Abstract
-
Skip-gram Model은 높은 Quality의 Distributed Vector Representation을 제공해줌
- Semantic, Syntatic적으로 정확한 관계를 가짐
-
논문에서 제안할 것 : Vector의 Quality와 Speed를 동시에 높이는 몇 가지 방법들에 대한 제안
- 빈번한 단어의 Subsampling 수행
- Hierarchical Softmax 대안인 Negative Sampling
Introduction
논문 이전 연구들
-
NLP Task에서 Vector Space 내에서 Distributed Representations를 표현함
- 비슷한 단어를 Grouping하는 결과를 가지고 옴
- NLP Task의 성능 향상을 가지고 옴
-
Distributed Vector Representation 생성 방법
- 통계학적으로 Language Modeling을 통해 Word Representation 생성
- 대표적 방법 : N-gram
- Skip-gram Model
- 통계학적으로 Language Modeling을 통해 Word Representation 생성
-
Skip-gram은 이전 Model과는 달리 Dense Matrix Multiplication이 없음
- 연산이 효율적으로 되는 이유
이 논문에서의 제안점
- Skip-gram Model에서의 몇 가지 확장점
-
빈번한 단어에 대해 Subsampling을 수행함
- Speedup
- 적게 나온 단어들에 대한 Representation Accuracy의 향상
-
Noise Contrastive Estimation(NCE)
- Train 속도의 증가
- 빈번한 단어들에 대한 Representation이 좋아짐
-
관용구를 표현하는 방법
- Word Representation은 Phrase(관용구)를 표현할 수 없다는 제한이 존재
- Recursive AE 같이 Word Vector 대신 Phrase Vector를 활용하여 이런 부분에 대한 이점을 얻을 수 있음
-
Skip-gram Model의 흥미로운 Property
- 간단한 Vector 연산은 Meaningful Results를 생산함
- 명확하지 않은 Langugae는 명확한 값의 연산을 통해 명명할 수 있음
Skip-gram Model
Skip-gram
Skip-gram의 목적은 Document나 Sentence에서 둘러싸인 단어들을 예측할 수 있는 Word Representation을 찾는 것이다.
- 용어 설명
- c : Training Context Size
- c가 커질수록 Accuracy는 커지겠지만 학습 시간은 길어짐
Skip-gram은 위 Log Probability 식의 값이 최대화 되도록 학습이 진행된다.
그리고 Basic Skip-gram Formuation은 를 계산하기 위하여 Softmax 연산을 수행한다.
하지만, 일반 Softmax 연산은 상대적으로 크기가 큰 W에 비례하므로 실용적이지는 않다
(W : Vocab에 있는 단어 개수)
Hierarchical Softmax
위에서 Basic Softmax는 실용적이지가 않다고 했다.
하지만, Softmax를 활용해야 하는 것은 분명하고, 이를 위해 나온 대안이 Hierarchical Softmax이다.
주요 이점으로는 Probability Distribution을 얻을 때 W Node를 모두 확인하지 않고, Node 값만 확인하면 된다는 점이다.
Hierarchical Softmax은 아래와 같이 구성된 Tree를 활용한다.
1. Binary Tree로 구성되어 있음
2. Vocab에 있는 단어들을 Leaf로 설정
3. 모든 Node에서 하위 Node에 대한 상대 확률을 명시적으로 나타냄
즉, Parent Node로부터 Left Child와 Right Child 중 더 높은 확률의 값을 가진 Node로 이동하는 과정을 거치는 것이다.
이를 논문에서는 단어들에 확률을 할당하는 "Random Walk"를 정의하는 과정이라고 말했다.
위 과정을 보면 왜 Node만 확인하면 되는지 알 수 있다. 결국, Root Node로부터 Leaf Node까지 2지 선다의 문제를 겪으며 알고리즘이 진행되고, 한 번 진행될 때 마다 확인해야 할 Node의 개수는 반으로 준다.
결국 Tree의 Heigth는 최대 이므로, 확인해야 할 Node 개수가 매우 많이 줄어드는 것이다.
수식을 통한 Hierarchical Softmax
- 용어 설명
- n(w,j) : Root ~ w(단어) Node 경로 중 j번째 Node
- L(w) : Path의 Length
- ch(n) : n의 고정된 Child Node
- [x] : x가 True일 경우1, 아닐 경우 -1을 반환
위 식을 통해 와 Gradient 값은 L(w)에 비례함을 알 수 있다.
즉, 보다는 크지 않은 비용으로 계산 수행이 가능할 것이다.
또한 Basic Softmax는 동일한 단어 w에 대하여 와 총 2개의 Vector가 필요했지만, Hierarchical Softmax에서는 w에 대응하는 와 Inner Node에 대한 있으면 계산이 가능하다는 것을 알 수 있다.
이런 Hierarchical Softmax는 학습 시간과 Accuracy 측면에서 좋은 효과를 보여줬다.
이 논문은 Experiment 때 빈번한 단어에 짧은 Code를 할당하여 Train을 빠르게 할 수 있게 하는 Binary Huffman Tree를 활용했다.
참고로, Frequency에 따라 Grouping 하는 것이 LM 기반 Neural Network의 Speed Up에 매우 좋음이 알려져 있다고 한다.
NCE(Noise Contrastive Estimation)
Hierarchical Softmax의 대안으로 나온 것이 NCE이다.
NCE란 CBOW나 Skip-gram Model에서 활용하는 Cost 계산 알고리즘이다.
전체 데이터셋에 Softmax 연산을 적용하는 것이 아닌 Sampling으로 추출한 일부에 대해서만 함수를 먹여주는 방식을 의미한다.
K개의 대비되는(Contrastive) 단어들을 Noise Distribution에서 구해서 평균을 구하는 것이 기본 알고리즘이다.
NCE는 Logistic Regression을 활용하면 Data와 Noise를 구분할 수 있는 좋은 Model이라는 것이 밝혀졌다
특정 논문에서는 NCE와 유사하게 Hinge Loss를 이용하여 Data와 Noise를 구분하는 Model을 제안하기도 했다.
Negative Sampling(NEG)
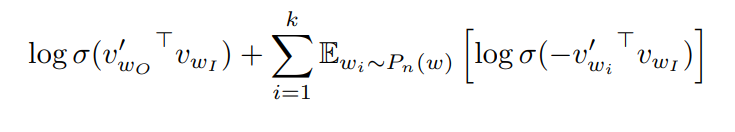
- 위 수식에서 는 Skip-gram의 Objective를 대체해 사용됨
- 목적 : Target Word 와 Nosie Distribution 를 구별할 수 있음
- k : Negative Sample 개수
논문 저자들의 실험 결과는, 데이터가 작을 때는 k가 5 ~ 20일 때, 데이터가 많을 때는 k가 2 ~ 5개일 때가 좋았다고 한다.
NCE VS NGE
NCE는 Sample과 Noise Distribution의 Probabilities가 동시에 필요하다. 이는 NCE가 Sample을 Noise Distribution에서 "Contrast"한 값을 뽑기 떄문이다.
하지만 NGE는 Contrast한 단어들을 Noise로 뽑는 것이 아니므로, 단순히 Sample만 뽑으면 된다.
또한 NCE는 Softmax의 Log Probability를 Maximize하지만, 이 특성은 논문에서(즉 NGE에서) 중요한 특성은 아니다.
NCE와 NGE 모두 Parameter와는 관련이 적은 Noise에 대한 확률분포를 가지고 있다.
Subsampling of Frequent Words
Rare한 단어와 Frequent한 단어들 사이의 Imbalance 문제 해결을 위해 도입된 Subsampling Approach 방식이다.
- 용어 설명
- : Word 의 Frequency
- t : Chosen Threshold. 일반적으로 정도로 설정함
Frequency가 t보다 큰 단어에 대해 적극적으로 Subsampling하기 위해 위 수식을 적용했다.
(즉, Frequency가 높은 단어들은 Subsampling 과정을 통해 Sampling될 확률이 감소한다)
Heuristic하게 들릴수도 있지만, 실제로 잘 작동한다고 주장한다.
Empirical Results
Skip-gram Model은 Large Dataset을 활용했는데, 이 논문에서는 Training Data에서 5번 이하로 나온 단어에 대해서는 Vocab에 저장하지 않고 버렸다고 말한다.
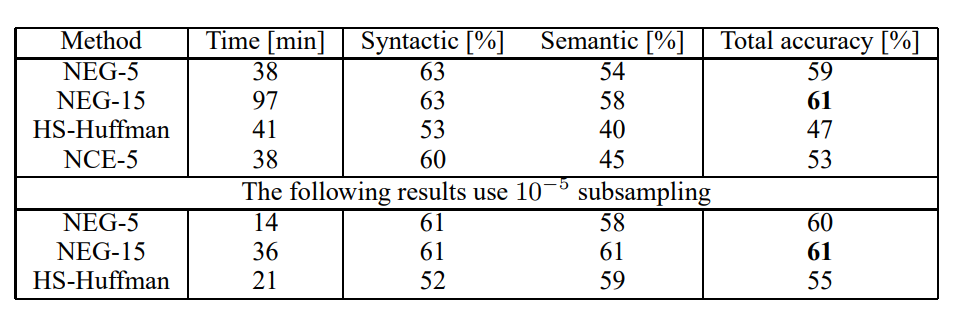
결과를 비교해 볼 때, NEG는 NCE보다 살짝의 성능 향상을 보였으며, HS와 비교했을 땐 큰 성능 향상을 보였다.
또한 Subsampling은 Training 속도를 빠르게 했을 뿐만 아니라, 위 표에서 결과를 더 향상 시켰음을 볼 수 있다.
Learning Phrases
많은 Phrase들은 단어들의 단순한 의미 결합이 아닌 구 자체로써의 의미를 가지고 있는 경우가 많다.
(ex) New York
우리는 다른 Paragraph에서는 자주 등장하지 않지만 특정 Paragraph에서만 빈번하게 같이 나오는 단어들을 찾아 처리해줬다.
그 결과, Vocabulary의 급격한 증가 없이 합리적인 Phrase를 찾았다.
Phrase를 식별하는 다양한 방법들이 있지만, 기술들의 비교는 주요 업무가 아니기 때문에 Simple Data-Drive Approach를 활용하기로 했다.
(1 ~ 2개 단어의 결합으로 Phrase가 형성되었다고 생각하는 것)
- 용어 설명
- : Coefficient를 빼주어 Rare 단어들로 구성되는 Phrase가 너무 많이 형성되지 않도록 막아줌
- 즉, 애초에 적게 나온 단어인데 Score가 작아 Phrase로 생각되는 경우를 제거시킴
Threshold를 넘어선 Score를 가졌다면 해당 Bigram을 Phrase로 사용하고, 2-4 pass를 넘어서면 Threshold를 감소시켜 더 긴 Phrase를 형성 할 수 있게 해주었다.
Additive Compositionality
단어나 구에 대한 Vector 구조는 Analogical Reasoning에 대해 정확한 성능을 보이는 선형적인 표현이다.
특히 Skip-gram은 의미 있는 요소들의 결합을 벡터 합을 통해 표현할 수 있음을 보여줬다.
두 단어의 합은 두 단어가 표현하는 Context의 곱으로, 이 논문에서는 AND 연산이라고 보았다.
높은 확률로 두 벡터가 결합된다면 결과 역시 높은 확률을 가지게 되고, 반대로 낮은 확률을 가지고 있다면 두 단어가 결합한 Vector는 낮은 확률을 가지게 된다.
예를 들어, "Volga River"가 River와 Russia라는 단어랑 자주 나온다면 두 벡터의 합으로 Volga River를 표시할 수 있게 되는 것이다.
Comparison to Published Word Representations
많은 선행 연구자들은 그들의 결과 Model을 Comparision 및 미래에 활용하기 위해 공유해 놓았다
이를 모두 다운 받아 비교해 본 결과, Skip-gram Model의 성능이 가장 좋았다.
특히, Large Corpus에 대해 학습한 Big Skip-gram Model이 다른 Model볻 성능이 좋았는데, 흥미롭게도 Training Time은 오히려 낮음을 알 수 있었다.
Conclusion
이 논문은 몇 가지 핵심적인 기여를 했다.
먼저, 여기에서 활용된 기법은 Continuous BoW Model을 학습시킬 때도 활용할 수 있다.
두번째로, 이전에 발행된 모델보다 계산적으로 나아진 모델을 통해 대용량의 데이터를 활용하여 성공적인 학습이 가능해질 것이다.
특히, Rare Entity들에 대해 더 좋은 Word & Phrase Representation을 얻을 수 있게 될 것이다.
빈번한 단어들을 Subsampling함으로써 빠른 학습이 가능해졌고, Uncommon Word에 대해 더 좋은 Representation이 가능해졌다.
Negative Sampling Algorithm을 도입하여 (특히 Frequent Words에 대해) 정확한 표현 방법을 배우는 간단한 Training Method를 형성하였다.
Task에 따라 HyperParameter와 Model의 선택은 달라져야하며, 이 논문의 저자들은 모델의 구조, Vector Size, Subsampling Rate, Training Window Size가 영향을 많이 끼친다고 생각했다.
가장 흥미로운 결과는 Word Vector들은 간단한 합연산을 통해 의미적으로 결합이 가능하다는 것이다.
또다른 접근법은 단일 Phrase를 학습하는데 있어서 단일 토큰으로 구문을 간단히 표현하는 것이다.
이 두가지 접근 방식의 계산 복잡성을 최소화하고 더 긴 텍스트를 표현하는 강력하고 간단한 방법을 제공한다.
느낀점
NCE와 NGE의 차이점을 이해하는 것이 이 논문의 핵심이 아니였나 싶다.
사실 Negative Sampling이라는 것을 들어보기는 했지만, 이렇게 자세히 공부해본적은 없어서 좋은 경험이 된 것 같다.
또한 Hierarchical Softmax에 대해서는 들어본적도 없었는데 처음 공부하게 되었으며, 이 연산에서 NCE, NGE가 도출되었다는 점도 신기하게 느껴졌다.
수식이 몇 개 나왔는데, 를 빼주는 이유 등을 이해하며 수식을 보니 사소한 예외 하나라도 생기지 않도록 최대한 노력해주는 모습이 보인 것 같았다.
AI를 다룰 때는 최대한 예외가 발생하지 않도록 코드를 짜는 것을 중요시해야 한다고 생각되는 논문이였다.
