미니배치
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
위 데이터의 개수는 5개입니다.
그러나 현업에서 다루게 되는 많은 양의 데이터에 비하면 굉장히 적은 양입니다.
예를 들어, 수 십만개 이상의 전체 데이터에 대해 계산을 하게 된다면 매우 많은 시간과 메모리가 필요합니다.
그래서 전체 데이터를 작은 단위로 나누어 그 단위로 학습하는 개념이 나오게 되었습니다. 이 단위를 미니 배치라고 합니다.
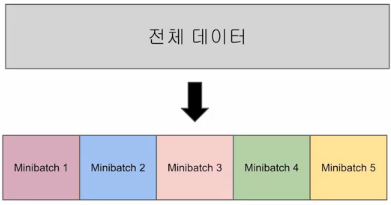
미니 배치 학습에서는 미니 배치의 개수만큼 최적화를 수행해야 전체 데이터가 한 번 전부 사용되어 1Epoch가 됩니다. 이 미니 배치의 개수는 미니 배치의 크기를 얼마로 하느냐에 따라 달라지는데 미니 배치의 크기를 배치 사이즈라고 합니다.
배치 사이즈는 보통 2의 제곱수를 사용합니다. 그 이유는 CPU와 GPU의 메모리가 2의 배수이므로 배치 사이즈가 2의 제곱수일 경우에 데이터 송수신의 효율을 높일 수 있습니다.
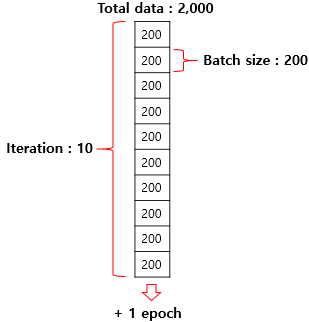
Iteration은 한 번의 Epoch 내에서 이뤄지는 매개변수인 가중치 W와 편향 b의 업데이트 횟수입니다.
Data Load
파이토치에서는 데이터를 효율적으로 다룰 수 있도록 데이터셋(Dataset)과 데이터로더(DataLoader)를 제공합니다. 이를 사용하면 미니 배치 학습, 데이터 셔플(shuffle), 병렬 처리까지 간단하게 수행할 수 있습니다. 기본적인 사용 방법은 Dataset을 정의하고, 이를 DataLoader에 전달하는 것입니다.
Custom Dataset
Dataset을 상속받아 직접 커스텀 데이터셋을 만드는 경우도 있습니다.
커스텀 데이터셋을 만들 때 가장 기본적인 뼈대는 아래와 같습니다.
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
def __len__(self):
def __getitem__(self, idx):

동물을 좋아하는 개발자(희망)의 저장소