조건으로 검색하기
numpy array와 마찬가지로 masking연산이 가능하다
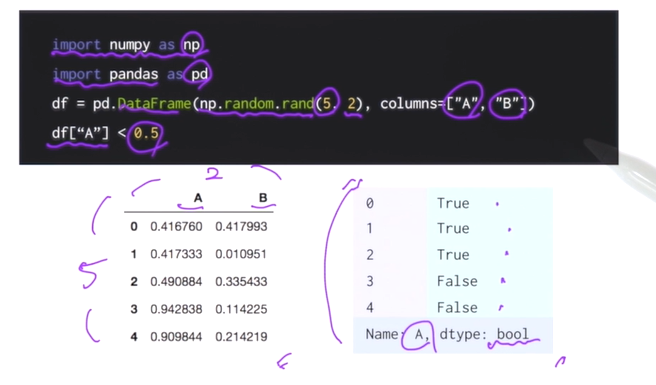

두가지 타입으로 검색 가능
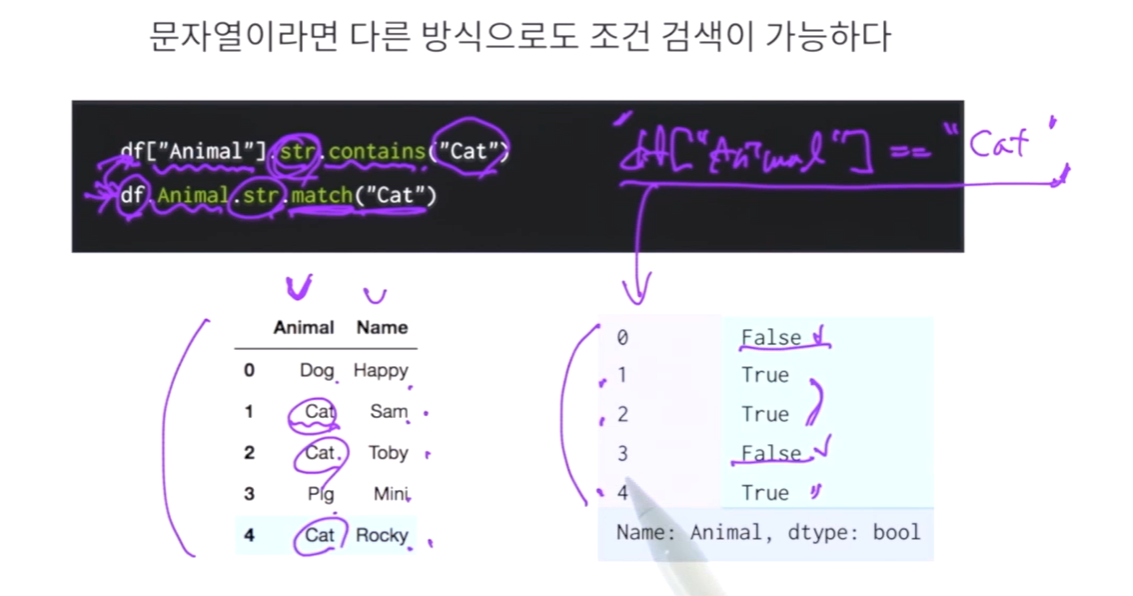
실습
print("Masking & query")
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
print(df, "\n")
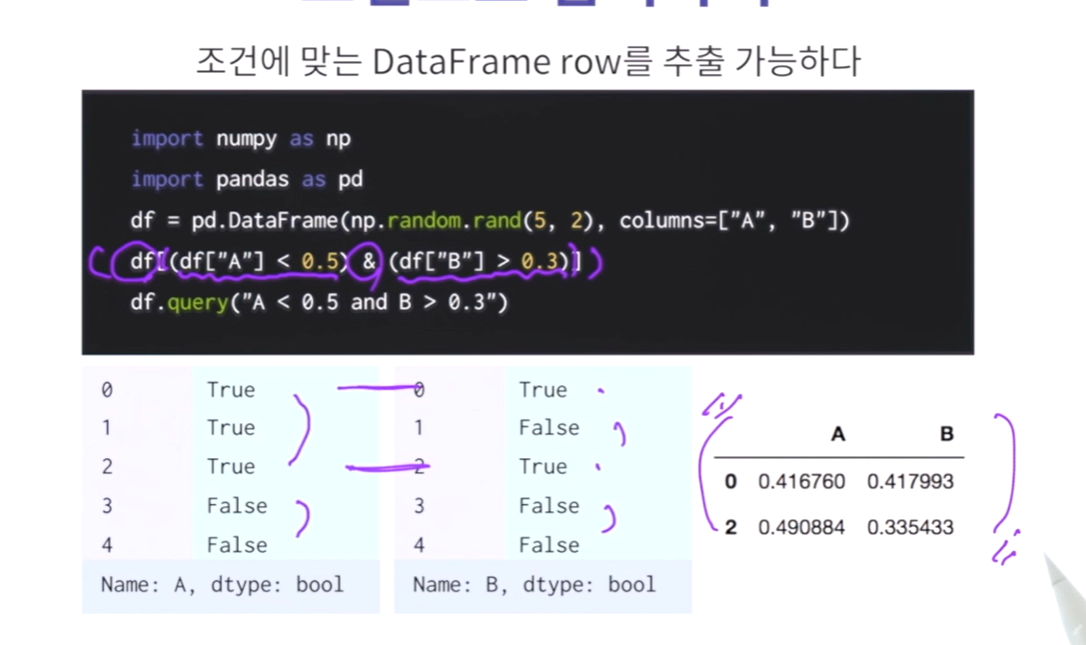
#데이터 프레임에서 A컬럼값이 0.5보다 작고 B컬럼 값이 0.3보다 큰값들을 구해봅시다.
print( df[(df["A"]<0.5 ) & (df['B']>0.3)])
print(df.query("A<0.5 and B>0.3"))
함수로 데이터로 처리하기
함수로 데이터 처리하기

/////////////////////////


inplace
df = pd.DataFrame(np.arange(5), columns=["Num"])
print(df, "\n")
# 값을 받으면 제곱을 해서 돌려주는 함수
def square(x):
return x**2
# apply로 컬럼에 함수 적용
df["Square"] = df["Num"].apply(square)
# 람다 표현식으로도 적용하기
df["Square"] = df["Num"].apply(lambda x:x**2)그룹으로 묶기
그룹으로 묶기

aggregate



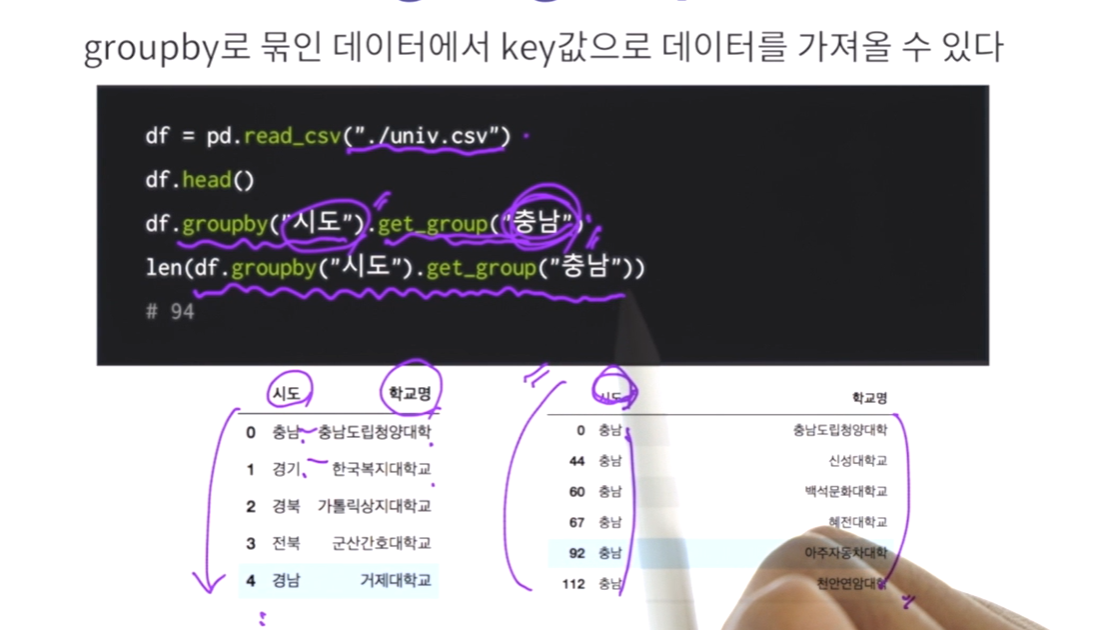
실습
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [1, 2, 3, 1, 2, 3],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")
# groupby 함수를 이용해봅시다.
# key를 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby('key').sum())
# key와 data1을 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby(['key','data1']).sum())
```python
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [0, 1, 2, 3, 4, 5],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")
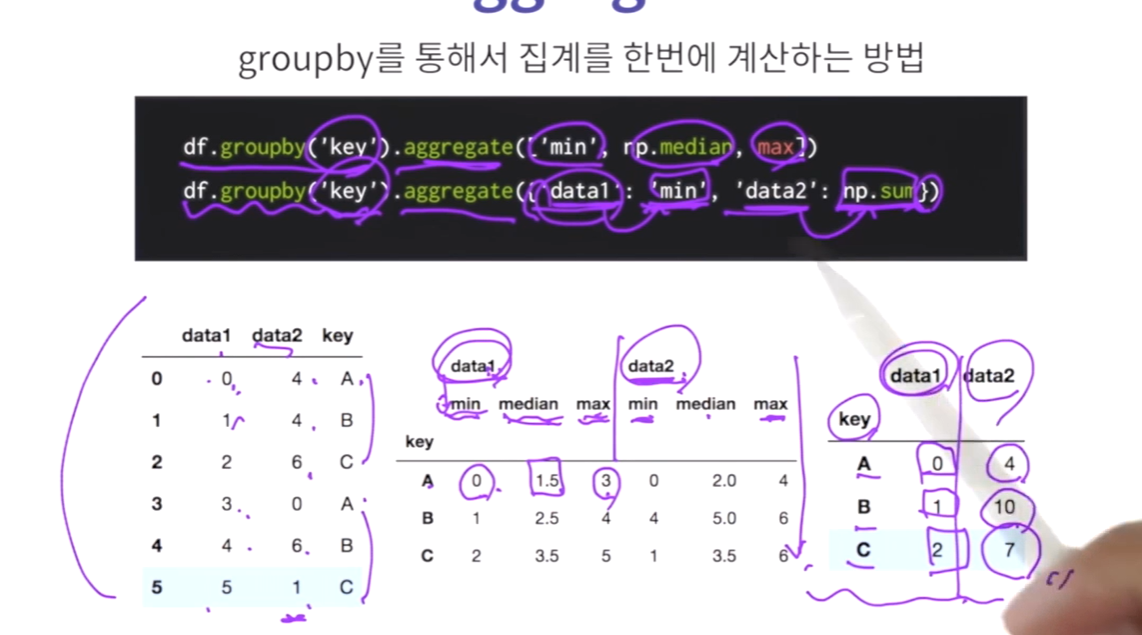
# aggregate를 이용하여 요약 통계량을 산출해봅시다.
# 데이터 프레임을 'key' 칼럼으로 묶고, data1과 data2 각각의 최솟값, 중앙값, 최댓값을 출력하세요.
print(df.groupby('key').aggregate([min,np.median,max]))
# 데이터 프레임을 'key' 칼럼으로 묶고, data1의 최솟값, data2의 합계를 출력하세요.
print( df.groupby('key').aggregate({'data1':min,"data2":sum}) )
- 괄호 확인!!!
import numpy as np import pandas as pd
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [0, 1, 2, 3, 4, 5],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")
groupby()로 묶은 데이터에 filter를 적용해봅시다.
key별 data2의 평균이 3이 넘는 인덱스만 출력해봅시다.
print("filtering : ")
def filter_by_mean(x):
return x['data2'].mean()>3
df.groupby('key').mean()
a=df.groupby('key').filter(filter_by_mean)
print(a)
groupby()로 묶은 데이터에 apply도 적용해봅시다.
람다식을 이용해 최댓값에서 최솟값을 뺀 값을 적용해봅시다.
print("applying : ")
b= df.groupby('key').apply(lambda x: x.max()-x.min())
print(b)
## M~
### MultiIndex

- 인덱스를 계층적으로 만들 수 있다.


- 다중 인덱스 컬럼의 경우 인덱싱은 계층적으로 한다
인덱스 탐새그이 경우에는 loc,iloc를 사용가능하다
### Pivot_table
>데이터에서 필요한 자료만 뽑아 새롭게 요약,
분석 할 수 있는 기능 엑셀에서의 피봇테이블과 같다
- index: 행 인덱스로 들어갈 key
- column에 열 인덱스로 라벨링될 값
- value: 분석할 데이터

>타이타닉 데이터에서 성별과 좌석별 생존률 구하기

//aggfunc : 없는 값은 평균으로 채운다
```python
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2']
)
print("DataFrame1")
print(df1, "\n")
df2 = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
print("DataFrame2")
print(df2, "\n")
# 명시적 인덱싱을 활용한 df1의 인덱스 출력
print("df1.loc['A', 1]")
print(df1.loc['A', 1], "\n")
# df2의 [A][1] 칼럼 출력
print('df2["A"]["1"]')
print(df2["A"]["1"], "\n")

🥰