지난 글에서 동시성의 개념과 쓰레드로컬을 이용한 해결방법에 대해 알아봤다. 오늘은 synchronized, lock, Redis를 이용한 해결방법에 대해 알아본다.
동시성 문제
동시성 문제는 같은 데이터 필드에 동시에 접근하려고 할 때 일어나는 문제로, 값이 비정상적으로 조회되거나 저장될 수 있다. 지역변수에서는 발생하지 않으며 주로 static으로 선언된 공용 필드나, 싱글톤 객체의 필드를 변경하려 할 때 발생하기 쉽다. [참고]
해결 방법
1. Synchronized
Synchronized란?
자바에서 제공하는 동기화 키워드로, 동기화가 필요한 메소드나 코드블럭 앞에 사용하여 동기화할 수 있다. synchronized로 지정된 임계 영역은 한 스레드가 이 영역에 접근하여 사용할 때 lock이 걸림으로써 다른 스레드가 접근할 수 없게 된다. 이후 해당 스레드가 이 임계영역의 코드를 모두 실행 후 벗어나게되면 unlock상태가 되어 그때서야 대기하고 있던 다른 스레드가 이 임계영역에 접근하여 다시 lock을 걸고 사용할 수 있게 된다.
1) 메소드에 임계영역(synchronized) 설정하기
- 메소드 이름 앞에 synchronized 키워드를 사용하여 해당 메소드 전체를 임계영역으로 설정할 수 있다.
synchronized void increase() {
count++;
System.out.println(count);
}2) 코드블럭에 임계영역(synchronized) 설정하기
- 동기화를 많이 사용할 경우 효율이 떨어지게 되므로, 필요한 부분에만 블럭을 지정하여 임계영역으로 설정할 수 있다.
- 아래 코드처럼, synchronized(this)로 지정하면, 참조변수(this) 객체의 lock을 사용하게 된다. 물론 this가 아닌 다른 객체도 지정할 수 있다. 이 동기화 블록에 전달되는 객체를 모니터 객체(a monitor object)라고 한다. 이 코드는 이 모니터 객체를 기준으로 동기화가 이루어짐을 나타내고 있다.
void increase() {
synchronized(this) {
count++;
}
System.out.println(count);참조변수 this?
인스턴스 자신을 가리키는 참조 변수. 인스턴스의 주소가 저장되어있다.
@Transactional 문제
그러나, Synchronized는 @Transactional 어노테이션과 함께 사용할 경우 동기화 문제가 여전히 발생할 수 있다.
@Transactional 어노테이션을 사용하면 Spring AOP로 인해 원래의 객체를 상속한 새로운 프록시 객체를 생성한다.
begin Transaction -> method -> commit Transaction
위와 같이 메소드를 감싸, 메소드 실행 전/후로 새로운 코드를 호출하게 된다.
이 때, begin / commit; 즉 Spring에서 추가하는 Transactional 코드는 우리가 synchronized를 이용해 동기화로 감싼 코드가 아닌 별도의 코드이다. 따라서 이 별도의 코드는 우리가 의도한 동기화 기능을 수행하지 않을 수 있다.
- 아래 예시처럼, 동기화된 메소드가 종료된 후 commit되기 전 시점에 다른 쓰레드에서 해당 메소드를 실행할 수 있다는 것이다.
T1: |--B--|--M--|--C-->
T2: |--B---------|--M--|--C-->
@Transactional 문제 해결 방법
위와 같은 문제 발생 시, @Transactional 호출 전 Synchronized를 호출하는 것이 아니라, Synchronized 안에서 @Transactional 메소드를 호출하게 되면 아래처럼 우리가 원하는 방식으로 메소드를 동기화할 수 있다.
T1: |--B--|--M--|--C-->T2: |--B--|--M--|--C-->
예제 코드
public class SynchronizedService() {
@Autowired
private TransactionService transactionService;
public synchronized void onRequest(Request request) {
transactionService.onRequest(request);
}
}
public class TransactionService() {
@Transactional
public void onRequest(Request request) {
...
}
}synchronized를 사용하지 않는 이유
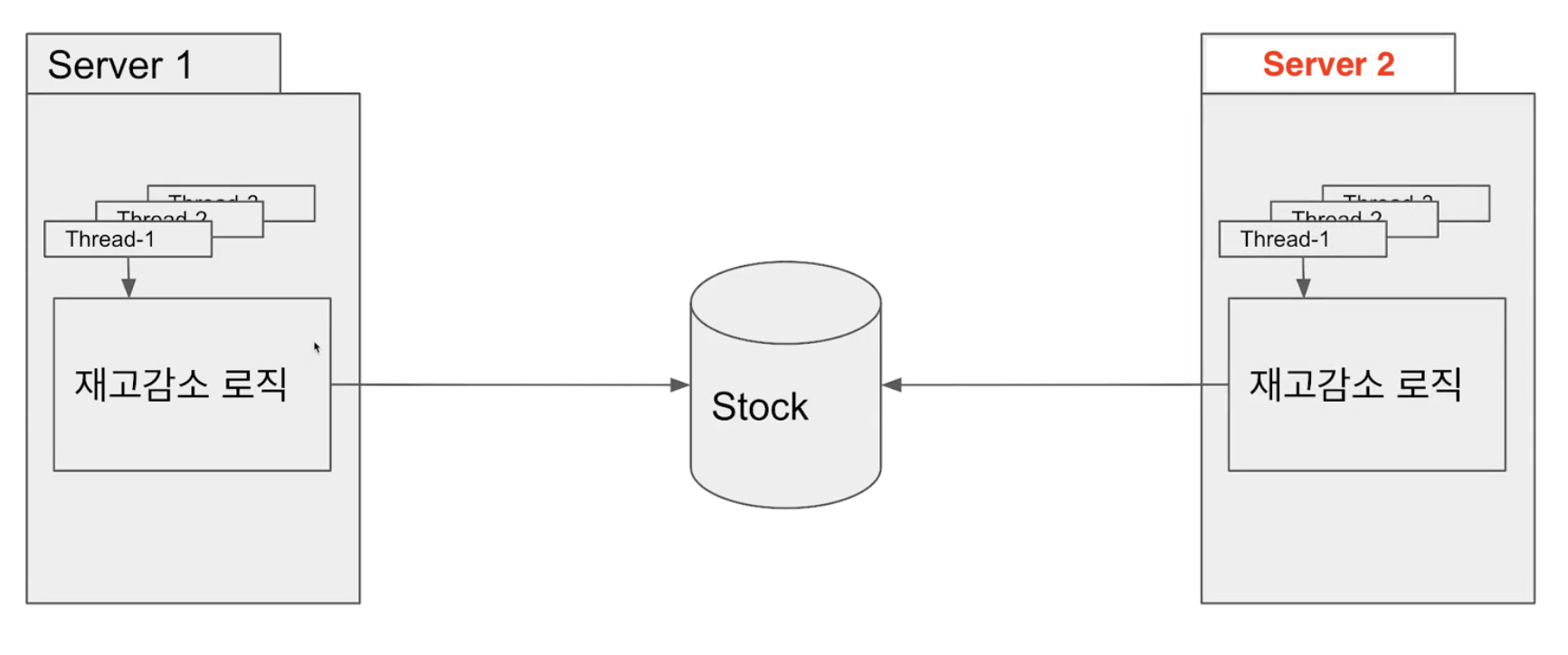
다만, synchronized는 한 프로세스 내에서만 동시성 제어가 가능하다. 그러나 실무에서는 대개 여러 대의 서버를 가지고 운용한다. 즉 두 개 이상의 프로세스를 실행하므로 synchronized는 잘 사용하지 않는다고 한다.
따라서 환경에 따라 애플리케이션 레벨에서의 동시성 제어가 아닌, 데이터베이스 레벨에서의 동시성 제어가 필요하다. 데이터에 직접 Lock을 걸어야 한다는 뜻이다.
2. Lock (MySQL)
- Lock의 종류에는 Pessimistic Lock(비관적 락), Optimistic Lock (낙관적 락), Named Lock이 있다.
Pessimistic Lock (비관적 락)
데이터베이스의 table 또는 row에 락을 걸어 다른 스레드에서 접근하지 못하게 하여 동시성 이슈를 해결한다.
- 예를 들어 스레드 A, B가 동시에 1번 row에 접근하는 경우 스레드A가 1번 row에 접근하여 락을 건다면 스레드B는 1번 row에 접근하지 못한다. A의 작업이 모두 끝나고 락을 해제해야 B는 1번 row에 접근할 수 있다.
- SpringDataJpa는 @Lock 어노테이션을 제공하여, 아래와 같이 구현할 수 있다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithPessimisticLock(Long id);- 단, 비관적 락은 데이터 정합성을 보장하는 대신, 조회할 때마다 매번 락을 사용하므로 데이터베이스에 부담을 줄 수 있다.
Optimistic Lock (낙관적 락)
낙관적 락은 version 개념을 사용한다.
- 스레드 A,B가 동시에 version이 1인 데이터에 접근한 경우, 스레드A가 작업을 완료하고 데이터를 변경하면 version은 2로 변경된다. 이 때 스레드B가 가지고 있는 version에 변경이 발생했으므로 스레드B는 새로운 version의 데이터를 조회한다.
- 마찬가지로 SpringDataJpa의 @Lock 어노테이션을 이용해 구현할 수 있다.
@Lock(LockModeType.OPTIMISTIC)
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithOptimisticLock(Long id);- 단 위와 같이 메소드 작성 후, 낙관적 락 사용을 위해서는
jakarta.persistence의@Version어노테이션을 사용하여 version 필드를 객체 필드에 추가해주어야 한다.
@Version
private Long version;-
또한, 낙관적 락은 version에 변경이 감지될 경우 재요청을 하는 로직이 필요하므로, 해당 로직 또한 직접 작성해주어야 한다.
-
낙관적 락은 데이터 조회 시 Lock을 사용하지 않으므로 비관적 락보다 성능이 좋다. 그러나 version충돌이 자주 발생할 경우 오히려 비관적 락보다 성능이 떨어질 수 있다.
Named Lock
별도의 공간에 Lock을 생성하고 반환하여 동시성 문제를 해결한다. Named Lock은 트랜잭션이 끝날 때 자동으로 반환되지 않으므로, 반환하는 로직을 직접 구현해주어야 한다.
예제 (MySQL의 NamedLock 기능을 사용하기 위한 새로운 LockRepository 작성)
public interface LockRepository extends JpaRepository<Stock, Long> {
@Query(value = "select get_lock(:key, 3000)", nativeQuery = true)
void getLock(String key);
@Query(value = "select release_lock(:key)", nativeQuery = true)
void releaseLock(String key);- 따라서 getLock -> method -> releaseLock의 과정을 거치게 되는데, 이 때 @Transactional을 같이 사용한다면, 트랜잭션을 commit하기 전에 락을 반납하지 않도록 주의해야 한다.
3. Redis
Lettuce
먼저 redis 사용을 위해서는 의존성을 추가해야 한다.
build.gradle : implementation 'org.springframework.boot:spring-boot-starter-data-redis'
-
Lettuce는 spin lock 방식을 이용해 동시성 문제를 해결한다.
-
Lettuce 기능을 사용하기 위해 RedisLockRepository를 만들고, lock/unlock 메소드를 구현한다.
- lock : key를 이용해 락 획득
- unlock : 작업 완료 후 락 해제
-
while문을 사용해 락을 얻을 때까지 재요청하는 로직을 구현하고, 락을 얻었다면 실행하고자 하는 메소드를 실행한다. 그 후 작업이 완료되면 unlock 메소드를 통해 락을 해제한다.
장점
spring-data-redis기본 라이브러리를 사용하여, 별도의 라이브러리를 사용하지 않아도 된다.- 구현이 간단하다.
단점
- spin lock 방식으로 작동하여 재요청 로직을 직접 구현해야 한다.
- spin lock 방식을 사용하므로 redis에 부하를 줄 수 있다. (
Thread.sleep을 이용해 부하를 줄일 수 있다.)
Redisson
- 별도의 라이브러리가 필요하다.(https://mvnrepository.com/artifact/org.redisson/redisson-spring-boot-starter)
- Redisson은 pub-sub 기반 lock을 사용하여 동시성 문제를 해결한다.
- 스레드 A와 B는 같은 redis에 접속하여 같은 채널을 구독한다.
- 스레드 A가 작업이 끝나면 채널에 작업이 끝났다는 메시지를 보낸다.
- 대기하고 있던 스레드 B가 메시지를 확인하고 락을 획득하기 위해 요청을 보낸다.

장점
- Redisson은 채널에서 메시지를 확인하고 락 획득 요청을 하므로 redis에 부하가 적다.
단점
- Lettuce에 비해 구현이 복잡하다.
- 별도의 라이브러리를 사용해야 한다.
Lettuce vs. Redisson
락 획득 요청 재시도가 필요한 경우 : Redisson
- ex. 동시에 상품을 주문한 경우
락 획득 요청 재시도가 필요없는 경우 : Lettuce - ex. 재고가 1개인 상품을 선착순으로 동시에 주문한 경우
-> lock을 선점한 유저의 주문이 완료되면 다른 유저는 락 요청 재시도를 할 필요가 없다.
MySQL vs. Redis
MySQL
- 이미 MySQL 사용 중이라면 별도의 비용이 들지 않는다.
- 어느 정도의 트래픽까지는 문제 없이 활용 가능하다.
- Redis보다는 성능이 좋지 않다.
Redis
- 활용 중인 Redis가 없다면 별도의 구축 비용, 인프라 관리 비용이 발생한다.
- MySQL보다 성능이 좋다.
출처
https://kadosholy.tistory.com/123
https://kdhyo98.tistory.com/59
https://velog.io/@balparang/Transactional과-synchronized를-같이-사용할-때의-문제점
https://velog.io/@evan523/SpringBoot-동시성-이슈-해결방법
