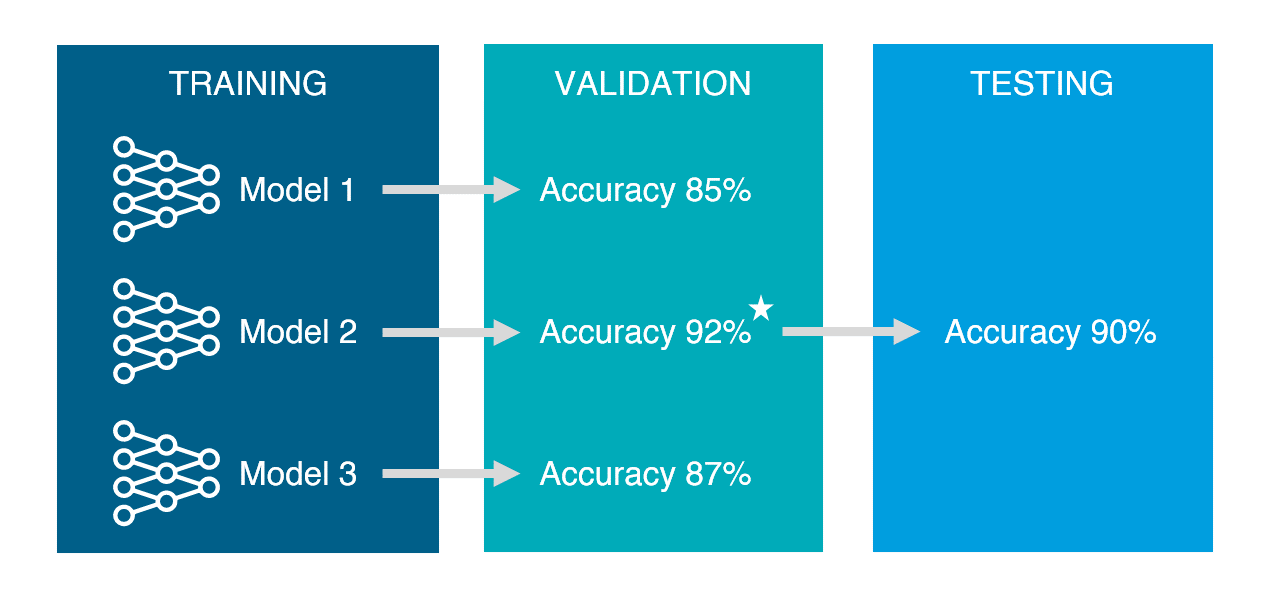
데이터 셋을 TRAIN, VALIDATION, TEST로 나누는 이유
데이터마이닝에서는 모델의 성능을 정확하게 평가하고, 개선하기 위해서 데이터를 분할해 사용한다.
- 학습용 데이터 (training data) : 모델을 학습하는데 사용된다. Training data으로 모델을 만든 뒤 동일한 데이터로 성능을 평가해보기도 하지만, 이는 cheating이 되기 때문에 유효한 평가는 아니다. 문맥상 Test data과 구분하기 위해 사용되는지, Validation과 구분하기 위해 사용되는지를 확인해야 한다.
- 검정용 데이터 (validation data) : training data으로 만들어진 모델의 성성능을 측정하기 위해 사용된다. 일반적으로 어떤 모델이 가장 데이터에 적합한지 찾아내기 위해서 다양한 파라미터(epoch, learning rate)와 모델을 사용해보게 되며, 그 중 validation set으로 가장 성능이 좋았던 모델을 선택한다. test set 직전, 모델의 최종 fine tuning의 진행과정이라고 이해하면 된다. 이 과정에서 과대추정, 과소추정을 미세하게 조정할 수 있다.
- 시험용 데이터 (test data) : validation data으로 사용할 모델이 결정 된 후, 해당 모델의 예상되는 성능을 검증 및 측정하기 위해 사용된다. 이미 validation set은 여러 모델에 반복적으로 사용되었고 그중 운 좋게 성능이 보다 더 뛰어난 것으로 측정되어 모델이 선택되었을 가능성이 있다. 때문에 이러한 오차를 줄이기 위해 한 번도 사용해본 적 없는 test set을 사용하여 최종 모델의 성능을 측정하게 된다.

Training set, Validation set, Test sets 비율
정해진 룰은 없지만 데이터를 충분히 크게 모을 수 있는 요즘에는 다음과 같은 비율을 일반적으로 사용한다.
⇒ 데이터가 충분히 많은 경우
Training set : Validation set : Test sets = 60 : 20 : 20
Training set, Validation set, Test sets 모두 target에 적합한 데이터에서 가지고 오면 된다.

❓ 데이터가 충분하지 않은 경우에는?
주어진 데이터셋의 크기가 지나치게 작다면, 이를 6:2:2의 비율로 나눈다고 하더라도 각 train, validation, test set에 할당되는 데이터의 양이 너무 적어 효과적으로 모델을 학습하고 검증하는데에 어려움을 겪을 수 있다.
🔎 해결방안
⇒ 데이터를 늘린다!
우리가 원하는 distribution에서 온 데이터셋을 a라고 부르고,
그 외의 다른 distribution 에서 오는 데이터셋을 b라고 가정해보자.
- a 와 b를 무작위로 섞은 뒤에 train, validation, test set 로 분할하기
- 장점: 전체 데이터가 같은 distribution 에서 오기 때문에, train, validation, test set 을 성질상 균일하게 나눌 수 있음.
- 단점: 실제로 모델이 사용될 distribution에서 오는 데이터가 아니기때문에, 우리가 사실상 원하는 target 에서는 멀어진 결과를 낳을 수 있고, accuracy 또한 떨어질 수 있음.
- a 를 validation 과 test set 에 사용하고, train set 에는 b를 사용하기 ✅
- 장점: validation set 을 통해 얻은 결과를 모델이 실제로 사용 되었을때 와의 성능과 비슷할 것 이라고 받아드릴 수 있음.
- 단점: 모델이 학습된 train set 과 validation set 의 성질이 다를 수 있기 때문에 모델의 성능을 높이는데 시간이 다소 오래 걸릴 수 있음. ⇒ 최종적으로 중요한 건 모델의 성능을 높이는 것이다. validation/test set 에 우리의 모델이 실제로 사용되었을 때 마주할 데이터를 더욱 잘 reflect 할 수 있는 데이터셋을 할당하는 것이 더 좋다고 판단된다.
⇒ 데이터를 늘리지 않는다!
✅ k-fold
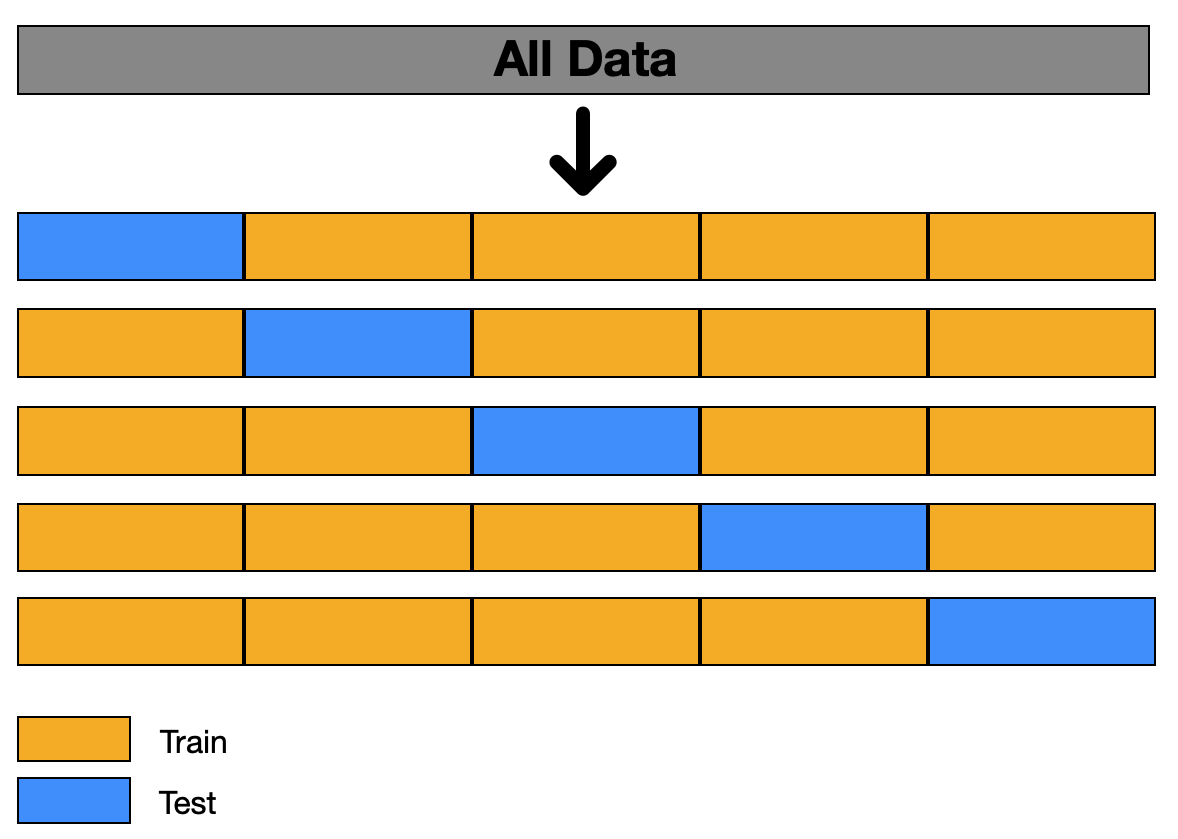
- dataset을 k-1 번 접어주면(fold) k 개의 fold로 분할
- 나누어진 dataset을 통해 모델을 학습할때에, 각 iteration마다 test set을 위와 보이는 것과 같이 중복 없이 다르게하여 모델의 training과 testing을 반복
- 각 test fold에서 나온 검증 결과를 평균내어 모델의 성능을 평가
- 장점 : k-fold 방법으로 dataset을 분할하여 사용한다면 데이터 양이 적을때 모델이 각기 다른 train과 test data를 학습하고 평가받게 되어 overfitting을 방지할 수 있을 뿐만 아니라 다양한 데이터에 대한 학습을 진행 가능.
- 단점 : iteration 횟수가 많아지기 때문에 학습에 걸리는 시간이 늘어난다
📌 이때, 예를 들어 시계열 데이터를 사용하여 모델을 학습시킨다고 한다면, 데이터를 random 하게 섞지 않고, 시간의 흐름에 따라 달라지는 데이터를 모델이 학습할 수 있도록 해 주어야 합니다.
시계열 데이터를 포함하는 다양한 데이터는 그성질에 따라 필요로 하는 dataset splitting 방법이 조금씩 달라질 수 있다. 따라서 데이터셋을 분할할때에 우리가 다루는 데이터는 어떤 성질을 가지고 있는지 고려해야 한다.

*distribution: 데이터의 출처(web page, user uploaded images, 미국에서 collect한 데이터, 한국에서 collect 한 데이터, etc.)
*target: 우리가 모델을 통하여 해결하고자 하는 문제, 또는 모델이 좋은 성능을 낼 수 있도록 하는 목표
Evaluation Metric
: 모델을 훈련시키고 validation set에 대한 결과를 평가할 때 사용되는 기준
Dataset splitting 을 하고, train set 으로 학습한 모델이 validation set 을 통해 검증을 받을때에, 우리는 evaluation metric 을 통해 모델의 성능을 평가한다.

if. 성공적으로 평가하는 Evaluation Metric를 세웠다고 할 때, evaluation metric에 따른 결과가 좋지 않다면 dataset splitting을 효과적으로 했는지 다시 한 번 확인해보는 과정이 필요하다.
실제 모델의 사용
Training set으로 모델들을 만든 뒤, validation set으로 최종 모델을 선택하게 된다. 최종 모델의 예상되는 성능을 보기 위해 test set을 사용하여 마지막으로 성능을 평가한다. 그 뒤 실제 사용하기 전에는 쪼개서 사용하였던 training set, validation set, test set 을 모두 합쳐 다시 모델을 training 하여 최종 모델을 만든다. 기존 training set만을 사용하였던 모델의 파라미터와 구조는 그대로 사용하지만, 전체 데이터를 사용하여 다시 학습시킴으로써 모델이 조금 더 튜닝되도록 만든다.
혹은 data modeling을 진행하는 동안 새로운 데이터를 계속 축적하는 방법도 있다. 최종 모델이 결정 되었을 때 새로 축적된 data를 test data로 사용하여 성능평가를 할 수도 있다.
Training sets, Validation sets, Test sets split 파이썬 코드 예시
MNIST 숫자 필기체 데이터에 대해 SVM(Support Vector Machine) 모델 수행 예제 코드.
SVM의 파라미터 중 하나인 gamma값을 바꿔 가며 어떤 gamma값을 가진 모델이 가장 성능이 좋은지 평가한다.
import matplotlib.pyplot as plt
from pandas import DataFrame
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_split
# 8x8 Images of digits
digits = datasets.load_digits()
images_and_labels = list(zip(digits.images, digits.target))
# Plot sample images
_, axes = plt.subplots(1, 4)
for ax, (image, label) in zip(axes[:], images_and_labels[:4]):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Training: %i' % label)
print('---------Sample---------')
plt.show()
# flattened to (samples, feature) matrix:
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Split data into train, valid and test subsets
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.2, random_state=1)
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.2, random_state=1)
gmm_list = [0.1, 0.01, 0.001]
score_list = []
# Validationfor gmm in gmm_list:
# Support vector classifier
classifier = svm.SVC(gamma=gmm)
classifier.fit(X_train, y_train)
# Score with validation set
predicted = classifier.predict(X_val)
score = metrics.accuracy_score(predicted, y_val)
score_list.append(score)
result = list(map(list, zip(gmm_list, score_list)))
result_df = DataFrame(result,columns=['gamma', 'score'])
print('-------Validation-------')
print(result_df)
print('')
print('----------Test----------')
# Test
best_gmm = result_df.iloc[result_df['score'].argmax()]['gamma']
classifier = svm.SVC(gamma=best_gmm)
classifier.fit(X_train, y_train)
predicted = classifier.predict(X_test)
test_score = metrics.accuracy_score(predicted, y_test)
print('Test Score :', test_score)
Referance
https://deepai.org/machine-learning-glossary-and-terms/evaluation-metrics
https://towardsdatascience.com/the-most-common-evaluation-metrics-in-nlp-ced6a763ac8b
https://medium.com/analytics-vidhya/evaluation-metrics-for-classification-models-e2f0d8009d69
