1. Attention
Attention function은 Attention(Q, K, V) = Attention value 이렇게 구성되어져 있다. 이때 attention value는 values들의 weighted average라고 생각을 하면 된다. Step 0에서의 값들을 정리해보자면
- Query (context): Decoder hidden state
- Key, Value (reference): Encdoer hidden states
기본적은 구성 요소는 다음과 같고, 지금부터는 위 요소들을 이용해 attention score와 value들을 어떻게 구하는지 설명해보도록 하겠다.
- Attention scores: Decoder hidden states와 Encoder value간의 relevance
- Attention coefficients:
- Attention value: weighted average of encoder hidden states
- 각 encoder의 value가 사전이라 생각하면, 입력된 context에 가장 유사도가 높은 value값을 추출한다고 생각할 수 있다. 또한 context는 이전 decoder의 hidden states 값과 새로운 입력값에서 도출된다는 점에서, 시간이 globally 하게 고려되고 있다고 생각할 수 있다.
- Weight: similarity between query and key
1-1. MultiLSTM
기본적인 LSTM 모델에 attention method를 추가한 것이다.
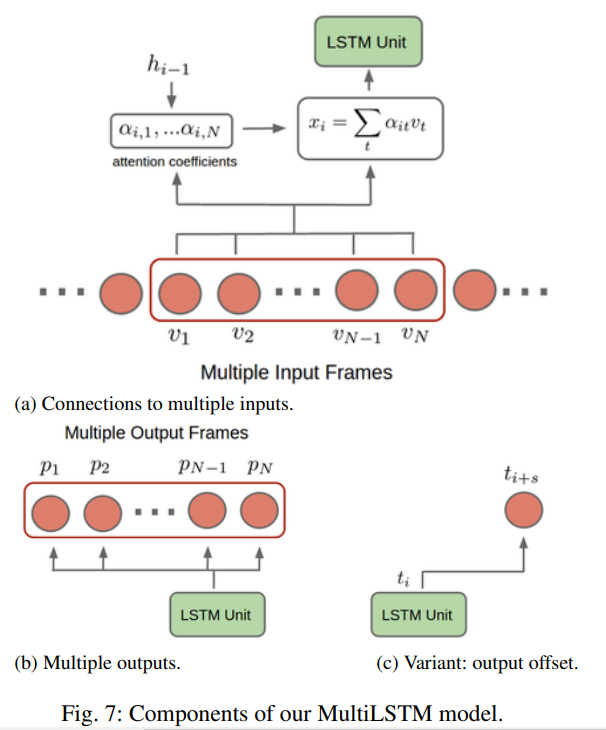
- Query (context): previous hidden state h_{t-1} of LSTM. 여기서 Query는 t-1 번째 hidden states와 t번째 text token이 반영된 값이라고 생각하면 편리하다.
- Key, Value (reference): Encoder의 값 대신, N recent input frame features를 본다.
- Attention value: weighted average of N recent frame features, 즉 현재 context에서 가장 의미가 있는 frame의 features 조합을 추출한다.
- Multiple output: N frames를 참고한 prediction 값.
1-2. Visual Attention
Action Recognition using Visual Attention
위에서는 시간적인 측면에서 Attention을 적용했다만, 공간적 측면에서 Attention을 적용하는 방법도 존재한다. Spatial attention은 이미지의 어느 파트에 집중해야 이미지 분류의 도움이 되는지를 반영하여 다음 hidden states값을 도출해낸다. 이때의 Query, Key, Value 값들의 의미를 살펴보자면,
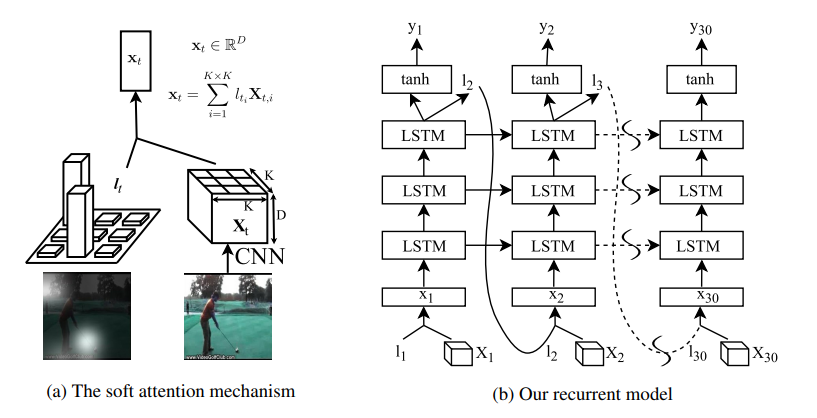
- Query (context): input image 의 번째 representation(hidden states)
- Key, Value (reference): t번째 input frames의 regional features
와 같고, attention value는 아래와 같다.
- Attention value: weighted sum of region featues. t번째 input frame 과 query간의 similarity를 구하고, 이 coefficients를 t번째 input frame에 element wise로 곱해주면서 attention이 적용된 t번째 representation이 등장한다.
- weights: (와 간의 공간적 relevance)
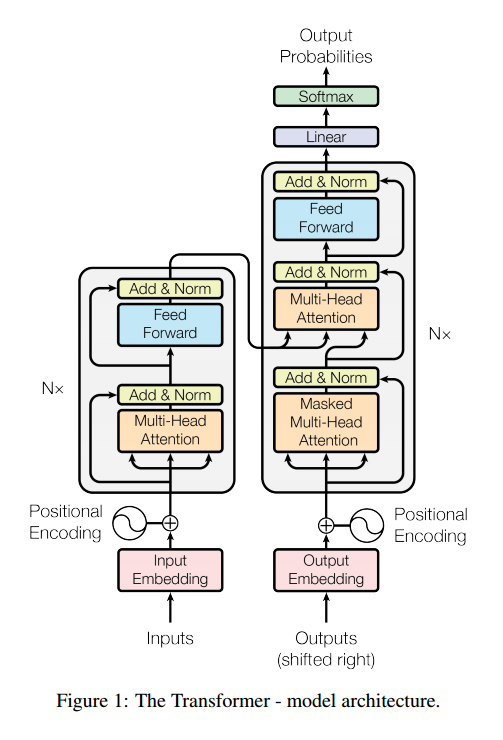
2. Transformer
Transformer의 핵심은 위에서 계속 설명했던 attention이 있다. Transformer를 다루기 전에 해당 개념을 다시 살펴보겠다. 참고로, 앞으로 대부분의 코드에서 transformer를 구현할 시 해당 layer code를 이용하게 될 것이다. nn.Multiheadattention code 설명
2-1. Self-Attention
일단 Attention 자체는 query(문맥)와 key 간의 유사도를 구하고, 이를 가중치로 이용하여 value의 weighted sum을 구하는 method이다. 이때, query, value, key가 무엇이냐에 따라 attention의 종류들이 달라진다. Self-Attention은 말그대로 나 자신과 관련된 attention, 즉, 나 자신의 어느 부분에 집중하여 값을 예측할 것인가와 관련된 말이다. 그래서 Self-Attention은 query값도 자기 자신, key - Value도 자기 자신에 해당된다. 이에 반해 차후 등장할 cross-attention 등은 key, value 값이 자기 자신에게서 비롯되지 않는데, 이는 밑에서 설명하도록 하겠다. 일단 self-attention의 간략한 로직이다.
-
Input tokens으로 이 주어졌다고 가정하자.
-
각 token 에 linear transformation을 적용하여 를 만든다. 이때 각각의 값들은 를 ) 로 linear transforamtion하는 것이다.
-
가 query라면, 자기 자신을 포함한 모든 토큰이 reference인 key, value값이 된다.
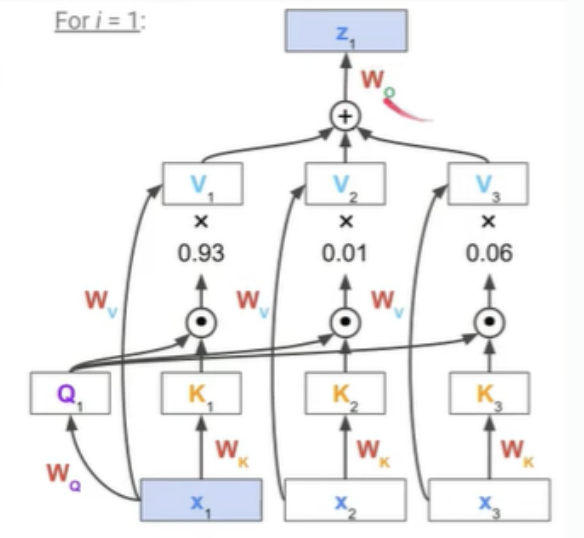
위 그림과 같이 query와 모든 key 값들 간의 similarity를 구하고, 이를 weight라고 가정한다. 이러한 weight에 각 value값을 곱하여 weighted sum을 구하고, 이것이 바로 이다. 즉, 를 다른 문맥들과의 연관성으로 표현된 vector 로 변환된다. (이때, 임베딩 자체도 각 단어들이 연관되어져 있게끔 임베딩이 되어져야 한다.)
다시 설명하자면 는 1) 자기 자신인 와 까지의 유사도를 구하고, 2) 각각을 과 곱하여 만들어진 weighted sum이다.
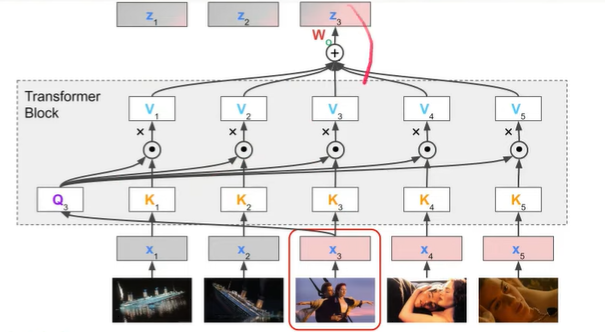
이러한 과정을 아래의 그림처럼 모든 input token에 대해 진행해주고, 하나의 transformer block을 지날 때마다 input token 개수와 동일한, 변형된 ouput vector 가 산출된다.
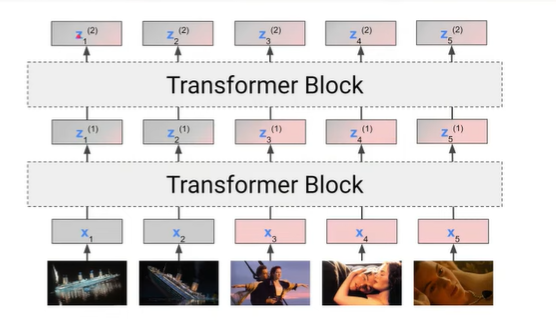
즉, 결론적으로 transformer는 자기 자신을 문맥을 고려한 어떠한 vector로 변환시켜주는 모델이라고 생각하면 된다.
하지만 우리에겐 여전히 남아있는 질문들이 있다. 이러한 value들로 우리가 무엇을 할 수 있나? 여러가지 접근법들이 있을텐데, 예를 들어 attention을 활용하여 분류 task를 해결하는 상황이라고 생각해보자.
1) value들로 mean으로 계산하여 분류를 진행하는 방법이 존재할 것이다. 다만, 이런 방법들은 token이 많지 않을 때만 효과적으로 적용가능하다.
2) input token에 dummy token인 classification token을 추가한다.
[cls] token은 기존 input token과 어떠한 연관성도 없기 때문에 비교적 균등하게 를 대신하여 표현할 수 있다.
2-2. Details about Transformer
Transformer는 하단의 그림과 같이 인코더와 디코드 구조로 이루어져 있다. 각각에 대해 설명해보도록 하겠다.
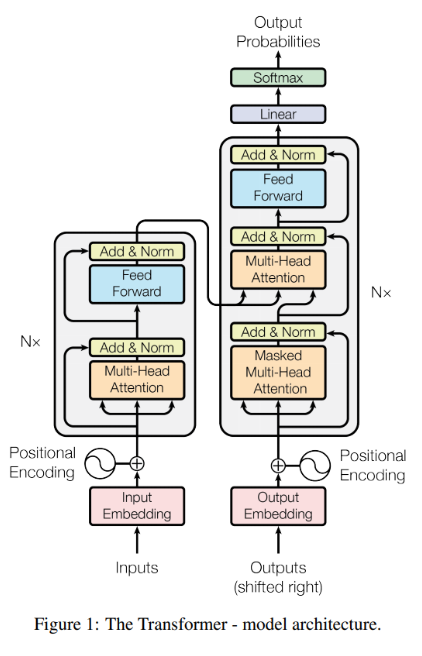
1) Encoder
-
Step 1. Input Embedding
Input은 token들의 sequence이다. 이때 각각의 token들은 같은 사이즈들로 표현되는데, text는 pretrained된 word embedding으로 표현되던가, 이미지는 고정된 사이즈의 작은 이미지 patches로 표현되던가, 비디오는 frame embedding으로 표현된다. 단어들을 토큰으로 임베딩하는데에는 word2vec등 다양한 방법들이 존재한다. -
Step 2. Positional Encoding
기존 RNN은 토큰들의 순서를 반영하지 못한다는 단점이 있다. transformer는 이를 보안하기 위해 sinusoidal encoding을 사용하게 된다. 식은 아래와 같다.
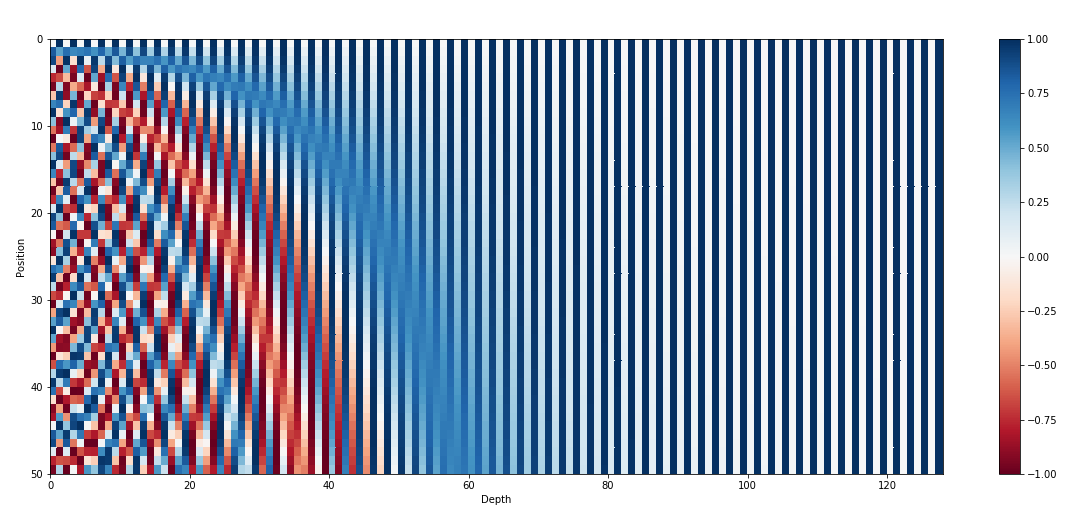
사진을 참고하자면, positional encoding은 단어와 단어 사이간의 거리가 멀어짐에 따라 값들의 차이가 커져 내적값은 작아지고, 거리가 가까울수록 내적값은 커지게 된다. 또한, 각 위치를 고유한 벡터로 표현가능해진다는 장점이 있다. positional encoding이 등장하게 된 배경까지 알면 이해하기 쉬운데, 이는 링크로 첨부하겠다.
https://pongdangstory.tistory.com/482
- Step 3. Contextualizing input embedding
위의 과정은 attention을 구했던 과정과 굉장히 유사하다. 하단의 그림을 참고하자. 우선 query, key, value 값들을 구하고,
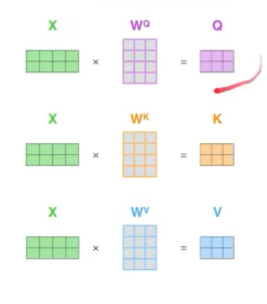
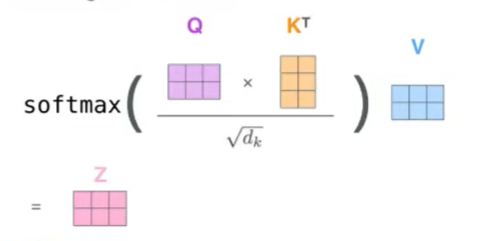
query와 key값을 product한 값을 softmax layer에 지나게 한 후, 이를 value와 곱한다. 그러면 input과 동일한 size의 z가 산출되게 된다.
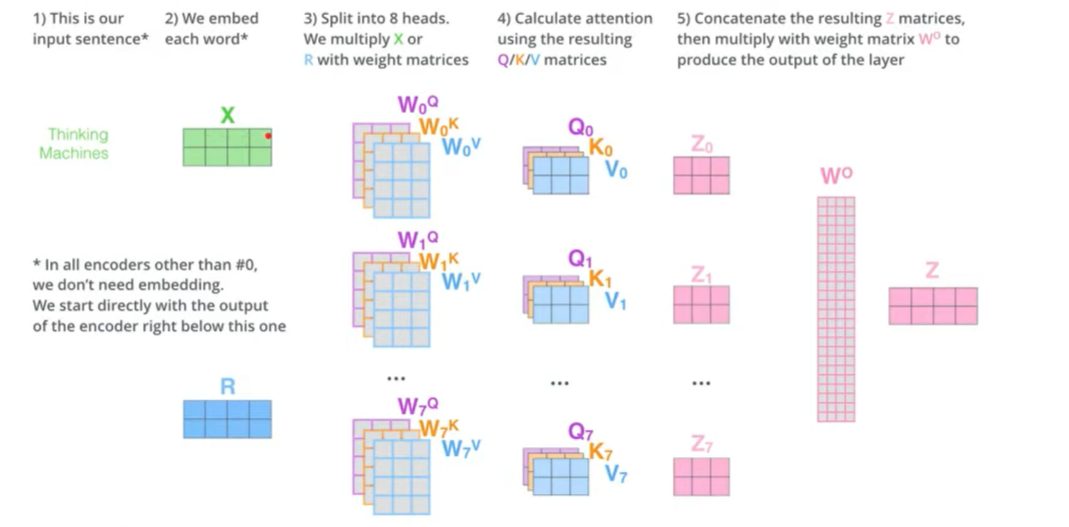
- Multi-head attention
Multi-head attention을 쓰는 이유는, 매 z값을 산출할 때마다 어느 부분에 attention을 주느냐, 즉 (Q, K, V)에 따라 결과값이 달라진다. 이러한 다양성을 고려하기 위해 여러 head를 쓰는 것이다.

- Encoder attention 총 정리
- Step 4. Feed-Foward layer
해당 layer도 지나가게 된다. output은 여전히 동일한 사이즈의 contextualized token embedding이 나올 것이다. 추가적으로, residual connection을 추가하여 해당 layer가 필요해질때만 학습되도록 하였고(이를 통해 층수를 다양하게 쌓을 수 있다), normalization layer 또한 추가하였다.
2) Decoder
Decoder part에서는 decoder의 input이 self-attention을 지나고, 이후 cross-attention을 지나는 과정을 이루어져있다.
-
Step 1. Masked multi-head attention
맨 처음 input이 들어갈 때, encoder와는 다르게 자기 자신 순번까지의 token들만 활용하여 contextualize한다. -
Step 2. Cross attention
cross attention은 query는 자기 자신, 나머지 key와 value는 encoder에서 온다.
cross attention 관련 추가적 자료: Cross Attention
- Step 3. FFN & linear & softmax
위의 layer들을 모두 지난 후 하고 싶은 task에 따라 특정 layer들을 추가한다.
3. Transformer in Vision
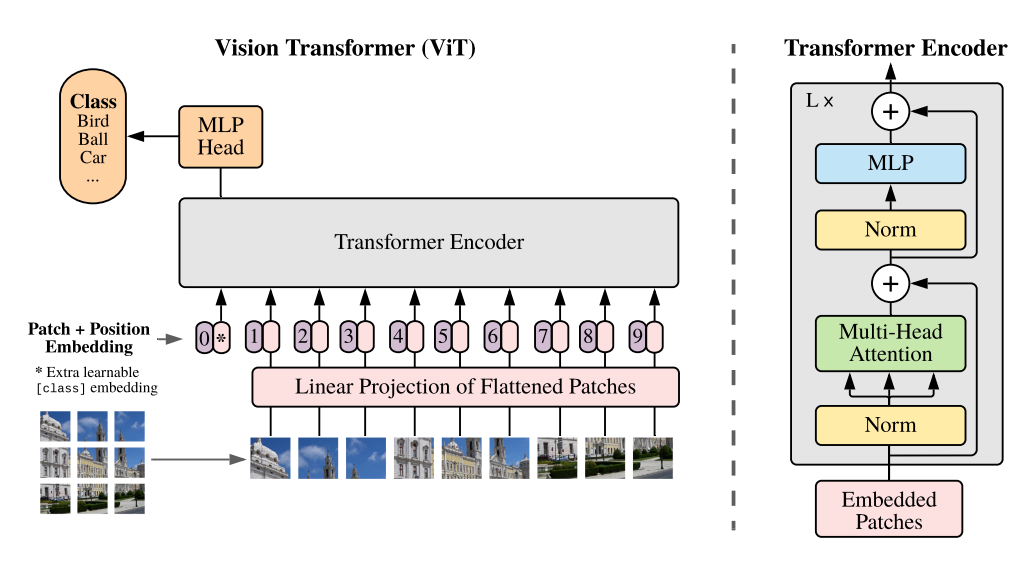
1) 이미지
image patches를 토큰처럼 입력한다. 대신, 이미지 패치들은 순서가 중요하지 않기 때문에 바로 입력해도 된다. 기존 transformer와의 차이점은, patches(token이라고 생각하자)를 linear projection을 통해 patch embedding을 진행하고, postional embedding을 fixed 상태로 두지 말고, 아무런 값도 입력하지 않은 빈 layer로 냅두어 학습가능한 상태로 만든다. 이후의 학습과정은 모두 동일하다! input의 형태가 조금씩 변하면서 ViT가 발전 중이라고 한다.
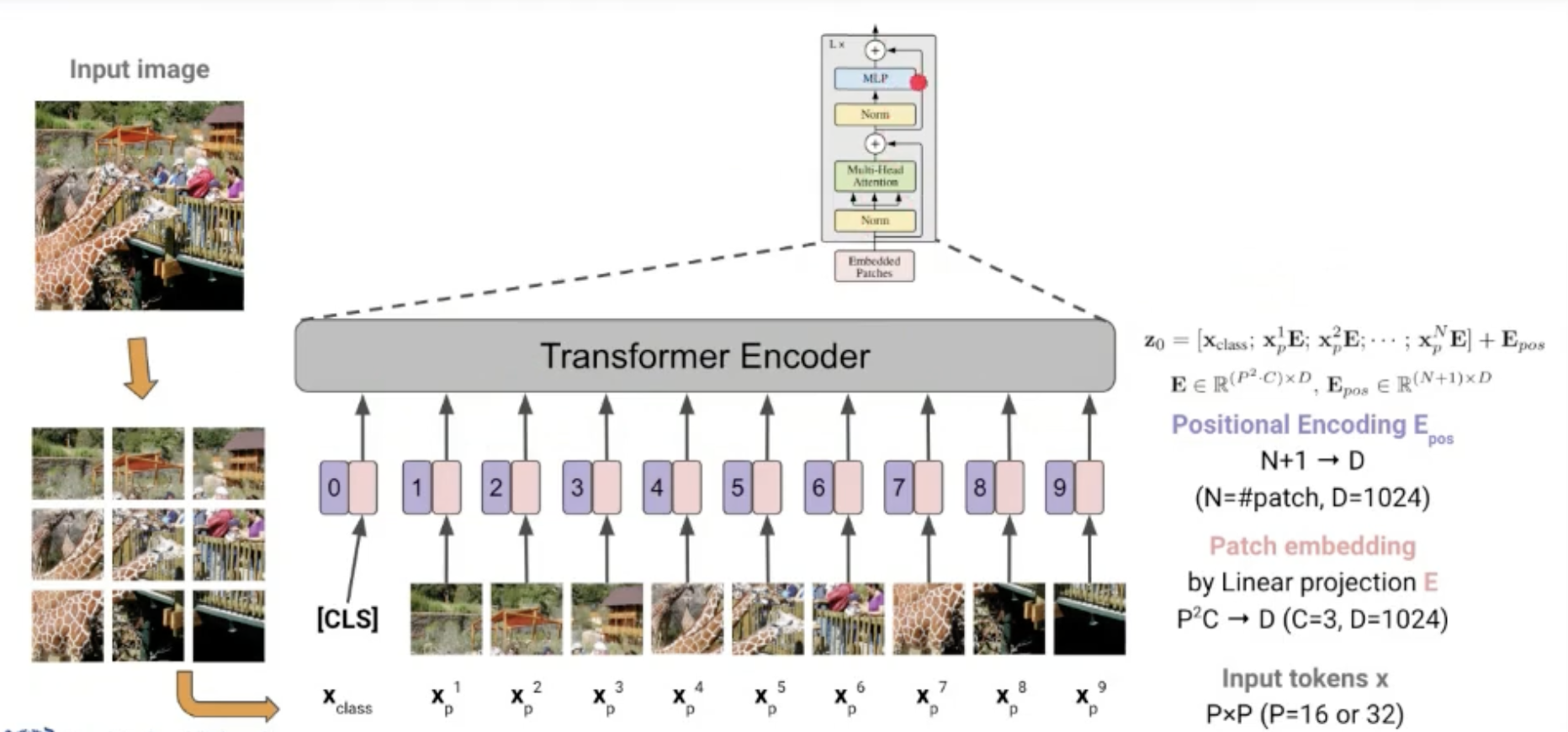
문제점은, ViT는 컴퓨팅 파워가 무지막지하게 좋아야지만 제 성능을 발휘할 수 있다는 점이다. 그 이유로는 비교군이었던 CNN은 spatial locality와 positional invariance를 담고 있는데, ViT는 나를 표현하기 위해 그저 다른 모든 패치들로 표현해보려는 것이기 때문에, locality가 존재하지 않기 때문이다. 다만 해당 논문의 저자는, 데이터 크기만 크면 전체를 보아도 어느 부분에 집중해야 하는지 배우게 된다고 주장하지만, 정말 많은 데이터를 학습해야한다는 단점이 있다. ViT는 데이터가 많다는 가정하에 locality와 globality를 모두 보장할 수 있다는 장점이 있다.
(DeiT) 이후 연구는 computing cost를 줄이는 과정으로 진행되었다. 추가적으로 비디오 분야에서도 transformer가 적용되는데, 이 경우는 frame을 sequence 별로 입력한다. ViViT등의 논문을 참고하자.
아래의 강의를 참고하여 작성하였습니다.
https://www.youtube.com/watch?v=NIFnKN2tWsE&list=PL0E_1UqNACXDTwuxUzCl5AeEjXBfWxCwc&index=14
