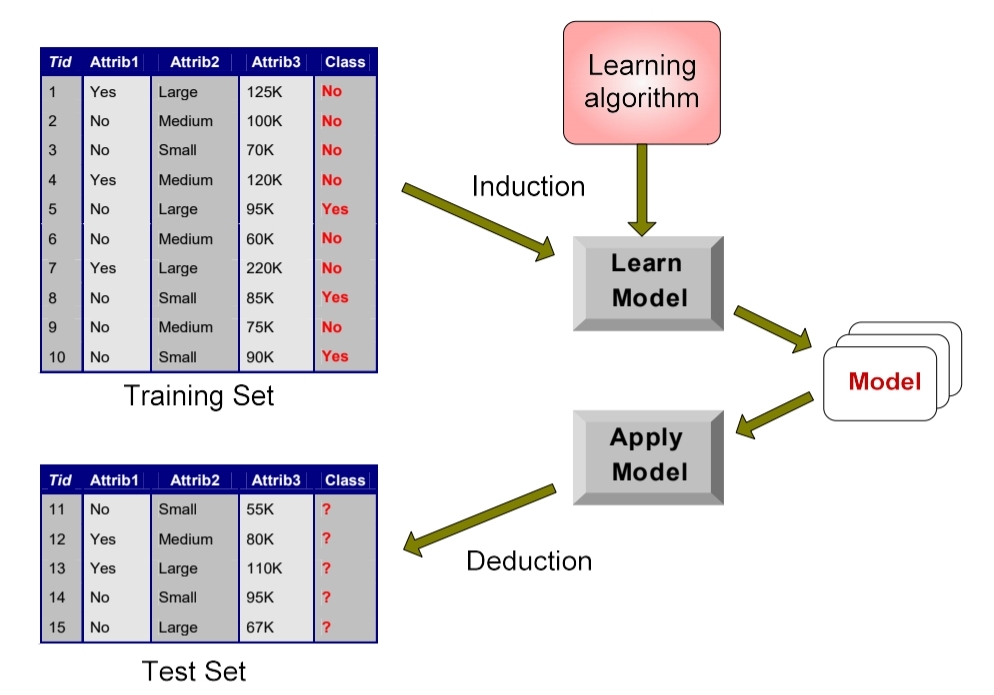
Supervised Learning
이미 x에 대해 f(x)라는 정답이 있는 경우
- 이산 f(x) : 분류
- 연속 f(x) : 회귀
- f(x)가 x의 확률일 때 : 확률 추정
분류 모델 (Classification)
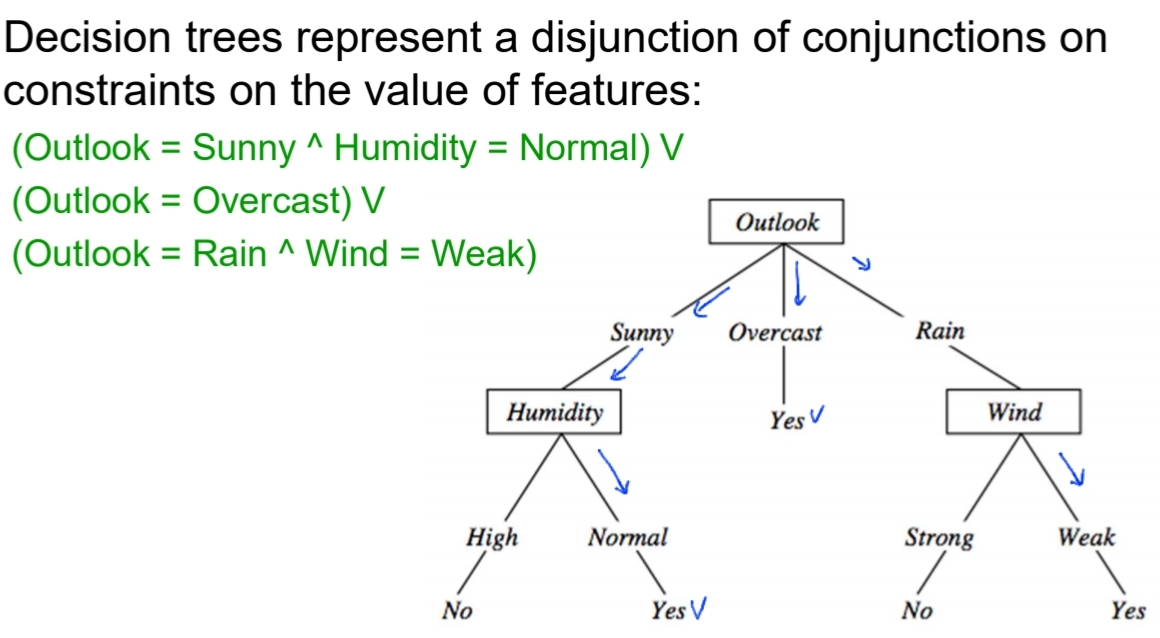
1. 그 중에서도 Decision Tree!
- 특징
- 이산 함수가 decision tree 형태(if - then - else rules)로 표현 됨
- noisy data에 강함
- Expressive hypostheses space, including disjunction
2. ID3 알고리즘
- 변별력이 좋은 질문을 위에서부터 하나하나 세팅 (top-down)
- Greedy Search 함
local optimum을 우선 찾으며 end 도달까지 backtrack하지 않음 - '변별력이 좋은 질문' 기준? 엔트로피!
드물게 발생할수록 사람들이 놀란다 - 정보량이 많은 것

엔트로피는 이러한 발생한 사건들의 정보량을 모두 구해서 평균 낸것

여기서 S는 이미 발생한 사건의 모음
c는 사건의 갯수 - 엔트로피가 크다 = 평균 정보량이 크다 = 대개 사건들이 일어난 확률이 비슷한 경우에 큼
ex) 동전을 던져서 앞면이 나오는 사건, 뒷면이 나오는 사건이 있을 때 {0.9, 0.1}로 앞면이 더 잘나올 확률이 크면, "앞면이 더 잘나와!"라고 예측하기 쉬우니까 정보량이 적은데, 둘이 똑같이 {0.5, 0.5}라면, 던졌을 때 앞면이 나올지 뒷면이 나올지 예측하기가 힘듦...
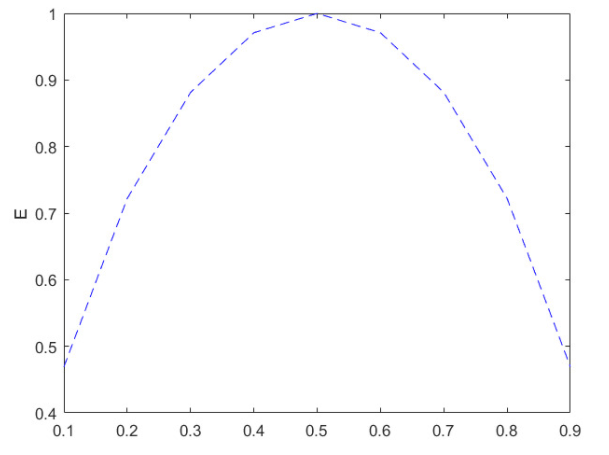
- 앞면, 뒷면 1/2로 똑같이 나올 때 엔트로피 : 1로 가장 큼
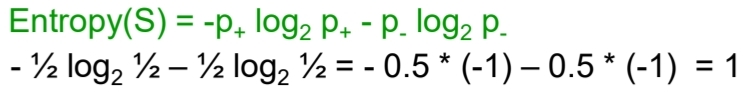
3. 정보이득 (Information Gain)
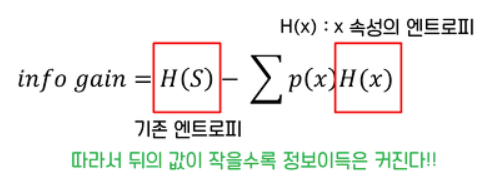
어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것.
예를 들어, 학생 데이터에서 수능 등급을 구분할 때 수학 점수가 체육 점수보다 변별력이 더 높았다
= 수학 점수 속성이 체육 점수 속성보다 정보 이득이 높다
# 정보이득 예시
- Outlook, Temperature, Humidity, Wind를 Tennis 치는 여부 (Yes : +, No : -)
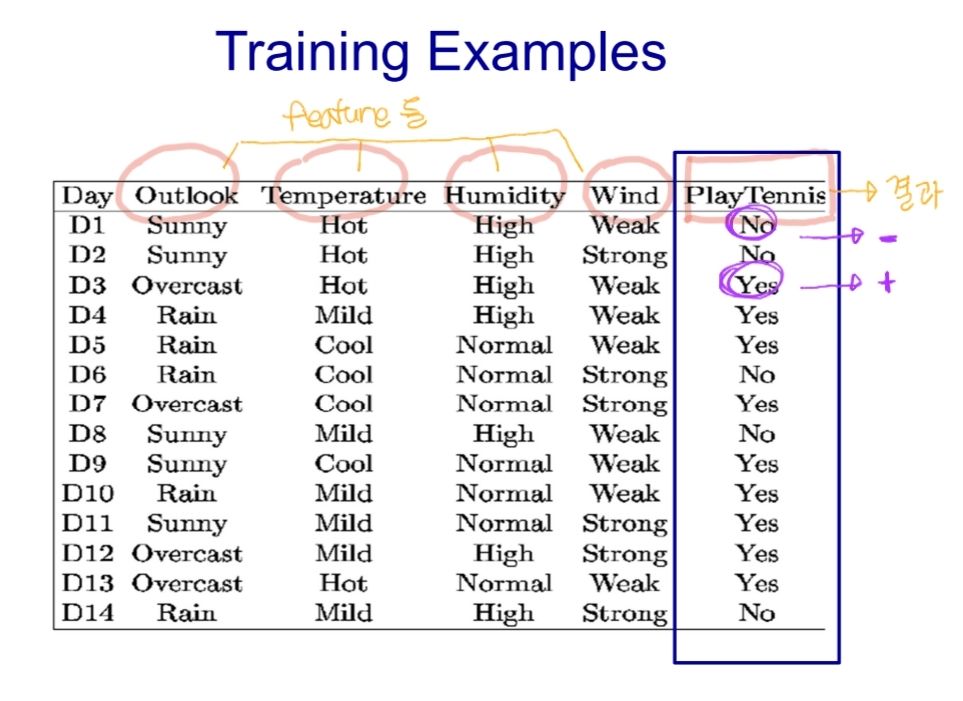


- Gain(S, Outlook) = 0.247
- Gain(S, Humidity) = 0.151
- Gain(S, Wind) = 0.048
: Outlook이 정보이득이 젤 큼!

: 또, Outlook 중에서도 Sunny일 때 Humidity가 정보이득이 젤 큼!
4. 지니 인덱스 (Gini Index)

- CART 알고리즘
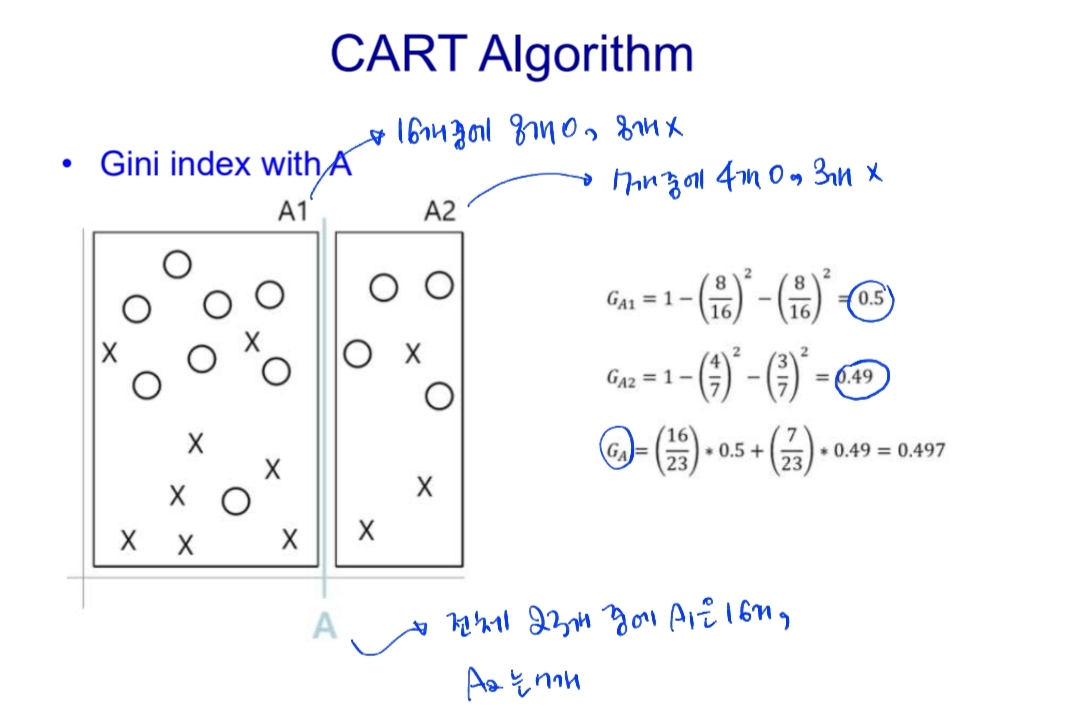
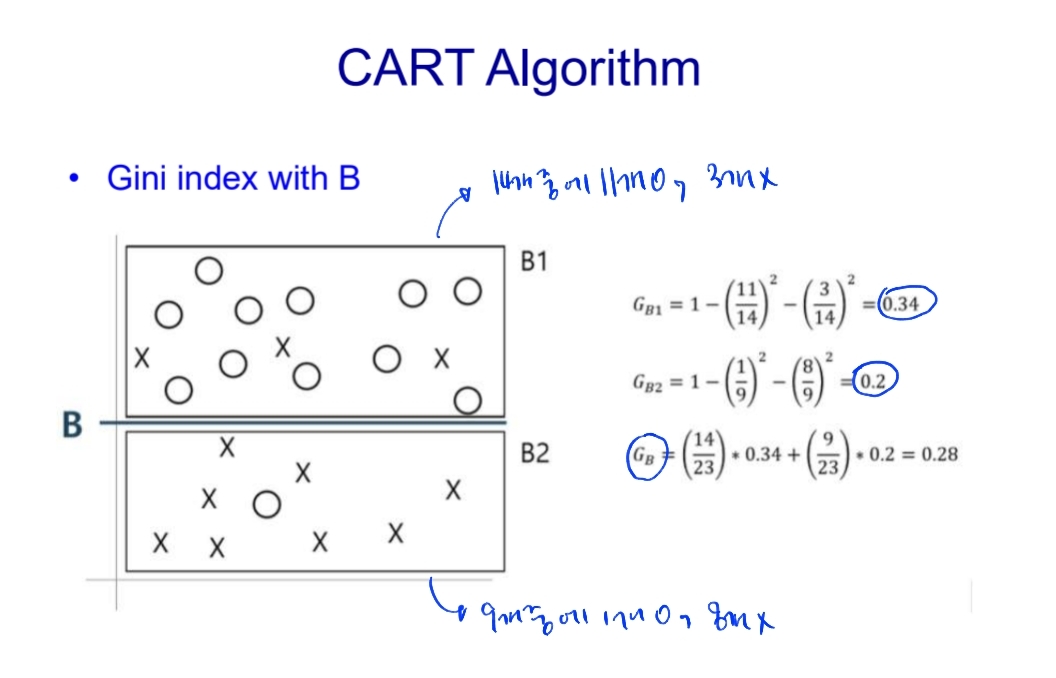
# 위의 예시(날씨에 따른 테니스 치는 여부)를 Gini index로 풀어가기



해보면,
- Gini(Outlook=Sunny and Temperature) = 0.2
- Gini(Outlook=Sunny and Humidity) = 0
- Gini(Outlook=Sunny and Wind) = 0.466
이라서, 트리는 Outlook -> Sunny -> Humidity -> No/Yes 가 됨!
Occam's Razor
2개가 있으면 굳이 어려운 길 말고 쉬운 길로 가자
5. Overfitting
훈련 데이터는 적중인데 새로운 것에는 적용 못하는 경우 (결정 트리에서는 분기(가지)가 너무 많은 경우)
- 어떻게 피해?
- 사전 가지치기 : 트리의 최대 깊이, 각 노드에 있어야 할 최소 관측값 수등을 미리 지정하여 트리를 만드는 도중에 통계적으로 중요하지 않은 정보들은 도중에 stop- 사후 가지치기 : 트리를 먼저 full로 만들고 terminal node를 결합
- 트리의 터미널 노드 수 + 오분류율을 더한 것을 최소화하는 방향으로
6. 장단점
- 장점 : 편하고 여러용도, 성능도 뛰어남
- 단점 : 계단 모양의 decision boundary라 훈련 세트에 민감함.(훈련 데이터의 작은 변화에도 매우 민감)
- 문제해결 : PCA 기법, 랜덤 포레스트(많은 트리에서 만든 예측을 평균하여 이런 불안정성을 극복)
7. 분류의 모델 평가하기
True Positive, False Positive, False Negative, True Negative로 Precision, Recall(Sensitivity), Accuracy, Specificity으로 F1을 평가
-
앞에꺼 : 예측이 맞았다 / 틀렸다
-
뒤에꺼 : 양성이다 / 음성이다
-
퀴즈 점수를 알려주고 정답을 알려주는 느낌
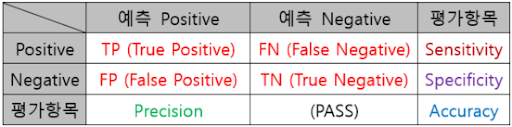
-
정확도 : 점수 100점 모음 / 전체
-
민감도(재현율) : 참 예측 맞는 거 / 참이라고 예측한 것들
-
특이도 : 거짓 예측 맞는 거 / 거짓이라 예측한 것들
-
정밀도 : 참 예측 맞는 거 / 참인 것들
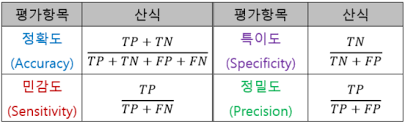
-
F1 = 2 x Precision x Recall / (Precision + Recall)

나영