1. 단순 선형 회귀
단순 선형 회귀의 데이터 구조는 다음과 같습니다.
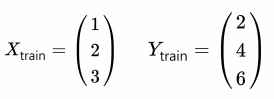
데이터 정의
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])가설, 손실함수, 옵티마이저 정의
선형 회귀의 가설은 y = Wx + b 직선의 방정식과 같습니다.
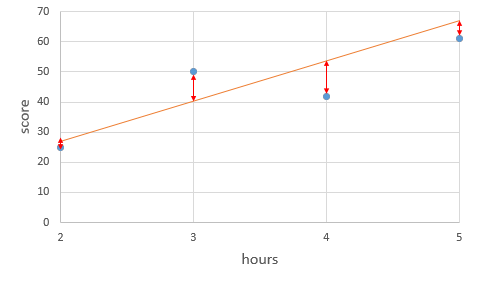
위 그림은 임의로 그려진 주황색 선에 대해 각 실제값과 직선의 예측값에 대한 값의 차이를 화살표로 표현된 것입니다. 빨간색 화살표는 곧 실제값과 예측값 사이의 오차입니다.
주황색 직선의 식은 y = 13x + 1 이며, 각 오차는 다음과 같습니다.
| x | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| 실제값 | 25 | 50 | 42 | 61 |
| 예측값 | 27 | 40 | 53 | 66 |
| 오차 | -2 | 10 | -9 | -5 |
회귀 문제에 사용되는 손실함수 중에서도 MSELoss를 사용하겠습니다.
MSELoss를 정의하면 다음과 같습니다.
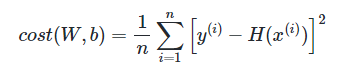
옵티마이저는 가장 기본적인 함수 중 하나인 경사하강법을 사용하겠습니다.
구현
구현은 nn.Module을 사용해서 하는 방법과 클래스를 만들어서 만드는 방법을 보겠습니다. 대부분 클래스를 정의해서 구현하는 방법을 사용합니다.
nn.Module을 사용해서 선형 회귀 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
#모델 선언 및 초기화. 단순 선형 회귀이므로 input_dim=1, output_dim=1
model = nn.Linear(1,1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1001):
prediction = model(x_train)
loss = F.mse_loss(prediction, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()Pytorch를 이용해서 클래스로 선형 회귀 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
return self.linear(x)
model = LinearModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1001):
prediction = model(x_train)
loss = F.mse_loss(prediction, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()2. 다중 선형 회귀
앞서 배운 단순 선형 회귀와 다른 점은 독립 변수 X의 개수가 1개가 아닌 여러개라는 점입니다. 구현을 하기 전에 짚고 갈 부분이 있습니다.
데이터 정의를 할 때 데이터가 많다면 앞에서 쓰인 데이터 정의 방법을 사용하기 어려운 부분이 있습니다.
각 독립 변수마다 정의를 해준다면
x1_train = torch.FloatTensor([[73], [93], [89], [96], [73]])
x2_train = torch.FloatTensor([[80], [88], [91], [98], [66]])
x3_train = torch.FloatTensor([[75], [93], [90], [100], [70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 가중치 w와 편향 b 초기화
w1 = torch.zeros(1, requires_grad=True)
w2 = torch.zeros(1, requires_grad=True)
w3 = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)이런 식으로 가중치까지 여러 개를 선언해줘야 합니다.
이를 개선하기 위해서는 벡터의 내적(행렬 곱셈)을 사용합니다. 벡터의 내적은 행렬의 곱셈 과정에서 이뤄지는 벡터 연산입니다.
편의 상 b는 보지않고 x와 w만 보겠습니다.
y = w1x1 + w2x2 + w3x3
이 식은 두 벡터의 내적으로 다시 표현할 수 있습니다.
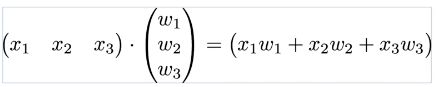
두 벡터를 각각 X와 W로 표현한다면 가설을 y = XW 로 표현할 수 있습니다.
이렇게 독립 변수 x의 개수가 3개였음에도 X와 W라는 두 개의 변수로 표현이 되었습니다.
여기에 편향b를 다시 붙여주면 y= XW + B 가 됩니다.
구현
nn.Module을 사용해서 다중 선형 회귀 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 데이터
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
model = nn.Linear(3,1)
optimizer = optim.SGD(model.parameters(), lr=1e-5)
for epoch in range(1001):
prediction = model(x_train)
loss = F.mse_loss(prediction, y_train)
optimizer.zero.grad()
loss.backward()
optimizer.step()Pytorch를 이용해서 클래스로 다중 선형 회귀 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 데이터
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
class MulLinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3,1)
def forward(self, x):
return self.linear(x)
model = MulLinearModel()
optimizer = optim.SGD(model.parameters(), lr=1e-5)
for epoch in range(1001):
prediction = model(x_train)
loss = F.mse_loss(prediction, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()