
EDA
EDA란?
데이터를 이해하기 위한 노력이다.
이 과정을 통해 데이터를 이해하고, Modeling 방법 및 Data Pre-processing(전처리)에 대한 계획을 짤 수 있게 해준다.
EDA에서 해야할 것
데이터에 대한 의문점을 해결하는 방법으로 수행한다.
EDA는 한번 수행하고 끝나는 것이 아닌, Modeling 도중에도 아이디어가 떠오르면 해당 아이디어를 활용하기 위해 EDA를 계속해서 수행해야 할 필요가 있다.
Pre-processing
데이터 전처리 과정을 의미한다.
아래는 Image Data에 대해 수행 할 수 있는 전처리 과정 중 일부를 가져왔다.
Bounding Box

원래 Data에서 원하는 영역만 잘라 해당 Data만 활용하는 방식이다.
만약 내가 Dog(개)에 대한 학습을 진행하려고 한다면, 노란색 Bounding Box 밖에 존재하는 Data는 단순히 Noise이자 학습을 방해하는 요소이다. 따라서, 노란색 Bounding Box 안에 존재하는 Dog의 이미지만 학습에 활용하도록 해당 영역만 잘라 새로운 Data를 형성하는 과정을 의미한다.
Resize
계산 효율을 위해 적당한 크기로 사이즈 변경하는 방법이다.
특정 Model들은 최적화를 위한 이미지 사이즈를 연구를 통해 명시해 놓은 Case도 있으므로, 잘 알아본 이후 Resize를 수행하자

- (ex) EfficientNet은 각 Model마다 원하는 Input Shape이 다름
- 출처 : https://discuss.pytorch.org/t/input-size-for-efficientnet-versions-from-torchvision-models/140525
Generalization
-
https://velog.io/@idj7183/Deep-Learning-%EC%9A%A9%EC%96%B4-j9rwwhfy
-
Cross Validation
-
Data Augmentation
- 목적 및 데이터의 형태에 따라 어떤 Augmentation을 활용할지 결정해야 함
- (ex) 9를 상하로 뒤집으면 d처럼 보일 수도 있다. 또한, 180도 회전시키면 6으로 볼 수도 있으므로 주의해야 한다.
-
Augmentation 라이브러리
- torchivision.transforms : RandomCrop, Flip 등
- Albumnetations : Pytorch가 아닌 다른 라이브러리
- 빠르고 기법이 다양함
주의 해야 할 점
위에서 설명한 방법이 무조건 좋은 결과를 가져다주지는 않는다.
실제로 Data Augmentation을 수행한 이후 Accuracy가 더욱 감소하는 Case도 많다.
Probelm을 깊이 관찰하고 EDA를 잘 수행하여, 활용할 수 있을 것 같은 기법을 체크하고 실험으로 가정이 맞았다는 것을 증명해야 한다.
Dataset과 DataLoader
https://velog.io/@idj7183/PyTorch2-DataSet-DataLoader-Transform
- Dataset : Vanilla Data를 원하는 형태로 반환
DataLoader : Dataset을 효율적으로 활용하기 위한 클래스
Model
Pytorch
https://velog.io/@idj7183/PyTorch2-DataSet-DataLoader-Transform
Model 형성
https://velog.io/@idj7183/Model-%EC%83%9D%EC%84%B1-%EB%B0%8F-%EC%A0%80%EC%9E%A5
Parameter 출력
- a.state_dict() : Key값과 Parameter Tensor가 동시에 Dict 형식으로 출력됨
- a.parameters() : Parameter만 출력됨
- data, grad, requires_grad 등의 변수를 가지고 있음
- requires_grad : True일 경우 학습이 진행되는 Parameter임
- grad : forward() 과정에서 얻은 Loss(Gradient)를 저장하는 공간
nn.Module Family
Module을 상속받은 모든 클래스의 공통된 특징이다.
모든 nn.Module은 Child Modules를 가질 수 있는데, 이 때 내 모델을 정의하는 순간 연결된 모든 Child Module들도 확인할 수 있다.
모든 Module은 forward() 함수를 가지며, 따라서 Sub Module로 설정되어 있더라도 forward() 과정이 수행된다. 순전파 과정이 진행되기 때문에, 역전파 과정도 수행할 수 있다.
Pretrained Model
좋은 품질, 대용량 데이터로 미리 학습한 모델로써, 내 목적에 맞게 Pretrained Model을 다듬어 활용하는 것이 Accuracy가 높고 Epoch도 획기적으로 줄일 수 있다.
모델 일반화를 위해 수많은 이미지를 학습시키는 것은 어렵고 비효율적이기 때문에 Pretrained Model을 활용한다.
CV 같은 경우, ImageNet이 형성됨으로써 데이터가 많아졌고, Pretrained Model이 좋아지며 CV의 큰 발전을 가져다 주었다.
torchivision.models혹은timm을 통해 Pretrained Model을 얻어올 수 있음
Transfer Learning
Pretrained Model을 가지고 와 내가 원하는 Output을 내도록 모델을 변형시키는 것이다.
예를 들어 CNN Backbone에 대해 Transfer Learning을 수행하도록 모델을 변경해보자
- CNN Base 모델 구조 : Input + CNN Backbone(Pretrained Model) + Classifier = Output
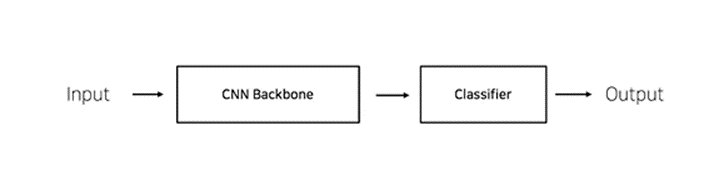
- fc : Fully Connected Layer. Classifier라고도 하며, 내가 원하는 형태로 Output을 만들어주는 Layer
- Fine-tuning : https://velog.io/@idj7183/BERT
Train
Loss Function
Output과 Target을 활용하여 계산한 오차 Function이다.
Loss도 nn.Module Family으로, forward()를 가지고 있으며, 내가 Loss Function을 만들 수도 있다.
Loss Function으로부터 Error Backpropagation이 수행된다.
Output과 Target을 통해 Loss를 구하는 것이 Loss Function이다. 이를 생각해보면, Model에서 Output이 나오는 과정에 Loss를 구하는 과정이 추가된 하나의 forward()라고 수행할 수도 있다.
즉, Error Backpropagation을 수행하면 Loss를 구하는 과정에서 필수적인 Model의 예측치를 구하는 과정도 Backpropagation이 수행되기 때문에 Model에 대한 학습도 진행이 되는것이다.
Loss도 nn.Module Family이기 때문에 활용 가능한 방법이다.
여러가지 Loss Function
Log loss(logistic loss, cross-entropy loss)
- neural network를 평가하는 방법
- 음의 로그 함수를 활용
- log loss 값이 작을수록 좋은 모델
- 다중 클래스 분류 모델의 평가 방법으로 많이 활용됨
- log loss =
- n : 문제 개수
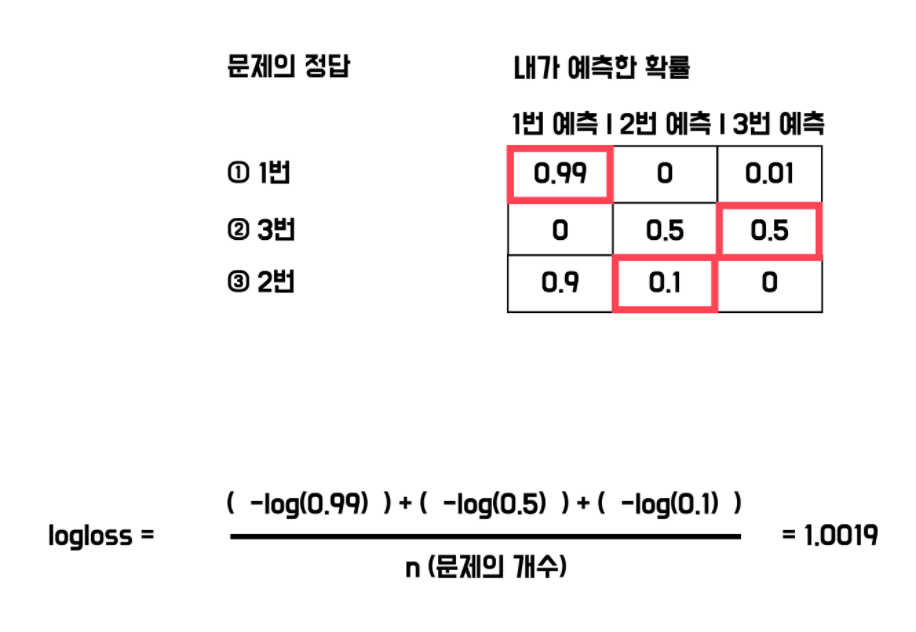
- n : 문제 개수
- Focal Loss
- Class Imbalance 문제가 있는 경우 활용되는 Loss Function
- 맞춘 확률이 높은 Class는 작은 Loss를, 맞춘 확률이 낮은 Class는 높은 Loss를 가지도록 만든 Loss function
- Label Smoothing Loss
- Class Target Label을 One-hot보다는 조금 soft하게 표현하여 일반화 성능을 높이기 위해 활용하는 방법
Optimizer
어떤 방향으로 얼마나 움직여 Model을 학습할지 결정해주는 도구이다.
Metric
모델의 평가 지표로써, Task별 활용할만한 Metric이 다양하다.
Classification
Accuracy, F1-score, precision, recall, AUC-ROC
Regression
MAE, MSE
Ranking
MRR, NDCG, MAP
Probelm 별로 Metric을 적절히 선택해야 한다.
예를 들어, Accuracy는 Class 별로 밸런스가 적절히 분포되어 있을 때 활용해야 하며, F1-score : Class 별로 밸런스가 좋지 않아 클래스별로 성능을 잘 낼 수 있을지 확인하고 싶을 때 활용해야 한다.
Train
https://velog.io/@idj7183/Model-%EC%83%9D%EC%84%B1-%EB%B0%8F-%EC%A0%80%EC%9E%A5
- CheckPoint는
torch.save와state_dict를 활용하여 직접 저장 조건을 지정해 준 이후, Model을 저장하는 코드를 구현하면 된다.
Ensemble
Ensemble이란?
여러 가지 모델로 여러 결과가 도출될 것이며, 이런 결과들을 버리지 않고 결합시켜 좋은 결과를 도출하기 위한 대표적 방법이다.
효과는 확실하지만, 학습 및 추론 시간이 몇 배로 소요된다.
Model을 N개 만들거나, 데이터를 N개로 증폭시켜 Train 해야 하기 때문에 Inference도 N배의 시간만큼 필요한 것이다.
Ensemble 기법들
Boosting
계속 Model이 나아지는 방향으로 학습을 진행하는 것이다.
Model Averaging(Voting)
서로 다른 Model을 활용하여 여러 개의 출력을 내고, 이 출력들을 모두 활용하여 최종 출력을 내는 것이다.
방법으로는 Hard Voting과 Soft Voting이 존재한다.
-
Hard Voting : 결과 Class를 보고, Class 중 가장 많이 예측한 Class로 최종 결과를 도출하는 기법이다.
-
Soft Voting : 결과 Class를 반환하기 직전, Model은 해당 Data가 각 Class일 확률을 수치로 구할 것이다. 이 예측 수치들의 각 Class별 확률을 구하여 최종적으로 가장 높은 확률을 가진 Class로 결과를 도출하는 기법이다.
일반적으로 Hard Voting보다 Soft Voting의 효과가 좋다고 알려져 있다.
(ex) 2개의 클래스로 예측할 때, Model A는 [0.4, 0.6]으로, Model B는 [0.9, 0.1], Model C는 [0.4, 0.6]으로 예측했다고 가정하자. Hard Voting일 경우, A와 C가 2로 예측했으므로 2가 최종 반환될 것이다. 하지만, Soft Voting으로 예측하면 [0.56666, 0.0.433333]으로, 1을 최종적으로 예측할 것이다.
TTA(Test Time Augmentation)
테스트 할 때 Augmentation을 수행하는 것을 의미한다.
Test에 Augmentation을 여러 가지로 수행한 이후 각 Augmentation마다 추론 값을 저장한다. 이렇게 나온 모든 추론 값에 대해 앙상블을 수행하는 기법이다.
(ex) 1개 Model이 A를 평가하고 싶다고 가정하자. A를 A', A''으로 Data Augmentation을 수행했다. A는 1, A'은 0.5, A''은 0.7의 확률로 Class 1이라고 유추했을 시, A는 약 0.7의 확률로 Class 1이라고 예측하는 것(Soft Voting 활용)이다.
기타
Training Visualization 도구
- Tensorboard와 Wandb 존재
실행 환경
- Jupyter Notebook
- 매 Cell마다 실행시켜 단계별 수행이 가능
- Notebook이 꺼지면 이전 연산은 저장되지 않으므로, 초기부터 다시 수행해야 함
- EDA 때 활용하면 좋음
- Python IDLE
- 구현은 한 번만 하고, 언제든 사용 가능
- 코드의 재사용이 간편함
- 디버깅을 잘 하면 Parameter의 변화를 잘 파악할 수 있음
- Configuration을 활용하여 자유롭게 실험을 핸들링 할 수 있음
