1. MultiModal Model
멀티모달 모델(MultiModal Model)은 텍슽, 이미지, 오디오, 비디오 등 다양한 유형의 데이터(모달리티)를 함께 고려하여 서로의 관계성을 학습하고 처리하는 인공지능입니다. 이 중에서 상대적으로 크기가 큰 모델은 대형 멀티모달 모델 즉, LMM(Large MultiModal Model)이라고 부릅니다.
멀티모달과 멀티모델
멀티모델(Multi Model)은 데이터의 종류가 1가지이면서 여러개의 모델을 거치는 방식입니다. 데이터가 여러 종류인 멀티모달 모델과는 다른점이죠.
배경
사람은 '사과'라는 개념을 이해하기 위해서 사과의 모양과 색(시각), 사과의 맛(미각), 사과의 촉감(촉각), 사과라는 글자(텍스트) 와 같이 여러 개념을 통합해서 인식합니다. 보통의 인공지능은 '사과'라는 개념을 비전모델이라면 픽셀들의 인접관계, RGB 값등을 통해 인식할 것이고 텍스트 모델이라면 자음과 모음의 조합으로 개념을 인식할 것입니다.
사람이 학습했던 방법으로 학습해야 인간의 사고를 닮은 인공지능이 만들어지게 될 확률이 높을 것입니다. 그래서 등장한 것이 멀티 모달리티(Multi Modality) 입니다. 모달리티(Modality)는 '양식', '양상' 이라는 뜻을 가지고 있습니다. 보통 어떤 형태로 나타나는 현상이나 그것을 받아들이는 방식을 말합니다. 이렇게 다양한 채널의 모달리티를 동시에 받아들여서 학습하고 사고하는 AI를 멀티모달 AI라고 말합니다. 즉, 사람이 개념을 인식하는 다양한 방식과 동일하게 학습하는 AI라고 볼 수 있습니다.
멀티모달 모델은 크게 3가지로 나눌 수 있습니다.
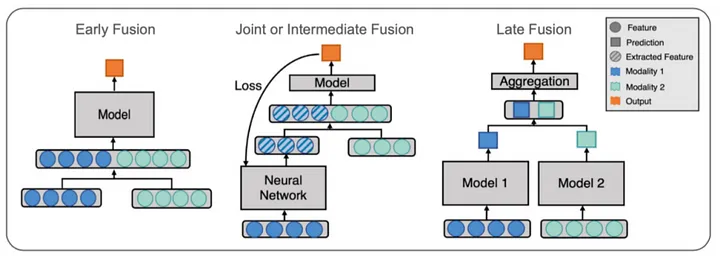
1. Early Fusion
Ealry Fusion은 종류가 다른 두 가지 데이터를 하나의 데이터로 먼저 합친 이후 모델 학습을 시키는 경우입니다. 이 때 형식이 다른 두 데이터를 합치기 위해서는 다양한 데이터 변환이 이뤄진다. 원시 데이터를 그대로 융합해도 괜찮고 전처리를 한 이후에 융합해도 상관없습니다.
2. Late Fusion
Late Fusion은 종류가 다른 두 가지 데이터를 각각 다른 모델에 학습시킨 이후 나온 결과를 융합하는 방법입니다. 기존의 앙상블 모델이 작동하는 방식과 비슷합니다.
3. Joint Fusion
Joint Fusion은 종류가 다른 두 가지 데이터를 동시에 학습시키지 않고 원하는 데이터 형식으로 모델 학습을 진행하다가 다른 데이터와 융합하는 방법입니다. 이 과정을 end-to-en learning 이라고도 합니다.
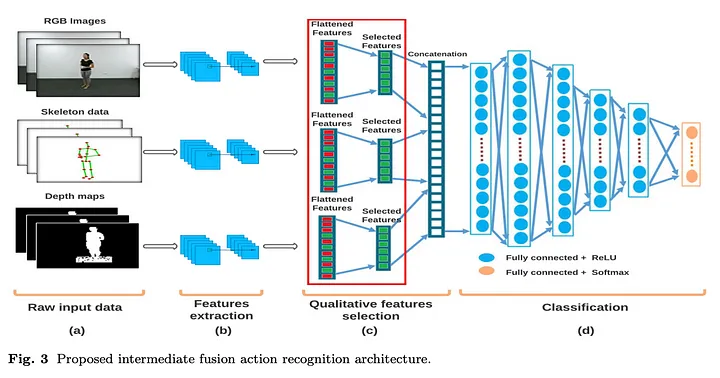
위 그림에서 볼 수 있듯이 서로 다른 3개의 데이터가 입력으로 들어가 모델을 거치면서 feature가 추출되고 3개 데이터의 특징을 하나의 데이터로 융합합니다.
