오늘 할 일
- KoBART를 활용한 한국어 Dialogue Summarization 만들어보기
오늘 한 것
데이터 얻기
- AI Hub에 Dialogue에 관련된 Data가 존재하여 이를 활용하기로 했음
데이터 형식의 차이
- json으로 데이터가 되어 있음
- 예를 들어 ["안녕", "안녕하세요"] 라는 대화가 있을 경우 SAMSum은 "P01:안녕\r\nP02:안녕하세요"의 형식으로 Dialogue가 되어 있지만, AI Hub 데이터는 "{utterance:안녕, Participant:P01}, {utterance:안녕하세요, Participant:P02}" 형식으로 되어 있음
- SAMSum은 데이터에 화자에 대한 정보가 없지만 AI Hub에는 대화 전체 개수, 화자에 대한 정보 등도 포함되어 있음
- 해당 대화에 대한 주제도 AI Hub에는 정리해 놓았다.
- 특정 논문(어떤 논문인지 기억이 안난다.... 그런 논문이 있었는데)에 대화에 대한 주제를 Input으로 추가시키면 더욱 Summarization을 잘한다는 것을 읽은 것 같아 나중에 활용해 볼 가치가 있을 것 같다.
데이터 형식에 이런 차이 말고 여러 다른 차이점이 존재하지만, 가장 눈에 띄는 차이점은 위와 같았다.
KoBART로 Dialogue Summarization 수행
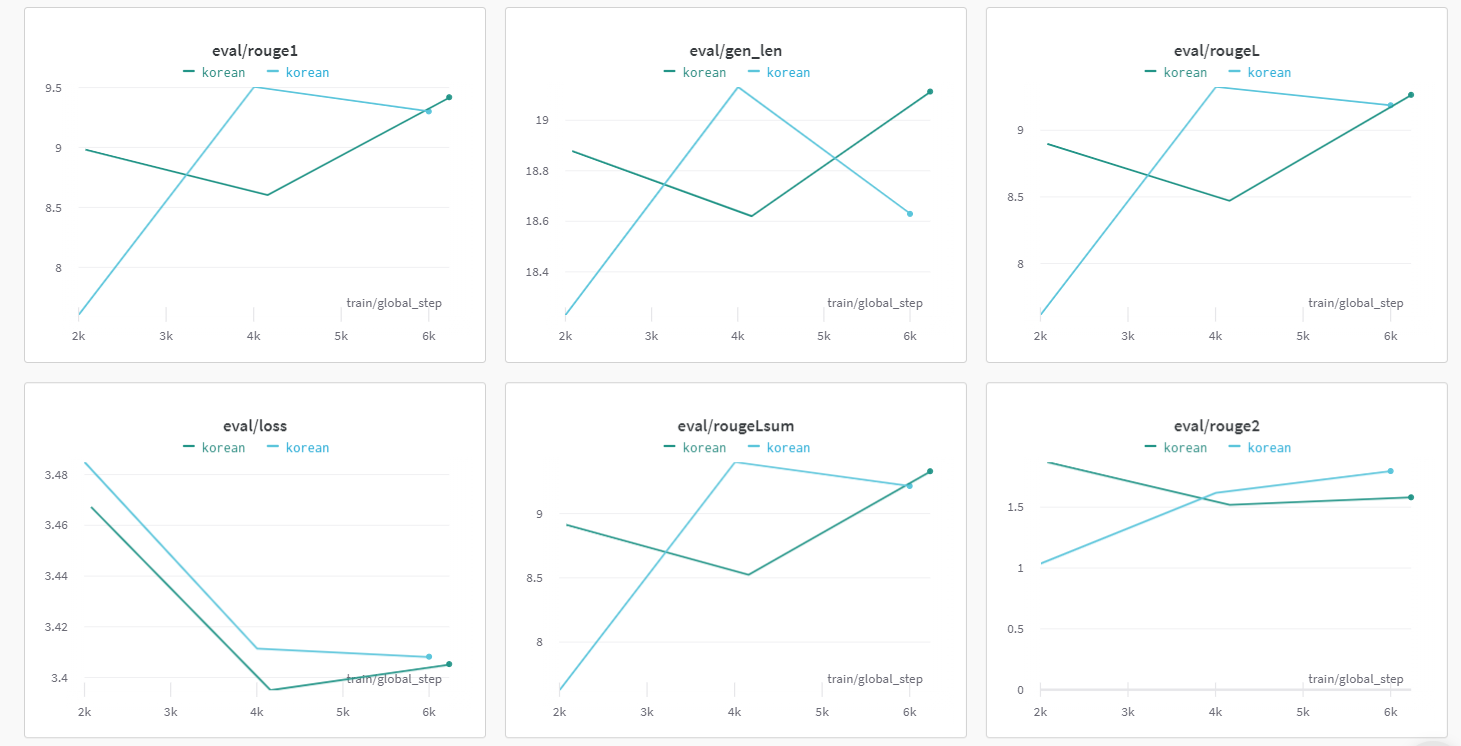
-
rouge가 10점을 못 넘어 가길래 나쁜 Model인 줄 알았지만, 결과를 보니 괜찮았다.
-
SAMSum 형식으로 AI Hub 데이터 형식을 바꾸기만 하고, Pretrained할 Model Name만 변경시키면 되는 작업이라 어렵지는 않았다.
-
문제점 : 한국어에 대해서는 ROUGE 점수가 좋은 Metric은 아닌 것 같다는 생각이 든다.
실제로 Rouge의 한계점은 RDASS 논문에도 설명되어 있다.
영어는 어떻게든 Rouge-2나 RougeL 등으로 처리할 수 있지만, 한국어는 ROUGE 점수가 높지 않을 것 같다라는 생각이 든다.
위 사이트에서 ROUGE Metric의 단점을 나타낸 문단을 가지고 왔다.
ROGUE의 한계는 한국어 문서 요약 태스크에서 더 도드라져 보입니다. 어근3에 붙은 다양한 접사4가 단어의 역할(의미, 문법적 기능)을 결정하는 언어적 특성을 갖춘 한국어에서는 복잡한 단어 변형이 빈번하게 일어나기 때문이죠. [그림 2]는 드라마 ‘슬기로운 의사생활’ 기사를 요약한 정답 문장과 모델이 생성한 요약 문장을 비교한 예시입니다. ROGUE는 정답 문장과 비교해 철자가 겨우 3개만 다른 오답 문장에 더 높은 점수를 부여합니다.
이런 부분에 대한 고찰이 이미 있었고, 특히 한국어에 대해 이런 부분이 부각되므로 이를 해결하기 위해 나온 RDASS Metric을 활용해보기로 했다.
느낀점
먼저 자화자찬 하고 가면 이번 코드를 짜는데 에러가 진짜 많이 안났다.
처음 Image Classification을 할 때와 비교해보자면 장족의 발전이 아닌가 싶다.
물론 BART라는 새로운 모델을 활용하였기 때문에 Seq2SeqTrainer를 활용해야 한다는 어려운 점이 있긴 했지만, 몇 번의 오류 없이 결과를 어느 정도 냈다는 점이 매우 기쁘다.
Dialogue Summarization은 이런 식으로만 가자! Project의 윤곽선이 보이는 것 같다
