ViT가 등장한 이후, vision 분야에서의 transformer 연구가 활발히 이루어지고 있다. Data efficiency를 고려한 DeiT도 존재하고, 또 다른 후속 논문으로는 Swin Transformer가 존재한다. Swin transformer는 shifted windowing scheme을 통해 linear한 computational complexity과 성능을 동시에 보장했다는 점에서 의미가 있는데, 아래에 자세하게 소개해보도록 하겠다.
1. Introduction
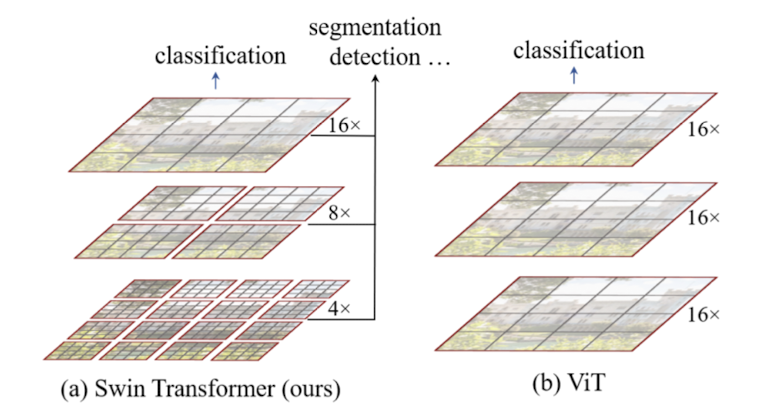
-> 기존 ViT는 이미지에. globally하게 self-attention을 적용하여ㅑ 이미지 사이즈에 따라 quadratic complexity를 지니고 있다. swin transformer는 이미지 패치들을 merging함으로써 hierarchical feature map을 만든다. 그리고self-attention을 이미지 전체에 적용하는 것이 아닌, 일부분에 적용함으로써 image size에 따른 linear complexity를 지니고 있다.
해당 논문은 transformer를 backbone 모델의 역할을 할 수 있게 새로 제안하였다. 우선 이미지와 텍스트 모달리티 사이에는 큰 차이점들이 존재하여 자연어에 사용되는 트랜스포머를 그대로 적용할 수 없다. 우선 이미지는 토큰의 scale 측면에서 다양성을 띄게 된다. 기존 비전 트랜스포머들은 이러한 점들을 고려하지 않고 고정된 사이즈의 토큰들을 사용한다. 또 다른 차이점은, 이미지가 더 큰 resolution(여기서는 데이터 정보의 크기?라고 생각해야 할 것같다.)을 지니고 있다. quadratic complexity를 띄고 있는 transformer에게는 치명적인 문제로 작용한다. 저자는 hierarchical feature map와 image size에 비례한 complexity를 보장하는 transformer를 선보임으로써 해당 문제들을 효과적으로 해결하였다. hierarchical feature map에서는 작은 사이즈의 patch들에서 layer가 깊어짐에 따라 patch size를 키워가는 구조를 세웠다. linear complexity는 locally non-overlapping window에 self-attention을 적용함으로써 해결하였다. patch의 개수 자체는 window마다 fix되어져 있기 때문에 linear complexity를 띄는 것이다.
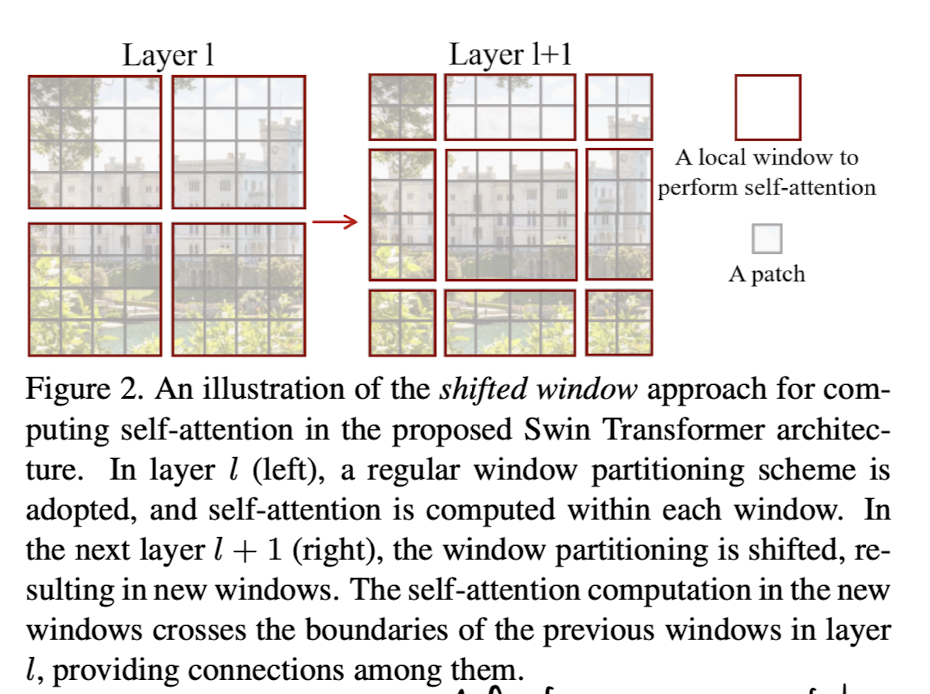
shifting approach vs sliding approach
또한, window를 sliding하는 대신 다음 layer의 window 크기를 shift함으로써 latency도 줄이고, 다른 patch들간의 연관성 또한 반영할 수 있다. shift window를 만드는 방법은 아래에서 자세하게 설명하겠다.
2. Related Work
Self-attention/Transformers to complement CNNS
CNN에 attention layer를 추가하는 방향으로 학습하는 연구도 진행되었다. self-attention은 distant dependencies와 heterogeneous interactions를 인코딩하면서 backbone과 head network를 보충해준다.(기존 cnn은 locality를 최우선으로 하는 모델이었기 때문에 이러한 self-attention의 도입은 globality를 고려해줄 수 있는 좋은 method이다.)
Transformer based vision backbones
transformer를 backbone으로 사용하는 모델은 ViT, 그리고 적은 데이터로 학습할 수 있는 DeiT 등이 존재한다.
ViT는 제 성능을 발휘하려면 수많은 데이터로 학습을 해야 제 성능을 발휘할 수 있다는 단점이 존재하고, 또한 고화질 이미지에 대해서는 patch size가 상대적으로 큰 편이라 feature map이 low-resolution 특징을 띌 수 있다는 단점이 존재한다. 이를 해결하기 위해 direct upsampling하거나, deconvolution하는 방향도 존재하지만, 이는 낮은 성능을 띈다는 문제점이 존재한다.
3. Method
3.1 Overall architecture
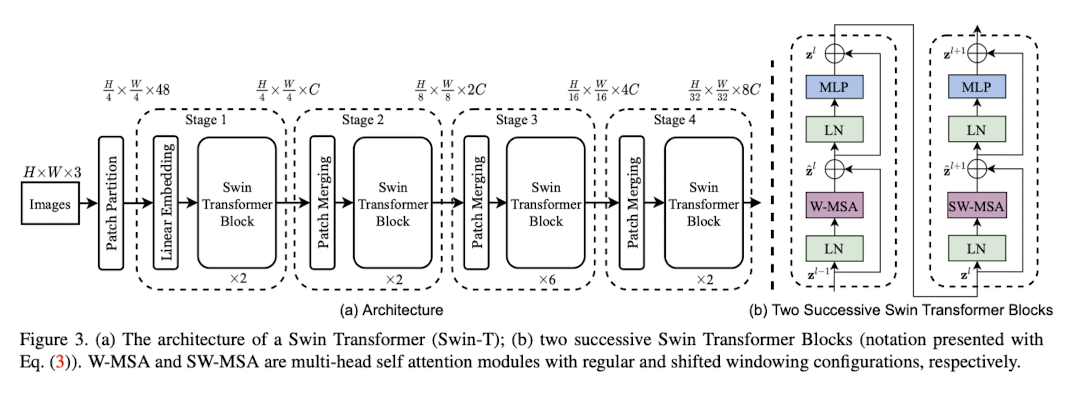
우선 이미지를 non-overlapping patch를 이용해서 나눈다. 각 patch들을 토큰이라고 생각하고, 토큰들의 feature를 픽셀값의 concatenation이라고 생각하였다. 해당 논문에서는 4 x 4 사이즈의 패치를 이용한다. (즉 각 patch의 차원을 4 x 4 x 3 = 48이라 생각한다.) 여기에 linear embedding을 거쳐 C dimension으로 만든다.
Stage 1 단계에서는 C dimension으로 표현된 각 patches를 입력으로 받는다. 이때, patch의 개수는 () 이다.
Stage 2 단계에서는 hierarchical representation을 만들기 위해서, layer가 깊어질수록 patch를 합침으로써 토큰의 개수를 줄인다. 첫 layer에서는 2 x 2 개의 이웃 패치를 합친다. 이렇게 만들어진 4C dimension을 downsampling을 통해 2C로 바꾼다. 그 이후에 swin transformer block이 적용된다. 이후 resolution은 로 바뀐다. Stage 3(), 4()도 동일 과정을 반복한다. 이러한 resolution은 기존 VGG나 ResNet 모델과 유사하다.
Swin Transformer block
Swin transformer는 기존 multi-head attention에 shifted windows module을 추가하였다. 2-layer MLP with GELU 이후 shifted window module이 첨가된 multi-head attention layer를 지나게 된다. MLP layer와 MSA layer를 지나기 전에는 LayerNorm layer를 지나게 되고, 모듈 하나를 지날때마다 residual connection을 지나게 된다.
3.2 Shifted Window based self-Attention
표준적인 transformer은 global self-attention을 적용하는데, 이러한 점이 토큰의 개수에 따라 복잡도가 quadratic하게 증가하게 된다는 문제점이 존재하고, 이는 dense prediction을 요하거나 이미지가 고해상도인 경우에 큰 문제점들을 야기한다.
1) self-attention in non-overlapped windows
효율적인 모델링을 위해 local window 안에서 self-attention을 계산한다. window는 non-overlapping한 방법으로, 짝수 개수로 나뉘어진다. 각 window는 M x M 개의 패치를 포함하고 있다. h x w 개의 패치들의 computational complexity는 아래와 같다.
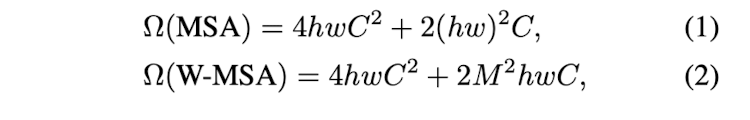
기존 복잡도
수정된 복잡도
기존 복잡도는 이미지의 높이와 너비에 quadratic한 형태를 띄었지만, 제안한 모델에서는 M이 fixed size인 7에 해당되기 때문에 이미지 사이즈에 대해 linear한 복잡도를 띈다고 말할 수 있는 것이다.
저 식이 정확히 어떠한 식으로 유추되는지는 자세하게 파악하진 못했지만, 한번 설명해보도록 하겠다.
우선 original transformer은 개의 patches들은 전체 patches인 에 대해 각각의 attention value를 구하는 연산 과정이 존재한다. 즉, 약 의 연산 과정을 거쳐야 하기 때문에 이미지 사이즈에 quadratic한 복잡도를 띄는 것이다. 그렇지만 해당 모델은 하나의 patch에 대해 attention value를 구할 때. 전체 이미지 patch를 참고하는 것이 아닌 neighboring한 patches들을 이용하여 계산하기 때문에 아래와 같은 복잡도를 띄게 된다.
2) Shifted window partitioning in successive blocks
window-based self-attention 모듈은 window간의 연관성을 반영시켜주지 못할 수 있기 때문에, 기존의 sliding window 대신 shifted window approach를 택하였다. 이 접근법은, swin transformer block 내 2개의 연속된 attention layer에 다른 window를 적용하는 기법이다.
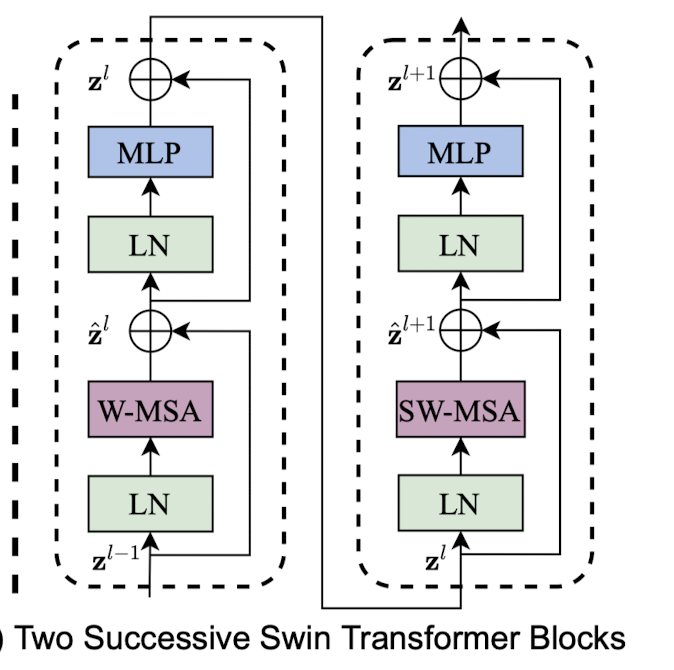
위 사진처럼, 첫 모듈은 일반적인 partitioning strategy를 사용한다. 8x8 featrue map을 4 x 4 크기의 2 x 2 개의 window로 분할한다. 다음 모듈에서는 () pixels만큼 윈도우를 displace(밀어낸다?)하고 계산을 진행한다. 이러한 shifted window approach에서는 block이 아래와 같이 계산된다.

여기서 과 은 각각 W-MSA와 MLP 모듈의 output이다. 그리고 W-MSA와 SW-MSA는 각각 일반적인 윈도우를 사용한 멀티헤드와 shifted window partitioning을 사용한 멀티헤드 어텐션이다.
3) Efficient batch computation for shifted configuration
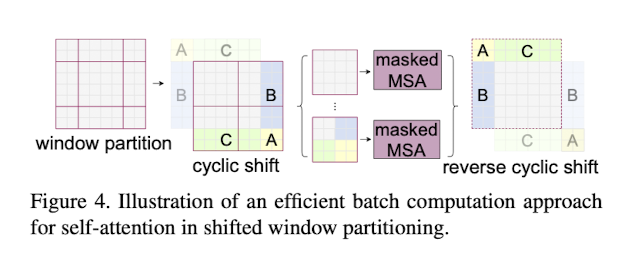
shifted window partitioning는 만일 () 에서 ()로 window를 shift할 때, 몇개의 window가 MxM보다 사이즈가 작아지는 경우 문제가 발생한다. 가장 기본적인 해결책은 padded 값을 첨가하는 것이다. 하지만 이 방법은 윈도우 개수도 동시에 증가시키게 만들기 때문에 computation cost가 증가된다. 저자는 이러한 점을 보안하기 위해 cyclic-shifting 방법을 사용하기로 했다. 이러한 shift 이후에는 batched window가 여러개의 sub-window로 구성된다. cyclic-shifting을 이용하면 윈도우 개수는 그대로 유지된다는 장점이 있다. 원리는 위의 그림과 같다. (정확힌 원리는 코드를 뜯어봐야지 알 수 있을 것 같다.)
4) Relative position bias
self-attention을 계산함에 있어, 각 헤드에 대해 relative position bias 가 존재한다.
이때 position의 range는 각 axis에 따라 [-M+1,M-1]이기 때문에, 더 작은 bias인 을 채택한다.
4. Experiments
실험은 classification부터 시작하여 object detection까지 다양한 분야에서 진행되었다.
-
classification
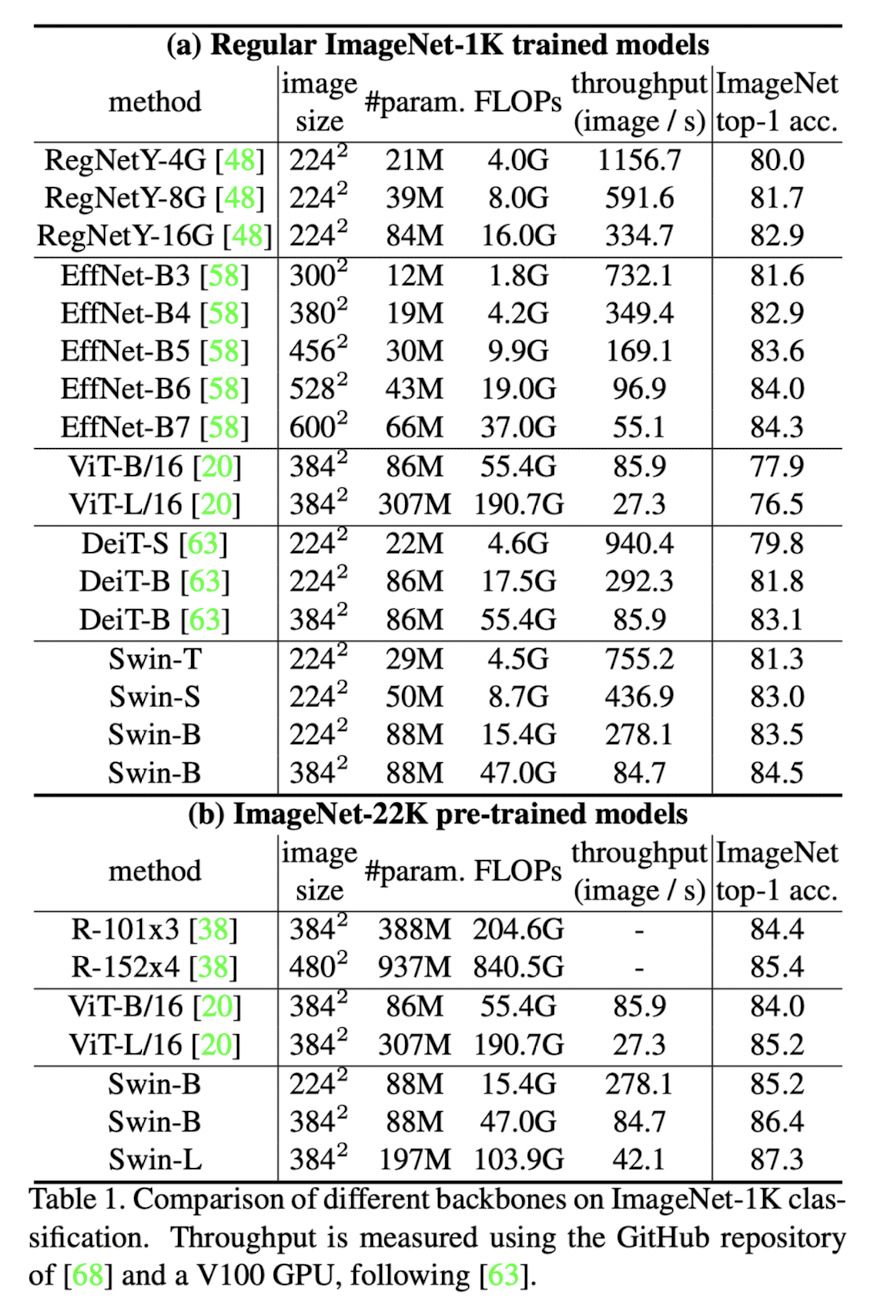
-
object detection
- Ablation Study
해당 논문에서는 key method인 shifted windows와 relative position bias의 유무에 따라 모델 성능을 테스팅하였다. 논문을 참고하길 바란다.
