Pandas
Pandas란?
구조화 된 데이터의 처리를 지원하는 Python 라이브러리이다.
Pandas의 공식 GitHub의 설명은 아래와 같다.
"관계형" 또는 "레이블이 된" 데이터로 쉽고 직관적으로 작업할 수 있도록 설계되었고 빠르고 유연한 데이터 구조를 제공하는 Python 패키지
여기서 중요한 부분은 "관계형" 또는 "레이블이 된" 데이터라는 것이다.
Excel 데이터나 DBMS의 관계형 테이블 형태와 같은 표 형태의 데이터로 처리한다는 것이다.
Numpy와 통합하여 강력한 Spread Sheet 처리 기능을 제공하며, 주로 데이터 처리 및 통계 분석을 위해 활용한다.
하지만, Table 형태로 데이터를 저장하므로 음성이나 이미지 데이터를 다루는 데에는 그다지 적합하지는 않다.
단지, Text를 다루는 NLP 쪽에서는 매우 강력한 도구라고 할 수 있다.
Series
Series란?
Pandas에서 가장 많이 활용되는 2가지 개념을 뽑으라면 Seires와 DataFrame이 아닐까 싶다.
즉, 이 2가지만 제대로 알고 있어도 Pandas의 대부분 기능을 잘 활용할 수 있게 될 것이다.
아래 사진을 보자
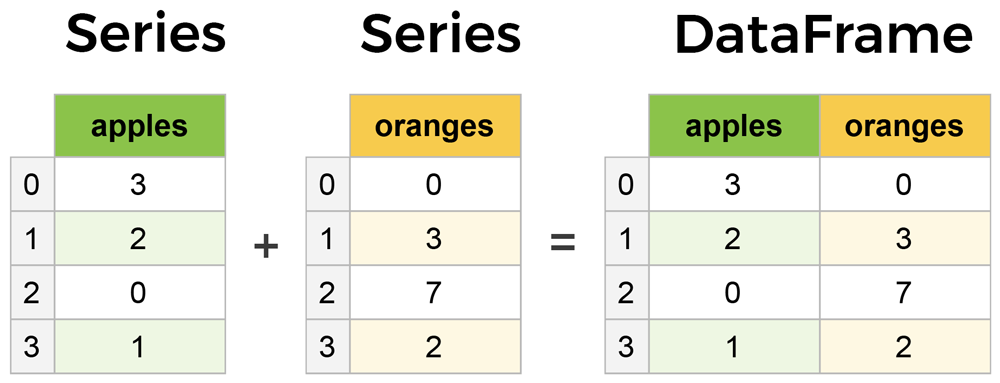
- 출처 : https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/
위 사진이 Series와 DataFrame을 잘 설명한 것 같다.
Series란 Index가 존재하는(Indexing된) 데이터의 1차원 배열을 의미한다.
여기서 생각할 점은 저렇게 활용할 경우 ndarray를 활용하면 되는 것이 아닐까라는 생각이 들 수도 있다.
실제로 위 사진만 보면 apples Series의 0번째 값을 접근할 때 apples[0]으로 접근하면 될 것 같고, 이 경우 Numpy를 통해 Array를 형성했을 때의 결과와 같다고 생각이 될 수도 있다.
Series가 Numpy보다 강력한 점은, Index가 명시적이라는 것이다.
Ndarray를 생각해보자. 우리는 Index를 바꿀 수 없다. 만약 Index를 바꾸기 위해서는 Index에 존재하는 값을 교환하거나, Dict를 활용하여 Index를 추출한 뒤, Dict에서 Index를 검색하는 방법을 활용해야 한다.
하지만 Pandas의 Series를 활용하면 그럴 필요가 전혀 없다. index 자체가 명시적이기 때문에 굳이 0, 1,...으로 순차적으로 Indexing할 필요가 없을 뿐더러, int가 아닌 값으로도 Indexing이 가능하다.
따라서, 이런 중간 과정을 없앴다는 점에서 강력한 성능을 가진다고 할 수 있을 것이다.
Series 특징
1. Index 이름 중복 가능
Default Index은 [0,1,2,3,...]으로 Python List나 Ndarray의 Index와 동일하다.
하지만, 내가 원할 경우 Index를 [0,0,2,3,...] 처럼 지정해줄 수도 있다.
물론, 개인적인 생각으로 가능한 것과 활용성은 차이가 있다고 생각한다. 굳이 활용해야 할까? 싶은 기능이긴 하다
2. Index 이름 숫자 이외에도 지정 가능
나는 이 기능이 매우 매력적이라고 생각한다.
예를 들어, 사람에게 명시하기 위해 [1,2,3,...]보다 [One, Two, Three,...]로 보여주고 싶을 수도 있다.
이 때 Ndarray는 위와 같이 하려면 함수를 만들거나 Dict Data를 활용해야하지만 Series는 그럴 필요가 없다.
3. JSON 데이터로 바로 생성 가능
Dict type(JSON) 데이터를 통해 Series를 생성하면 Key값이 Index, Value값이 Data 공간에 저장되어 Series를 생성할 수 있다.
Series 생성 방법
Series(data={실제 Data List}, index = {index List},
dtype = {Sereis의 Data Type}, name = {Column 이름})DataFrame
DataFrame이란?
Series가 여러개 모여 Table 형식으로 표현된 데이터를 말한다.
Series가 모여만들어진 하나의 Data Tablel로써 위 사진을 보면 잘 나타나있다.
DataFrame 생성 방법
# Data를 한꺼번에 담고 싶을 때
pd.DataFrame({Data}, columns={Column 이름 List})
# Data를 각각 특정 Column에 넣고 싶을 때
pd.DataFrame({"Column 이름":"Data", "Column 이름":"Data",...})Pandas 활용법
- Pandas API : https://pandas.pydata.org/docs/reference/index.html
모듈 다운받기
- 꼭 pandas에서부터 Series, DataFrame에 관한 모듈을 다운 받은 이후 활용해야 함
from pandas import Series, DataFrameCSV에서 데이터를 읽어 DataFrame화 시키기
pd.read_csv({데이터 파일 경로 or URL}, sep={데이터 분리 문자}, header=None)- header
- Default로 CSV의 첫번째 행을 header(열 이름)로 지정해서 불러옴
- 불러올 데이터에 Header가 존재하지 않을 경우(즉, 첫 번째 행부터 Data일 경우) "header = None" Option을 주어 header가 없음을 명시해야 함
Data 출력 & 접근
N개 Data 출력
# 맨 위에서부터 N개 Data 출력
df.head(N)
# 맨 아래에서부터 N개 Data 출력
df.tail(N)Column Data(Series Data) 모두 불러오기
df["{Column Name}"]
df.{Column Name}- df[T]로 접근 할 경우, T가 Column Name이라면 Column으로 인식하지만, 그렇지 않을 경우 index Number로 인식한다. 상황에 따라 활용되는 방식이 달라 의미가 모호해질 수 있기 때문에 Column Name으로만 활용하는 것을 추천한다.
index Name을 통한 Data 접근
df.loc[N, {Column List}] - Row Data를 반환함
- Column List를 입력하지 않을 경우 : index name = N인 Row Data 모두 반환
Column List를 입력할 경우 : index name = N인 Row Data 중 Column List의 Series에 존재하는 Data만 반환 - N 위치에 숫자 뿐만이 아닌 Slicing 가능
index Number를 통한 접근
df[{Column List}].iloc[N]- N번째 Row Data 중 Column List에 해당하는 Series Data만 반환
- N은 숫자 뿐만이 아닌 Slicing 가능
index와 Value를 한번에 받아오는 방법
df.iteritems()- 출력값으로 (index, Value)를 반환
- Label이 여러개일 경우, Label 마다 (index, Value)를 구하여 반환함
DataFrame 정렬(Sorting)
df.sort_index() # index를 기준으로 Sorting. Default는 오름차순
df.sort_values(ascending=False)
# value를 기준으로 Sorting. ascending=False이므로 내림차순DataFrame 변경
df.data_columns = {Column List}- Column List에 저장된 값으로 Column 이름들이 모두 바뀜
df.index = {Index List}- Index List에 저장된 값으로 Index 이름들이 모두 바뀜
Series 삭제
del df[{Column List}]- DataFrame에서 실제로 Series를 삭제
- Column List에 해당하는 Series를 DataFrame에서 삭제
df.drop({Column List}, axis=1)- DataFrame에서 해당 Series들만 제외하고 나머지 Series들을 반환
- Column List에 해당하는 Series들을 제외하고, 나머지 Series들로만 DataFrame을 만들어 반환
- axis = 1이므로, 거름망은 왼쪽에서 오른쪽으로 이동하므로 Series 전체가 삭제 될 것이다
inplace Parameter
- inplace : Data 변환 결과를 원래 DataFrame에 적용할지를 결정하는 Parameter
inplace = True: Data 변환 결과를 DataFrame에 적용시켜 실제 DataFrame Updateinplace = False: Data 변환을 하여 DataFrame을 반환하되, 실제 DataFrame은 변화하지 않음
progress_apply
- 데이터 전처리를 위해 사용하는 메서드
- data에 존재하는 모든 Element들에 대하여 lambda function을 적용해 값을 바꿈
- Data는 Series 형태이거나 DataFrame형태여야 함
- numpy나 List등을 pd.DataFrame() 혹은 pd.Series()를 통해 전환한 이후 활용해야 함
- tqdm.panas()를 꼭 입력해야 활용할 수 있음
- 코드로 이해하기
import pandas as pd
from tqdm import tqdm
import numpy as np
df = pd.DataFrame(np.array([1,2,3]))
# pd.Series(np.array([1,2,3])으로 설정해줘도 괜찮다
tqdm.pandas()
# 꼭 붙여줘야지만 progress_apply를 활용할 수 있다!
df.progress_apply(lambda x: x**2)
# df에 존재하는 모든 값들에 대하여 lambda Function을 적용한다
# 결과값은 [1,4,9]가 나올 것이며,
# type은 위에서 DataFrame으로 지정했으므로 결과도 DataFrame일 것이다DataFrame Operation
연산 원리
같은 Column과 Index를 가진 공간에 저장된 Data에 대한 연산을 수행하는, 어떻게 보면 Element-wise Operation으로 봐도 될 것이다.
여기서 중요한 점은 우리는 Pandas의 장점으로 명시적 Indexing을 할 수 있다는 점을 말했다. 반대로 말하자면 Index Number(위치)가 같더라도 Index Name이 다르다면 같은 값으로 보지 않는다는 의미이며, 반대로 Index Number가 다르더라도 Index Name이 같다면 같은 Index로 본다는 것이다.
Column Name도 같아야 같은 값으로 본다는 사실은 자명하다.
그렇다면 한쪽만 Data를 가지고 있을 경우 어떻게 연산이 수행될까?
한 쪽 값이 값이 없기 때문에 어떤 연산이 수행되든 NaN으로써 DataFrame 공간을 채운다.
즉, 결과적으로 양 쪽 Matrix가 가지고 있는 Index와 Column들은 Operation 이후 Result Matrix에 전부 존재해야 한다는 의미이다.
(Result Matrix 또한 DataFrame 형태를 가짐)
추가로, axis를 지정해 줄 경우 Broadcasting에 의한 연산이 가능해진다.
코드 실행을 통해 확인한 Operation
- (Case 1) Shape가 같고, Column Name과 Index Name이 완전 일치
- 같은 공간에 저장된 Data끼리 연산 수행(Element-wise operation)

- 같은 공간에 저장된 Data끼리 연산 수행(Element-wise operation)
- (Case 2) Shape는 같지만 Column(혹은 Index) Name이 다름
- 2개 Matrix의 모든 Column과 Index는 보존되어야 하므로, 한쪽 공간에만 존재하는 data(한쪽에만 존재하는 Column이나 Index에 포함된 Data)에 대한 연산 결과를 NaN으로 처리하여 DataFrame 생성
- 아래 사진에서, df1은 "abc", df2="def" Column Name을 가지고 있으므로 모두 다르고, 따라서 연산 결과 "abcdef" Colum Name이 보존되어야 하지만 저장되는 값은 NaN이 될 것이다

- (Case 3) Shape는 다르지만, Column과 Index Name이 포함(혹은 교집합이 존재하는) 관계
- 같은 Column Name & Index Name에 존재하는 Data끼리만 연산이 수행되고, 나머지는 모두 NaN처리됨

- 같은 Column Name & Index Name에 존재하는 Data끼리만 연산이 수행되고, 나머지는 모두 NaN처리됨
- (Case 4) axis를 통한 Operation 축 설정
- Series + DataFrame Operation에서 자주 활용됨
- Series가 Broadcasting되어 DataFrame과 연산이 수행됨
- Broadcasting 된다 하더라도 Column Name이나 Index Name은 동일 해야 함
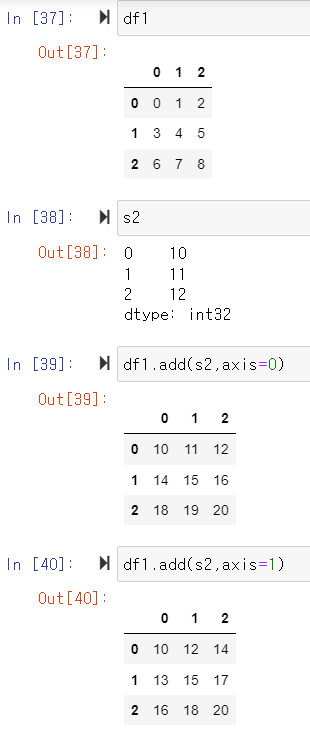
Map For Series
의미
Function이나 Dict, Sequence Data 등을 활용하여 DataFrame Series를 교체하거나 DataFrame에 Series를 추가하는 것을 가능하게 해주는 기능이다.
특정 Series(Column)을 선택하고, 해당 Column 값을 활용하여 DataFrame을 확장하거나 존재하는 값을 변경하는 기능을 수행할 수 있다.
중요한 점은, "Series" 관련 메서드이므로 Series에 대해 Mapping을 수행해줘야 하며, 이 때문에 특정 Column을 선택하는 경우가 많다.
활용법
df[{추가하거나 변경할 Column Name}] = {df Series}.map(T)
- T : function
- df Series Data를 Function에 통과시켜 나온 반환 값을 통해 Series를 Update 하거나 추가시킴
- lambda function이나 def를 통해 선언한 Function 모두 활용 가능
- T : Dict type data
- Key : Series에 저장된 값, Value : Key에 대응하여 DataFrame에 저장될 값
- {"man":1, "woman":2}일 경우, Series Data가 "man"일 때는 1이, "woman"일 때는 2가 저장되어 새로운 Series가 형성될 것이다
- 사진으로 보는 활용법
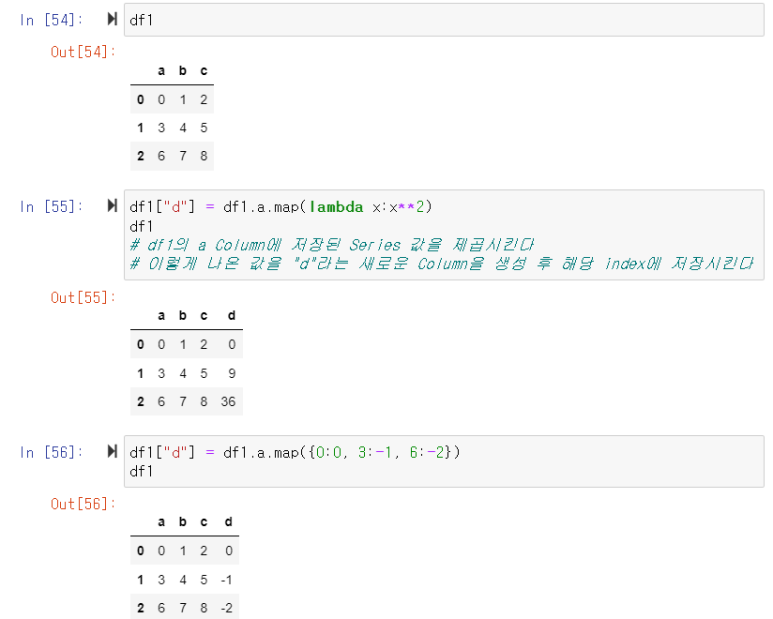
Replace For Series
의미
Map 기능 중 데이터 변환 기능만 담당하는 특별한 함수이다.
Replace로 가능한 기능은 Map으로도 수행할 수 있지만, Map은 "추가", Replace는 "변환" 기능만을 담당하게 하여 코드 보는데 조금 더 쉽게하기 위해 만든 함수가 아닐까 싶다.
inplace Parameter 활용이 가능하며, 활용할 경우 원본 DataFrame Update를 수행하며, 반대로 활용하지 않는다면 원본 데이터 자체는 변환되지 않는다.
활용법
{df Series}.replace([Target List], [Conversion List])
{df Series}.replace({Dict type data})
- df Sereis에서 Target List로 저장된(혹은 Dict type의 Key로 저장된) 값들을 Conversion List 값으로(혹은 Dict type Value 값으로) 변환
Apply
의미
Map은 Series에 포함된 Data 각각에 함수나 Dict type이 적용되었다.
하지만, 이 경우 Series 전체 합을 구하기 위해서는 값 하나씩을 추출하는 방법밖에 없을 것이다.
이런 Series 전체 값에 대한 연산을 수행하기 위해 활용되는 것이 Apply이다.
Map과는 다르게 Series 전체 원소에 대해 Function이 적용된다
특히, 내장 함수인 max, sum 등을 Function으로 활용할 수 있다는 점이 가장 큰 중요점이다
사용법
{DataFrame or Series}.apply(function)
- DataFrame이 입력 될 경우, 모든 Series에 대하여 Function을 수행함
- 직접 만든 Function 이외에도 sum, max, min 등 내장 함수 활용 가능
Built-in Function
-
df.describe()- Numeric Type의 요약 정보 반환
-
df[{Column Name}].unique()- Series Data의 정의역 반환
- 매우 많이 활용하는 기능이다
-
내장 함수
- axis Parameter 활용 가능
- sum(), mean(), max(), count(), median(), var() 등
{Series1}.corr({Series2}): Series1과 Series2의 상관 계수 수치 반환{Series1}.cov({Series2}): Series1과 Series2의 공분산 수치 반환{DataFrame}.corr(): 모든 Series 사이의 상관관계 수치 표시{DataFrame}.corrwith(Series1): DataFrame의 모든 Series와 Series1 사이 상관관계 수치 표현
-
df.sort_values({Column list}, ascending=True)- Column List를 기준으로 Sorting
- index가 작을 수록 Sorting 우선순위가 높음
- ascending = True : 오름차순, ascending = False : 내림차순
- Column List를 기준으로 Sorting
-
Series 원소별 개수
{Series}.value_counts -
pd.options.display.max_rows = x- x : Int형 데이터
- DataFrame을 출력할 때 최대 x줄 출력하게 하기 위한 Option 설정
GroupBy
GroupBy란?
- SQL의 groupby 명령어와 동일
- 동작 과정
- Split : Group 기준을 통한 분류
- apply : (주어진 Function에 대해서) 연산 수행
- combine : 연산 결과값들을 합쳐 하나의 DataFrame으로 생성
- 활용 방법
{DataFrame}.groupby({Column List})[{연산을 수행할 Column Name}].function()- Column List : Group의 기준이 될 Column List
- function() : sum(), max() 등의 내장 함수나 사용자 정의 함수
Hierarchical Index
Hierarchical Index 설명
groupby를 수행할 때 Column List에 2개 이상의 data가 포함될 경우, index도 2개 이상 존재하게 된다
이런 경우 계층 구조를 가지게 되는데, 이를 Hierarchical index라고 한다.
(ex) A, B를 기준으로 Group화 시켰을 때, A 기준으로 쪼개진 Data에
다시 B 기준으로 쪼개진 Data들이 있는 구조이다
만약 A 원소 개수가 2개, B가 4개라면 총 8개로 Data가 쪼개지는 것이다
Hierarchical Index 관련 메서드
- h_index x: Hierarchical Index 구조 데이터
- Hierarchical Index를 일반 DataFrame 형태로 만들기
- 가장 높은 우선순위의 Column이 index로, 낮은 것들이 Column으로 설정되어 Matrix를 형성
h_index.unstack() - index를 [0,1,2,..]로 지정하여 Matrix 형성
h_index.reset_index()
- 가장 높은 우선순위의 Column이 index로, 낮은 것들이 Column으로 설정되어 Matrix를 형성
- 일반 DataFrame을 Hierarchical Index 데이터로 만들기
h_index.stack() - Sorting
- 0번째 "Index"를 기준으로 Sorting
h_index.sort_index(level = 0) - Values를 기준으로 Sorting
h_index.sort_values()
- 0번째 "Index"를 기준으로 Sorting
- 0번째 Index(Group 기준)에 포함된 데이터의 합
h_index.sum(level=0)- std(), mean(), max(), min() 등의 함수도 활용 가능
Grouped
- Groupby에 의해 group화 된 Data
- Generator 형태 : for loop나 list화를 통해 데이터 출력 가능
- {Groupby 기준}:{Group에 저장된 Data} 형태로 데이터가 저장되어 있음
- 3가지 유형의 apply가 가능
- Aggregation : 요약된 통계정보 추출 => Key값 별로 요약된 정보
- Transformation : 해당 정보 변환 => 개별 데이터의 변환 지원
- Filtration : 특정 정보를 제거하여 보여주는 필터링 기능
- grouped : Group화 된 Data
- Aggregation
- Group화된 data를 더함
grouped.agg(sum) - 특정 Column에 여러 개의 Function을 Apply하여 그 결과값으로 DataFrame 생성
grouped[{Column List}].agg([Function List])- 내장 함수 : np.sum, np.mena, np.std 등
- Group화된 data를 더함
- Transformation
- Function의 결과 값을 통해 DataFrame 생성
grouped.transform({Function})
- Function의 결과 값을 통해 DataFrame 생성
- Filtration
gropued.filter({filter function})- Filter Function : Boolean 조건을 반환하는 Function
- True일 경우 해당 Group을 반환하고, False일 경우 해당 Group을 반환하지 않음
Pivot Table
Pivot Table
- Column에 Labeling 값을 추가하여 Aggregatoin을 수행하여 만든 Table
- DataFrame에서 특정 Column으로 분류한 이후 Index 리스트에 맞춰 Aggregation한 이후 Table 형태로 생성
- groupby를 통해 만들 수도 있지만, Pivot table을 통해 더욱 직관적으로 Table 형성 가능
- Pivot Table 형성 방법
{DataFrame}.pivot_table(values = {Aggreagtion을 원하는 Column Name}, index = [{Index로 만들 Column List}], columns= {Column으로 지정할 이름}, aggfunc = {Aggregation function}, fill_value = {Data가 없을 경우 Default로 채울 값} )- index + Columns로 지정한 Column들로 Group화 시킨다음, values에 지정된 Column에 aggfunc을 적용시켜 Table을 생성
- Groupby를 통한 위 코드 구현
{DataFrmae}.groupby([index + columns])[values].aggfunc.unstack()
CrossTab
- A와 B의 관계가 수치로 표현 가능한 데이터일 때 활용하면 좋음
- 두 Column의 교차 빈도, 비율, 덧셈 등을 구할 때 활용
- Pivot Table의 특수 형태
- CrossTab 형성 방법
pd.crosstab(index, columns,aggfunc).fillna({Value})- index : Index로 지정할 DataFrame의 Column Name
- Columns : Column으로 지정할 DataFrame의 Column Name
- aggfunc : index와 Columns에 지정한 Column들에 적용시킬 함수
- 내장 함수 활용 가능
- fillna({Value}) : NaN, 즉 계산 불가한 Data를 value로 채움(Default 값 설정)
Data 합치기
Merge
- 2개의 Data를 하나로 합침
- SQL의 Join과 매우 유사한 기능
- 활용법
- 일반적인 Merge
- df_a와 df_b에서 Merge시킬 기준이 되는 Column Name이 동일해야 함
pd.merge(df_a, df_b, on={Join 기준 Column Name})
- df_a와 df_b에서 Merge시킬 기준이 되는 Column Name이 동일해야 함
- Join시키고 싶은 Column Name이 다를 경우의 Merge
pd.merge(df_a, df_b, lef_on={df_a Column Name}, right_on = {df_b Column Name}) - How 설정을 통한 Join 종류 선택
- how = "inner" : Defult. Inner join 수행
- how = "left" : Left join 수행. 왼쪽 DataFrame 정보는 모두 출력되어야 함
- how = "right" : Right join 수행. 오른쪽 DataFrame 정보는 모두 출력되어야 함
- how = "outer" : Left join + Right Join. 모든 Data를 출력하는 Full Join 수행
pd.merge(df_a,df_b, on, how ="left")
- Index를 기준으로 Merge 수행
pd.merge(df_a, df_b, right_index = True, left_index = True)- Index 값을 기준으로 Merge가 수행됨
- DataFrame에 중복된 Column 이름이 존재할 경우, prefix에 DataFrame Name이 추가됨
- 일반적인 Merge
Concat
- "같은 형태"의 Data를 합치는 연산작업
- 활용법
- DataFrame "아래로" DataFrame 붙이기
pd.concat([{DataFrame 리스트}] df_a.append(df_b)- DataFrame "옆으로" DataFrame 붙이기
pd.concat([{DataFrame 리스트}], axis = 1)- axis = 1이므로 거름망이 왼쪽에서 오른쪽으로 이동하므로 오른쪽으로 DataFrame이 붙여짐
Data Persistence
- Database 연결하여 데이터 추출
import sqlite3
conn = sqlite.connect("DB 주소")
data1 = pd.read_sql_query({SQL Query}, conn)- Excel 형식으로 데이터 저장
- openpyxl, xlsxWriter 중 하나를 활용
writer = pd.ExcelWriter({Excel 파일 경로}, engine="xlsxwriter")
{저장시킬 DataFrame}.to_excel(writer, sheet_name={원하는 Sheet Name})- Pickle 활용
- 가장 일반적인 Python 파일 Persistence 방법
{DataFrame}.to_pickle({저장 시키고 싶은 Pickle Name})
df = pd.read_pickle({DataFrame을 저장한 Pickle Name})