Abstract
-
많은 Machine Learning Alogrithm은 Fixed-length feature vector가 필요함
- NLP(특히 Text)에서는 BoW 기법을 만힝 활용
-
BoW의 2가지 약점
- Word의 Order를 고려하지 못함
- 단어의 Semantic적 유사성을 무시해버림(의미를 무시함)
-
Pargraph Vector
- 이 논문에서 제안하는 핵심 개념
- Unsupervised Algorithm을 통해 단어, Paragraph, Document 등의 다양한 길이 Text에서 학습된 고정 Vector를 얻는 것
- Dense Vector로 문서를 나타내어 단어를 예측함
- BoW의 단점을 이겨낼 Potential을 가짐
- Semantic Analysis나 Text Classification Task에서 SOTA를 달성
Introduction
이전 연구들
-
Text로부터 도출되는 Fixed-length Vector가 필요함
- Text Classification이나 Clustering은 많은 Application(Web Search, Document Retreival, Spam Filtering 등)에서 중요한 역할을 하는데, 이를 위해 Fixed-length Vector가 필요함
-
기존에 활용하던 알고리즘 : BoW 혹은 Bag-of-n-grams
- 장점 : Simplicity, Efficiency, 생각보다 좋은 Accuracy
- 단점 1 : Word Order가 사라짐
- 같은 단어가 활용되었다면 다른 단어라도 똑같은 Representation을 가짐
- 단점 2 : Semantic적인 유사성을 고려하지 못함
- 본문에서는 Little sense about the semantics of the words or more formally the sitances between the words로 표현
- 즉, 의미적인 느낌이 별로 없고 단어 사이 거리를 활용하지 못함
-
Bag-of-n-grams는 Word Order를 고려하긴 하지만, Data Sparsity와 High Dimensionality를 겪음
Pargarph Vector
-
BoW의 단점을 해결하기 위해 이 논문에서 제안하는 개념
-
Text 부분으로부터 Continuous Distributed Vector Representation을 학습하는 Unsupperivsed Framework
-
이 논문의 강조점 : 다양한 길이의 Text에 이 알고리즘을 적용할 수 있음
-
Word Vector와 Pargarph Vector를 Concat시킨 이후, 주어진 Text에 대해 다음 단어를 예측하는 방식으로 학습 진행됨
- SGD 및 Backpropagation을 통해 Pargraph Vector와 Word Vector들이 학습됨
-
Pargarph Vector : Paragraph마다 다름
Word Vector : 모든 Pargraph에서 동일함(공유됨) -
Infrence시 Pargraph Vector : 계속해서 학습이 진행됨
Infreence시 Word Vector : 고정되어 단순히 결과값을 도출 하는데에만 활용됨 -
다양한 길이의 Input Sequence에 대해 잘 동작하도록 도와줌
- Parse Tree에 의존하지 않음
- Word Weighting Function을 위한 Task-Specific한 Function이 필요 없음
-
Pargarph Vector의 장점을 잘 보여줄 수 있는 BenchMark Dataset을 공개함
Inspired Paper(영감을 준 논문들)
- 일부분만 입력하였다.
Learning vector representations of words using neural networks (Bengio et al., 2006; Collobert & Weston, 2008; Mnih & Hinton, 2008; Turian et al., 2010; Mikolov et al., 2013a;c)
- 다른 단어와 Concat 시키거나 평균을 낸 Vector들에 의해 표현된 단어들과 Resulting Vector를 활용하여 다음 단어를 예측
- 결과 Vector들을 통해 단어의 의미적 유사성을 표현할 수 있음
Mitchell & Lapata, 2010; Zanzotto et al., 2010; Yessenalina & Cardie, 2011; Grefenstette et al., 2013; Mikolov et al., 2013c
- 위에서 활용한 개념을 Sentence나 Phrase-Level로 가져오도록 노력
- 간단한 접근법 : Document의 모든 단어에 Weighted Average를 적용
- 단점 : 평균을 활용하기 때문에 Word Order를 활용하지 못함
- 정교한 접근법 : Matrix-Vector Operation을 활용하여 Sentence의 Parse Tree에 의해 만들어진 Word Vector를 합함
- 출처 : Socher et al., 2011b
- 단점 : Parsing에 의존하기 때문에 Sentence보다 큰 Text에서는 잘 작동할지 미지수임
Algorithm
Learning Vector Representation of Words
이전까지 잘 알려진 Representation of Words를 만드는 방법은 아래 사진과 같다.
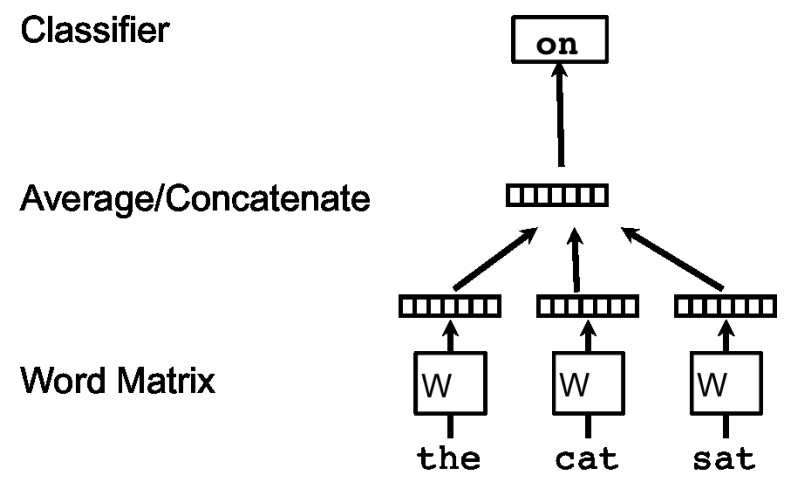
위 사진은 CBOW와 매우 유사한 알고리즘이자 이 논문 이전까지 자주 활용했던 방법이다.
(CBOW는 앞, 뒤 N개 단어를 활용하지만 위 사진은 이전 N개 단어만 활용했다)
각각의 Vector는 W라는 Matrix의 Column에 의해 형성된다.
여기서 Column에 의해 형성된다는 의미는, "the", "cat", "sat" 단어는 처음에 One-hot Vector로 들어가기 때문에 W의 특정 Column 값을 추출하는 것과 Matrix 연산이 똑같은 결과를 도출하기 때문이다.
이렇게 구해전 N개의 Vector들을 Concat 시키거나 Sum 연산을 수행한 이후, Classifier를 거쳐 다음 단어를 예측하는 알고리즘을 가지고 있다.
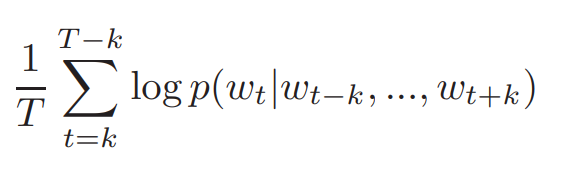
위 식은 Word Vector의 Log Probability로써, 위 식의 값을 극대화 시키는 방향으로 학습이 진행되는 것이다.
(이상하게 위 사진과는 다르게, Log Probabililty는 전형적인 CBOW의 Log Probability 식을 가지고 왔다. 어떤 방향성을 원하는지 모르겠었던 부분이다)
위 식에서 Prediction Task는 Softmax같은 전형적인 Multiclass Classifier를 활용해야 한다.
(그래야 확률 값을 구할 수 있고, 확률 값에 의거하여 다음 단어를 선택할 수 있으므로)
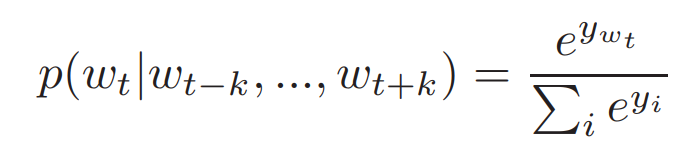
위 식은 Softmax Classifier를 적용시킨 식이다.
- 수식 용어
- : Output 단어 i로부터 나온 Un-normalized Log-probability
즉, 해당 위치에 올 수 있는 단어 후보 까지의 Log Probability를 구하고, 이 중 다음 단어로 예측한 의 확률을 구하는 공식이라고 보면 될 것이다.
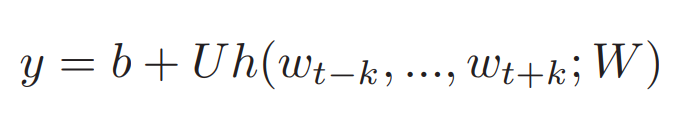
그리고, 이 때 는 아래와 같은 식으로 계산 될 수 있다.
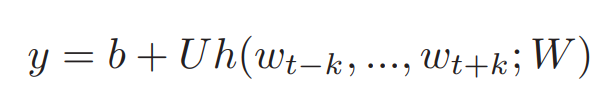
- 용어 설명
- U, b : Softmax Parameter
- h : W로부터 추출된 단어 Vector들의 평균 혹은 Concat을 반환하는 함수
수식 설명
처음에 Softmax Parameter라는 것이 잘 이해가 되지 않았는데, 개인적으로는 아래와 같이 이해했다.
y라는 것은 으로 이루어진 Matrix이다.
는 이 중 i번째 값을 뽑아 활용하는 것이다.
이렇게 이해하고 보니 위 식이 Linear 함수와 매우 유사하다는 것을 알게 되었다.
즉, h 함수를 통해 구해진 함수를 U와 곱해주고, 이 값을 b(Bias)와 더해주어 값을 계산할 수 있다고 이해했다.
하지만, (이전 논문 리뷰에서도 말했듯이) Softmax는 현실성이 없는 Cost가 비싼 함수이기 때문에 빠른 학습에 도움을 주는 Hierarchical Softmax가 제안되었다.
이 논문에서는 이 중에서도 Binary Huffman Tree를 활용할 것이다.
이유는, 이 Tree는 Frequent Words에 짧은 코드가 할당되어 좋은 Speedup Trick을 가지고 있기 때문이다.
학습은 SGD와 Backpropagation을 활용하여 진행될 것이다.
학습이 수렴되면(나는 학습이 모두 진행된다는 것으로 이해했다), 비슷한 의미의 단어들은 Vector Space 공간 내에서 비슷한 위치에 존재할 것이다.
이런 특성을 활용하여 다른 Language에 대해 Phrase와 Word를 번역할 때 Linear Matrix를 하는 것도 가능하다고 주장한다.
또한, 이런 특성들은 많은 NLP Task에서 Word Vector가 매우 매력적이게 만들었다.
Paragraph Vector : A distributed Memory Model
Paragraph Vector는 Word Vector에서 영감을 받았다.
Word Vector에서는 랜덤하게 단어 Vector가 Initalize되어도 결국에는 좋은 Vector Represenation들이 도출된다.
즉, Pargarph Vector는 Pargarph에 존재하는 많은 Context Sample의 다음 단어를 예측하는 Task에 기여한다.
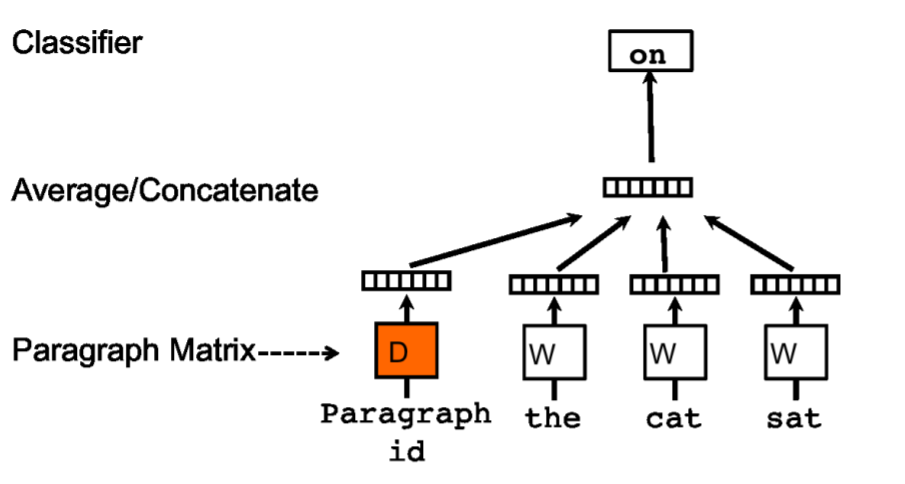
위 사진에서 볼 수 있듯, 모든 Pagraph Vector는 D라는 Matrix에 의해 Unique Vector로 Mapping 된다.
이렇게 구한 Paragraph Vecotr와 Word Vector를 평균 내거나 Concat 시켜 다음 단어를 예측하는 방식으로 모델이 작동한다.
아래 Experitments에서는 Concat 방식을 활용하여 실험을 진행하였다.
Paragraph Token은 현재 Context나 Paragraph의 topic에서 어떤 부분이 빠졌는지 기억해주는 역할을 수행한다.
이러한 이유로, 우리는 이런 알고리즘을 PV-DM이라고 부르기로 했다.
모델의 학습은 SGD와 Backpropagation에 의해 진행된다.
Prediction(inference)를 수행할 때는 새로운 Paragraph를 위해 Pargarph Vector를 계산할 필요성이 존재한다.
(사실 이 부분에서 논문에 대한 의문성이 들었던 점이, 새로운 Pargraph가 Input으로 들어올 때 마다 Matrix가 커져야 한다는 것인데, Matrix를 추가시키는 연산의 Cost가 만만치 않게 클 뿐더러 실생활에 적용시키기 위해서는 수많은 Paragraph가 추가되기 때문에 저장 공간이 부족해지지 않을까라는 의문이 들었다.)
Inference 과정에서는 Word Vector W와 Softmax Weight은 고정되고, Paragraph Matrix만 Gradient Descent를 통해 학습이 진행된다.
이 때 Paragraph Vector들은 Paragraph를 위한 특징으로 활용되는데 이런 특징을 K-mean나 SVM같은 Logistic Regression ML 기술에 적용하여 활용할 수도 있다.
Pargarph Vector의 이점은 Unlabeled Data로부터 학습하기 때문에 Labeled data가 적어도 잘 학습이 진행된다는 점으로써, Supervised Algorithm의 단점을 해결할 수 있다는 점에 있다.
특히, Pargraph Vector는 BoW의 key weakness를 처리할 수 있다.
- Word Vector의 중요한 특성인 "의미(Semantic)"를 담음
- Word Order를 고려할 수 있음
- n-gram model에서 n을 매우 크게 설정하는 아이디어와 비슷한 방식으로 Word Order를 고려할 수 있게 됨
n-gram model은 word order를 포함한 Paragraph에 대한 많은 정보를 보존하고 있고, bag of n-grams보다는 적은 Dimensional Representation을 창조한다는 장점을 가지고 있다.
- 차원이 높으면 일반적으로 일반화가 poorly하게 되는 경향이 있다고 논문에선 말함
Paragraph Vector without word ordering : Distributed Bag of words
위의 CBOW와 비슷한 방법으로 Pargraph Vector를 활용하는 방법 이외에 다른 방법을 제시하고 있다.
Input의 Context Words를 무시하고 Paragraph로부터 랜덤하게 예측된 단어들을 도출하는 방식이다.
모델은 아래와 같다
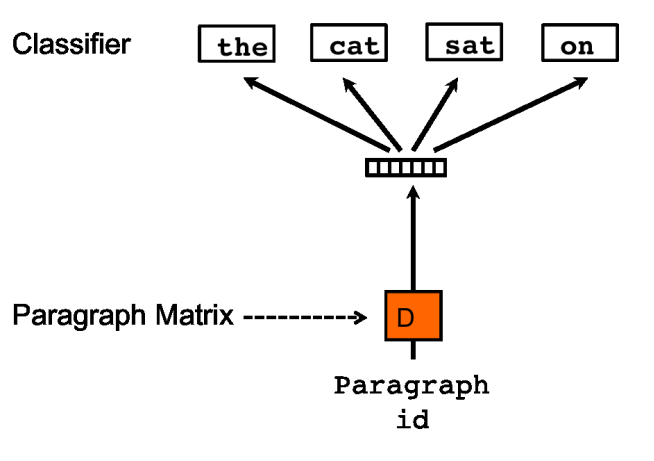
SGD의 Iteration을 진행할 때, 주어진 Pargraph Vector를 활용하여 Text Window를 형성하고, 이 단어들 중 Random하게 단어를 Sample하는 Classification Task를 형성하는 것이다.
이 말을 어떻게 이해했냐면, Paragraph Vector만 Input으로 넣어주면 몇 개 단어들이 Output으로 (랜덤하게) 예측 될 것이다.
이 때, Word Vector를 Input으로 넣어주지 않으므로 Context Words를 무시한다는 것이다.
또한 이렇게 예측된 단어가 N개가 있을텐데, 이 N이 Text Window를 의미하며, 이 중 (연속된 몇 개의) 단어들을 선택하는 것이 Sample하는 과정이라고 이해했다.
이 논문에서는 이 모델을 PV-DBOW라고 지칭하였다.
(PV-DM 과는 반대되는 개념)
PV-DM이 PV-DBOW보다 일반적으로 좋은 점수를 냈다.
하지만, PV-DM과 PV-DBOW를 동시에 활용하였을 경우 광범위한 Task에서 더 좋은 점수를 냈고, 이러한 이유로 두 방법 모두를 활용하는 것을 추천한다.
논문의 Experiments에서도 이 2가지 방법 모두를 활용하여 실험을 진행하였다.
Experiments
들어가기 앞서
-
Sentiment Analysis
- Stanford sentiment treebank Dataset & IMDB Dataset활용하여 실험
- Document의 길이는 모두 다름
-
Information Retrieval Task
- 목적 : 주어진 Query에 대하여 Document를 찾을 수 있는가
Sentiment Analysis with the Stanford Sentiment Treebank Dataset
Dataset
Negative인지 Positive인지 0.0 ~ 1.0 사이의 값으로 Labeling되어 있는 Datset이다.
Tasks and Baselines
2개의 Task에 대해 진행하였다.
1. Fine-grained Classification
- {Very Negative, Negative, Neutral, Positive, Very Positive} 중에서 1개를 고르는 Task
- 2-way coarse-grained classification task
- {Negative, Positive} 중 1개를 고르는 Task
특히, 평가를 위하여 영화 Review를 활용하였다.
영화 Review는 짧고 문장의 구성성이 긍정적인지 부정적인지에 중요한 역할을 한다.
훈련 세트가 작음을 생각해봤을 때, 이런 단어 간 유사성은 중요한 역할을 한다고 생각하여 Dataset으로 선택하였다.
Experiment Protocol
Special Character (,.!?)도 1문자로 생각하여 총 8개 단어를 Concat 시켜 Predict했다.
Inference 때는 Pargarph Vector도 계산에 넣어줘야 하므로, 넣어주는 Word Vector의 개수는 7개가 될 것이다.
Results
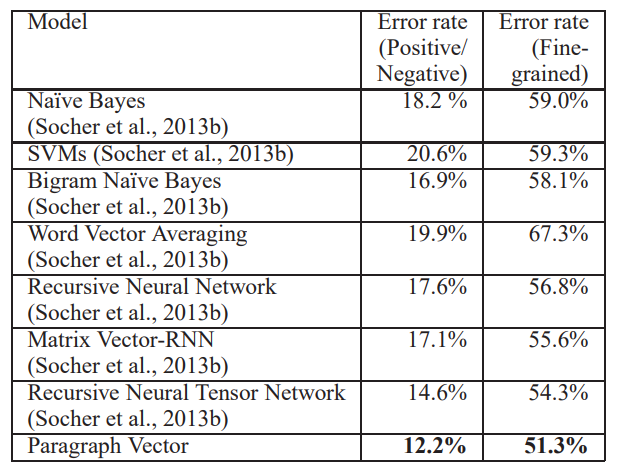
-
bag-of-n-grams model(NB, SVM, BiNB)는 점수가 매우 안 좋음
- Averaging한 것도 결과 향상은 없음
- 이유 : Sentece 구성(Word ordering)을 파악하지 못하므로 (언어학적으로) 정교하지 못함
-
RNN 같이 더 발전된 방법들(하지만 Parsing이 필요한 것들)은 Bag-of-n-grams Model보다는 좋아짐
-
그러나, Pargraph Vector를 활용한 우리 결과가 가장 좋았음
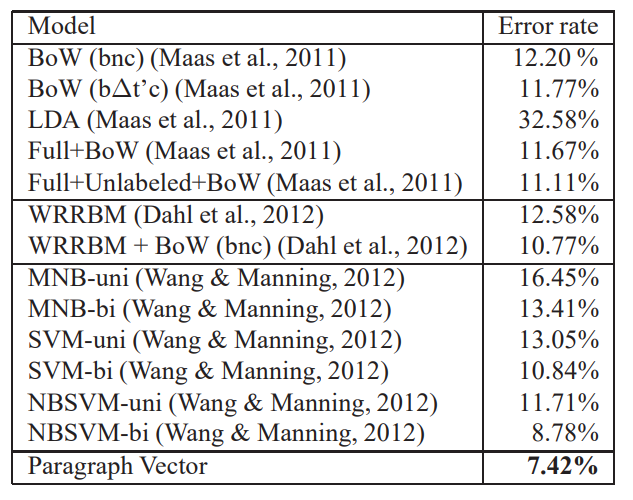
Beyond One Sentence : Sentiment Analysis with IMDB Dataset
논문에서 설명한 방법은 Parsing이 필요하지 않으므로 다양한 길이의 Text에도 적용할 수 있는데, 이를 보이기 위한 실험이다.
Dataset
100000개 movie review를 모아두고, label training instance, test instance, unlabled train instance를 1:1:2로 나눴다.
이후, 이 Data를 Positive, Negative 2개 Label로 지어 Dataset을 형성되었다.
Label은 Balance가 잡혀 있는 상태이다.
Results
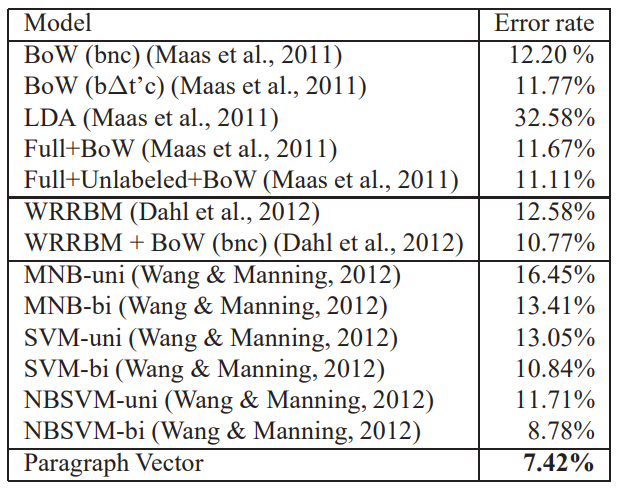
Wang & Manning, 2012 방법의 Error Rate가 10%이하라 좋은 거 같다.
하지만, Pargraph Vector를 활용한 결과 이보다 더 좋아졌다.
Information Retreival with Pargraph Vectors
1000000개의 가장 유명한 Query들에 대해 (Search하였을 때) Return되는 10개의 첫번째 결과들을 Dataset으로 활용했다.
즉, 검색했을 때 나오는 10개의 결과들을 Dataset으로 활용하는 것이다.
2개는 Query에 의해 나온 pargarph, 1개는 Random한 query에서 나온 paragraph로 설정했다.
이 때, 어떤 Pargarph가 똑같은 Query에서 나온 것인지 찾는 Task로 실험이 수행되었다.
이 논문에서는 8:1:1 비율로 데이터를 Train:Validation:Test Data로 나누었다.
- 참고로, 개인적인 생각이지만 이 논문에서 직접 만든 Dataset이므로 그렇게까지 신빙성이 높은지는 모르겠다
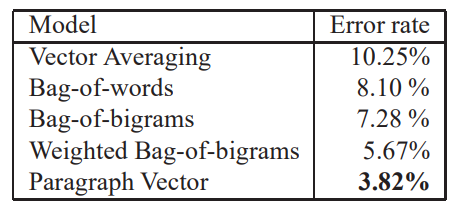
Some Furthrer Observations
-
PV-DM은 PV-DBOW보다 좋았다.
-
PV-DM에서 concat이 성능이 더 좋았다.
-
Window Size를 Cross Validate하는 것이 더 좋은 성능을 냈다.
- 주로 5 ~ 12 사이가 좋은 결과를 도출함
-
Pargarph Vector는 비싸지만 Test time 때는 Parallel하다.
- 16 core machine에서 30분 정도 소요
- 25000 document, document 1개당 평균 230 Word 존재
Related Work
Distributed Representations of words이 제안되고, 이는 NLP applicatios에서 많이 활용되었다.
현재 Trend는 Representing Phrases이고, Socher et al. (Socher et al., 2011a;c; 2013b)에서 이를 위한 방법이 제안되었다.
- Representing Phrases : "구"에 대하여 Represent하는 것
하지만 위 방법은 Parsing이 필요하고, Sentence-level 표현에는 잘 적용되었지만, 그 이상 범위에서 잘 적용되는지는 모호했다.
또한 Supervised Learning Algorithm이기 때문에 Labeled Data가 많이 필요했다.
Paragraph Vector는 반대로 Unsupervised이며 훨씬 적은 Labeled Data에 대해서도 잘 적용된다는 장점을 가진다.
이런 적용 방법은 CV의 Fisher Kernels라고 불리는 성공적인 패러다임과 유사하다.
Discussion
Unsupervised Learning Algorithm으로 다양한 길이에 적용하기 위해 학습된 Paragraph Vector에 대해 설명했다.
실험을 몇 개 진행해봤고, 해당 실험에서 SOTA를 달성했으며, Paragraph의 Semantic을 잡는데 장점을 지녔다.
(이러한 이유로) Pargarph Vector는 BoW Model의 약점을 잡아줄 수 있을 것 같다.
이 Pargarph Vector는 단어 뿐만이 아닌 Sequential Data 전체에도 적용이 가능할 것 같다.
느낀점
사실 읽으면서 "실제로 활용할 수 있을까?"라고 생각한 적이 한두번이 아닌 논문이다.
의도 자체는 좋았던 것 같다. Paragraph마다 특징을 가지고 있으니, 그 특징에 맞춰 학습을 진행하면 더욱 다음 단어 예측이 잘 될 것이다.
문제는 Pargraph Vector에 있다. 결국 이런 Algorithm은 새로운 Paragraph가 들어와도 잘 작동되어야 하는데, 이를 위해서는 Pargraph Vector를 위한 Matrix가 점차 확장되어야 할 필요가 있다.
그럼, 정~말 나중에는 Pargraph Matrix의 크기가 얼마나 커질 것이며, 연산 비용은 얼마나 들 것인가 생각하니 조금 아찔했다.
스터디에서 Pargraph에 대해서는 Test Paragraph까지 미리 Input으로 넣어 학습을 진행했다는데, 이게 실생활에서는 잘 적용할 수 있을지 모르겠다(모든 Paragraph를 학습 데이터로 넣을 순 없으니)
하지만, Pargraph에 Label을 붙여 학습을 진행하면 이 논문의 개념을 어느 정도 살리면서도 실생활에 활용할 수 있지 않을까 생각이 들었다.
예를 들어, "A는 오늘 밤 ?를 당했다"라는 문장이 있을 때, Sports Section에서는 "끝내기"라고 예측할 수 있고, 사회 Section이면 "범죄"라고 예측할 수 있을 것 같았다.
(물론, 이런 방법을 생각했으나 다른 방법이 더 좋았으니 위 방법을 사용한거겠지만....)
