반 실용 버전
- YOLOv6 – 산업 환경 최적화 모델
- YOLOv7 – 정확도와 속도의 SOTA 모델
- YOLOv8 – 범용 비전 모델로 진화
- 그리드 → 멀티스케일 → 앵커 → 앵커프리 흐름
- 성능 비교표
- 용어 정리
YOLO의 구조와 원리
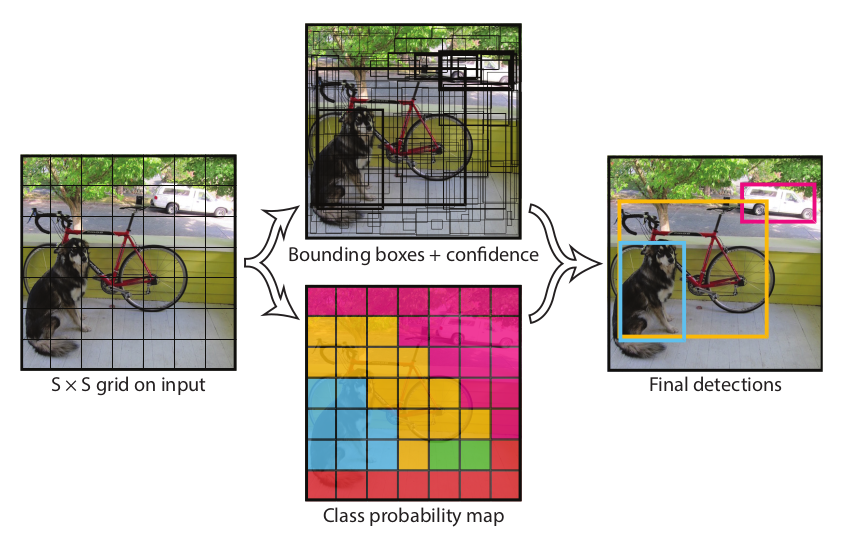
YOLO의 기본 구조는 "이미지를 그리드로 나누고, 각 그리드 셀이 바운딩 박스와 클래스 확률을 예측" 하는 방식
YOLO 기본 구조 요약
- 입력 이미지를 S x S 그리드로 나눔
- 각 셀(Cell)은 다음을 예측:
- 바운딩 박스 (x, y, w, h)
- 객체 존재 확률 (confidence)
- 클래스 확률 (softmax or logistic)
YOLOv1 구조 예시
- 7x7 그리드, 셀당 2개 바운딩 박스, 20개 클래스
YOLOv2 – Anchor Box로 1 Cell에서 여러 객체 탐지
YOLOv1에서는 한 셀이 하나의 객체만 탐지할 수 있었지만, YOLOv2부터는 Anchor Box를 도입해 하나의 셀에서 여러 객체를 탐지할 수 있게 되었습니다.
- 각 셀은 여러 개의 고정된 anchor box(예: 5개)에 대해 예측을 수행
- 다양한 크기와 비율의 객체에 더 잘 대응할 수 있게 됨
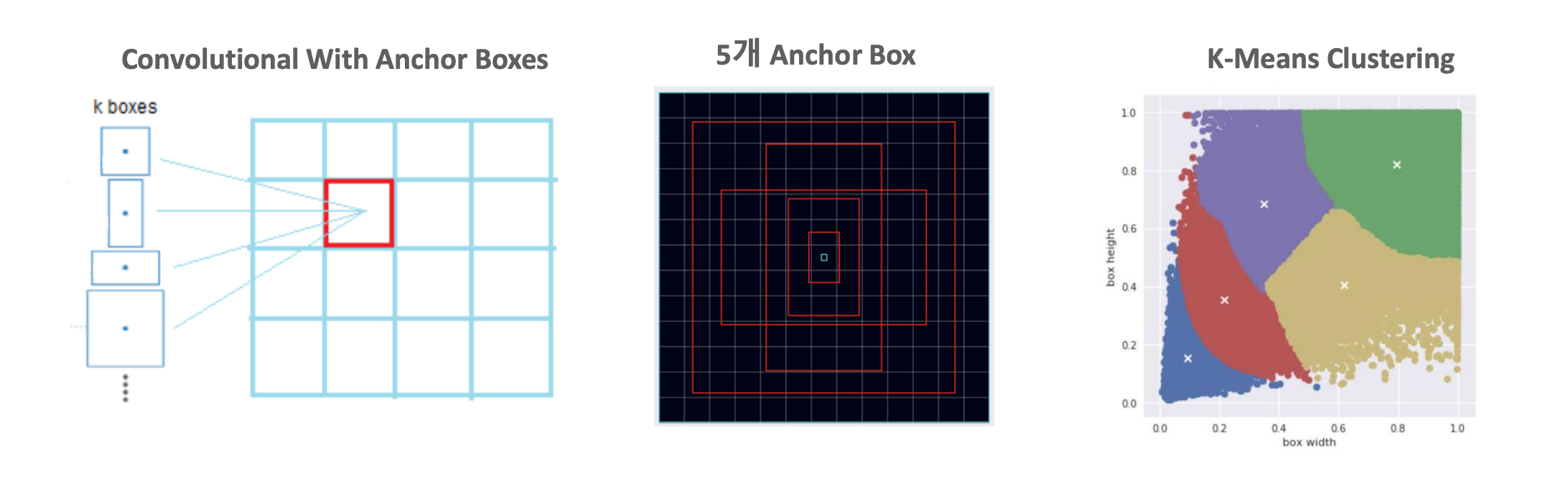
1. Convolutional With Anchor Boxes
- 각 셀은 K개의 Anchor Box(고정된 모양) 을 기반으로 예측 수행
- 그리드 셀 하나가 서로 다른 크기와 비율의 박스 K개 를 미리 준비하고,
- 각 Anchor에 대해 (x, y, w, h, confidence, class)를 예측
- 하나의 셀에서도 작은 객체, 큰 객체를 모두 예측가능
2. 5개의 Anchor Box
- 한 셀 기준으로 Anchor Box가 5개 설정된 예시
- 빨간 사각형이 각각의 Anchor Box이고, 중심 위치는 동일하지만 크기와 비율이 다름
- → 즉, 한 셀이 다양한 모양의 객체를 인식할 수 있게 설계한 것임
3. K-Means Clustering (Anchor Box 크기 학습)
- Anchor Box의 크기와 비율은 YOLOv2에서 K-Means Clustering을 통해 학습함
- 많은 객체 바운딩 박스 데이터를 가지고, 객체 크기와 비율에 따라 클러스터링하여 Anchor 형태를 설정
- 중앙의 흰 점이 Anchor Box 중심이고, 주변 데이터가 실제 박스 데이터야.
- → 이 과정을 통해 Anchor Box를 데이터에 최적화함!
YOLOv2에서 Anchor Box가 하는 일
| 항목 | 내용 |
|---|---|
| 목적 | 한 셀이 여러 객체 크기를 다룰 수 있도록 |
| 구조 | 셀마다 K개의 Anchor 설정 |
| 이점 | 다양한 크기/비율의 객체 탐지 가능 |
| Anchor 설정 방식 | K-Means 클러스터링으로 학습 기반 최적화 |
YOLOv3 – 멀티 스케일 예측 + Feature Pyramid 구조
YOLOv3에서는 다양한 크기의 객체를 더욱 정밀하게 탐지하기 위해
Feature Pyramid Network(FPN) 구조를 도입하고, 3가지 해상도에서 예측하는 방식을 사용
YOLOv2에서는 1개의 feature map (13×13)만 사용,
YOLOv3는 13×13, 26×26, 52×52의 3가지 해상도에서 각각 예측을 수행함
-> 작은 객체부터 큰 객체까지 모두 커버 가능하게 됨
1. Residual Block + Feature Pyramid Network
- Darknet-53 백본을 통해 Feature를 추출하고, 중간중간에 Residual Block(잔차 연결)을 삽입하여 학습 안정성을 높임
- FPN 구조를 통해 높은 해상도 ↔ 낮은 해상도의 정보를 융합 → 다양한 스케일에서 정보 손실 없이 탐지 가능
2. 3개의 예측 스케일
| 스케일 | Feature Map 크기 | Stride | 탐지 대상 객체 |
|---|---|---|---|
| Scale 1 | 13×13 | 32 | 큰 객체 |
| Scale 2 | 26×26 | 16 | 중간 객체 |
| Scale 3 | 52×52 | 8 | 작은 객체 |
- 입력 이미지에서 추출된 feature를 각기 다른 해상도에서 예측하여 다양한 객체 크기를 커버함
- 각 스케일에서 Anchor Box 기반으로 (x, y, w, h, conf, class) 예측
3. Anchor Box 설정
- 각 스케일에 Anchor Box를 3개씩 설정 → 총 9개의 anchor 사용
- YOLOv2처럼 K-Means 클러스터링으로 최적 Anchor 크기 설정
YOLOv4 – 정확도와 속도 모두 강화한 실용적 모델
- 백본: CSPDarknet-53 (CSPNet 기반으로 경량화 + 정확도 향상)
- Neck: SPP + PANet (Feature aggregation)
- Head: YOLOv3 방식 유지 (3-scale prediction)
- 주요 기술:
- Mosaic Augmentation, DropBlock, CIoU, Mish Activation, SAT 등
- 특징:
- 다양한 최신 기법을 조합하여 학습 정확도와 속도 모두 개선
YOLOv5 – 경량화 + PyTorch 기반 실용 버전
- 백본: CSPDarknet 계열 (버전별로 S/M/L/X 제공)
- Neck: PANet + FPN
- 기술 특징:
- PyTorch로 구현되어 확장성, 사용성 뛰어남
- ONNX/TensorRT 등 다양한 환경으로 Export 가능
- Hyperparameter Evolution, AutoAnchor 등의 기능 지원
- 특징:
- 논문은 없지만, 실무에서 가장 널리 사용됨
YOLOv6 – 산업 환경 최적화 모델
- 백본: EfficientRep Backbone
- Neck: Rep-PAN
- 특징:
- 고속 처리 및 실시간 응답성을 고려하여 TensorRT 최적화 설계
- 앵커 기반 탐지 방식 유지
- ONNX, INT8 등 경량 추론에도 강함
- 용도: 산업용 영상 처리, CCTV 시스템 등에 적합
YOLOv7 – 정확도와 속도의 SOTA 모델
- 백본: E-ELAN 구조로 학습 효율 강화
- Head: Task 통합형 YOLO Head
- 기술 특징:
- Trainable bag-of-freebies
- Extended ELAN 구조로 더 깊은 네트워크 학습 가능
- 특징:
- 실시간 탐지에서 정확도와 속도 모두 최고 수준
YOLOv7은 현재까지도 많은 벤치마크에서 속도·정확도 균형 최고 수준 유지 중
YOLOv8 – 범용 비전 모델로 진화
-
백본: 커스텀 아키텍처
-
구조 특징:
- 앵커프리(Anchor-free) 구조 → 유연하고 정확한 바운딩 박스 예측 가능
- Detect + Segment + Pose task 통합 가능
-
기술 특징:
- Export & deployment 쉬움 (PyTorch 기반)
- 객체 검출 외에 다중 Task 지원 (Segmentation, Pose Estimation)
-
특징:
- YOLO 모델의 확장형으로, 범용 비전 솔루션으로 진화 중
-
YOLOv1~v7까지는 Anchor 기반 방식 → 정해진 박스 후보에 대해 회귀 예측
-
YOLOv8은 Anchor-free 방식 → 픽셀 단위 예측 (CenterNet, FCOS 계열처럼)
-
그리드 셀마다 직접 중심점 + 크기를 예측 → 계산량 줄이고 더 유연
그리드 → 멀티스케일 → 앵커 → 앵커프리 흐름
- YOLOv1 – 단일 그리드 셀 기반 회귀
- YOLOv2 – 앵커 박스로 다양한 객체 크기 대응
- YOLOv3 – 3개의 해상도(feature map)에서 예측 (FPN)
- YOLOv4~v7 – 정확도 향상 기법 추가 + 고속화 구조
- YOLOv8 – 그리드 개념은 유지하되, 더 유연한 anchor-free 방식으로 발전
성능 비교표
| 버전 | mAP | FPS (Tesla V100 기준) | 모델 크기 |
|---|---|---|---|
| YOLOv3 | ~33.0 | 30 | 중 |
| YOLOv4 | ~43.5 | 62 | 중상 |
| YOLOv5s | ~36.7 | 140+ | 소형 |
| YOLOv6 | ~43.1 | 120+ | 중 |
| YOLOv7 | ~51.4 | 120+ | 중상 |
| YOLOv8n | ~37.3 | 160+ | 소형 |
용어 정리
- FPN: Feature Pyramid Network, 다양한 크기의 객체를 탐지하기 위해 서로 다른 해상도 특성 결합
- Anchor Box: 사전에 정의된 바운딩 박스 후보
- NMS: Non-Maximum Suppression, 중복 박스 제거
