현실 세계의 수많은 데이터는 annotation이 없는 경우가 많다. 그래서 데이터셋 자체의 특징과 패턴을 학습하여, 적은 양의 데이터로도 높은 성능의 모델을 만드려는 접근법이 많이 등장하고 있고, 이를 self-supervised learning, 자기지도학습이라고 한다. 자기지도학습 방법론 중 한 분야인 contrastive learning, 그중에서도 simCLR 논문을 살펴볼 것이다. 실제 데이터의 1%의 라벨 데이터만 사용함에도 불구하고, top-5 정확도를 얻었다고 한다. (이후에는 MoCo 리뷰 예정)
해당 논문을 읽어보면 매 매소드마다 다양성을 부여하면서 실험을 하고, 정당성을 부여하는데, 추후 연구를 진행할 때 무지성으로 그냥(?)이라는 것은 없다는 것을 깨달았다(...)
1. Introduction
지금껏 수많은 visual representation 연구가 진행되었었다. 대표적으로 generative approach, 그리고 discriminative approaches가 존재한다. 전자의 경우는 pixel-level에서 이미지를 생성해내면서 패턴을 배운다는 의미인데, 픽셀레벨이라는 것자체가 computaitonal cost가 상당히 많이 들어가고, 또한 generalized한 패턴을 배우는게 중요한 representation learning 분야에서는 그렇게 좋은 선택이 아닐수도 있다. Discriminative approach에서는 지도학습과 유사한 목적함수를 지니지만, 라벨링되지 않은 데이터로부터 라벨(pretest)과 input을 생성하여 학습하는 기법이다. 이러한 기법은 pretest task를 어떻게 설정하냐에 따라 성능이 달라지고, 이는 generality를 제한시킬 수 있다. 저자는 simCLR라는 representation 기법을 제안하는데, 이는 더 쉽고, 특별한 구조와 memory bank를 요구하지 않는다는 점에서 장점이 존재한다.
2. Method
2-1. The Contrastive learning framework
simCLR는 contrastive loss를 통해 x라는 데이터와 x를 augmented 이미지(similar pair)사이의 agreement를 최대함으로써 representation을 학습한다. 아래의 그림을 참고하며 설명해보겠다.
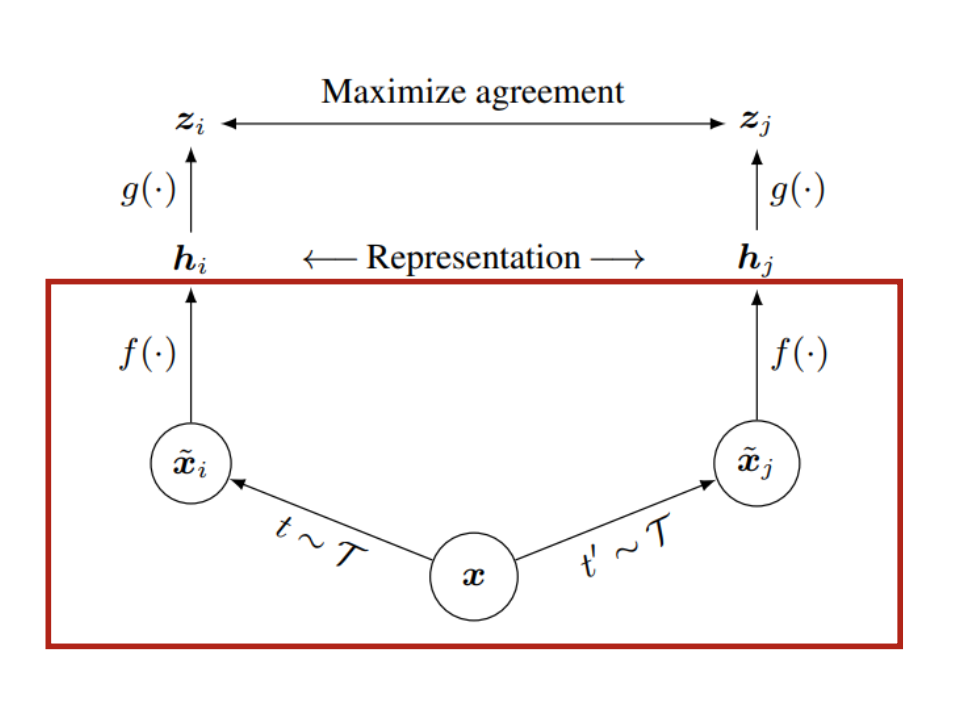
1) 우선 stochastic data augmentation을 통해 라는 데이터를 각각 , 으로 transform한다.
이 두 데이터를 positive pair, 즉 유사한 데이터 페어라고 생각하면 된다. 데이터 변형 시에 적용되는 transformation으로는 random cropping, color distortions, gaussian blur등 여러가지 방법들이 있다. 이때 augmentaion의 조합에 따라 성능이 다르게 나오는데, 실험 결과 crop + color distortion 조합이 가장 좋았다고 한다. 개인적으로 이렇게 성능이 나온 이유로는, 아무래도 crop하고 color값을 바꾸는 augmentation이 상대적인 픽셀 변화가 크므로 학습이 다양성이 커져서 더더욱 학습을 잘하는 것이 아닐까라고 생각을 하였다. (회전과 같은 경우는 피쳐의 위치만 달라진 것이기 때문에)
2) 𝑓(.)가 augmented된 데이터에서 representation vector를 뽑아낸다.
base encoder f(.)로써 다양한 architecture를 선택할 수 있다. 저자는 가장 많이 사용되는 ResNet을 기본 인코더로 채택하였다. 위 수식에서 h_i는 average pooling layer 이후의 결과에 해당된다.
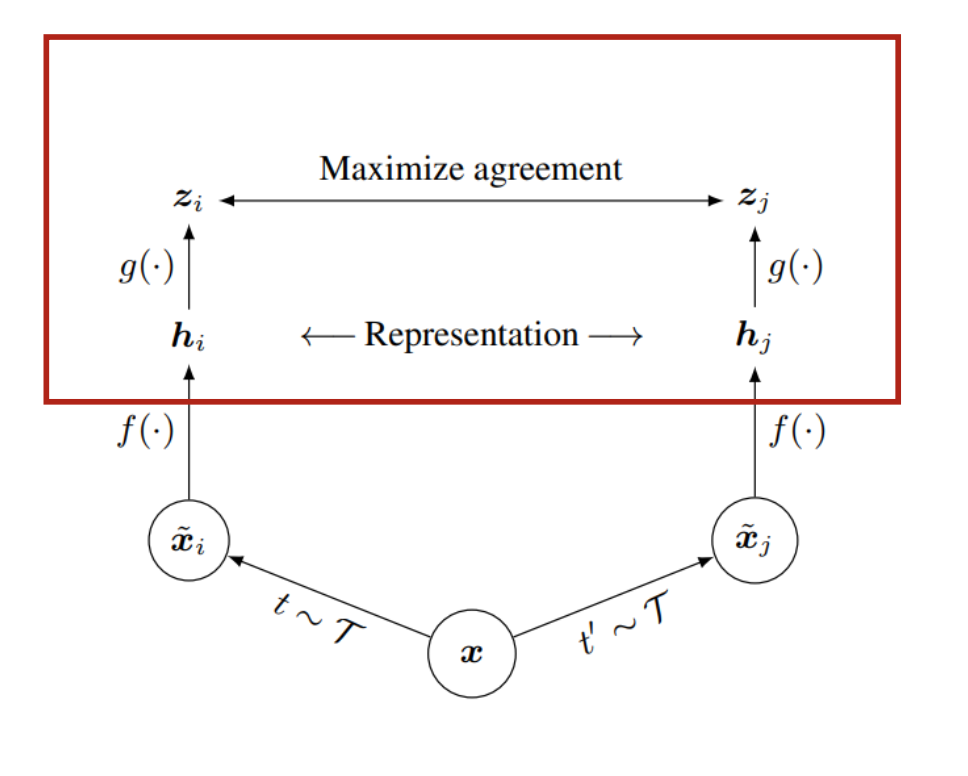
3) Projection head g(.)가 representation을 contrastive loss 값을 계산할 수 있는 공간으로 맵핑을 시킨다.
저자는 MLP를 사용하여 representation을 한번 더 매핑한다. 이때, contrastive loss값을 보다 이전 단계에서 구해진 representation인 에서 구하는 것이 효과적임을 찾았다고 한다.
4) contrastive loss를 계산하고 f를 업데이트를 한다. 추후 downstream task에서는 f(.)만을 사용한다.
contrastive loss는 가 주어졌다고 가정할 때, 로부터 positive pair인 를 인식하도록 계산이 되어진다.
위의 과정을 차례대로 설명하자면, 미니 배치안에 n개의 이미지들을 각각 augmentation을 진행하고, 이미지 에서 파생된 는 positive pair, 나머지 2(N-1)개의 미니배치 안 이미지를 negative pair라고 가정을 하고 위와 같은 학습 방법을 진행한다. 아래는 contrastive loss의 수식에 해당한다.

위의 수식에서 similarity 는 cosine similartiy로 계산되었다. softmax 수식과 유사한 형식을 띄는게 특징이다.

위의 그림은 SimCLR 의 간략한 pseudo 코드이다.
2-2. Training with Large Batch Size
Memory bank(MoCo 논문에서 등장한다.)는 모든 데이터의 representation을 memory bank에 담아 랜덤하게 샘플링하여 dictionary를 구성하는 방식이다. 다만, 예전에 업데이트된 encoder로부터 추출된 것이므로 일관성이 매우 떨어진다는 단점이 있다.
저자는 모델 구조를 심플하게 만들기 위해 메모리 뱅크를 사용하지 않았다. 대신, negative pair의 개수를 늘려 효율적으로 학습하기 위해, batch size를 256 - 8192까지 다양하고 훨씬 더 큰 범위로 만들었다. 다만 큰 범위의 배치사이즈로 학스비을 하는 것은 매우 불안정적이고 컴퓨팅적으로 비용이 많이 든다는 단점이 있어, 저자는 이를 개선하기 위해 linear learning rate를 지닌 표준 SGD, momentum optimizer보다 LARS optimizer를 사용하였다. (어떤 차이점이 있는지는 다른 논문을 통해 확인해봐야할 듯.) TPU를 사용했고, 코어를 배치 사이즈에 따라 32-128개 사이로 설정할 수 있도록 다양성을 주었다.
Global BN
표준적인 ResNet은 batch normalization을 사용한다. data parallelism을 활용하여 distributed training을 진행하면, 디바이스별 배치들의 평균과 분산을 사용하기 때문에 local information leakage에 빠질 수 있다. (이렇게 되면 representation 성능을 높이지 않은 채 예측 정확도만 올리려고 하게 될 수 있다.) 이를 해결하기 위해 전체 디바이스들의 BN mean과 분산을 사용하여 학습을 진행하였다.
3. Data Augmentation for Contrastive Representation learning

3-1. Composition of data augmentation operations is curical for learning good representations

Data augmentation에 따른 성능을 측정하기 위해,
- spatial/geometric transformation: cropping and resizing, rotaton, cutout
- apperance transformation: color distortion, gaussian blur, sobel filtering
등을 적절히 조합하여 사용하였고, 위의 그림은 그 조합들에 대한 각각의 모델 성능을 나타낸다. 그 결과 random cropping + color distortion의 조합이 가장 큰 성능을 보여주었다. 이때, 랜덤하게 데이터를 cropping하는 것은 위험하다. 대부분의 이미지 패치들이 비슷한 색깔 분포를 공유하기 때문이다.
3-2. Contrastive learning needs stronger data augmentation than supervised learning
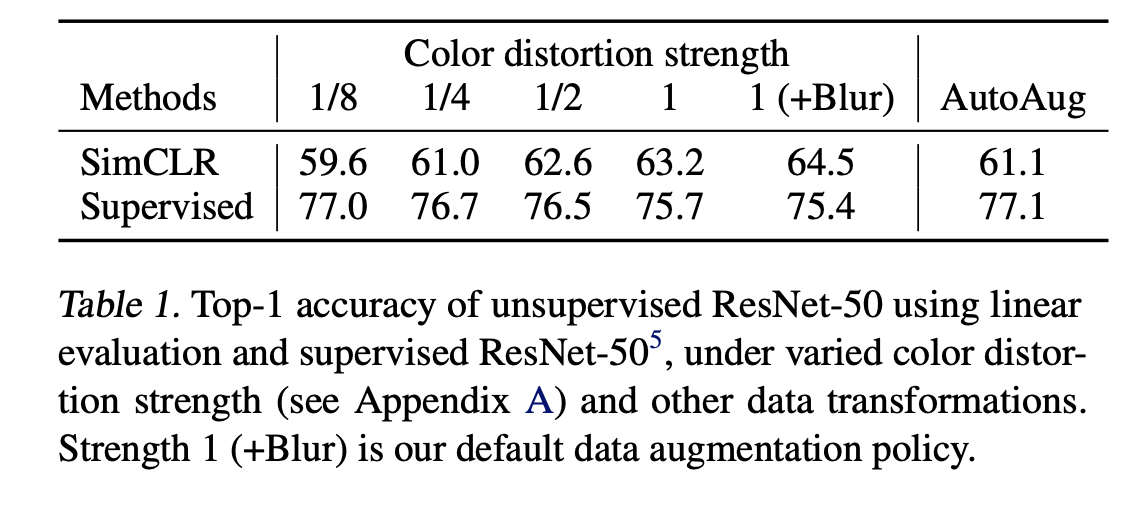
color augmentation의 중요성을 말하기 앞서, 해당 변화의 힘을 측정하였다. color augmentation이 더 강할 수록 더욱더 성능이 향상되는 것을 발견하였다. 그렇지만 supervised learning에서는 이러한 데이터 augmentation이 제 힘을 발휘하지 못하는 경우가 많다.
4. Architecture for Encoder and Head
4-1. Unsupervised contrastive learning benefits from bigger models
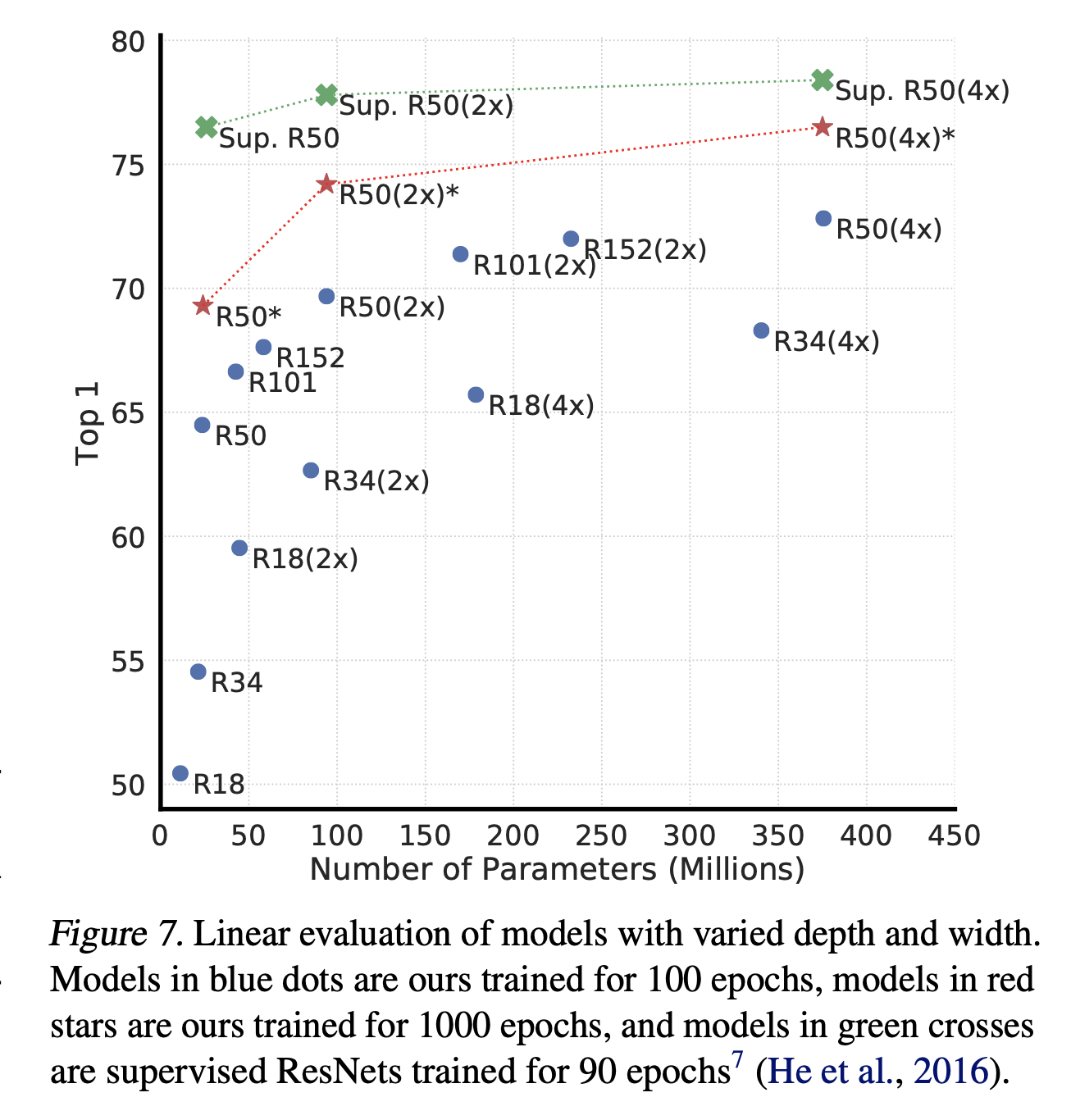
위의 그림에서 보이듯이, 당연하게도 모델의 depth와 width를 높이면 성능이 향상하게 된다. supervised learning에서도 이와 유사하다. 저자는 supervised model과 unsupervised model로 학습된 linear classifier간의 갭이 모델 사이즈가 커질수록 줄어든다는 것을 발견했다. 즉 unsupervised learning을 사용할거면 큰 모델을 사용하는 것이 좋다라고 생각하면 된다.
4-2. A nonlinear projection head improves the representation quality of the layer before it
저자는 이후 projection head인 g(h)의 종류와 차원을 달리하며 성능을 측정하였다. 그림에서 보이듯, 차원과는 대부분 상관없이 non-linear한 projection head가 성능이 좋다는 것을 찾을 수 있다.
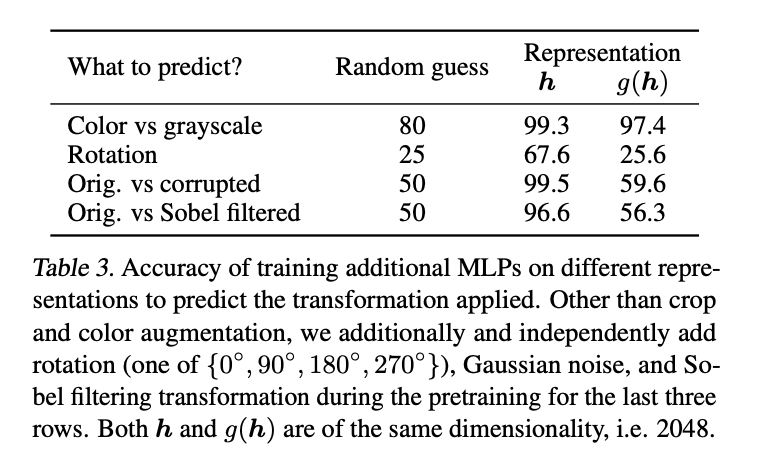
또한, 최적의 representation은 projection head 전 layer에서 뽑힌 representation이 제일 최적이다. 이에 대한 이유로, contrastive loss로 인해 발생하는 정보의 손실을 그 이유로 뽑았다. 구체적으로 설명해보자면, 는 data transformation에 따라 다르게 표현이 된다. 그래서, g는 downstream task에 중요하게 쓰일 색깔과 같은 정보를 없앨 가능성이 크다. g를 활용함으로써, h에는 오히려 더. 유용한 정보들이 남게 된다. h에서 이러한 정보를 대신 없애주기 때문이다. 이러한 가정을 확인하기 위해 h 혹은 g(h)만을 활용하여 예측 task를 해결하는 실험을 진행하였고, 그 결과 h가 더 유용한 정보를 포함하고 있음을 위 표에서 확인할 수 있다.
5. Loss functions and Batch Size
5-1. Normalized cross entropy loss with adjustable temperature works better than alternatives

해당 모델에서 사용된 NT-Xent loss를 다른 loss function 값과 비교하여 실험을 진행하였다. 실험에 대한 결과는 위와 같다. 저자는 gradient의 추이를 보며 1) temperature에 따른 l2 noramlization(코사인 유사도)이 다양한 예제들에 효과적으로 가중치를 부여한다는 것, 2) 그리고 적절한 temperature값은 학습에 도움이 된다는 점, 3) cross entropy와 다르게 다른 목적함수들은 상대적 hardness를 이용하여 negative pair에 효과적으로 가중치를 부여한다는 점을 알아내었다.
5-2. Contrastive learning benefits from larger batch sizes and longer training
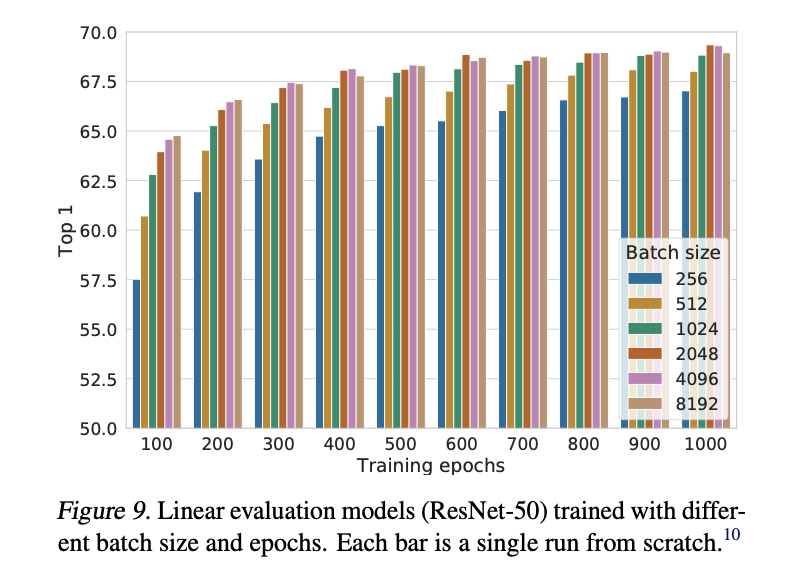
constrastive learning을 사용 시에는 더 큰 batch size와 더 큰 epoch를 지닐 때 성능이 올라감을 위에서 확인할 수 있다.
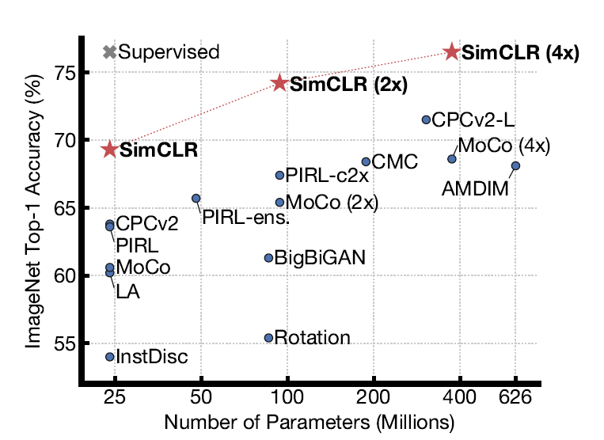
6. Comparision with SoTA
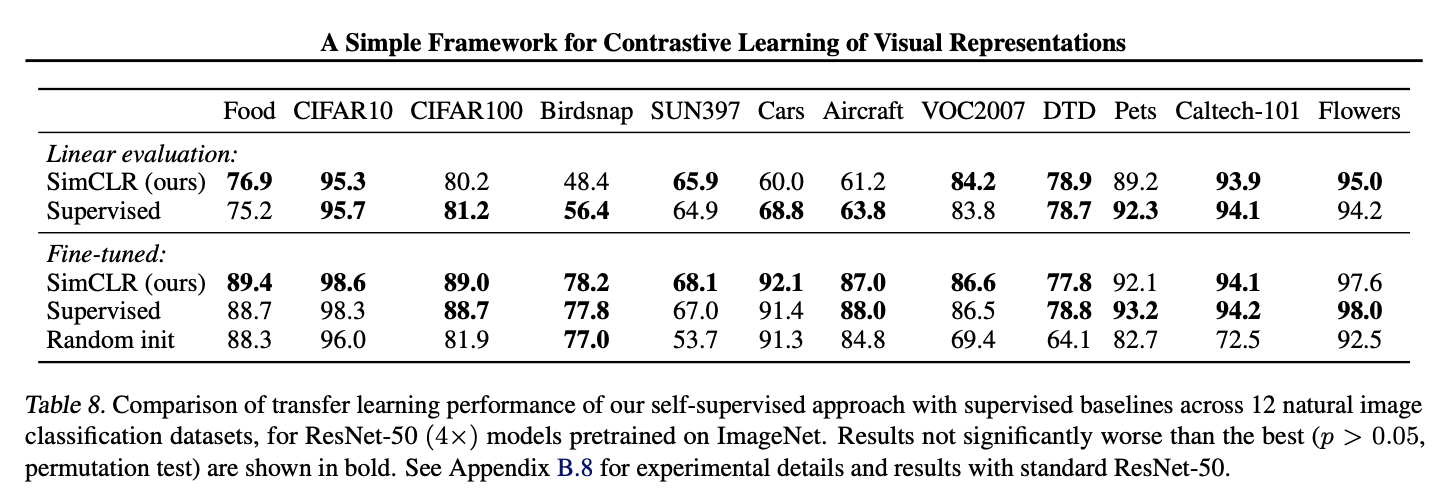
도표를 참고하길 바란다.
