Abstraction
- NLU는 다양한 task로 구성되어 있음
- Textual Entailment
- QA
- Semantic similairty assesment
- Document Classification
- 현재 학습을 위한 Labeled Data는 매우 적음
- Train을 어렵게 하는 이유
- Unlabeled Text Corpora의 양은 많으므로, 이를 활용할 방법을 생각해봤음
- UnLabeled Data로 Pre-train 시키고, Task에 맞게 Fine-tuning으로 Parameter를 미세조정 처리하는 것이 효과가 좋음을 알아냈음
- 많은 작업에서 큰 성능 향상을 이뤄냄
Introduction
-
현재 Annotated Resource의 부족으로 많은 Domain에서 NLP Model의 적용성이 제한됨
- 대부분 Deep Learning Model은 학습을 위해 상당한 양의 Label data를 요구하기 때문
-
Unlabeled Data로 학습하는 것은 시간이 많이 들고 expensive하지만, 뛰어난 대안이 될 수 있음
- 대표적인 Pre-trained Word Embedding : Word2Vec, GloVe
-
Unlabeled Data에서 단어 단위 이상 정보를 활용하기 어려운 이유
- 어떤 Objective를 이용해야 Model의 Output을 Transfer했을 때 효과적일지 명확하지 않음
- Unlabel Data로 학습시킨 Model을 정해진 Task로 바꾸는 과정(Transfer 과정)에 대한 명확한 방식이 없음
- Transfer : Pre-trained Model을 Fine-tuning을 통해 미세 조정시켜 Supervised Model로 만드는 과정
-
논문 핵심 : Unsupervised Pre-trainig과 Supervised fine-tuning의 Combination으로 Semi-supervised approach 방법을 발견했음
-
논문 목표 : 특정 Task에 종속되지 않은, 범용적인 Model은 만드는 것
-
Semi-supervised approach 과정은 크게 2단계로 구성됨
- Unlable Data로 초기 Parameter를 학습함
- 1에서 정해진 Parameter들을 Target Task에 대해 적용하여 Task에 적합한 Supervised Model을 생성함
-
모델 구조 : Transformer의 Decoder 활용
- 많은 Task에 대하여 Strong하게 동작함
- Long-term dependency를 처리할 때 더 적합(구조적인 Memory 제공)
- RNN보다 다양한 Task에 대하여 Robust Transfer Performance를 이끌어냄
-
(다양한 Task에 대하여) Pretrained Model의 변형을 최소화시켜 Fine-tuning함
- 모델을 Transfer할 때 Task-specific한 입력을 생성해서 활용함으로써 미세 조정을 가능하게 함
Related Works
Semi-supervised Learning for NLP
- 이번 논문(GPT)도 semi-supervised Learning의 일종
- 이전까지의 모델은 단어 단위 정보를 학습하여 활용하는 Word Embedding 방식
- Word2Vec, GloVe
- Unlabel Data로부터 단어를 학습시키고, 이렇게 학습시킨 모델로 Word Embedding을 수행하면 해당 Embedding Vector를 모델의 입력 값으로 넣었음
- GPT는 더 높은 수준의 의미를 학습하려 함
Unsupervised pre-training
- 목적 : 좋은 초기 환경을 제공하는 것
- 이전 Unsupervised Pre-training Model은 LSTM을 활용
- GPT에서는 Transformer를 활용하여 Long-term Dependency를 잘 학습할 수 있음
- Hidden Representation을 활용하는 방식도 존재는 함
- 다양한 Task에 대해 Parameter 차이가 너무 다양해진다는(변화가 커진다는) 단점이 존재
Auxiliary training objective
- 보조적인 Unsupervised Training Objecive를 추가하는 것
- POS tagging, NER, chunking, LM 등을 활용하여 성능을 향상시킬 수 있음
- GPT에서는 Auxiliary LM을 활용함
Framework
Unsupervised Pre-training
- 학습 진행 방향 : Likelihood를 최대화 하는 방향
- : Unsupervised Corpus of tokens
- k : Window Size
- : Parameter
- Multi-Layer transforemre Decoder를 활용
- Multi-Headed Self-attention을 통해 모든 입력 토큰에 대해서 수행함
Supervised Fine-tunning
- 학습 진행 방향 : 를 최대화 하는 방향으로 학습됨
- Dataset 구성 : Label - y, input token -
- : Parameter
- : Pretrain Model의 (m번째) Output
- LM(Language Model)을 Fine-tuning 과정에서 보조 Objectvie로 활용했을 때 장점
- Supervised Model의 일반화를 개선
- Generalization 향상
- 수렴을 빠르게 시킬 수 있음
- Supervised Model의 일반화를 개선
- Fine-tuning 과정에서 추가적으로 필요한 파라미터
- : Linear Output Layer를 위해 추가
- Delimiter(구분자)를 위한 Embedding
Task-specific input transformations
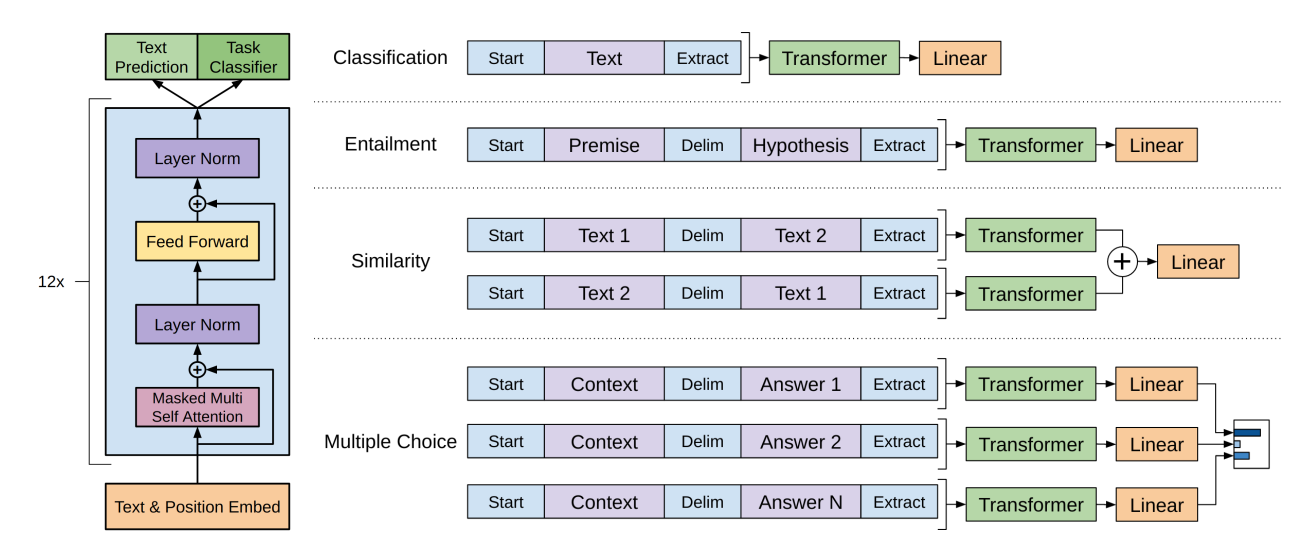
- Fine-tuning시 Traversal-style approach를 사용
- 원래 Data를 구조화된 input으로 바꾸는 것
- 우리의 Pre-trained Model이 처리할 수 있도록 Ordered Sequence로 만드는 것
- input transformation은 Task에 따라 Parameter 변화가 심하게 되는 것을 막아줌
- Task별 Input Transformation
- Text Entailment : Premise와 Hypothesis를 delimiter($)로 나눠줌
- Similarity : Order가 상관이 없는 것을 반영하기 위하여, Order를 바꿔 총 2개의 Input Sequence를 만든 이후 각각을 독립적으로 Model에 돌려줌
- QA, Commonsense reasoning : Document , question , 가능한 Answer 후보들 가 입력에 존재해야 한다. 이 모든 값을 ;a_k]$로 연결해준 이후 각각의 Sequence를 독립적으로 처리함
- Answer들의 Output Distribution을 위한 Softmax Layer에 Normalize를 적용시켜줌
Experiments
Setup
-
Unsupervised Pre-trainig Model을 형성할 때 BooksCorpus Dataset 활용
- 긴 문장들이 포함되어 있어 long-range information 학습에 적합
-
1B Word BenchMark를 활용하기도 함
- 매우 늦은 Perplexity를 달성
- 이유 : 문장 단위로 섞여져 있어 long-range structure를 파괴함
-
12-layer decoder only transformer with maksed self-attention head를 Train시킴
-
Adam Optimization scheme 활용
- 최대 lr : 2.5e-4
- 0 ~ 최대 lr까지 증가하다 Cosine Schedule을 활용했음(Warmup Scheduler 활용)
-
Weight Initialization : N(0,0.02)
-
L2 regularization 활용
- w=0.01
-
Activation Function : GELU
-
Dropout을 Classifier에 추가
- p = 0.1로 설정
-
Fine-tuning이 빠르게 수행됨
- 3 Epoch이면 충분했음
-
: 0.5로 설정
Supervised fine-tuning 실험 결과
-
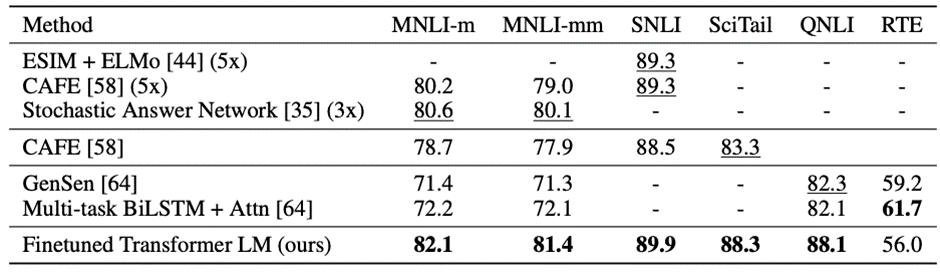
NLI(Natural Language Interface)
- 두 쌍의 문장에 대해 관계를 판단하는 Task
- SNLI, MLNI, QNLI, SciTail, RTE 5개 Dataset에 대한 성능을 비교했음
- 모든 Dataset에 대해 성능이 좋아짐
-
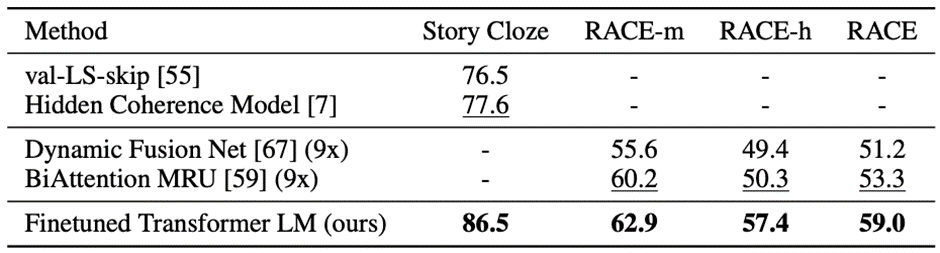
Question Answering and commonsense reasoning
- RACE datset 활용
- 영어로 구성된 중/고등학교 시험 문제
- Long-range Context를 필요로 하고, 더 많은 reaoning type question을 보유하고 있다고 생각하여 활용
- 기존 모델보다 성능이 좋아짐
- RACE datset 활용
-
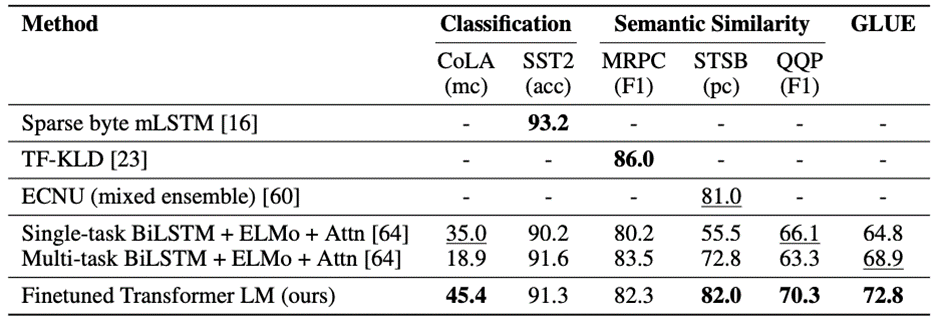
Semantic Similarity
- 두 문장의 의미적 유사성을 판단하는 Task
- MRPC, QQP, STS-B 데이터 셋을 활용
- 기존 모델보다 모두 좋은 성능을 보임
-
Classification
- 2종류의 Classification Task 진행
- CoLA : 문장이 문법적으로 맞는지 판단하는 과정이 포함됨
- SST-2 : Standard Binary Classification Task
- 2종류의 Classification Task 진행
-
전반적으로 총 12개 DataSet 중 9개 Dataset에 대해 SOTA를 달성함
- 다양한 크기의 Dataset에 대해 비슷하거나 더 좋은 성능을 제공할 수 있음
- 다양한 크기의 Dataset에 대해 비슷하거나 더 좋은 성능을 제공할 수 있음
Analysis
Impact of number of layers transferred
- Transfer할 때 Layer Number의 영향 확인
- Transfer하는 Layer 개수가 많아질수록 성능이 더 좋아짐
- 알 수 있는 점 : Pre-trained Model의 각 Layer가 Target task를 해결하기 위한 다양한 특성들을 각각 학습함
Zero-shot Behaviors
- Language model pre-training이 효과적인 이유에 대해서 살펴봄
- 가설 : LM의 성능을 향상시키기 위하여 다양한 NLP task를 학습한다는 것
- 오른쪽 Chart에서 Pre-training을 많이 할수록 다양한 Task의 성능이 증가함
- LM을 수행하며 다양한 NLP 특성들을 함께 학습한다는 것에 대한 증명이 됨
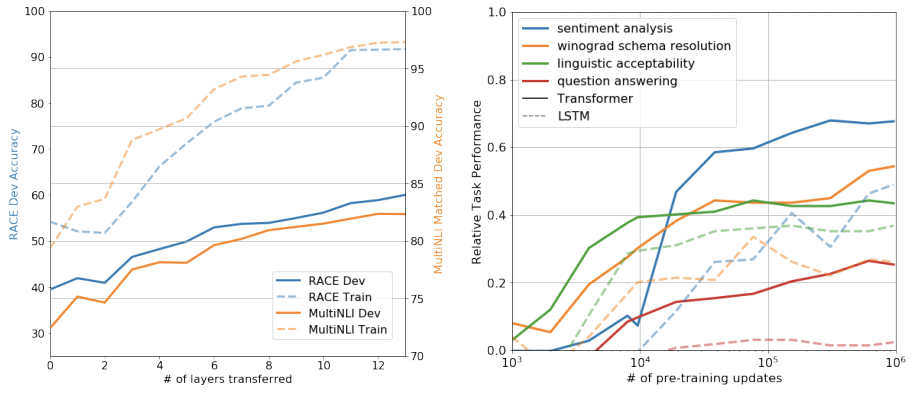
Ablation studies
- (Fine-tuning 과정에서) Auxiliary LM objective 없이 Model 학습
- Dataset이 많을 경우 영향을 많이 받음
- Transformer의 영향을 확인
- LSTM을 활용하여 실험해봄
- MRPC에 대해서는 LSTM이 더 좋았지만, 다른 모든 Test에 대해서는 Transformer가 좋음
- Pre-trainig없이 Trnasformer만 활용해봄
- 모든 Task에 대하여 성능이 떨어짐

- 모든 Task에 대하여 성능이 떨어짐
Conclusion
Pre-trainig을 통해 Task-agnositc한 Model을 형성하고, 이후 Discriminative Fine-tuning 과정을 거쳐 미세 조정을 통해 NLU를 성취하는 Framework를 소개했다.
다양한 Corpus를 통해 Pre-trainin하는 것은 상당한 World 지식과 넓은 범위의 Dependency를 처리하는 능력을 습득하게 해주며, 많은 Task로 변환하여 처리할 수 있게 된다.
성능을 향상시키기 위하여 Unsupervised Training(Pre-trainig)을 활용하는 것은 Machine Learning 연구의 중요한 목표가 될것이다.
이 연구가 NLU 및 다른 Domain에 대한 Unsupervised Learning 새로운 연구에 도움이 되고, 나중에 Unsupervised Learning에 대한 이해도가 높아지기를 기대한다.
느낀점
GPT는 악용을 막기 위해 코드를 공개하지 않았다고 들은 것 같은데, 실제로 논문에서도 최대한 코드를 숨기려고 하는 것이 보이는 것 같다.
실제로 Transformer의 Decoder 부분을 활용하고, 몇 개 부분에서 Input Transformation에 대해 설명해준 것 이외에는 코드적인 설명이 거의 존재하지 않고, 오히려 수학적 개념이 더 많았던 것 같다.
하지만, 매우 뛰어난 Semi-Supervised Learning Model이였던 GPT-1에 대해 알게 되고, BERT 때 약간 이해되지 않았던 Pre-training과 Fine-tuning에 대해 조금 더 자세히 알게 된 것 같다.
