
오늘은 파이썬 requests, beautifulsoup을 통해서 알라딘의 카테고리별 도서 랭킹 내용을 크롤링 하려고 한다!
왜 하필 도서 사이트를 크롤링?
크롤링을 입문함에 있어 길들이는 것이 가장 중요하기 때문에 대한민국 빅사이트 (네이버,다음,구글 등) 들의 html 태그는 체계가 잘 잡혀있어 파싱하기가 쉽다
우리는 그 편안함에 익숙해지면 안되기 때문에 , 더 어려운 실전 사이트를 크롤링하면서 크롤링에 익숙해지는 것이 중요하다!
시작하기 앞서, 알라딘의 태그를 보자면
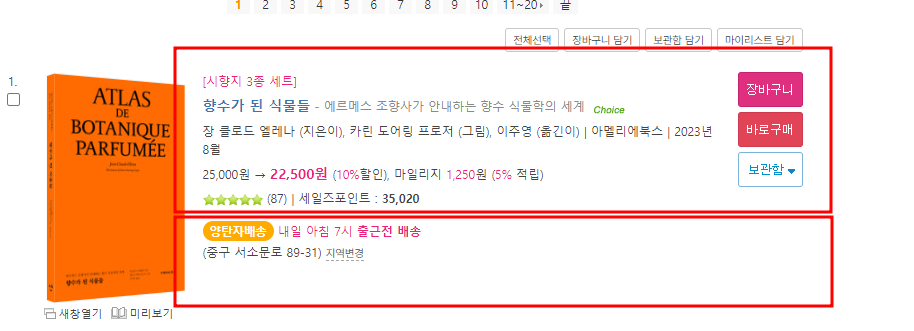
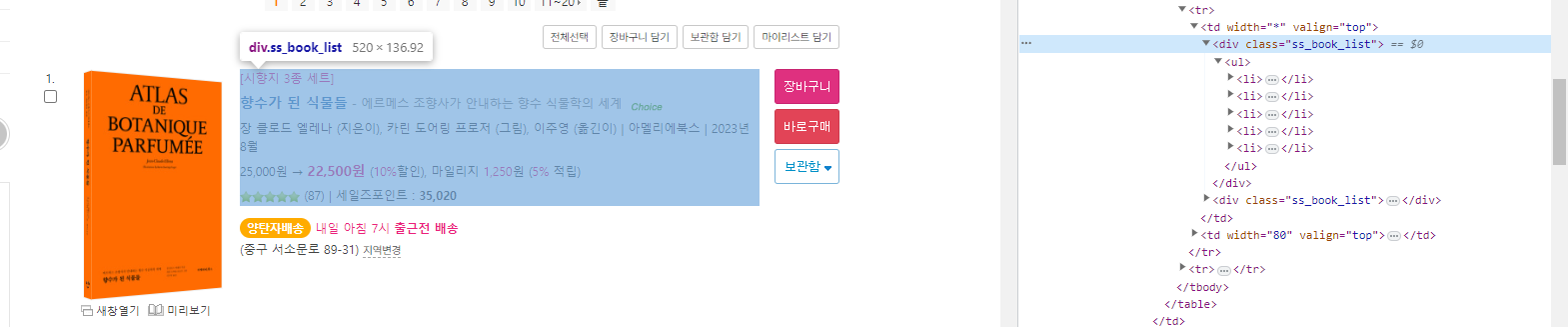

같은 div class의 이름을 가진 태그들이 2가지 섹션으로 구분되어 있다.
그러므로 우리는 CSS_SELECTOR에서 child구문을 이용을 하여 추출을 해줘야 하는데
여기서 문제점은
책을 소개하는 구문안이 담긴 li 태그가 사은품이 있는 칸이 있고 없는 칸이 있다
(예) 사은품이 있는 li가 담긴 태그

(예) 사은품이 없는 li 태그
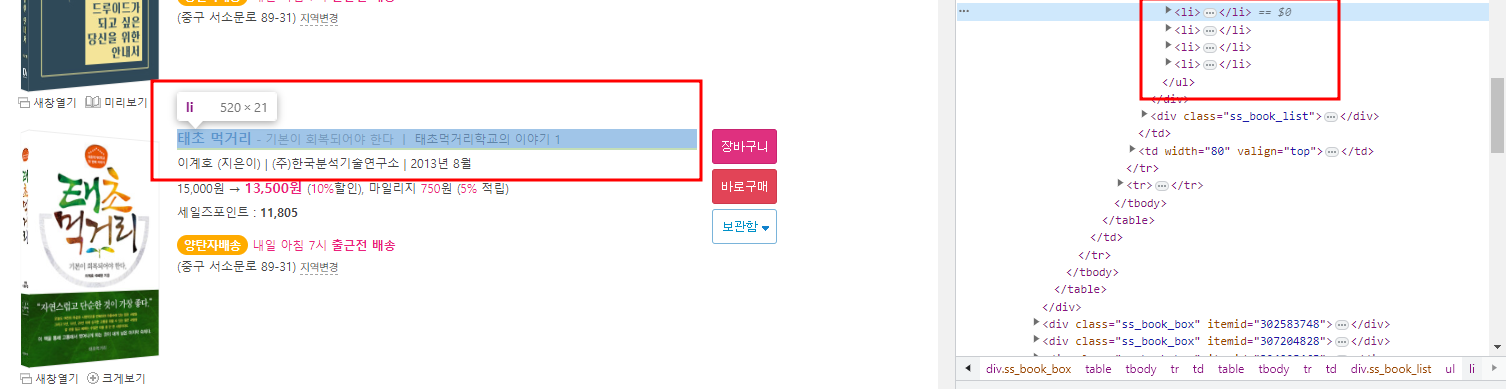
보이는가? li 개수가 차이가 있다!
우리는 for문을 이용해서 li를 반복하면서 돌건데 이렇게 li 개수가 차이가 난다면 원하는 정보를 크롤링 할 때 문제가 생긴다.
그러므로 우리는 child문을 적극 활용하여 움직일 필요가 있는거다.
코드
일단 기본 세팅을 갖춰준다
from bs4 import BeautifulSoup as bs
import lxml
import pandas as pd
import numpy as np
import requests
url = "https://www.aladin.co.kr/shop/wbrowse.aspx"
payload = dict(BrowseTarget="List",ViewRowsCount="50",ViewType="detail",PublishMonth="0",SortOrder="2",page="1",Stockstatus="1",PublishDay="84",CID="55890",SearchOption="",CustReviewRankStart="",CustReviewRankEnd="",CustReviewCountStart="",CustReviewCountEnd="",PriceFilterMin="",PriceFilterMax="")
r = requests.get(url, params=payload)
response = r.text
soup = bs(response, 'lxml')
r.urlr.url 을 통해 url이 정상적으로 연결되었는지 확인해본다
그 후
select 구문을 이용해서 대표 내용을 담을 태그 전체를 가져온다
나는 table이 담긴 id 태그를 갖고왔음
soup.select(".ss_book_list:nth-child(2n+1)")ss_book_list 클래스는 2섹션으로 나뉘기 때문에 우리가 필요한 정보는 홀수 child에 있는 정보들을 추출해낸다는 코드이다. (짝수 ss_book_list 클래스는 쓸모없는 정보가 담겨있음)
for i in soup.select(".ss_book_list:nth-child(2n+1)"):
if len(i.select("li")) >= 5:
data_dict["제목"] = i.select_one("li:nth-child(2) .bo3").text
data_dict["책 설명"] = i.select_one("li:nth-child(2) .ss_f_g2").text if i.select_one("li:nth-child(2) .ss_f_g2") is not None else "None"
data_dict["글쓴이"] = i.select_one("li:nth-child(3)").text.split("|")[0]
data_dict["출판사"] = i.select_one("li:nth-child(3)").text.split("|")[1].strip()
data_dict["출간일"] = i.select_one("li:nth-child(3)").text.split("|")[2].strip()
data_dict["정가"] = i.select_one("li:nth-child(4)").text.split("→")[0]
data_dict["할인가"] = i.select_one("li:nth-child(4)").text.split("→")[1][1:9]
data_dict["별점"] = i.select_one("li:nth-child(5) img")["src"].split("_")[1].replace("s","").replace(".gif","") if i.select_one("li:nth-child(5) img") is not None else "None"
data_dict["리뷰수"] = i.select_one("li:nth-child(5) a").text if i.select_one("li:nth-child(5) a") is not None else "None"
data_dict["세일즈포인트"] = i.select_one("li:nth-child(5) b").text.strip()여기서 li의 총 개수를 세어주는 select를 통해 li 개수가 짝수개수 (사은품이 있는 구문이 있는 태그)의 태그만 추출한다
예)
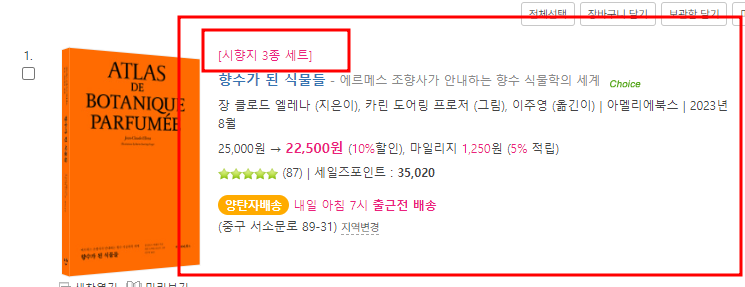
요 부분 시향지 3종세트가 있는 애들을 다 뽑는다는거임
그 다음
else :
data_dict["제목"] = i.select_one("li:nth-child(1) .bo3").text
data_dict["책 설명"] = i.select_one("li:nth-child(1) .ss_f_g2").text if i.select_one("li:nth-child(1) .ss_f_g2") is not None else "None"
data_dict["글쓴이"] = i.select_one("li:nth-child(2)").text.split("|")[0]
data_dict["출판사"] = i.select_one("li:nth-child(2)").text.split("|")[1].strip()
data_dict["출간일"] = i.select_one("li:nth-child(2)").text.split("|")[2].strip()
data_dict["정가"] = i.select_one("li:nth-child(3)").text.split("→")[0]
data_dict["할인가"] =i.select_one("li:nth-child(3)").text.split("→")[1]
data_dict["별점"] = i.select_one("li:nth-child(4) img")["src"].split("_")[1].replace("s","").replace(".gif","") if i.select_one("li:nth-child(4) img") is not None else "None"
data_dict["리뷰수"] = i.select_one("li:nth-child(4) a").text if i.select_one("li:nth-child(4) a") is not None else "None"
data_dict["세일즈포인트"] = i.select_one("li:nth-child(4) b").text.strip()이번엔 li 개수가 4개인 애들의 정보를 뽑아준다.
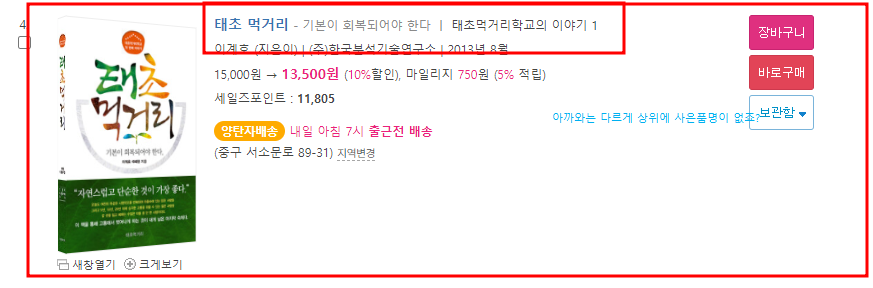
아까 li가 5개가 담긴 애들이랑은 다르게 위에 사은품이 없죠?
그렇게 추출한 내용들을 딕셔너리에 담아준 다음 데이터프레임으로 작업시키겠음ㅋ
data_list = [] # 데이터를 저장할 리스트 초기화
for i in soup.select(".ss_book_list:nth-child(2n+1)"):
data_dict = {}
if len(i.select("li")) >= 5:
data_dict["제목"] = i.select_one("li:nth-child(2) .bo3").text
data_dict["책 설명"] = i.select_one("li:nth-child(2) .ss_f_g2").text if i.select_one("li:nth-child(2) .ss_f_g2") is not None else "None"
data_dict["글쓴이"] = i.select_one("li:nth-child(3)").text.split("|")[0]
data_dict["출판사"] = i.select_one("li:nth-child(3)").text.split("|")[1].strip()
data_dict["출간일"] = i.select_one("li:nth-child(3)").text.split("|")[2].strip()
data_dict["정가"] = i.select_one("li:nth-child(4)").text.split("→")[0]
data_dict["할인가"] = i.select_one("li:nth-child(4)").text.split("→")[1][1:9]
data_dict["별점"] = i.select_one("li:nth-child(5) img")["src"].split("_")[1].replace("s","").replace(".gif","") if i.select_one("li:nth-child(5) img") is not None else "None"
data_dict["리뷰수"] = i.select_one("li:nth-child(5) a").text if i.select_one("li:nth-child(5) a") is not None else "None"
data_dict["세일즈포인트"] = i.select_one("li:nth-child(5) b").text.strip()
else:
data_dict["제목"] = i.select_one("li:nth-child(1) .bo3").text
data_dict["책 설명"] = i.select_one("li:nth-child(1) .ss_f_g2").text if i.select_one("li:nth-child(1) .ss_f_g2") is not None else "None"
data_dict["글쓴이"] = i.select_one("li:nth-child(2)").text.split("|")[0]
data_dict["출판사"] = i.select_one("li:nth-child(2)").text.split("|")[1].strip()
data_dict["출간일"] = i.select_one("li:nth-child(2)").text.split("|")[2].strip()
data_dict["정가"] = i.select_one("li:nth-child(3)").text.split("→")[0]
data_dict["할인가"] =i.select_one("li:nth-child(3)").text.split("→")[1]
data_dict["별점"] = i.select_one("li:nth-child(4) img")["src"].split("_")[1].replace("s","").replace(".gif","") if i.select_one("li:nth-child(4) img") is not None else "None"
data_dict["리뷰수"] = i.select_one("li:nth-child(4) a").text if i.select_one("li:nth-child(4) a") is not None else "None"
data_dict["세일즈포인트"] = i.select_one("li:nth-child(4) b").text.strip()
data_list.append(data_dict)추출결과
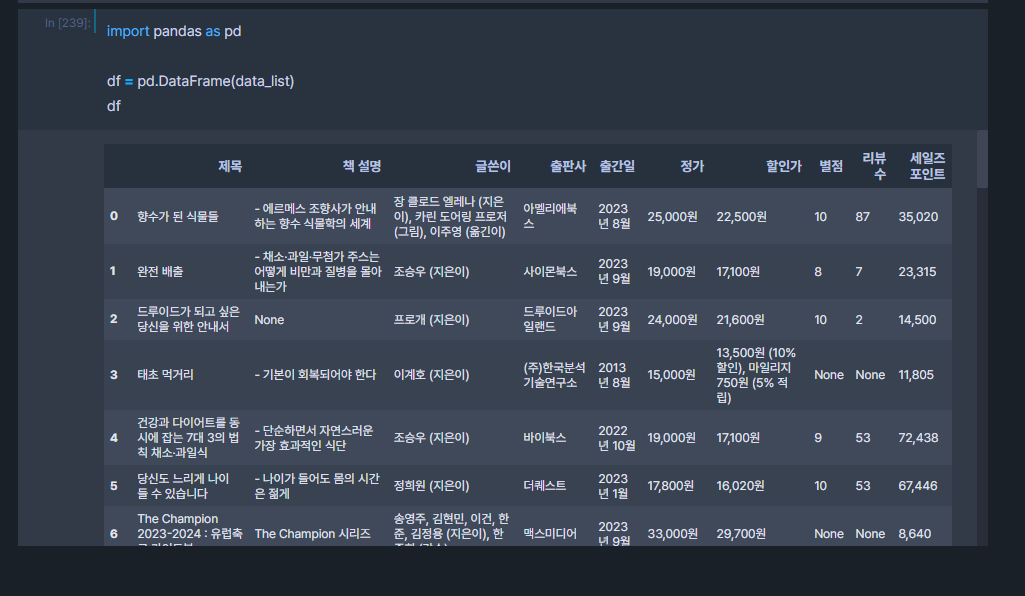
예쁘게 맞춰진 결과를 볼 수 있게되었다
주요 코드리뷰 😁
data_dict["별점"] = i.select_one("li:nth-child(4) img")["src"].split("_")[1].replace("s","").replace(".gif","") if i.select_one("li:nth-child(4) img") is not None else "None"
# 별점별점 같은 경우에는 알라딘에서 점수별로 gif 파일 뒤에 숫자명을 붙여주고, 여러개가 아닌 한 img파일로 저장시켰기 때문에 손쉽게 gif명을 슬라이싱으로 따줬다.
말로설명하면 어려우니 사진으로 설명해주면

이쪽에 보시면 별을 까만별 노란별로 따로따로 구분한게 아닌
아예 이미지 파일로 구분을 시켜놨는데 점수별로 src 이미지 파일 이름을 별점별로 각각 다르게 지어주었다.
그럼 이 패턴을 분석해봤을 때
별 반개씩마다 1점씩 분배하였으므로 저 별 5개는 s10.gif img파일로 올려두었기 때문에
조금은 하드하지만 select_one을 통해 src를 추출해주고
("li:nth-child(4) img")["src"].split("_")이후에 인덱싱을 통해 s10.gif를 추출해준후 불순문들을 replace로 빼준다
data_dict["별점"] = i.select_one("li:nth-child(4) img")["src"].split("_")[1].replace("s","").replace(".gif","")그리고 마지막으로 별점이 없을 수 있으니 예외처리를 해주면 된다.
if i.select_one("li:nth-child(4) img") is not None else "None"예외처리는 왜 하냐?
- 크롤링을 하다보면 없는 값이 있을 수 있기 때문에 (상기 내용건만 봐도 별점이 없는 도서들이 있다)
- 만약 없을 땐 뭘로 대처할건지? if문으로 걸러준다
- 유용하기도 하고 리스트 컴프리헨션과 같이 간결하게 작성하면 되는데
- 만약 간결하다고 막 쓰면 좀 주옥 같은 상황들이 발생할 수 있으니 조건이 여러개로 나뉜다 싶으면 쓰지 않는걸 추천한다
총평 🎂
다른 사이트들과 다르게 도서 사이트 (알라딘,예스24)들은 생각보다 태그가 어지럽게 구성되어 있다
특히 li 가 class가 따로 없다던지, li값 안에 값이 있을 때도 없을 때도 있었기 때문에 생각 이상으로 어려웠다이럴 때 특히 nth-child를 이용하고 if문을 혼용해서 사용하면서 문제를 해결하였는데
print로 한번씩 찍어보면서, 가져온 데이터가 짝이 맞는지 안 맞는지 확인하면서 천천히 해결했다
특히나 li 순서가 바뀌는 상황에서 문제가 많이 발생했었는데
if문과 len을 통해 응용해서 해결했다는 점에서 많은 의의를 두었다이로써 조금 더 어려운 관문을 해결할 수 있을 것 같다는 자신감이 생긴 것 같다.
