차원의 저주 (Curse of Dimensionality)
차원의 저주(Curse of Dimensionality)란, 간단히 말해, 데이터의 특징(feature)이 너무나도 많아서 알고리즘 성능 저하가 나타나는 현상을 일컫는다. 데이터를 학습시키는 근본적인 이유는 데이터 간의 경향성이나 특정 패턴을 찾아 새로운 데이터에 대해서도 발견한 패턴을 적용하여 예측하기 위함이다. 하지만 데이터 셋(data set)이 고차원 공간(high-dimensional spaces)을 가지고 있다면 데이터 간 거리가 멀어지고, 데이터의 밀도가 균일하지 않아서 비슷한 특징을 가지는 패턴이나 클러스터를 찾기 더 어려워진다.
K-최근접 이웃(KNN, K-Nearest Neighbor)을 통해, 차원의 저주를 알아보자.
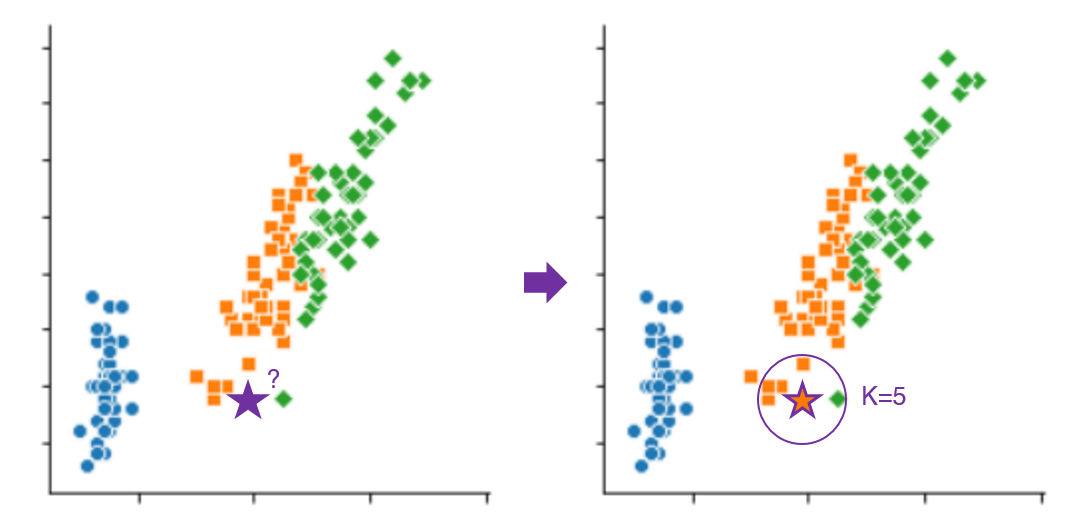
차원이 커지면 근접한 이웃의 거리가 점점 멀어지게 된다. 아래 예시와 같이 ‘Sepal Width’라는 하나의 특성만을 사용하여 분류 예측을 하고자 하면 근처 데이터들이 많아 분류하기가 쉽다. 차원을 하나 더 늘려 ‘Sepal Length’로도 분류를 하게 되면 데이터 간 거리가 점차 생기는 것을 확인할 수 있다.
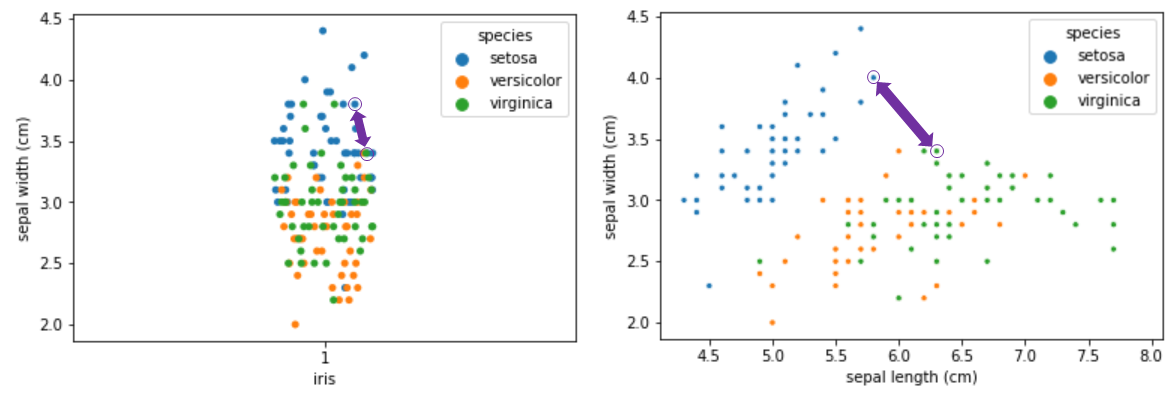
>> FiIris Data with Different Dimensionality
물론 이 예시와 같이 두 차원만으로 분류하는 것은 큰 문제가 되지 않지만 차원의 수가 커질 수록,(100차원, 1000차원) 데이터간의 거리가 훨씬 멀어지게 된다.
🔎 해결방안
- 더 많은 데이터를 확보한다. 차원이 크더라도 엄청난 양의 데이터를 모을 수 있다면 데이터의 밀도가 높아져 특징을 좀 더 잘 설명해줄 수 있게 된다.
- 차원 축소 방법을 사용
차원축소(Dimension Reduction)
가지고 있는 정보는 각각의 중요도가 다르다. 중요도 낮은 정보는 흔히 노이즈(Noise)라고 불리며, 노이즈는 데이터에서 유의미한 결과를 분석하기 위한 과정에 방해가 되는 요소이다. 데이터분석, 기계학습분야에서는 이러한 노이즈를 제거하는 것이 매우 중요한 과제 중 하나이다.
데이터 표본의 수와 변수가 매우 많으면 데이터 분석 과정에서 데이터를 파악하는 일이 매우 어렵다. 이러한 문제를 해결하기 위해 제시된 것이 차원 축소이다.
데이터의 차원이 커질수록 해당 차원을 표현하기 위해 필요한 데이터가 기하급수적으로 많아지며, 데이터 간의 거리가 멀어진다. ( 희소한 구조 → 모델의 예측 신뢰도 하락 ) 차원의 저주 문제를 해결하기 위해, 기계학습(머신러닝) 분야에서는 데이터의 특성을 잘 보존하면서 차원을 줄이는 차원축소를 진행한다.
차원축소(Dimension Reduction)는 고차원의 데이터를 저차원의 데이터로 변환하는 과정이다.
(매우 많은 피처로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성)
이를 통해 데이터의 구조를 파악하고, 시각화하거나 더 적은 차원에서 효율적인 분석 및 예측을 할 수 있다.
차원 축소는 단순히 데이터를 압축하는 것이 아닌 차원 축소를 통해 좀 더 데이터를 잘 설명할 수 있는 잠재적인 요소를 추출하는 데에 있습니다.
PCA - 주성분 분석(Principal Component Analysis)
: 여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분을 추출해 차원을 축소하는 기법
차원 축소 기법에는 PCA, Kernel PCA, LLE, LDA 등 다양한 기법이 있다.
-
피처 선택
-
피처 추출
고유벡터(Eigenvector)와 고윳값(Eigenvalue):
고유벡터(Eigenvector) : 고유벡터는 선형 변환에 의해 방향은 변하지 않고 크기만 변하는 벡터
고윳값(Eigenvalue): 고윳값은 해당 고유벡터에 대응하는 크기의 값.
선형 변환에 의해 해당 벡터의 크기가 어떻게 변하는지를 나타낸다.
Referance
https://wendys.tistory.com/169
https://modern-manual.tistory.com/entry/차원의-저주-KNN으로-쉽게-이해하기
