
tqdm
- 프로그램 진행상황을 그림으로 볼 수 있게 해주는 파이썬 라이브러리
- 모듈 다운 :
from tqdm import tqdm - 파라미터
- iterable : 반복자 객체
- desc : 진행바 앞에 출력할 Text 지정
- total : 전체 반복량
- ncols : 진행바 컬럼길이
- ascii : Treu로 설정할 경우, #문자로 진행바가 표시됨
- mininterval : 업데이트 주기
- Iterable-Based
- iterable 객체를 tqdm()으로 감쌈
- 이터러블이 증가하는 것에 따라 진행률 증가
for i in tqdm(range(100), desc="Text", leave = True):
time.sleep(0.1)- Manual
- with 구문을 활용하여 수동으로 컨트롤
- update()로 수동으로 진행율르 증가시킴
with tqdm(total=100) as pbar:
for i in range(10):
time.sleep(0.1)
pbar.update(10)
- pbar.update() 명령어가 수행될 때마다 진행상황 막대가 Update됨
- 위 예시에선 10으로 설정했으므로, for문이 1번 돌 때마다 10씩 진행상황이 Update되며, for문이 10번 진행되므로 총 100의 진행상황까지 Update 될 것이다
- total=100으로 설정했다. range(10)에 tqdm을 했으면 Total이 10으로 설정되었겠지만, total=100이므로 막대는 100/100을 향해 진행된다.
LR Scheduler
- 학습 과정에서 Learning Rate를 동적으로 조절하는 것
- LR Scheduler Module 가져오기 :
import torch.optim as optim - 활용법
- 학습 시에는
optimizer.step()으로 학습 값을 적용시키고, scheduler.step()을 활용하여 Learning Rate를 Epoch마다 바꿔줌
- 학습 시에는
for epoch in range(args.epochs):
model.train()
matches = 0
for idx, train_batch in enumerate(train_loader):
inputs, labels = train_batch
optimizer.zero_grad()
outs = model(inputs)
preds = torch.argmax(outs, dim=-1)
loss = criterion(outs, labels)
loss.backward()
optimizer.step()
# Train시켜 Parameter를 Update시킴
# 이걸 해줘야 Scheduler도 Update 됨
scheduler.step()
# Optimizer가 다음 Epoch에서 활용할 Learning Rate로 바꿔주는 부분- Learning Rate를 확인하기 위해 생성한 메서드
def visualize_scheduler(optimizer, scheduler, epochs):
lrs = []
for _ in range(epochs):
lrs.append(optimizer.param_groups[0]['lr'])
scheduler.step()
# 학습 과정이 없으므로 Optimizer.step()은 생략해도 됨
plt.plot(lrs)
plt.show()torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma)- Step Size마다 Gamma 비율로 lr을 감소시킴
- step_size : 몇 Epoch마다 lr을 감소시킬 것인가
- MultiStepLR을 활용하여 Epoch을 직접 지정해 줄 수도 있음
epochs = 300
optimizer = optim.SGD([torch.tensor(1)], lr=0.1, momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.5)
visualize_scheduler(optimizer, scheduler, epochs)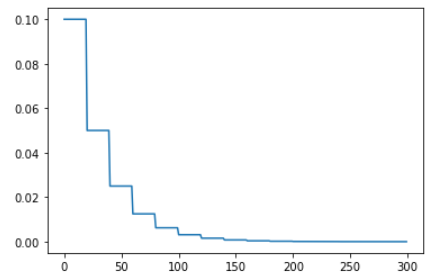
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min)- lr이 cos함수를 따라서 eta_min까지 떨어졌다 다시 초기 lr로 올라옴
- 변화를 급격하게 주어 Local minima 문제가 발생했을 때 빠르게 탈출 할 수 있게 해 줌
- T_max : 1번 Iteration이 수행될 때 걸리는 시간과 연관 있음
- CosineAnnealingLR 수식
- T_max값이 에 들어가는 것. 즉, T_max 값이 작을수록 한 번 Iteration 돌기 위한 이 더 커질 것이기 때문에, 총 Iteration 횟수는 적어질 것이다.
- CosineAnnealingLR 수식
- eta_min : 최소로 떨어질 수 있는 lr. Default = 0
epochs = 300
optimizer = optim.Adam([torch.tensor(1)], lr=0.1)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, \
eta_min=0)
visualize_scheduler(optimizer, scheduler, epochs)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, \
eta_min=0)
visualize_scheduler(optimizer, scheduler, epochs)
# 위 그래프가 T_max = 10, 아래 그래프가 T_max = 20인 그래프
# T_max = 20일 때 총 Iteration이 줄어들었음을 알 수 있다.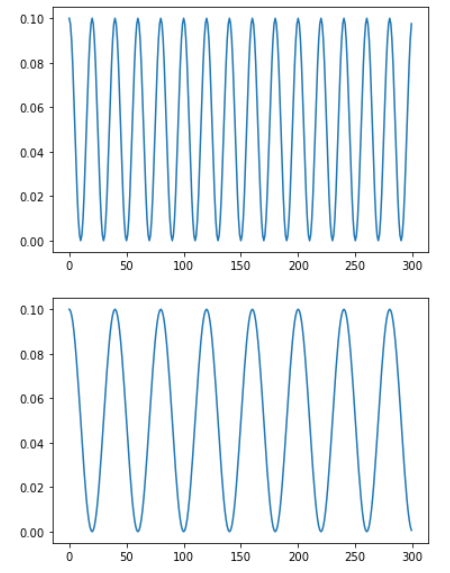
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode)- 성능 향상이 없을 때 lr 감소시킴
- 안정적인 학습을 위해 가장 많이 활용하는 방식
- scheduler.step({Metric})을 통해 Metric 값에 의하여 Update가 수행되도록 해야 함
- 즉, Parameter로 Metric(성능 측정치) 값을 전달해줘야 함
- mode : lr을 변경시키는 Mode 설정
- 'min' : Metric이 감소를 멈출 때마다 lr을 Update(min이므로 Metric이 작을수록 성능이 좋은 것이기 때문)
- 'max' : Metric이 증가를 멈출 때마다 lr을 Update(max이므로 Metric이 클수록 성능이 좋은 것이기 때문)
- factor : lr을 감소시킬 비율. Default = 0.1
- patience : Metric 향상이 안될 때, 몇 Epoch을 참을지 결정
- cool_down : lr이 감소한 후 몇 Epoch동안 lr scheudler 동작을 쉴지 결정
- min_lr : 최소 lr
- eps : 줄이기 전, 줄인 후 lr의 차이가 eps보다 작으면 무시(lr Update시키지 않음)
- 너무 작은 lr을 막기 위한 장치
"""
먼저, ReduceLROnPlateau는 Metric을 전달해야 함을 알고 있자
scheduler.step()에 Metric을 Parameter로 입력해줘야 하므로, 임의로
scheduler.step(1)로 전달해줬다.
"""
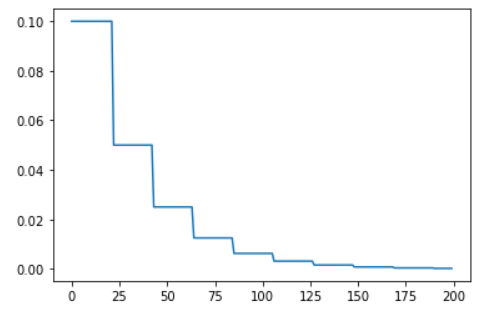
epochs = 200
optimizer = optim.Adam([torch.tensor(1)], lr=0.1)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min',\
factor=0.5, patience=20)
visualize_scheduler(optimizer, scheduler, epochs)
"""
사실상 항상 Metric이 1이므로 성능 향상은 이뤄지지 않는다.
patience=20으로 설정했으므로, 20 Epoch마다 lr Update가 이뤄질 것이다.
아래 그래프를 보면, 실제로 20 Epoch 주기로 lr이 Update됨을 볼 수 있다.
"""
- Warm-Up LR Scheduler
- 개념 : https://velog.io/@idj7183/Attention-TransformerSelf-Attention
- Warm-up Learning Rate Scheduler 참조
- 적용하기 위해서는 PyTorch Ignite를 활용해야 함
- 개념 : https://velog.io/@idj7183/Attention-TransformerSelf-Attention
- Warm-up LR Scheduler 활용 순서
!pip install pytorch-ignite: Pytorch Ignite 설치from ignite.handlers.param_scheduler import create_lr_scheduler_with_warmup: Warm-up 설정을 위한 Module import- 아래 코드처럼 Warm-up 적용
model = models.resnet18()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.5)
lr_scheduler = create_lr_scheduler_with_warmup(scheduler,
warmup_start_value=0.0,
warmup_duration=3,
warmup_end_value=1e-3)
"""
위에서 우리가 optim.lr_scheduler를 통해 설정해 준 lr Scheduler를
create_lr_scheduler_with_warmup에 먹여주는 방식으로 Warmup Scheduler를 활용
할 수 있다
warmup_start_value ~ warmup_end_value까지, warmup_duration만큼
선형적으로 증가시킨 뒤에 내가 지정한 lr_scheduler를 적용시킴
위에서는 0.0 ~ 1e-3까지 증가한 뒤 StepLR Scheduler가 실행될 것이다.
"""
lrs = []
lr_scheduler(None)
# 위 방식으로 진행하면 0.1 -> 0.0 -> ... -> 1e-3으로 lr이 변화된다.
# 즉, 초기 Optimizer의 learning Rate부터 출력되므로, 이 값을 버리기 위한 과정
for _ in range(100):
lrs.append(optimizer.param_groups[0]['lr'])
lr_scheduler(None)
plt.plot(lrs)
plt.show()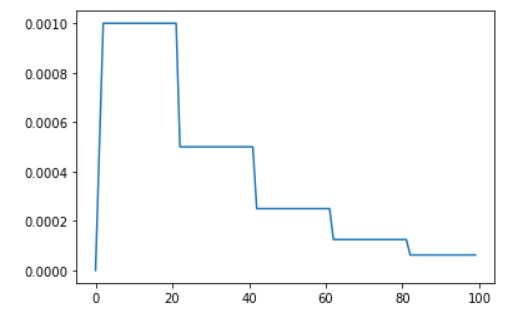
- 0 ~ 3 Epoch에서는 LR이 증가하다가, 이후 StepLR이 적용됨을 볼 수 있음
Timm
Pretarined Model을 활용하는법
- torchvision의 models
- 많은 Pretrained SOTA Model 지원
- 상대적으로 Update가 느림
- Timm
- 비교적 최신 모델을 사용할 수 있음
- 우리 문제에 맞게 Classifier를 변형하는 것도 Torchivision에 비해 매우 간단함
Timm 활용법
- Timm에 존재하는 Model들 : https://rwightman.github.io/pytorch-image-models/results/
- timm 설치 :
pip install timm - Pretarined Model Load하기
model = timm.create_model('{원하는 모델}', pretrained=True)- Classifier 변형하기
- 우리가 원하는 Model로 변경하는 것
- 즉, 마지막 Layer인 Classifier(Linear)의 out_features를 바꾸는 과정
model = timm.create_model('{원하는 모델}', pretrained=True,\
num_classes={Output Features})- 모델 선택에 도움을 주는 사이트
Optuna
- 최적의 HyperParameter를 찾아주는 Module
- 파라미터 범위를 주면, 그 범위 안에서 trials만큼 Test를 수행함
Optuna 설치
- Optuna 설치 :
pip install optuna
study 목적 함수 생성
-
Optuna는 Metric과 Train 과정을 모두 인자로 전달해주는 목적 함수가 필요
- 특정 함수를 생성하고, 이 함수에서 accuracy 등 Metric을 반환하도록 설정함
- 특정 함수에는 Train 과정 및 내가 원하는 후보군들에 대한 설정까지 해줘야 함
-
목적 함수 예시
def objective(trial):
model = ConvNet(trial).to(DEVICE)
# Optimizer Setting
optimizer_name = trial.suggest_categorical("optimizer",\
["Adam", "Adadelta","Adagrad"])
lr = trial.suggest_float("lr", 1e-5, 1e-1,log=True)
optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)
# optim에 Optimizer_name을, lr에 내가 지정했던 lr을 적용하는 구간
# 이렇게 내가 원하는 후보군들을 적용하여 optimizer로 넘겨줌
# optimizer는 특정 1개로 지정된 것이 아닌 후보 여러개가 존재하고 있는 상태
batch_size=trial.suggest_int("batch_size", 64, 256,step=64)
criterion=nn.CrossEntropyLoss()
# Get the MNIST imagesset.
train_loader, valid_loader = get_mnist(train_dataset,batch_size)
# Training of the model.
for epoch in range(EPOCHS):
model.train()
for batch_idx, (images, labels) in enumerate(train_loader):
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
# Validation of the model.
model.eval()
correct = 0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(valid_loader):
images, labels = images.to(DEVICE), labels.to(DEVICE)
output = model(images)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(labels.view_as(pred)).sum().item()
accuracy = correct / len(valid_loader.dataset)
trial.report(accuracy, epoch)
# Handle pruning based on the intermediate value.
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy<목적 함수에서 활용된 여러 가지 변수 설정 방법>
- 실험해 볼 Optimizer 및 lr 지정
- trial.suggest_categorical() : 리스트 범위 내에서 값을 선택함
- trial.suggest_uniform() : 범위 내에서 균일 분포 값을 선택함
- trial.suggest_float() : 범위 내에서 소수형 값을 선택함
- trial.suggest_int() : 정수형 값을 선택할 때 활용
- Batch Size를 지정할 때 주로 쓰임
- 이외의 trial : https://optuna.readthedocs.io/en/latest/reference/generated/optuna.trial.Trial.html#optuna.trial.Trial
- trial.report({기록할 Data}, {현재 epoch})
- trial.report(accuracy, epoch) : 현재 Epoch에 반환된 Accuracy를 저장함
- Pruning
- 만약, 더 이상 실험할 필요가 없다고 생각한다면(성능이 다른 실험보다 안 좋아질 것을 미리 예측할 수 있는 경우) 가지치기(Pruning)을 수행
- 즉, 안 좋은 실험에 대해서는 미리 끝내버리는 것
if trial.should_prune():
raise optuna.exceptions.TrialPruned()study 생성
- direction : 목적 함수가 반환하는 값의 방향을 지정
- maximize : 목적 함수가 반환하는 값이 커진다면 성능이 향상된 것. (ex) Accuracy
- minimize : 목적 함수가 반환하는 값이 작아진다면 성능이 향상된 것. (ex) Loss
import optuna
study = optuna.create_study(direction='maximize')- Optuna를 통한 실험 수행 :
study.optimize({목적 함수}, n_trials)- n_trials : Epoch. n_trials까지만 실험을 수행하고 이후로는 시행을 하지 않음
- 위 예시를 활용하면,
study.optimize(objective, n_trials=20)으로 활용 가능
- Study 중 가장 성능이 높은 실험 Data 가져오기 :
study.best_trial - 모든 Study 기록 가져오기 :
study.trialsstudy.trials_dataframe()을 통해 DataFrame형식으로 변환하여 결과값을 반환할 수도 있음
- Value 및 Parameter 값 가져오기
- 가장 성능이 높았을 때의 Value :
trial.value - 가장 성능이 높았을 때의 Parameter :
trial.params
- 가장 성능이 높았을 때의 Value :
Optuna를 활용한 시각화
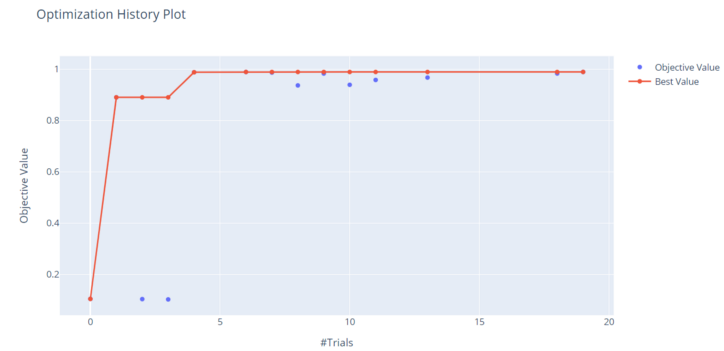
- Study History를 시각화 :
optuna.visualization.plot_optimization_history(study)
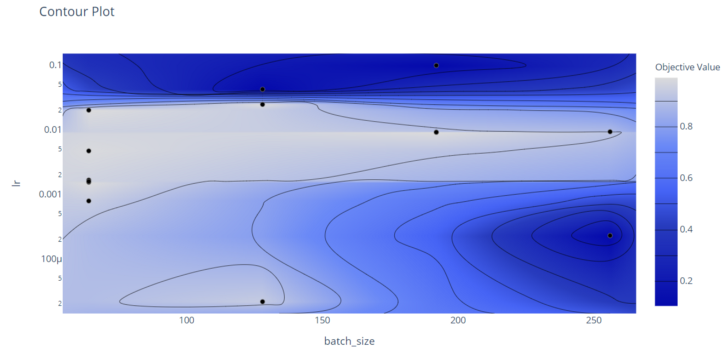
- Contour Plot을 활용하여 다른 HyperParameter 간 관계를 보여줌
optuna.visualization.plot_contour(study, params=['batch_size', 'lr'])- batch_size와 lr 사이의 관계를 Contour Plot으로 그림
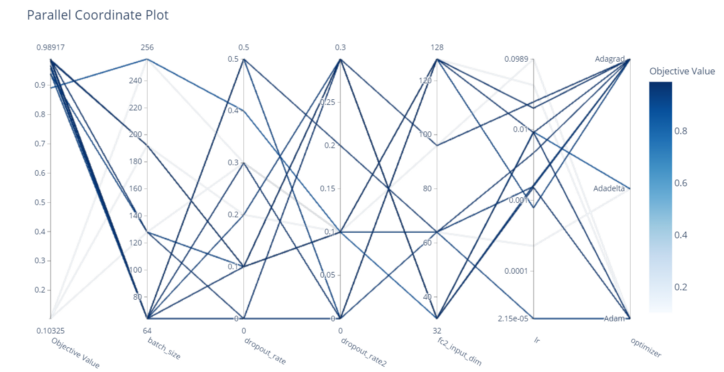
- 모든 HyperParametr간 관계를 Coordinate Plot으로 그림
optuna.visualization.plot_parallel_coordinate(study)
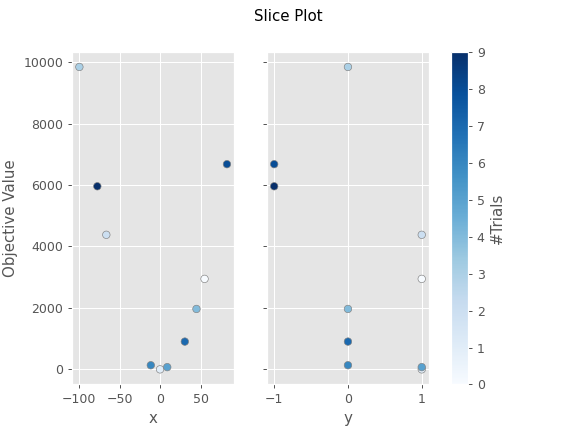
- 각 파라미터에 대한 최적의 공간을 Slice Plot으로 그림
fig = optuna.visualization.plot_slice(study, params=["x", "y"])- x,y가 Parameter인 실험에서 그릴 수 있는 차트
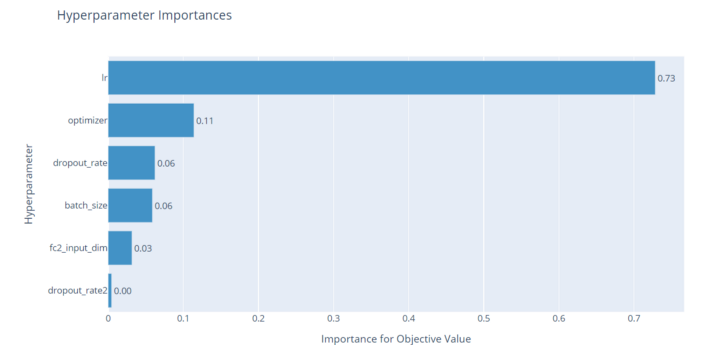
- HyperParameter 중요성(영향력)을 Bar Plot으로 그려줌
optuna.visualization.plot_param_importances(study)
Random_split
- Module 다운 :
from torch.utils.data import random_split - 데이터 나누기
- 아래 예시에서는 8:2로 데이터를 나눌 것이다.
train_data, val_data = random_split(train_dataset,\
[int(m-m*0.2), int(m*0.2)])이미지 출처
https://optuna.readthedocs.io/en/stable/reference/visualization/generated/optuna.visualization.matplotlib.plot_slice.html
https://ichi.pro/ko/optunalo-pytorch-haipeopalamiteo-jojeong-4883072668892

개념부터 확실히!