
Deep Learning 기본 용어
Data
Model이 학습할 때 활용할 것을 의미한다.
Train Data는 학습 때 활용하는 Data, Test Data : Model의 정확성을 평가하기 위해 활용하는 Data를 의미한다.
Model
Data를 변화시켜 내가 원하는 결과를 반환하게 만들어주는 것으로, y = f(x)라는 수식이 존재하고, 내가 y라는 값을 얻기를 원할 때 x가 Data, f라는 함수가 Model이라고 할 수 있다.
Loss Function
Model의 학습을 위해 활용하는 것으로, Model에서 나온 예측값과 실제 값의 차이를 나타내는 함수이다.
- Regression Task(회귀)에서의 Loss Function
- Regression Task : 데이터의 실제양과 모델의 예측치 사이의 차이가 평균으로 회귀하는 것
- 회귀 모델링 : 오차의 합이 최소가 되도록 만드는 것
- : 실제 결과 Data, : Model을 통해 구한 예측치
- Classification Task(분류)에서의 Loss Function
- : 실제 결과 Data, : Model을 통해 구한 예측치
Algorithm
Loss값을 최소화하건, Generalization을 위해 활용하는 방법들을 말한다.
Deep Learning 핵심 용어
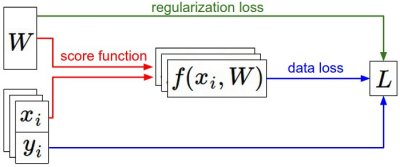
Optimization(최적화)
Gradient Descent는 최적화를 위해 활용하는 가장 대표적인 방법이다
- 사진 출처 및 이해할 때 활용한 사이트 : http://aikorea.org/cs231n/optimization-1/
Generalization(일반화)
DL의 목표는 Loss를 줄임과 동시에 일반화 성능을 높이는 것이다.
일반화 성능을 높인다는 것은 결국 Train Data에만 잘 적용되는 모델이 아닌 일반 생활에서도 잘 활용될 수 있는 모델을 만든다는 것이다.
Generalization Gap은 Test Error와 Train Error의 차이를 의미하며, 이 Gap을 작게 하는 것이 일반화가 잘 되었다는 것을 의미한다.
이런 관점에서, "일반화가 잘 되었다 최적화가 잘 되었다"임을 알 수 있다.
Overfitting과 Underfitting
Overfitting은 Model이 학습 데이터에 너무 적합하게 만들어져 Test Error와의 Gap이 존재하는 상태이며, Underfitting은 학습을 너무 적게 수행하여 Error 자체가 높은 상태를 의미한다.
- Overfitting, Underfitting, Generalization을 표현한 그래프
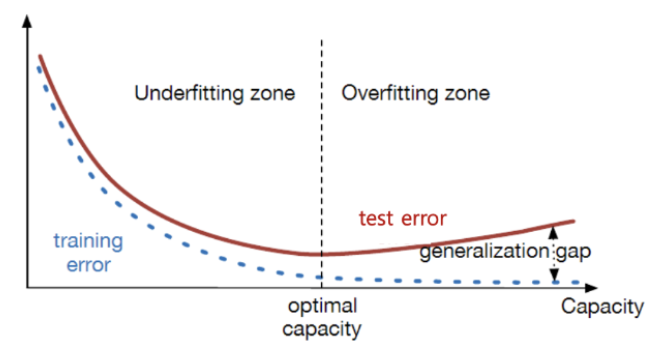
- 사진 출처 : https://mj-lahong.tistory.com/58
Cross Validation
Cross Validation이란 Train Data를 임의로 쪼개 Train Data + Test Data로 생성하는 것이다.
우리에게 주어진 Data는 Test Data(Validation Data)와 Train Data이다.
Model을 평가할 때는 Test Data를 활용할 수 없다. Test Data를 학습에 포함시키는 것은 그 자체로 Cheating이기 때문이다.
따라서, 우리는 Train Data를 활용하여 내가 설정한 Learning Rate 등이 최적의 Model을 도출해 내는지 유추할 필요가 있다.
이를 위해 활용하는 것이 Cross Validation이다.
Cross Validation을 통해 여러 가지 실험 모델 중 가장 좋은 모델을 선택하고, 최종 모델로 Select하는 방식을 활용한다.
특히, HyperParameter 값을 결정하는데 필수불가결한 방식이다.
(HyperParmaeter는 내가 변경해 줄 수 있는 값들(Learning Rate 등)을 의미하며, Parameter는 학습을 통해 최적화 시키고 싶은 값이라는 것을 알아두자. Parameter는 내가 지정하는 것이 아닌 컴퓨터 계산을 통한 학습으로 최적화 된다)
장점으로는 특정 평가 데이터 셋에 overfit 되는 것을 방지할 수 있어 좀 더 일반화 된 모델을 만들 수 있고, 모든 데이터 셋을 훈련에 활용할 수 있어 정확도를 향상시킴과 동시에 데이터 부족으로 인한 UnderFitting을 방지할 수 있다.
단점으로는 Iteration 횟수가 많기 때문에 모델 훈련/평가 시간이 오래 걸린다는 점이 있다.
Cross Validation 방법
- Train Data를 쪼개는 방법 : https://m.blog.naver.com/ckdgus1433/221599517834
1. Holdout method
Train Set을 임의의 비율로 쪼개 Train Set과 Test set으로 분할하여 활용하는 것으로, 한 번 쪼갠 Data를 모든 Epoch에서 동일하게 활용한다.
train : test = 9:1 또는 7:3 비율로 자주 활용한다.
계산 시간에 대한 부담이 적지만 Overfitting의 위험성이 높아지는 방식이다.
2. k-fold cross validation
데이터를 K개의 Data Fold로 분할한 이후, 1번의 Epoch을 진행 할 때 마다 총 K개의 묶음 ({(K-1) Train Data, 1개 Test Data})을 모두 활용하여 Accuracy를 계산한 이후, 평균값을 활용하여 학습을 진행하는 방법이다.
3. Leave-p-out cross Validation
전체 데이터를 K개로 나누고, 이 중에서 p개의 Sample을 선택하여 모델 검증에서 활용하는 방법으로, 얻을 수 있는 묶음이 이므로, p에 따라 묶음의 개수가 너무 많아져 계산 시간에 대한 부담이 커질 수 있다.
k-fold는 p=1인 Leave-p-out Corss Validation이다.
4. Stratified k-fold cross validation
주로 Classification 문제에서 활용되며, Label의 분포가 각 클래스별로 불균형을 이룰 때 유용하게 활용된다.
Label의 분포가 불균형한 상황에서 모든 Data Fold의 Label 분포를 최대한 실제 Data의 Label 분포와 비슷하게 하여 쪼개어 k-fold를 진행한다.
Bias and Variance
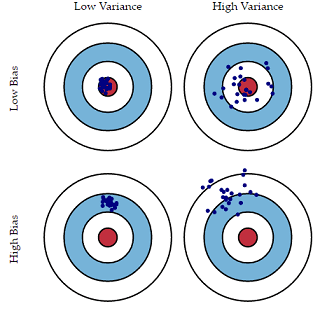
평균적으로 봤을 때 Data가 목표치에 가까우면 Bias가 낮은 것이고, Target이 모여 있을 경우 Variance가 낮은 것이다.
즉, Bias와 Variance가 동시에 낮을수록 좋은 모델이 만들어지는 것이다.
Bias and Variance Tradeoff
- 공부할 때 참조한 사이트 : https://modulabs-biomedical.github.io/Bias_vs_Variance

- : 실제 Data, : Model을 통해 출력된 예측치
위 식에서 E[θ']이 커지면 Variance가 작아지고, Bias가 커지기 때문에 서로 Trade off 관계에 존재함을 알 수 있다
그렇다면 어떻게 MSE 값이 줄어들 수 있을까? Var과 Bias는 Tradeoff 관계인데 말이다
Train을 통해 MSE를 구할 때는 Bias나 Variance 한 쪽을 보고 학습하는 것이 아닌 예측치를 활용하기 때문에 값이 작아질 수 있다.
즉, train을 위한 MSE를 구할 때는 Var이나 Bias 값이 영향을 끼치지 못하며, 어디까지나 "Loss function"으로 구한 MSE 값이 작아지고 이에 의거하여 Var과 Bias값이 바뀌는 것이지, Var이나 Bias 값이 바뀌어 MSE값이 변경되는 것은 아니다
Bias-Variance Tradeoff에 의하면 최적해에서는 Bias와 Variance값이 유사할 것이다
Generalization Gap이 생기는 이유도 예측이 되는 식이다. Loss 값은 최소를 향하고 결국 최솟값에 도달할 것이다. 그런데, Var과 Bias는 계속해서 Update 될 것이다.
따라서, Variance가 높아지고 이에 따라 정확도가 떨어지게 되는 것이다
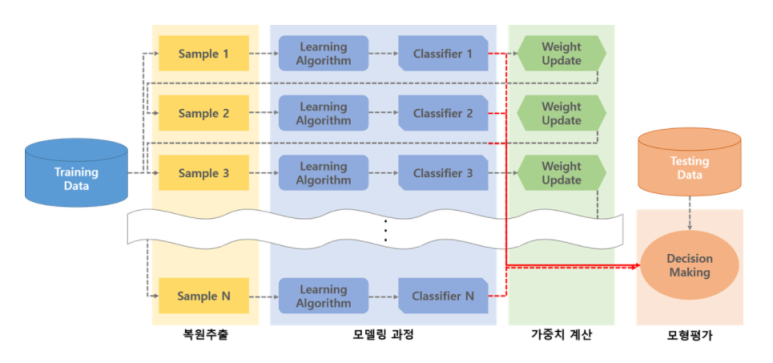
Bootstrapping
통계학에서 Bootstrapping이란 가설 검증을 하거나 Metric을 계산하기 전 Random Sampling을 적용하는 방법을 말한다.
예를 들어 집단 전체 값으로 가설 검증을 하지 않고, Random하게 100개를 뽑은 값으로 가설을 검증하는 것이다.
ML에서의 Bootstrapping은 Random Sampling을 통해 Training Data를 늘리는 방법을 의미한다.
학습 데이터의 일부분을 여러 개 묶음으로 만들고, 만든 Data Set을 통해 여러 개 Model을 만들어 모든 Model을 최종적으로 활용하는 것을 의미한다.
Bootstrapping 방법
1. Bagging
Data Set을 랜덤하게 여러 개 만들고 여러 개의 Data Set을 통해 각각의 Model을 생성. 이후 Model의 Output의 평균을 활용하는 Parallel 방식이다.
회귀 분석에서는 Output의 평균을 활용하며, 분류 Task에서는 Output을 Voting하여 최종 결과값을 도출한다.
앙상블 유형 중 하나이다.
2. Boosting
학습 Data를 Sequential 하게 바라보며 학습하는 방법으로, 아래와 같은 방식으로 진행된다.
먼저 Model을 하나 생성하고, Data 중 Model과 Loss가 크거나 틀린 Data들로만 새로운 Data Set을 생성한다.
이후 새로 생성했던 Data Set을 다시 Model에 통과시켜 재학습시키고, 이 과정에서 틀린 Data들을 모아 새로운 Data Set을 만드는 방식의 Sequential 방식을 통해 완벽한 Model을 형성하는 것이다.
오차가 발생한 Data Set으로 만든 Model을 Weak Learner라고 하며, Weak Learner를 계속 학습시켜 최종적으로 얻어진 정확도가 높아진 Model을 Strong Learner라 하고, 최종적으로 얻고 싶은 모델이기도 하다.
- Boosting에 대한 추가 설명 : https://hyunlee103.tistory.com/25
Gradient Descent Method
Optimizer를 설명하면서 가장 간단한 Gradient Descent Method를 설명했다. 자동으로 Gradient를 계산하는 방법들로써, PyTorch에서는 모든 Method가 구현되어 있으므로 실제로 코딩할 일은 많이 없을 것이다.
