YOLOv1 논문을 바탕으로 Pytorch를 이용하여 구현했습니다. 아직 서툰부분이 많아 미흡하지만 보람찬 구현이었습니다.
구현 환경은 Colab을 사용하였습니다.
!pip install xmltodict
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.datasets import VOCDetection
from PIL import Image
import numpy as np
from tqdm.notebook import tqdm
import xmltodict
import copy
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"]데이터셋 정의
class Pascal_data(VOCDetection):
def __getitem__(self, idx):
img = Image.open(self.images[idx]).convert("RGB").resize((448,448))
transform_img = transforms.Compose([transforms.PILToTensor(),
transforms.Resize((448,448))])
transformed_img = torch.divide(transform_img(img), 255)
target = xmltodict.parse(open(self.annotations[idx]).read())
image_height = float(target['annotation']['size']['height'])
image_width = float(target['annotation']['size']['width'])
label = torch.zeros((7,7,30))
#bounding box
try:
for obj in target['annotation']['object']:
class_idx = classes.index(obj['name'].lower())
x_min = float(obj['bndbox']['xmin'])
y_min = float(obj['bndbox']['ymin'])
x_max = float(obj['bndbox']['xmax'])
y_max = float(obj['bndbox']['ymax'])
x_min = float((448.0/image_width)*x_min)
y_min = float((448.0/image_height)*y_min)
x_max = float((448.0/image_width)*x_max)
y_max = float((448.0/image_height)*y_max)
#yolo가 요구하는 데이터는 x,y,w,h
x = (x_min + x_max) / 2.0
y = (y_min + y_max) / 2.0
w = x_max - x_min
h = y_max - y_min
#x,y가 속한 영역(cell)
x_cell = int(x/64)
y_cell = int(x/64)
x_incell = float((x-(x_cell*64))/64)
y_incell = float((y-(y_cell*64))/64)
w = w/448.0
h = h/448.0
label[y_cell][x_cell][0] = x_incell
label[y_cell][x_cell][1] = y_incell
label[y_cell][x_cell][2] = w
label[y_cell][x_cell][3] = h
label[y_cell][x_cell][4] = 1.0
label[y_cell][x_cell][class_idx+10] = 1.0
except TypeError as e:
class_idx = classes.index(target['annotation']['object']['name'].lower())
x_min = float(target['annotation']['object']['bndbox']['xmin'])
y_min = float(target['annotation']['object']['bndbox']['ymin'])
x_max = float(target['annotation']['object']['bndbox']['xmax'])
y_max = float(target['annotation']['object']['bndbox']['ymax'])
x_min = float((448.0/image_width)*x_min)
y_min = float((448.0/image_height)*y_min)
x_max = float((448.0/image_width)*x_max)
y_max = float((448.0/image_height)*y_max)
#yolo가 요구하는 데이터는 x,y,w,h
x = (x_min + x_max) / 2.0
y = (y_min + y_max) / 2.0
w = x_max - x_min
h = y_max - y_min
#x,y가 속한 영역(cell)
x_cell = int(x/64)
y_cell = int(x/64)
x_incell = float((x-(x_cell*64))/64)
y_incell = float((y-(y_cell*64))/64)
w = w/448.0
h = h/448.0
label[y_cell][x_cell][0] = x_incell
label[y_cell][x_cell][1] = y_incell
label[y_cell][x_cell][2] = w
label[y_cell][x_cell][3] = h
label[y_cell][x_cell][4] = 1.0
label[y_cell][x_cell][class_idx+10] = 1.0
return transformed_img, torch.tensor(label)모델 정의
모델을 정의하는 부분은 따로 architecture config를 만들어 반복된 작업을 줄였으면 좋았겠지만 처음 구현하는 것이다보니 구현에 익숙해질겸 처음부터 끝까지 layer를 추가했습니다.
class YOLOv1(torch.nn.Module):
def __init__(self):
super(YOLOv1, self).__init__()
self.darknet = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.1),
nn.MaxPool2d(kernel_size=(2,2), stride=2),
nn.Conv2d(64,192,3, padding=1),
nn.BatchNorm2d(192),
nn.LeakyReLU(0.1),
nn.MaxPool2d((2,2), 2),
nn.Conv2d(192, 128, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.1),
nn.Conv2d(128, 256, 3,padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1),
nn.Conv2d(256,256,1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1),
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.MaxPool2d((2,2), 2),
nn.Conv2d(512, 256,1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1),
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.Conv2d(512, 256,1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1),
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.Conv2d(512, 256,1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1),
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.Conv2d(512, 256,1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.1),
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.Conv2d(512,512,1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.Conv2d(512,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1),
nn.MaxPool2d((2,2),2),
nn.Conv2d(1024,512,1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.1),
nn.Conv2d(512,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1),
nn.Conv2d(1024,512,1),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
nn.Conv2d(512,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1),
nn.Conv2d(1024,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1),
nn.Conv2d(1024,1024,3,stride=2, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1),
nn.Conv2d(1024,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1),
nn.Conv2d(1024,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.1))
self.head = nn.Sequential(
nn.Flatten(),
nn.Linear(7*7*1024, 4096),
nn.Dropout(),
nn.LeakyReLU(0.1),
nn.Linear(4096,1470))
for m in self.darknet.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, mean=0, std=0.01)
for m in self.head.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.01)
def forward(self, x):
nn.Flatten()
out = self.darknet(x)
out = self.head(out)
out = torch.reshape(out, (-1,7,7,30))
return out손실 함수
def loss_fn(y_pred, y_true):
noobj = 0.5
coord = 5
batch_loss = 0
count = len(y_true)
for i in range(0, len(y_true)):
true_unit = y_true[i].detach().requires_grad_(True)
pred_unit = y_pred[i].detach().requires_grad_(True)
true_unit = torch.reshape(true_unit, [49,30])
pred_unit = torch.reshape(pred_unit, [49,30])
loss = 0
for j in range(len(true_unit)):
bounding_box1_xywh = pred_unit[j,:4].detach().requires_grad_(True)
bounding_box1_confidence = pred_unit[j, 4].detach().requires_grad_(True)
bounding_box2_xywh = pred_unit[j, 5:9].detach().requires_grad_(True)
bounding_box2_confidence = pred_unit[j, 9].detach().requires_grad_(True)
pred_class = pred_unit[j, 10:].detach().requires_grad_(True)
true_bbox1 = true_unit[j, :4].detach().requires_grad_(True)
true_bbox1_confidence = true_unit[4].detach().requires_grad_(True)
true_bbox2 = true_unit[j, 5:9].detach().requires_grad_(True)
true_bbox2_confidence = true_unit[j, 9].detach().requires_grad_(True)
true_class = true_unit[j, 10:].detach().requires_grad_(True)
bbox1_pred_info = bounding_box1_xywh.detach().numpy()
bbox2_pred_info = bounding_box2_xywh.detach().numpy()
bbox1_true_info = true_bbox1.detach().numpy()
bbox2_true_info = true_bbox2.detach().numpy()
bbox1_pred_area = bbox1_pred_info[2] * bbox1_pred_info[3]
bbox2_pred_area = bbox2_pred_info[2] * bbox2_pred_info[3]
bbox1_true_area = bbox1_true_info[2] * bbox1_true_info[3]
bbox2_true_area = bbox2_true_info[2] * bbox2_true_info[3]
#minx, miny, maxx, maxy
bbox1_pred_mM = np.asarray([bbox1_pred_info[0]-0.5*bbox1_pred_info[2], bbox1_pred_info[1]-0.5*bbox1_pred_info[3], bbox1_pred_info[0]+0.5*bbox1_pred_info[2], bbox1_pred_info[1]+0.5*bbox1_pred_info[3]])
bbox2_pred_mM = np.asarray([bbox2_pred_info[0]-0.5*bbox2_pred_info[2], bbox2_pred_info[1]-0.5*bbox2_pred_info[3], bbox2_pred_info[0]+0.5*bbox2_pred_info[2], bbox2_pred_info[1]+0.5*bbox2_pred_info[3]])
bbox1_true_mM = np.asarray([bbox1_true_info[0]-0.5*bbox1_true_info[2], bbox1_true_info[1]-0.5*bbox1_true_info[3], bbox1_true_info[0]+0.5*bbox1_true_info[2], bbox1_true_info[1]+0.5*bbox1_true_info[3]])
bbox2_true_mM = np.asarray([bbox2_true_info[0]-0.5*bbox2_true_info[2], bbox2_true_info[1]-0.5*bbox2_true_info[3], bbox2_true_info[0]+0.5*bbox2_true_info[2], bbox2_true_info[1]+0.5*bbox2_true_info[3]])
#IOU 계산
def cal_IOU(pred_np, true_np):
if (np.all(pred_np[0]== 0) == True and np.all(pred_np[1]==0)==True and np.all(pred_np[2]==0)==True and np.all(pred_np[3]==0)==True) or ((np.all(true_np[0] == 0) == True) and np.all(true_np[1]==0)==True and np.all(true_np[2]==0)==True and np.all(true_np[3]==0)==True):
box_iou = 0
else:
union_min_x = min(pred_np[0], true_np[0])
union_min_y = min(pred_np[1], true_np[1])
union_max_x = max(pred_np[2], true_np[2])
union_max_y = max(pred_np[3], true_np[3])
union_box = [union_min_x, union_min_y, union_max_x, union_max_y]
intersection_min_x = max(pred_np[0], true_np[0])
intersection_min_y = min(pred_np[1], true_np[1])
intersection_max_x = min(pred_np[2], true_np[2])
intersection_max_y = max(pred_np[3], true_np[3])
intersection_box = [intersection_min_x, intersection_min_y, intersection_max_x, intersection_max_y]
union_area = abs(union_max_x - union_min_x) * abs(union_max_y - union_min_y)
intersection_area = abs(intersection_max_x - intersection_min_x) * abs(intersection_max_y - intersection_min_y)
box_iou = intersection_area / union_area
return box_iou
IOU_bbox1_1 = cal_IOU(bbox1_pred_mM, bbox1_true_mM)
IOU_bbox1_2 = cal_IOU(bbox1_pred_mM, bbox2_true_mM)
IOU_bbox2_1 = cal_IOU(bbox2_pred_mM, bbox1_true_mM)
IOU_bbox2_2 = cal_IOU(bbox2_pred_mM, bbox2_true_mM)
if IOU_bbox1_1 > IOU_bbox1_2:
responsible_pred_bbox1 = {"name":"IOU_bbox1_1", "iou_value":IOU_bbox1_1, "pred_coord":bounding_box1_xywh, "pred_confidence":bounding_box1_confidence, "true_coord":true_bbox1, "true_confidence":true_bbox1_confidence}
unresponsible_pred_bbox1 = {"name":"IOU_bbox1_2", "iou_value":IOU_bbox1_2, "pred_coord":bounding_box1_xywh, "pred_confidence":bounding_box1_confidence, "true_coord":true_bbox2, "true_confidence":true_bbox2_confidence}
else:
responsible_pred_bbox1 = {"name":"IOU_bbox1_2", "iou_value":IOU_bbox1_2, "pred_coord":bounding_box1_xywh, "pred_confidence":bounding_box1_confidence, "true_coord":true_bbox2, "true_confidence":true_bbox2_confidence}
unresponsible_pred_bbox1 = {"name":"IOU_bbox1_1", "iou_value":IOU_bbox1_1, "pred_coord":bounding_box1_xywh, "pred_confidence":bounding_box1_confidence, "true_coord":true_bbox1, "true_confidence":true_bbox1_confidence}
responsible_pred_bbox1['unresponsible'] = unresponsible_pred_bbox1
if IOU_bbox2_1 > IOU_bbox2_2:
responsible_pred_bbox2 = {"name":"IOU_bbox2_1", "iou_value":IOU_bbox2_1, "pred_coord":bounding_box2_xywh, "pred_confidence":bounding_box2_confidence, "true_coord":true_bbox1, "true_confidence":true_bbox1_confidence}
unresponsible_pred_bbox2 = {"name":"IOU_bbox2_2", "iou_value":IOU_bbox2_2, "pred_coord":bounding_box2_xywh, "pred_confidence":bounding_box2_confidence, "true_coord":true_bbox2, "true_confidence":true_bbox2_confidence}
else:
responsible_pred_bbox2 = {"name":"IOU_bbox2_2:", "iou_value":IOU_bbox2_2, "pred_coord":bounding_box2_xywh, "pred_confidence":bounding_box2_confidence, "true_coord":true_bbox2, "true_confidence":true_bbox2_confidence}
unresponsible_pred_bbox2 = {"name":"IOU_bbox2_1", "iou_value":IOU_bbox2_1, "pred_coord":bounding_box2_xywh, "pred_confidence":bounding_box2_confidence, "true_coord":true_bbox1, "true_confidence":true_bbox1_confidence}
responsible_pred_bbox2['unresponsible'] = unresponsible_pred_bbox2
if responsible_pred_bbox1['iou_value'] > responsible_pred_bbox2['iou_value']:
high_iou_dict = copy.deepcopy(responsible_pred_bbox1)
low_iou_dict = copy.deepcopy(responsible_pred_bbox2)
else:
high_iou_dict = copy.deepcopy(responsible_pred_bbox2)
low_iou_dict = copy.deepcopy(responsible_pred_bbox1)
#Localization
hx_loss = torch.pow(torch.subtract(high_iou_dict['true_coord'][0], high_iou_dict['pred_coord'][0]), 2)
hy_loss = torch.pow(torch.subtract(high_iou_dict['true_coord'][1], high_iou_dict['pred_coord'][1]), 2)
hw_loss = torch.pow(torch.subtract(torch.sqrt(high_iou_dict['true_coord'][2]), torch.sqrt(high_iou_dict['pred_coord'][2])), 2)
hh_loss = torch.pow(torch.subtract(torch.sqrt(high_iou_dict['true_coord'][3]), torch.sqrt(high_iou_dict['pred_coord'][3])), 2)
hloss_xy = torch.add(hx_loss, hy_loss)
hloss_wh = torch.add(hw_loss, hh_loss)
hlocal_loss = torch.add(hloss_xy, hloss_wh)
if torch.isnan(hlocal_loss).detach().any() == True:
hlocal_loss = torch.zeros_like(hlocal_loss)
htrue_object = torch.ones_like(high_iou_dict['true_confidence'])
if np.all(high_iou_dict['true_coord'][0].detach().numpy() == 0) == True and np.all(high_iou_dict['true_coord'][1].detach().numpy() == 0) == True and np.all(high_iou_dict['true_coord'][2].detach().numpy()==0) == True and np.all(high_iou_dict['true_coord'][3].detach().numpy()==0) == True:
htrue_object = torch.zeros_like(high_iou_dict['true_confidence'])
hweighted_local_loss = torch.multiply(torch.multiply(hlocal_loss, coord), htrue_object)
lx_loss = torch.pow(torch.subtract(low_iou_dict['true_coord'][0], low_iou_dict['pred_coord'][0]), 2)
ly_loss = torch.pow(torch.subtract(low_iou_dict['true_coord'][1], low_iou_dict['pred_coord'][1]), 2)
lw_loss = torch.pow(torch.subtract(torch.sqrt(low_iou_dict['true_coord'][2]), torch.sqrt(low_iou_dict['pred_coord'][2])), 2)
lh_loss = torch.pow(torch.subtract(torch.sqrt(low_iou_dict['true_coord'][3]), torch.sqrt(low_iou_dict['pred_coord'][3])), 2)
lloss_xy = torch.add(lx_loss, ly_loss)
lloss_wh = torch.add(lw_loss, lh_loss)
llocal_loss = torch.add(lloss_xy, lloss_wh)
if torch.isnan(llocal_loss).detach().any() == True:
llocal_loss = torch.zeros_like(llocal_loss)
ltrue_object = torch.ones_like(low_iou_dict['true_confidence'])
if np.all(low_iou_dict['true_coord'][0].detach().numpy() == 0) == True and np.all(low_iou_dict['true_coord'][1].detach().numpy() == 0) == True and np.all(low_iou_dict['true_coord'][2].detach().numpy()==0) == True and np.all(low_iou_dict['true_coord'][3].detach().numpy()==0) == True:
ltrue_object = torch.zeros_like(low_iou_dict['true_confidence'])
lweighted_local_loss = torch.multiply(torch.multiply(llocal_loss, coord), ltrue_object)
#Confidence
hobj_confidence = torch.pow(torch.subtract(high_iou_dict['true_confidence'], high_iou_dict['pred_confidence']), 2)
hobj_confidence = torch.multiply(hobj_confidence, htrue_object)
hnoobj_confidence = torch.pow(torch.subtract(high_iou_dict['unresponsible']['true_confidence'], high_iou_dict['unresponsible']['pred_confidence']), 2)
hnoobj_confidence = torch.multiply(hnoobj_confidence, noobj)
lobj_confidence = torch.pow(torch.subtract(low_iou_dict['true_confidence'], low_iou_dict['pred_confidence']), 2)
lobj_confidence = torch.multiply(lobj_confidence, ltrue_object)
lnoobj_confidence = torch.pow(torch.subtract(low_iou_dict['unresponsible']['true_confidence'], low_iou_dict['unresponsible']['pred_confidence']), 2)
lnoobj_confidence = torch.multiply(lnoobj_confidence, noobj)
hconfidence_score_sum = torch.add(hobj_confidence, hnoobj_confidence)
lconfidence_score_sum = torch.add(lobj_confidence, lnoobj_confidence)
#Classification
class_loss = torch.pow(torch.subtract(true_class, pred_class), 2)
class_loss = torch.sum(class_loss)
hclass_loss = torch.multiply(class_loss, htrue_object)
lclass_loss = torch.multiply(class_loss, ltrue_object)
loss1 = torch.add(torch.add(hweighted_local_loss, hconfidence_score_sum), hclass_loss)
loss2 = torch.add(torch.add(lweighted_local_loss, lconfidence_score_sum), lclass_loss)
added_loss = torch.add(loss1, loss2)
real_loss = added_loss[0]
if loss == 0:
loss = real_loss
else:
loss = loss + real_loss
if batch_loss == 0:
batch_loss = real_loss
else:
batch_loss = batch_loss + real_loss
batch_loss = batch_loss / count
return batch_loss
훈련 함수
학습률을 조정하는 부분이 추가되면 좋겠다는 생각이 듭니다.
def train(model, loss, optimizer, epochs, data_loader):
for epoch in tqdm(range(epochs), desc='train', mininterval=0.01):
count=0
for inputs, labels in data_loader:
count += 1
optimizer.zero_grad()
outputs = model(inputs)
loss_fn = loss(outputs, labels)
loss_fn.requires_grad_(True)
loss_fn.backward()
optimizer.step()
if count % 100 == 0:
print("repeat ", count, "/", len(data_loader), "\n"
"loss: ", loss_fn.item())
print('Epoch:', epoch+1, '|', 'loss:', loss_fn.item())메인 함수
def main():
#device = 'cuda' if torch.cuda.is_available() else 'cpu'
batch_size = 32
epochs = 100
learning_rate = 1e-03
print("Data Downloading...")
train_data = Pascal_data(root='voc_data/', year='2012', image_set='train', download=True)
test_data = Pascal_data(root='voc_data/', year='2012', image_set='val', download=True)
DataLoader = torch.utils.data.DataLoader(dataset=train_data,
batch_size=batch_size,
shuffle=True,
drop_last=True)
yolov1 = YOLOv1()
optimizer = torch.optim.Adam(yolov1.parameters(), lr=learning_rate)
train_result = train(yolov1, loss_fn, optimizer, epochs, DataLoader)Conclusion
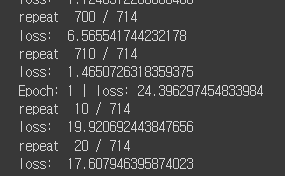
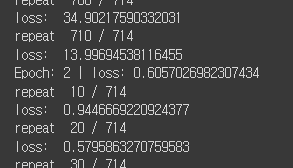
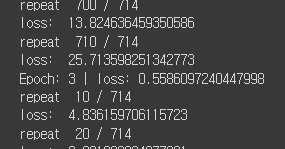
테스트 결과는
1epoch : 24.396
2epoch : 0.6057
3epoch : 0.5586
으로 epoch 마다 loss 가 잘 줄어들고 있음을 확인했습니다.

동물을 좋아하는 개발자(희망)의 저장소