페이징 처리 기법
DB의 데이터를 클라이언트에서 페이징 처리하여 표시하는 방법에는 현재 페이지와 다음 페이지를 나누는 기준에 따라 offset 방식과 cursor 방식이 있습니다.
offset based pagination
offset은 특정 페이지에서 표시할 데이터의 시작점을 의미하며, page 값을 이용해 한 페이지의 총 데이터 개수인 limit과 함께 다음 offset이 계산됩니다.
예를들어 limit이 10이라면, 각 페이지에 따른 offset 값은 다음과 같습니다.
- page = 1, offset = 0
- page = 2, offset = 10
- page = 3, offset = 20
장점
-
구현이 쉽습니다.
Supabase API에서는range함수만을 사용해 특정 페이지의 데이터를 불러올 수 있습니다. (이후 자세한 구현을 다룰 예정입니다.) -
데이터의 개수와, 페이지의 총 개수를 파악할 수 있습니다.
이를 이용하여 특정 페이지로 한 번에 이동이 가능합니다.
offset 기반 페이지네이션은 데이터 추가, 제거가 많지 않고 페이지 숫자로 구성된 UI가 필요한 게시판 형태에 사용할 수 있습니다.
단점
-
클라이언트에서 데이터의 중복이 발생할 수 있습니다.
유저1이 1페이지의 데이터를 확인하는 중 유저2가 새로운 데이터를 추가했을 때, 유저 1은 1페이지에서 확인했던 데이터를 2페이지에서 다시 보게 됩니다. -
offset이 증가할수록 성능이 저하됩니다.
데이터를 조회하는 쿼리가offset이전까의 데이터를 불러온 후limit만큼의 데이터를 잘라내는 방식으로 동작하기 때문입니다.
cursor based pagination
cursor에는 id, created_at과 같이 데이터를 구분할 수 있는 유일한 값이 저장됩니다. 페이지 이동 시 특정 필드의 값을 cursor비교하여 limit 개수만큼 데이터를 불러온 후, cursor를 업데이트 합니다.
첫번째 페이지에서 cursor은 null입니다. limit가 5라고 했을 때, 첫 페이지의 데이터 5개를 불러온 후 5번째 데이터의 created_at 값이 curosr에 저장됩니다. 이후 페이지에서는 created_at이 cursor보다 작은 5개의 데이터를 불러오고, cursor를 마지막 데이터의 created_at으로 다시 업데이트 합니다.
장점
- 실시간 데이터 페이징에 유리하다.
cursor를 기반으로 다음 페이지를 보여주기 때문에 페이지를 넘기는 과정에서 새로운 데이터가 추가되어도 그 데이터가 다음 페이지 데이터 목록에 영향을 주지 않습니다. - 보여주는 데이터의 양이 많아져도 성능이 일정하다.
쿼리가cursor와 특정 필드의 값을 비교하여limit개수 만큼만 데이터를 확인하기 때문에 페이지 수와 관계없이 일정한 속도로 데이터를 불러옵니다.
단점
- 데이터 정렬에 제한이 있다.
cursor는 데이터마다 다른 값을 가지고 있는 필드의 값으로 설정되어야 합니다. like_count(좋아요 수)가cursor로 지정되었을 때 중복된 like_count을 가지고 있는 데이터가 있다면, 다음 페이지에서 해당 데이터들은 보여지지 않습니다. (이 때like_count와created_at을 모두 cursor로 사용하거나, 이 두 컬럼의 값을 조합해 새로운 cursor 컬럼을 만드는 등의 방법으로 해결할 수 있습니다.) - 사용자가 원하는 페이지로 이동이 어렵다.
특정 페이지로의 이동까지 cursor가 순차적으로 업데이트 되어야 하기 때문이다.
cursor 기반 페이지네이션은 데이터가 실시간으로 추가, 제거되거나 규모가 큰 SNS, 채팅 등의 무한 스크롤 구현에 사용할 수 있습니다.
페이지네이션 구현
오프셋 기반
목표

Pagination 컴포넌트의 UI 버튼 동작에 따라 데이터를 페이징 처리하려고 합니다.
동작 흐름도
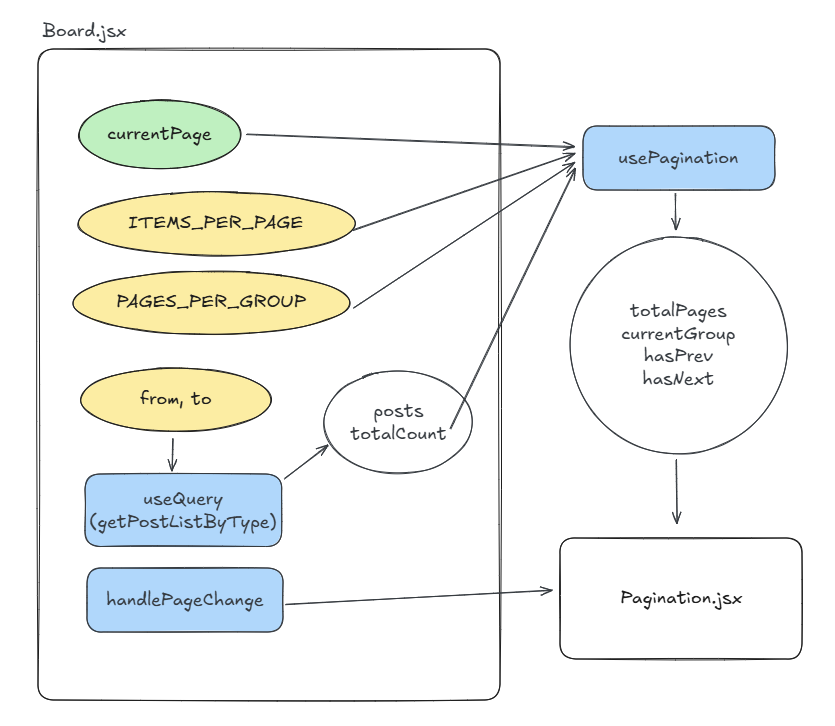
Board.jsx는 현재 페이지 숫자를 나타내는 상태인 currnetPage와 함께 다음 변수들을 가지고 있습니다.
ITEMS_PER_PAGE: 한 페이지당 불러올 아이템 개수PAGES_PER_GROUP: 한 페이지 그룹에서 보여줄 페이지 개수 (위의 스크린샷에서PAGES_PER_GROUP의 값은 3입니다.)from,to: supabase 쿼리(getPostListByType)에 전달되어 원하는 범위의 데이터를 불러오는 offset 역할을 합니다.
getPostListByType로 획득한 데이터는 posts와 totalCount로 나눠지며, useQuery에 의해 브라우저 메모리에 캐싱됩니다.
currentPage와 ITEMS_PER_PAGE, PAGES_PER_GROUP, totalCount는 usePagination 훅으로 전달되며, 내부에서 알고리즘을 통해 다음 속성을 가진 객체를 반환합니다.
totalPages: 총 페이지 개수입니다.currentGroup: 현재 위치한 페이지 그룹을 나타냅니다. (위 스크린샷의 3페이지에서 다음 버튼을 누르면currentGroup은 [1,2,3]에서 [4,5]로 바뀝니다.)hasPrev,hasNext:currentPage의 이전, 다음 페이지 존재 여부를 나타냅니다.
totalPages, currentGroup, hasPrev, hasNext와 함께 페이지 이동시 currentPage 상태의 값을 변경하고, url에 page 파라미터를 추가하는 handlePageChange 함수가 페이지네이션 UI를 렌더하는Pagination 컴포넌트에 props로 전달되며 페이징이 동작합니다.
코드
Board.jsx
const getSortOptionFromURL = () => {
const params = new URLSearchParams(location.search);
const value = params.get('sortBy');
return (
options.find((option) => option.value === value) || {
name: '정렬 기준',
value: '',
}
);
};
const [currentPage, setCurrentPage] = useState(getPageFromURL());
const ITEMS_PER_PAGE = 3;
const PAGES_PER_GROUP = 3;
const from = (currentPage - 1) * ITEMS_PER_PAGE;
const to = from + ITEMS_PER_PAGE - 1; currentPage의 초기값은 url 쿼리스트링에 저장된 page params로부터 불러옵니다. 이를 통해 페이지 값이 포함된 url을 통해 특정 페이지의 게시글을 바로 확인할 수 있습니다.
from과 to는 currentPage와 ITEMS_PER_PAGE 값에 의해 계산됩니다.
| from | to | |
|---|---|---|
| currentPage = 1 | 0 | 2 |
| currentPage = 2 | 3 | 5 |
| currentPage = 3 | 6 | 8 |
| currentPage = 4 | 9 | 11 |
즉, 오프셋 기반 페이지네이션에서 limit은 3이 되고, offset은 currentPage에 따라 0, 3, 6, 9로 증가합니다.
const { data, isLoading } = useQuery({
queryKey: ['posts', boardType, currentPage, sortOption.value],
queryFn: () => {
return getPostListByType(studyId, boardType, from, to, sortOption.value);
},
select: (res) => ({
posts: res.data,
totalCount: res.count,
}),
staleTime: 1000 * 10,
});useQuery의 queryFn에는 getPostListByType 함수에 from과 to를 전달하여 사용했습니다.
queryKey에 currentPage를 추가해 페이지가 바뀔 때 마다 해당 offset의 데이터를 캐싱해줍니다.
getPostListByType.js
import supabase from '@libs/supabase';
export const getPostListByType = (studyId, type, from, to, sortBy) => {
const query = supabase
.from('posts')
.select(
`*,
post_participants (
user_id,
is_writer,
users (
id,
nickname,
img_url
)
)
`,
{ count: 'exact' },
)
.eq('type', type)
.eq('study_id', studyId);
if (sortBy) {
if (sortBy === 'mostViewed') {
query.order('views', { ascending: false });
} else if (sortBy === 'mostCommented') {
query.order('comment_count', { ascending: false });
} else if (sortBy === 'recent') {
query.order('recent_activity', { ascending: false });
}
} else {
query.order('created_at', { ascending: false }); // default : 최신 순 정렬
}
if (typeof from === 'number' && typeof to === 'number') {
query.range(from, to);
}
return query;
};수퍼베이스 쿼리 함수의 길이가 길기 때문에 따로 분리해주었습니다.
range 함수에 from과 to를 전달하여 offset만큼의 데이터를 비동기적으로 획득하는 Promise 객체를 반환합니다.
Board.jsx
const pagination = usePagination(
currentPage,
data?.totalCount || 0,
ITEMS_PER_PAGE,
PAGES_PER_GROUP,
);usePagination 훅에 currentPage와 useQuery로부터 획득한 totalCount, ITEMS_PER_PAGE, PAGES_PER_GROUP을 전달하여 사용합니다.
usePagination
import { useMemo } from 'react';
const usePagination = (
currentPage,
totalCount,
itemsPerPage,
pagesPerGroup = 3,
) => {
// 총 페이지 개수
const totalPages = Math.ceil(totalCount / itemsPerPage);
// currentPage가 속하는 pageGroup을 나타내는 인덱스
const currentGroupIndex = Math.floor((currentPage - 1) / pagesPerGroup);
// pagesPerGroup 맞춰 pageGroups를 나누는 로직
const pageGroups = useMemo(() => {
const newPageGroups = [];
for (let i = 1; i <= totalPages; i += pagesPerGroup) {
const group = [];
for (let j = 0; j < pagesPerGroup && i + j <= totalPages; j++) {
group.push(i + j);
}
newPageGroups.push(group);
}
return newPageGroups;
}, [totalPages, pagesPerGroup]);
return {
totalPages,
currentGroup: pageGroups[currentGroupIndex] || [],
hasPrev: currentPage > 1,
hasNext: currentPage < totalPages,
};
};
export default usePagination;usePagination은 pagesPerGroup을 계산하고, currentPage가 위치한 페이지 그룹인 currentGroup을 totalPages, hasPrev, hasNext와 함께 객체로 반환합니다.
pageGroups를 계산하는 과정은 즉시실행함수와 useMemo를 사용하여 totalPages, pagesPerGroup이 변경됐을때만 실행되도록 하였습니다.
예를 들어 totalPages가 7이고, pagesPerGroup이 3이라면, pageGroups는 [[1,2,3],[4,5,6],[7]]의 이차원 배열 형태를 가지게 됩니다.
그리고 currentPage가 5라면 currentGroupIndex는 1이 되어 [4,5,6]의 currentGroup을 반환하게 됩니다.
Board.jsx
const handlePageChange = (page) => {
const params = new URLSearchParams(location.search);
setCurrentPage(page);
params.set('page', page); // url에서 page와 sortBy 파라미터 동시 적용
navigate(`?${params.toString()}`);
};handlePageChange가 실행되면 currentPage를 매개변수 page로 바꾸고, 쿼리스트링에 page 파라미터가 추가된 url로 이동합니다. (예시 : http://localhost:5173/study/1/debate?sortBy=recent&page=2)
return (
<div className="lg:mx-0 md:-mx-8 sm:-mx-6">
{/* ... */}
<div className="h-[64px] flex items-center justify-center">
<Pagination
currentPage={currentPage}
onPageChange={handlePageChange}
currentGroup={pagination.currentGroup}
hasPrev={pagination.hasPrev}
hasNext={pagination.hasNext}
/>
</div>
{/* ... */}
</div>
);마지막으로 Pagination 컴포넌트에 props를 알맞게 전달하여 UI에 기능을 추가합니다.
Pagination.jsx
import PropTypes from 'prop-types';
const Pagination = ({
currentPage,
onPageChange,
currentGroup = [],
hasPrev,
hasNext,
}) => {
return (
<div className="flex justify-center items-center gap-2 h-[64px] *:cursor-pointer">
{/* 이전 버튼 */}
<div
className={`px-4 py-1 border-1 border-slate-500 rounded-xl text-slate-500 bg-white ${!hasPrev && 'opacity-60 pointer-events-none'}`}
onClick={() => hasPrev && onPageChange(currentPage - 1)}
>
이전
</div>
{/* 페이지 그룹 */}
{currentGroup?.map((page) => {
return (
<div
key={page}
className={`px-4 py-1 border-slate-500 rounded-xl ${page === currentPage ? 'bg-primary-300 text-white' : 'border-1 border-slate-500 bg-white text-slate-500'} `}
onClick={() => onPageChange(page)}
>
{page}
</div>
);
})}
{/* 다음 버튼 */}
<div
className={`px-4 py-1 border-1 border-slate-500 rounded-xl text-slate-500 bg-white ${!hasNext && 'opacity-60 pointer-events-none'}`}
onClick={() => hasNext && onPageChange(currentPage + 1)}
>
다음
</div>
</div>
);
};
Pagination.propTypes = {
currentPage: PropTypes.number.isRequired,
onPageChange: PropTypes.func.isRequired,
currentGroup: PropTypes.array.isRequired,
hasPrev: PropTypes.bool.isRequired,
hasNext: PropTypes.bool.isRequired,
};
export default Pagination;정렬
Board.jsx
const getSortOptionFromURL = () => {
const params = new URLSearchParams(location.search);
const value = params.get('sortBy');
return (
options.find((option) => option.value === value) || {
name: '정렬 기준',
value: '',
}
);
};
const [sortOption, setSortOption] = useState(getSortOptionFromURL());
const handleSortOptionChange = (sortOption) => {
setSortOption(sortOption);
navigate(`?sortBy=${sortOption.value}`); // URL의 page 파라미터를 업데이트
};
// ...
return (
<div className="lg:mx-0 md:-mx-8 sm:-mx-6">
{/* ... */}
<DropdownBox
selectedOption={sortOption}
options={options}
onChange={handleSortOptionChange}
size={md ? 'medium' : 'small'}
/>
{/* ... */}
</div>
);
정렬은 sortOption 상태와 클릭한 옵션을 sortOption에 저장하고 url 파라미터를 업데이트하는 handleSortOptionChange 함수를 DropDownBox 컴포넌트에 전달하여 기능을 구현했습니다.
sortOption을 useQuery의 queryKey로 지정했기때문에 2페이지에서 정렬 옵션을 선택하면 정렬된 데이터의 두 번째 페이지가 바로 보여집니다. (offset은 유지된 상태로 supabase 쿼리의 조건문에서 order 함수 사용)
커서 기반
목표

커서 기반 페이지네이션을 활용해 무한 스크롤 기능을 구현하고, 정렬 기능도 함께 적용되도록 만드려 합니다.
동작 흐름도
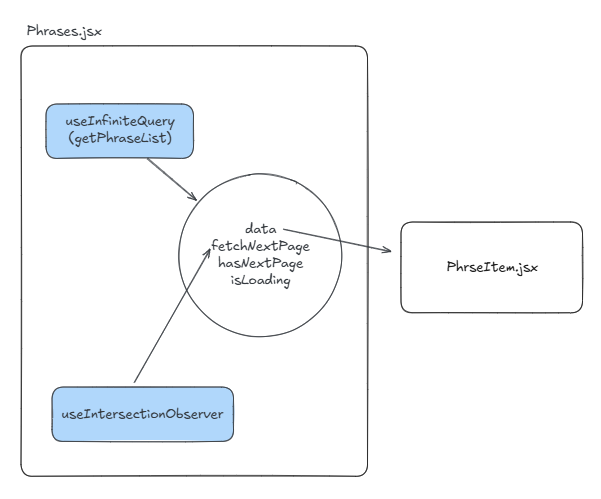
커서 기반 페이지네이션은 tanstack-query에서 지원하는 useInfiniteQuery 함수로 간단하게 구현할 수 있었습니다.

useInfiniteQuery는 pageParam을 cursor로 사용해 queryFn에서 cursor로부터 limit 개수 만큼의 데이터를 불러온 후 getNextPageParam 함수를 사용해 다음 pageParam을 재설정합니다.
그 후 fetchNextPage가 실행되면 위의 작업을 반복합니다.
획득한 data 객체는 다음의 속성을 가지고 있습니다.
- pageParams 배열 : 현재까지 데이터 패칭에 사용한 cursor 정보
- pages 배열 : `pageParams를 이용해 획득한 data 배열 (페이지 별로 구분되어 있습니다.)
초기 data와 fetchNextPage가 실행되었을 때의 data

그 외에 hasNextPage는 다음 페이지 여부를, isLoaing은 초기 데이터 로딩 여부를, isFetchingNextPage는 fetchNextPage가 실행되었을 때 다음 페이지의 데이터 로딩 여부를 의미합니다.
data를 UI를 렌더하는 컴포넌트에 map하고, 화면에 마지막 아이템이 보여질 때 fetchNextPage를 실행하여 무한 스크롤을 구현할 수 있었습니다.
코드
Phrases.jsx
const { data, fetchNextPage, hasNextPage, isLoading } = useInfiniteQuery({
queryKey: ['phrases', studyId, sortOption.value],
queryFn: async ({ pageParam = null }) => {
return await getPhraseList(studyId, pageParam, sortOption.value);
},
getNextPageParam: (lastPage) => {
if (lastPage.length === 0) return undefined;
const lastItem = lastPage[lastPage.length - 1];
if (sortOption.value === 'mostLiked') {
return {
likeCount: lastItem.like_count,
createdAt: lastItem.created_at,
};
} else if (sortOption.value === 'pageAscending') {
return {
page: lastItem.page,
createdAt: lastItem.created_at,
};
} else {
return lastItem.created_at;
}
},
staleTime: 1000 * 10,
});
// 🌀 화면에 lastItemRef가 보여졌을 때 실행되는 함수
const handleIntersect = () => {
if (hasNextPage && !isLoading) {
fetchNextPage();
}
};
// 🌀 커스텀 훅 안에서 선언된 관찰 대상(targetRef)를 바깥에서 지정합니다.
const lastItemRef = useIntersectionObserver(handleIntersect);getNextPageParam의 lastPage 인자는 data의 pages 배열에서 마지막 요소를 의미합니다. (위에서 useInfiniteQuery가 반환하는 data 구조를 확인할 수 있습니다.)
저는 기본적으로 cursor를 created_at 값으로 사용했고, getNextPageParam이 호출될 때 페이지 내에서의 마지막 요소의 created_at 값으로 pageParam을 갱신하도록 했습니다. (sortOption이 존재하는 경우는 정렬 기능 구현에서 다시 살펴보겠습니다.)
queryFn에서 getPhraseList를 호출할 때 pageParam에는 null이 전달됩니다.
getPhraseList.js
import supabase from '@libs/supabase';
export const getPhraseList = async (studyId, cursor, sortBy) => {
const query = supabase
.from('phrases')
.select(
`*,
users (id,nickname,img_url),
likes(user_id)
`,
)
.eq('study_id', studyId);
if (sortBy) {
if (sortBy === 'mostLiked') {
query
.order('like_count', { ascending: false })
.order('created_at', { ascending: false });
if (cursor) {
const { likeCount, createdAt } = cursor;
query.or(
`like_count.lt.${likeCount},and(like_count.eq.${likeCount},created_at.lt.${createdAt})`,
);
}
} // 최신 순 정렬
else if (sortBy === 'pageAscending') {
query
.order('page', { ascending: true })
.order('created_at', { ascending: false });
if (cursor) {
const { page, createdAt } = cursor;
query.or(
`page.gt.${page},and(page.eq.${page},created_at.lt.${createdAt})`,
);
}
}
} else {
query.order('created_at', { ascending: false }); // 최신 순 정렬
if (cursor) {
query.lt('created_at', cursor);
}
}
query.limit(5);
const { data, error } = await query;
if (error) throw error;
return data;
};getPhraseList는 인자 pageParams를 cursor 매개변수로 받습니다.
조건문은 정렬 기능 구현을 위해 사용하였고, else 부분에서 cursor가 없다면(null) 최신순으로 정렬 후 limit로 상위 5개의 데이터만, cursor가 있다면 lt로 해당 커서 다음부터 5개의 데이터를 획득하는 쿼리 함수를 사용했습니다.
useInfiniteQuery는 queryFn에 Porimise 객체를 사용하는 useQuery와 다르게 실제 데이터를 사용해야합니다. 따라서 query에 await으로 비동기처리된 data를 반환했습니다.
useIntersectionObserver.jsx
import { useEffect, useRef } from 'react';
const useIntersectionObserver = (onIntersect) => {
const observerRef = useRef(null); // 관찰 도구
const targetRef = useRef(null); // 관찰할 DOM 노드
useEffect(() => {
// 기존의 관찰 설정을 초기화합니다.
if (!targetRef.current) return;
if (observerRef.current) observerRef.current.disconnect();
// 관찰 도구(Intersection Observer 인스턴스)를 설정합니다.
observerRef.current = new IntersectionObserver(
(entries) => {
// 등록된 entries 중 첫 번째 요소가 화면에 보일 때 onInteresect이 실행됩니다.
if (entries[0].isIntersecting) {
onIntersect();
}
},
// entry가 화면에 100% 모두 나타났을 때 isIntersecting이 ture로 바뀝니다.
{ threshold: 1.0 },
);
// 설정된 관찰 도구에 targetRef를 등록합니다.
observerRef.current.observe(targetRef.current);
// 메모리 누수 방지를 위해 언마운트시 등록을 해제합니다.
return () => observerRef.current?.disconnect();
}, [onIntersect]);
return targetRef;
};
export default useIntersectionObserver;useIntersectionObserver 훅은 onIntersect 함수를 매개변수로 받고, ref 객체의 참조값인 targetRef를 리턴합니다.
targetRef.current는 관찰할 DOM 노드를 의미하며, observerRef.current는 관찰 대상이 화면에 나타나면 onIntersect 함수를 실행하는 IntersectionObserver 인스턴스를 가지고 있습니다.
observe 함수를 통해 targetRef.current는 관찰 대상이 됩니다.
Phrases.jsx
const handleIntersect = () => {
if (hasNextPage && !isLoading) {
fetchNextPage();
}
};
const lastItemRef = useIntersectionObserver(handleIntersect);lastItemRef와 useIntersectionObserver 훅 안의 targetRef는 같은 참조값을 가지고 있습니다.
이것은 ref 객체를 담을 빈 그릇을 의미하며, 이후 jsx 태그의 ref props에 의해 ref 객체가 등록됩니다.
return (
<div className="lg:mx-0 md:-mx-8 sm:-mx-6">
<div className="pb-8 max-w-[1000px] mx-auto lg:px-10 md:px-8 px-6 flex flex-col gap-4">
{!isLoading &&
data?.pages.map((page, i) => (
<div key={i} className="flex flex-col gap-4">
{page.map((phrase, i, pages) => (
//🌀 각 페이지의 마지막 데이터를 관찰 대상으로 지정
<PhraseItem
key={phrase.id}
phraseData={phrase}
ref={i === pages.length - 1 ? lastItemRef : null}
/>
))}
</div>
))}
</div>
</div>
);data 구조에 맞게 map을 두 번 사용해주고, pages의 마지막 PhraseItem 컴포넌트에서 ref를 등록해줍니다.
결과적으로 마지막 PhraseItem이 화면에 보여질 때 handleIntersect 함수 안에서 fetchNextPage가 실행됩니다.
이후 새로운 data와 함께 PhraseItem이 다시 렌더됩니다.
정렬
Phrase 데이터를 정렬하여 무한 스크롤과 함께 보여주기 위해 다음을 고려해야합니다.
-
스크롤이 동작하지 않은 첫 페이지에서 보여줄 데이터 (cursor가 null일 때)
-
스크롤이 동작해쓸 때 다음 페이지에서 보여줄 데이터
created_at 정렬
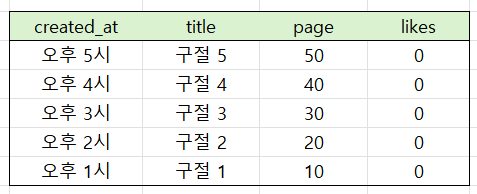
데이터는 기본적으로 created_at 내림차순으로 불러와지고, 이 상황에서 첫 페이지의 데이터는 다음과 같습니다. (created_at은 실제로 ms까지 저장되므로 중복인 경우는 제외했습니다.)

그리고 cursor에는 오후 6시 값이 저장되고, 다음 페이지를 불러올때는 lt 함수를 이용하여 오후 6시보다 작은 5개 데이터를 불러옵니다.
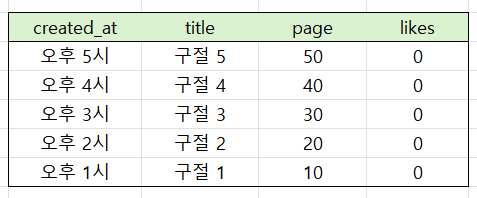
likes 정렬
만약 likes 오름차순으로 데이터를 정렬할 때 cursor에 likes만을 사용하면 데이터 중복이 발생할 수 있습니다.
아래처럼 작성된 supabase 쿼리 함수가 사용될 것이고,
if (sortBy === 'mostLiked') {
query
.order('like_count', { ascending: false })
if (cursor) {
query.lt('like_count', cursor);
}
}첫 페이지의 데이터는 정상적으로 불러와지지만,

likes가 0인 다른 데이터들은 lt 함수에 의해 제외되어 다음 페이지가 불러와지지 않습니다.
이를 해결하려면 cursor에 likes와 함께 created_at을 저장하면 됩니다.
if (sortBy === 'mostLiked') {
query
.order('like_count', { ascending: false })
.order('created_at', { ascending: false });
if (cursor) {
const { likeCount, createdAt } = cursor;
query.or(
`like_count.lt.${likeCount},and(like_count.eq.${likeCount},created_at.lt.${createdAt})`,
);
}
}or 함수를 사용하여, 만약 데이터의 like_count가 cursor와 같다면 created_at도 함께 비교하여 데이터 중복을 피할 수 있습니다.
예를 들어 첫 페이지의 데이터를 불러온 후 cursor는 {likeCount: 0, createdAt: 오후 7시}가 됩니다.
다음 페이지의 데이터들은 모두 like_count가 0이므로 like_count.lt.${likeCount} 조건을 만족하는 데이터는 존재하지 않고, and(like_count.eq.${likeCount},created_at.lt.${createdAt})에 의해 like_count가 0이면서 오후 7시 이전에 작성된 데이터들이 or에 의해 불러와집니다.