오늘 할 것
- Dialogue Summarization Metric으로 활용해 볼 RDASS 코딩
오늘 한 것
RDASS에 관한 논문 읽기
SBERT
RDASS에서 제일 중요한 모델이다.
(사실, s(d, g)가 무슨 의미인질 이해 못해서 한참을 헤맸던 것 같다)
SBERT를 간단히 설명하자면 BERT 2개를 만들고, 각각의 모델에 다른 Setence를 넣어주는 것이다.
BERT 모델의 Output을 Mean-Pooling 시키고, 이렇게 나온 2개의 Output에 대해 Cosine-Similarity를 구하여 두 문장 사이의 유사도를 구하는 것이다.
(Dense Layer를 추가하여 Classification 문제도 해결할 수 있다고 나와 있지만, 우리는 Metric으로 활용하고 싶기 때문에 Cosien Similarity에 조금더 집중해 보기로 하였다)
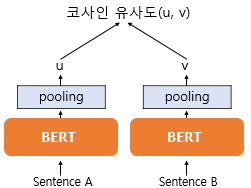
RDASS
SBERT에 2문장을 넣어야 하는데, A = (Dialogue, Golden Sumamry), B = (Dialogue, Prediction Sumamry)의 Cosine Similarity 값이라고 했을 때, 두 값을 평균 낸 것이 RDASS이다.
먼저, 개념 자체는 괜찮았던 것 같다. 점수를 구할 때 원본이 되는 "본문"에도 집중하여 점수를 구하기 때문에 더욱 점수가 괜찮아질 것이라고 생각한 것같다.
그런데, 우리 Task에는 맞지 않다고 생각했다.
먼저, 애초에 Dialogue가 Document가 아니기 때문에 Golden Summary를 통해 구한 Cosine Similarity 자체가 작다.
즉, A값이 작기 때문에 Golden Summary로 향하는 Prediction Summary의 방향성을 생각했을 때 B값도 작을 것이라고 판단했다.
따라서, Dialogue Summarization에는 적절하지 않다고 생각했다.
Dataset
KorSTS 관련된 데이터셋을 kakao-brain 팀에서 만들어 놓았기 때문에, 이를 활용하기로 했다.
Sentence-Transformer
처음에는 SBERT를 구현했었는데, 나중에 찾아보니 SBERT에 관련된 Library인 Sentence-Transformer가 존재하였다.
(좀 허무했지만) 그래도 이를 활용하니 쉽게 훈련이 되었고, 결과도 괜찮게 나와서 KorSTS로 학습한 SBERT 모델을 Metric 계산에 활용하기로 하였다.
고민점
위에도 말했듯, 이번 Task에는 RDASS가 그렇게 좋지 않은 Metric인 것 같다.
그런데, SBERT의 가장 큰 장점은 그냥 문장 2개를 넣으면 그 2개 문장의 Similarity를 구할 수 있다는 점이라고 생각하였다.
그렇다면, 굳이 Document를 활용할 필요가 있을까?
그냥 (Golden Summary, Prediction Summary) 사이의 Cosine Similarity만 구하면 될 것 같다
결론
팀원과의 회의를 통해 RDASS를 활용하기 보다는 SBERT의 Cosine Similariry를 활용하는 방식으로 Metric을 결정하기로 했다.
느낀 점
오늘은 구현은 했는데 의문점이 많이 드는 논문이였던 것 같다.
논문이라고 해서 맹신적으로 믿는 것 보다는, 정말 이 논문이 맞는가, 또한 논문이 왜 이런 아이디어를 냈는지를 파악하는 것이 좋은 것 같다.
