MySQL, MongoDB, BigQuery 등 많은 종류의 DB를 사용해보고 수많은 쿼리를 작성해보았지만, 정확히 아킥텍쳐와 실행원리를 뜯어본 적은 없는 것 같아 각각의 DB (MySQL, MongoDB, BigQuery에 대하여 알아보고 비교해보려고 합니다. 본 글은 RealMySQL 8.0, 그리고 말미에 언급되는 레퍼런스를 참고하여 작성되었습니다 :)
MySQL

MySQL은 가장 대표적인 RDBMS (관계형 데이터베이스) 시스템이라고 할 수 있다.
먼저 MySQL 공식문서에서 제공하는 대략적인 아키텍쳐는 아래 그림과 같다.
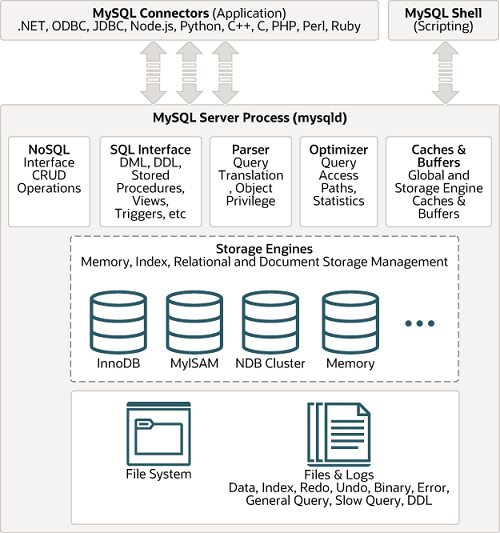
크게 MySQL 엔진(두뇌 역할)과 스토리지 엔진 (팔, 다리 역할)으로 분류할 수 있다.
MySQL 엔진에는 클라이언트의 요청을 처리하는 커넥션 핸들러와 쿼리파서, 전처리기, 옵티마이저 등이 있고, 스토리지 엔진에는 InnoDB (default) 엔진과 MyISAM 엔진이 있다.
쿼리 실행 구조
일단 우리가 파이썬에서 커넥션을 위한 라이브러리를 사용하든, Shell에 바로 접근하든 MySQL서버에서 쿼리를 실행할때의 과정은 아래와 같을 것이다.
- 쿼리파서: 쿼리 파서는 클라이언트 요청으로 들어온 쿼리를 토큰으로 분리하여 트리 형태의 구조로 만들어낸다. 기본적인 문접오류는 이 과정에서 발견된다.
- 전처리기: 위 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다. 실제 존재하지 않거나 권한 상 사용할 수 없는 개체의 토큰은 해당 단계에서 걸러진다.
- 옵티마이져: 요청으로 들어온 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정한다.
- 실행 엔진: 옵티마이저가 회사의 경영진이라면, 실행엔진은 중간관리자, 핸들러는 각 업무의 실무자로 비유할 수 있다.
- 핸들러 (스토리지 엔진): 핸들러는 MySQL 실행 엔진의 요청에 따라 데이터를 디스크를 저장하고 디스크로부터 읽어 오는 역할을 담당한다.
아래는 책에서 소개한 옵티마이저가 GROUP BY를 처리할 때, 임시테이블을 사용했다고 가정한 예시입니다.
- 실행 엔진이 핸들러에게 임시테이블을 만들라고 요청
- 다시 실행 엔진은 WHERE 절에 일치하는 레코드를 읽어오라고 핸들러에게 요청
- 읽어온 레코드들은 1번에서 준비한 임시 테이블로 저장하라고 다시 핸들러에게 요청
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 (예: GROUP BY) 데이터를 읽어 오라고 핸들러에게 다시 요청
- 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
MySQL 스레딩 구조
MySQL 서버는 스레드 기반으로 작동하며, 크게 포그라운드 스레드와 백그라운드 스레드로 구분된다.
실행 중인 스레드의 목록은 performance_schema 데이터베이스의 threads 테이블에서 확인할 수 있다.
포그라운드 스레드
포그라운드 스레드는 최소한 MySQL 접속된 클라이언트의 수만큼 존재하며, 주로 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리한다. 그래서 포그라운드 스레드를 클라이언트 스레드라고도 부른다.
클라이언트 사용자가 작업을 마치고 커넥션을 종료하면 해당 커넥션을 담당하던 스레드는 스레드 캐시로 되돌아간다. 이미 스레드 캐시에 일정 개수 이상의 대기 중인 스레드가 있으면 스레드 캐시에 넣지 않고 스레드를 종료시켜 일정 개수의 스레드만 스레드 캐시에 존재하게 한다. 이때 스레드 캐시에 유지할 수 있는 최대 스레드 개수는 thread_cache_size 시스템 변수로 설정한다.
포그라운드 스레드는 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져오며, 버퍼나 캐시에 없는 경우에는 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리한다. MyISAM 테이블은 디스크 쓰기 작업까지 포그라운드 스레드가 처리하지만, InnoDB 테이블은 데이터 버퍼나 캐시까지만 포그라운드 스레드가 처리하고, 나머지 버퍼로부터 디스크까지 기록하는 작업은 백그라운드 스레드가 처리한다.
백그라운드 스레드
앞서 언급한 것과 같이 백그라운드 스레드는 MyISAM과는 연관이 없는 사항이지만, InnoDB는 다음과 같이 여러 가지 작업이 백그라운드로 처리된다.
- 인서트 버퍼를 병합하는 스레드
- 로그를 디스크로 기록하는 스레드
- InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드
- 데이터를 버퍼로 읽어오는 스레드
- 잠금이나 데드락을 모니터링하는 스레드
위의 작업 중 가장 중요한 것은 로그 스레드와 버퍼의 데이터를 디스크로 내렸는 작업을 처리하는 쓰기 스레드이다. MySQL 5.5 버전부터 데이터 쓰기 및 읽기 스레드의 개수를 2개 이상 지정할 수 있게하여, innodb_write_io_threads와 innodb_read_io_threads 시스템 변수로 스레드의 개수를 설정할 수 있다. InnoDB에서도 데이터를 읽는 작업은 주로 포그라운드 스레드에서 처리되기 떄문에 읽기 스레드는 많이 설정할 필요가 없지만 쓰기 스레드는 아주 많은 작업을 처리하기 때문에 일반적인 내장 디스크를 사용할 때는 2~4 정도, DAS나 SAN과 같은 스토리지를 사용할 때는 디스크를 최적으로 사용할 수 있을 만큼 풍분히 설정하는 것이 좋다고 한다.
사용자의 요청을 처리하는 도중 쓰기 작업은 버퍼링되어 처리될 수 있지만, 읽기 작업은 절대 지연될 수 없다. 책에서는 사용자가 SELECT 쿼리를 실행했는데, 10분 뒤에 결과를 돌려주겠다하는 데이터베이스는 없다는 예시를 들어 설명한다.
그래서 일반적인 DBMS에는 대부분 쓰기 작업을 버퍼링해서 일괄 처리하는 기능이 탑재돼 있으며, InnoDB 또한 이러한 방식으로 처리한다.
InnoDB에서는 INSERT, UPDATE, DELETE 쿼리로 데이터가 변경되는 경우 데이터가 디스크의 데이터로 완전히 저장될 때까지 기다리지 않아도 된다.
그러나, 앞서 포그라운드 스레드에서 설명했다시피 MyISAM 엔진은 포그라운드 스레드가 쓰기 작업까지 함께 하고, 일반적인 쿼리는 쓰기 버퍼링 기능을 사용할 수 없다.
MongoDB

MongoDB는 대표적인 NoSQL중 하나이다. 나또한 토론 채팅 서비스를 구축하면서, 또는 업무에서 빠르게 비정형 데이터 위주로 구성된 DB 구축하고 싶을 떄 사용하였던 데이터베이스이다. 아무래도 objectid를 사용하여 어플리케이션 서버에서 1대1로 매칭할 수 있으므로 빠른 개발이 가능한 것 같다.
일단, MongoDB의 기본적인 구성은 아래와 같습니다.
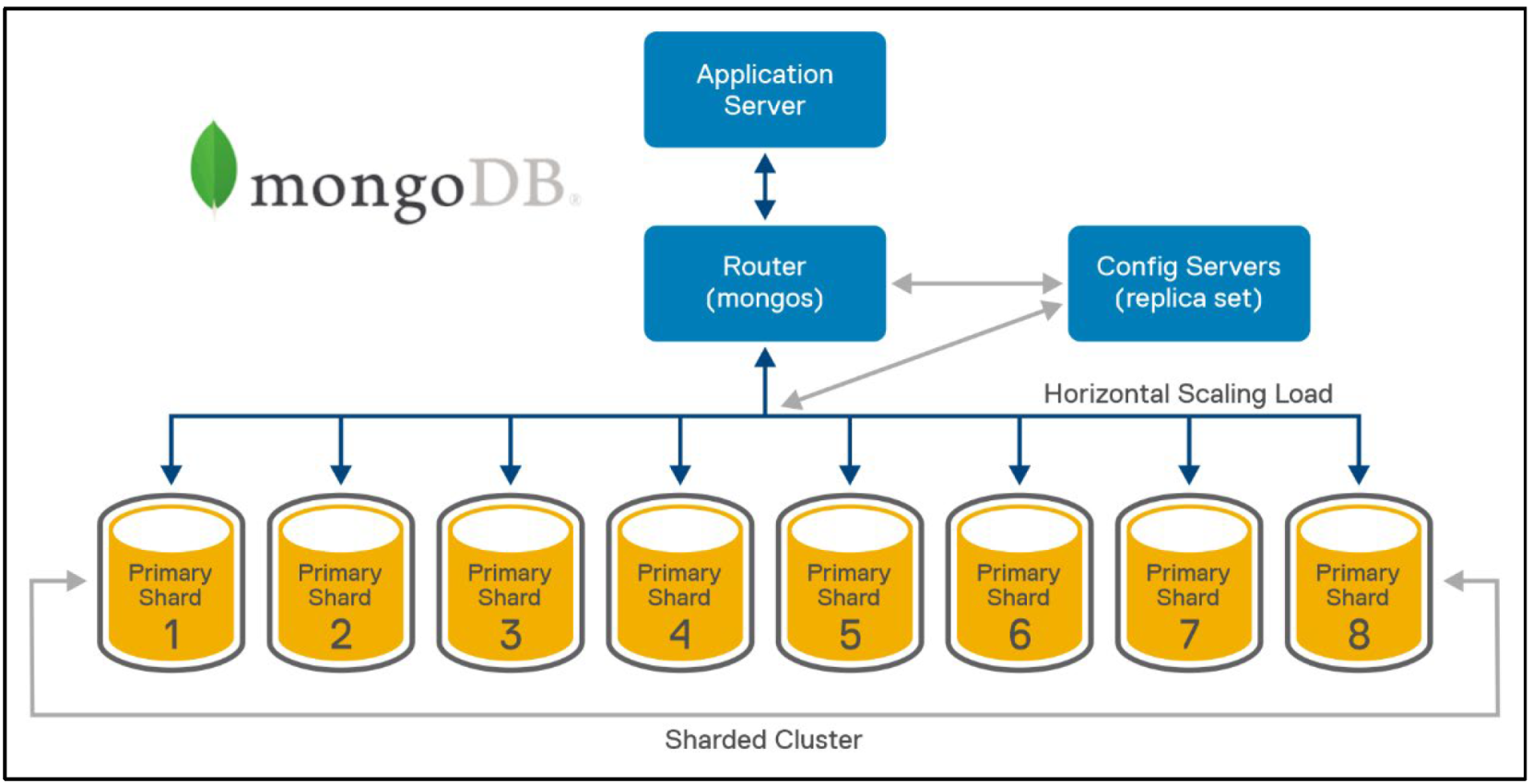
- Config 서버: 중개자 계층, 샤딩을 위한 메타 데이터를 저장한다. (데이터들의 위치 정보를 저장)
- Mongos 서버: MongoDB의 중개자 역할, Config 서버의 메타 데이터를 이용해 각 MongoDB에 데이터 접근을 도와준다.(라우터와 같은 역할)
- Mongod 서버: MongoDB의 데이터 서버로써, 서버 장애에 대비해 MongoDB 서버 안에 여러 개의 리플리카 셋 구조로 구성되어 있다.
What is DocumentDB?
일단 MongoDB는 도큐먼트 데이터베이스라고 보통 불린다. 표면적으로는, JSON 형식으로 데이터를 관리하고, 도큐먼트 단위로 데이터를 저장하기 때문일 것이다.
보통, 도큐먼트는 관계를 가지는 데이터를 중첩 도큐먼트와 배열을 사용하여 1개의 도큐먼트로 표현한다.
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"courses": ["Math", "Science", "History"],
"address": {
"street": "123 Main St",
"city": "Anytown",
"zipcode": "12345"
}
}BSON 형식
JSON은 구문 분석 속도, 타입 명확성 부족, 공간효율성 등의 면에서 단점을 가지고 있다.
따라서, 위와 같은 단점을 보완하기 위해 MongoDB는 BSON (Binary JSON) 형식을 도입하였다고 한다.
그 결과, MongoDB에서 우리가 눈으로 데이터를 확인할 때는 JSON으로 보이지만, 나머지 상황에서는 모두 BSON 형태로 저장하고 전송한다고 한다. (MongoDB 초기에는 모두 JSON으로 관리하였다고 한다)
BSON의 장점
BSON(Binary JSON)은 JSON의 단점을 보완하기 위해 고안된 바이너리 형식의 데이터 포맷이다. BSON은 다음과 같은 장점을 가지고 있다.
1. 빠른 구문 분석 속도
- BSON은 이진 포맷이기 때문에, 컴퓨터가 데이터를 읽고 해석하는 데 더 효율적입니다. 이진 데이터를 직접 읽고 필요한 위치로 이동할 수 있기 때문에 구문 분석 속도가 빠르다.
- BSON은 데이터를 타입과 함께 저장하므로, 파싱 시 데이터 타입을 명확히 알 수 있어 추가적인 변환 과정이 필요 없다.
2. 공간 효율성
- BSON은 데이터 타입 정보를 포함하여 저장하므로, 숫자, 날짜, 바이너리 데이터 등을 효율적으로 저장할 수 있다.
- 키 이름을 길게 반복하는 대신, BSON은 짧은 형식으로 데이터를 저장하여 공간을 절약할 수 있다.
- BSON은 정수, 부동 소수점 등의 숫자 데이터를 효율적인 이진 형식으로 저장한다. 예를 들어, 정수 1234는 4바이트로 저장되며, 이는 텍스트 형식보다 공간 효율적이다.
아래는 카카오 개발 컨퍼런스에서 MongoDB에 대하여 발표한 내용을 중심으로 정리한 글입니다. MongoDB 개념을 이해하고, 실제 카카오에서는 어떤 방식으로 MongoDB를 사용하는지 소개하는 유익한 영상이므로 MongoDB 입문자라면 한번씩 보시는걸 추천드립니다 :)
https://tv.kakao.com/channel/3693125/cliplink/414072595
MongoDB의 특징
MongoDB의 4가지 특징 (신뢰성, 확장성, 유연성, 인덱싱 지원)을 가지고 있습니다.
Reliability: 서버 장애에도 서비스는 계속 동작
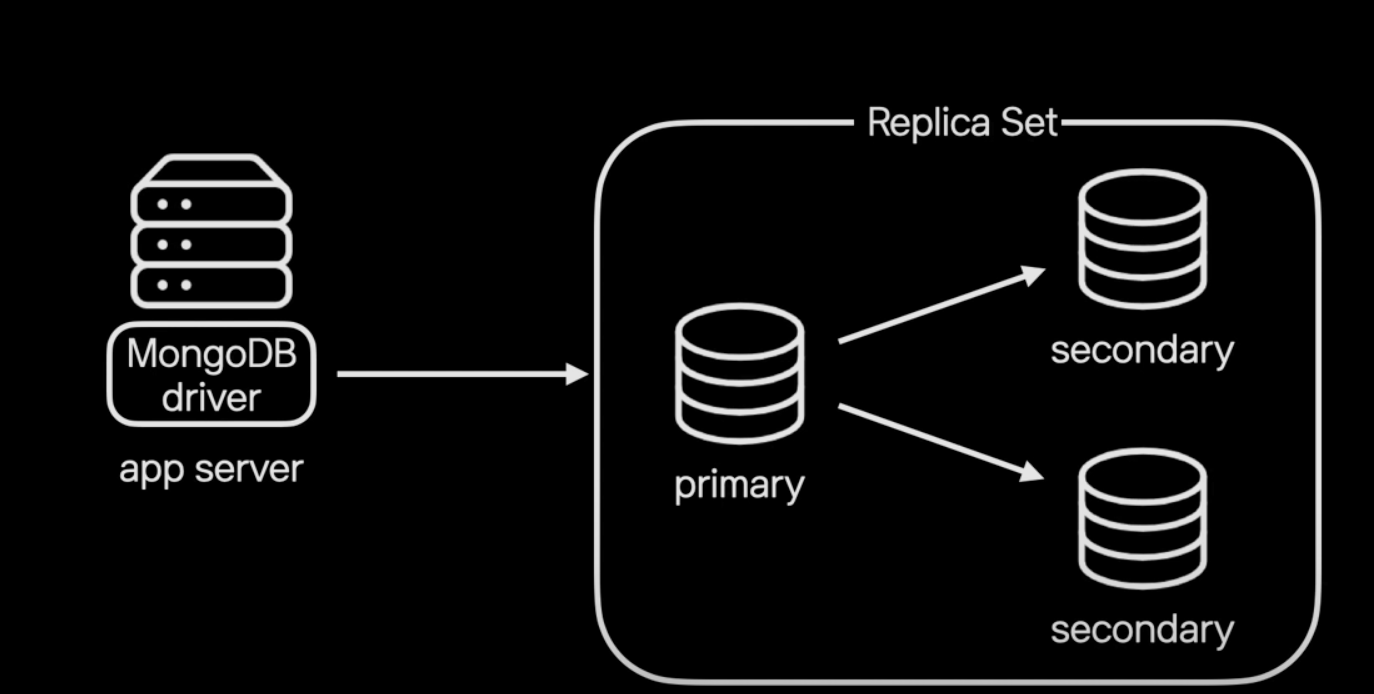
일반적으로 MongoDB는 1개의 primary와 2개의 secondary로 구성된 레프리카셋 구조를 가지고 있어 데이터 복제와 고가용성을 구현하기 때문에 장애로부터 안정된 상태를 유지한다. (primary, secondary는 master나 slave라는 용어로도 쓰이기도 한다)
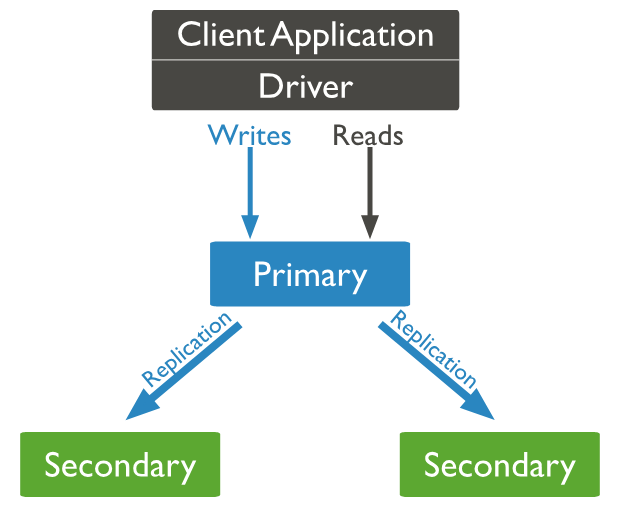
만약 primary에서 장애가 발생하면 secondary가 primary가 된다. 따라서, 어느 한 서버에서 장애가 발생해도 데이터 유실을 막을 수 있고 application 서버는 별도로 이에 대한 처리를 하지 않아도 된다!
Scalability: 데이터와 트래픽 증가에 따라 수평확장 가능
MongoDB는 데이터 증가로 더이상 하나의 레플리카셋에 못담을 상황일 때, 데이터를 샤딩하여 분산 시켜준다. 또한, 이러한 과정이 서비스 중단없이 온라인으로 진행된다.
사실 MongoDB에서 auto-sharding을 지원한다고 했을 때 구체적으로 어떤 것을 의미하는지 몰랐는데, 이러한 점을 뜻하는 것으로 보인다)
위와 같은 과정을 용어로는 밸런싱 기능이라고 하는데, 이는 특정샤드에 데이터가 몰리면 다른 샤드로 데이터를 옮겨 전반적으로 모든 샤드가 균등하게 데이터를 저장할수 있게 하는 것을 뜻한다.
또한, 온라인상에서 데이터를 밸런싱하기 때문에 단일 레플리카셋에서 샤드로의 온라인 전환이 가능하며, 샤드의 확장 축소 모두 온라인에서 진행할 수 있다.
위에서 MongoDB의 구성에 대하여 언급하였는데, 구체적으로 어떤 과정으로 샤드클러스터에서 데이터를 다루는지 살펴보자.
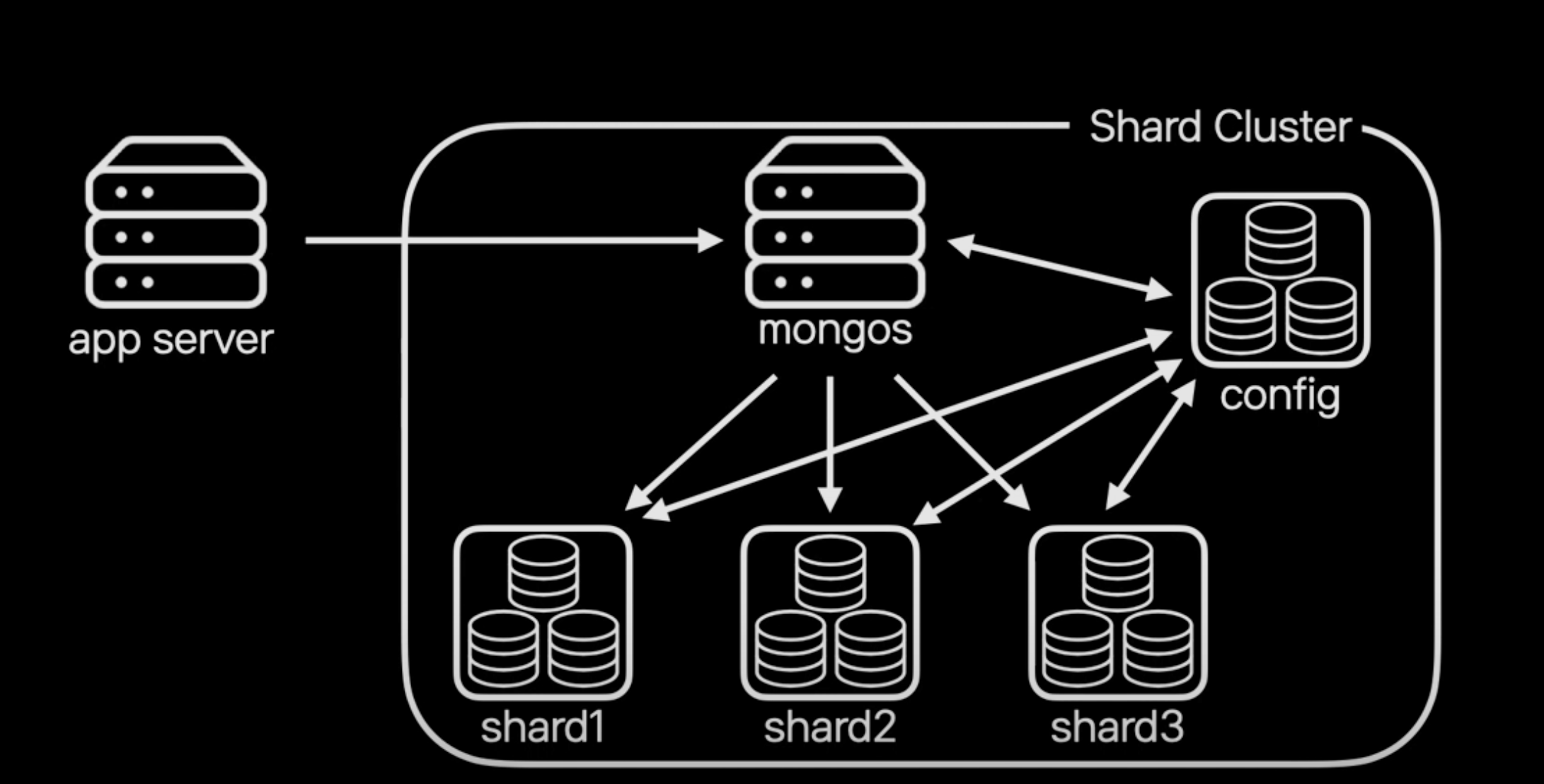
- 샤드 클러스터에 저장되는 실제 데이터는 각 샤드 1, 2, 3에 나누어 저장
- 어떤 데이터가 어떤 샤드에 있는지는 config 서버에 저장
- application 서버는 mongos 서버를 통해 샤드 클러스터에 접근
- mongos 서버는 config 서버와 통신하여 요청받은 데이터가 어느 샤드에 있는지 확인하고 해당 샤드에서 데이터를 조회하여 application에 전달
application단에서는 샤드 클러스터 내부 동작을 알 필요없이 위와 같은 일련의 과정을 mongos 서버에서 알아서 해주기 때문에, application에서의 접근을 쉽게 만들어 준다.
Flexibility: 여러가지 형태의 데이터를 손쉽게 저장
MySQL과 같은 RDBMS의 경우, 새로운 특성을 추가하려면 컬럼을 별도로 추가해야 한다.
그러나, MongoDB는 스키마를 제공하지 않으므로 데이터 변경에도 유용하게 대처 가능하다.
예를 들어, 고객의 핸드폰 번호를 담는 테이블이 있을 때 기존에 없던 기기 OS 정보를 추가하고 싶을 때 혹은 핸드폰이 여러개일 때, 테이블을 따로 추가하지 않고 배열로 그냥 담아버리면 된다.
참고로 RDMBS에서의 데이터 단위와 MongoDB에서의 데이터 단위에 대한 대응관계는 아래와 같다.
| RDBMS | MongoDB |
|---|---|
| Database | Database |
| Tables | Collections |
| Rows | Documents |
| Columns | Fields |
이와 같은 특성으로, MongoDB는 데이터 구조를 한눈에 볼수 있고 application에서 다루는 객체와 1대1대응 관계로 이루어져 있어 개발자는 쉽게 데이터를 이해하고 빠르게 개발할 수 있다.
Index Support: 다양한 조건으로 빠른 데이터 검색
보통의 NoSQL에서는 데이터를 찾고 분산할 목적으로 키(PK)를 한개만 제공한다.
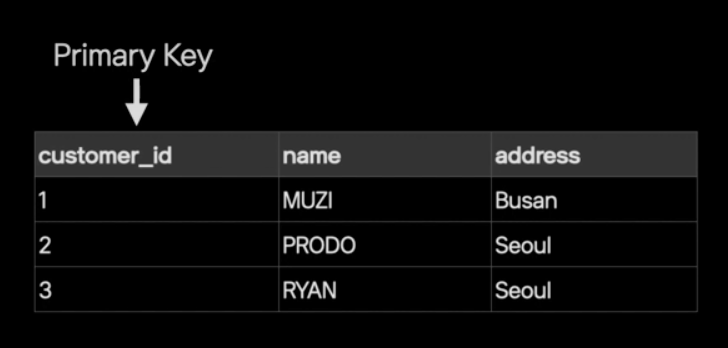
nosql에 customer_id를 PK로 지정한다고 가정하면, 데이터는 여러 서버에 customer_id를 기준으로 나누어서 저장할 것이다. 때문에, 특정 id값으로 검색하면 데이터가 저장된 서버를 알 수 있고 바로 조회가 가능하다. 그러나, 이름을 기준으로 검색할 상황이 있을 때는 해당 데이터 (정확히는 documents)가 어느 서버에 위치하는지는 모르기 때문에 모든 서버를 검색해야 하고, 대용량 데이터일 경우 비용은 매우 클 것이다.
MongoDB의 다양한 인덱스 제공 기능은 위와 같은 이슈를 방지할 수 있다.
필요한 필드에 필요한 만큼 인덱스를 생성할 수 있으므로, 위 예시의 경우에는 이름 field에도 인덱스를 생성하여 데이터를 빠르게 찾을 수 있다.
MongoDB가 제공하는 다양한 형태의 인덱스는 아래와 같다.
- Hashed 인덱스: 샤드 클러스터에서 데이터를 균등하게 분산하고자 할 때 사용하는 인덱스
- TTL 인덱스: 제한시간을 설정하여 오래됀 데이터를 자동으로 지워주는 인덱스; 보관 기간이 정해진 데이터는 어플리케이션에서 굳이 관리 하지 않아도 된다.
- Geospatial 인덱스: 공간 내의 거리나 범위를 다루기 위해 사용하는 일종의 공간 인덱스; 카카오 모빌리티 서비스에서 사용한다.
- Multikey 인덱스, Partial 인덱스...etc
사용사례
해당 발표에서 MongoDB의 여러 사용사례를 보여주었는데, 대용량 로그 저장 및 조회를 위해MongoDB를 도입한 사례와 MySQL에서 MongoDB로 이전한 사례가 MongoDB의 이해에 매우 도움될 것 같아 본 글에서 소개드리려고 합니다 :)
대용량 로그 저장 및 조회를 위한 MongoDB를 도입
보통, 사용자의 요청은 로그로 저장되며 통계를 분석하여 서비스 개선에 활용하는데, 통계를 계산할 시에 특정 기간에 대한 전체 데이터를 읽는 용도로 HBase가 많이 사용됩니다.
하지만, 통계가 아니라 이름이나 물품명으로 등으로 검색해야 할 시에, HBase는 PK만 지원하므로 키가 걸리지 않은 데이터라면 전체 데이터를 읽어야 하고, 이는 높은 비용을 발생시킬 가능성이 농후합니다.
위와 같은 상황에서, MongoDB를 도입하여 필요한 필드에 필요한 만큼 인덱스를 부여할 수 있기 때문에 대용량 데이터가 있어도 빠르게 데이터를 찾을 수 있습니다.
따라서, application에서 로그를 저장할 때 MongoDB에 저장하거나, HBase의 로그데이터를 주기적으로 MongoDB에 업데이트하면 관리자가 다양한 조건으로 원하는 데이터를 빠르게 조회할 수 있습니다.
DB 이전 사례 (MySQL → MongoDB)
사내 서비스 중 서비스가 확장되면서 기존의 MySQL로 유지하던 서비스의 한계점이 아래와 같이 나타났다고 합니다.
- 상품데이터와 로그데이터의 혼재
- 수TB의 디스크 -> Scale-Up 한계
- 테이블 당 수백 GB -> 스키마 변경시마다 10시간 이상 소요
아무래도 RDBMS 특성 상 마지막 한계점은 극복하기 어려우므로 NoSQL로의 이전은 불가피 했을 것으로 보인다. 따라서 MongoDB로 이전하였고, 아래와 같은 성과를 보였다고 합니다.
- 로그데이터 이관 -> 63% 압축률
- 스키마 변경 부담 제거
- 샤드 클러스터 구성 -> 서비스의 확장에 따라 유연하게 Scale-Up
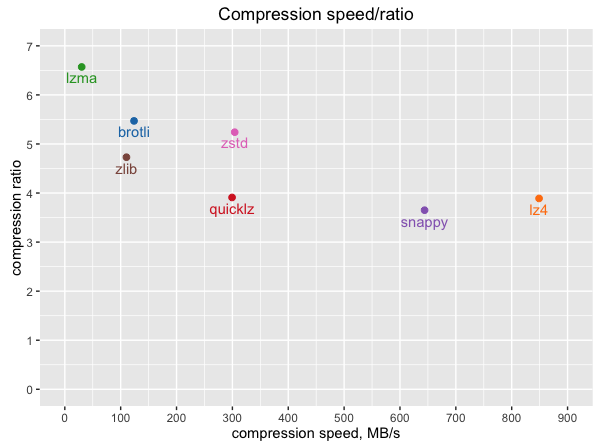
아마 압축 방식은 default로 방식을 사용하였다고 했는데, 아마도 snappy 방식 일 것이다. 아래는 MongoDB에서 지원하는 여러 압축 방식인데, MongoDB는 snappy 방식이 기본값으로 설정되어있다.
BigQuery

BigQuery는 RedShift, Snowflake와 같은 데이터웨어하우스 솔루션 중 하나로, 그 중 현재 가장 많이 쓰이는 시스템이라고 볼 수 있다.
데이터웨어하우스는 대용량 데이터를 처리하기 위한 빅데이터 기반 데이터베이스 이므로, 굳이 데이터의 양이 크지 않다면 사용하지 않아도 된다. (오히여, 성능 저하가 올 수 도 있음)
BigQuery의 표면적인 특징은 아래와 같습니다.
- SQL로 데이터 처리 가능 (Nested fields, Repeated fields)
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- 구글 클라우드 내의 다른 서비스들과 연동이 쉬움
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 스키마 변경도 유연하게 대처 가능
사실 대부분의 클라우드 기반의 데이터웨어하우스 솔루션들은 위 특징들을 만족한다. 특히 3번째 특징인 동일한 클라우드 내에서 다른 서비스들과 연동들이 쉬운 부분이 개발 생산성에 큰 기여를 한다. 예를 들어, AWS내에서 AWS Athena + S3 + RedShift 조합이나, GCP내에서 Cloud Storage + BigQuery + Cloud Scheduler 조합을 사용하여 파이프라인을 구축한다면 리소스 소모가 매우 줄어들 수 있다.
물론, 필요성과 성능 및 비용을 고려하여 파이프라인 구성을 제작하는 것이 선결과제 임을 잊으면 안된다 :)
다음 step으로 넘어가기 전에, BigQuery를 사용할 때 알고 있으면 좋은 2가지를 설명해보려고 합니다.
- PK 제공 X: 보통의 데이터웨어하우스 솔루션들은 동일한 사항인데, RDBMS와 같이 인덱스나 PK와 같은 키는 제공되지 않는다. 애초에 대용량 처리를 위한 데이터웨어하우스 설계 목적에 반하기 때문이라고 생각된다. 따라서, 보통 Full scan으로 진행됩니다.
- Delete 불가: BigQuery는 Delete문을 지원하지 않고, append 하는 것만 지원한다. 따라서, 한번 입력된 데이터는 변경되거나 삭제될 수 없습니다. 나 또한 실제로 BigQuery를 사용하며 필드를 잘못 추가하여 데이터가 몇개 유입되는 바람에 테이블을 지우고 다시 생성한 적이 있다ㅠ 근데, BigQuery는 Update문도 지원하지 않는다고 들었는데 나는 얼핏 단발성으로 사용했던 기억이 있는 것 같은데...? 추후에 관련 경험을 공유해보겠다 :)
그럼 왜 기존의 데이터베이스를 쓰지 않고, 데이터 웨어하우스를 꼭 사용해야 하는걸까?
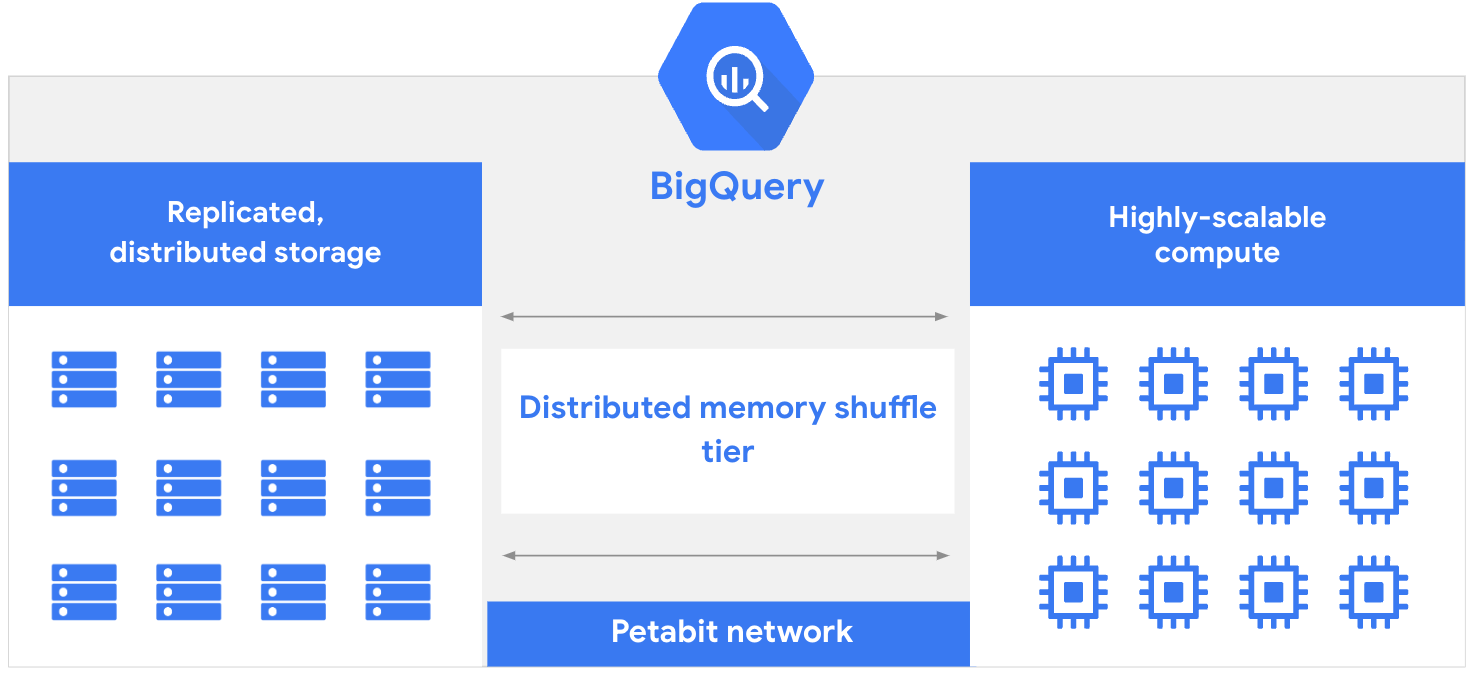
기존 데이터베이스는 읽기/쓰기 작업과 분석 작업에서 리소스 충돌이 발생할 수 있지만, BigQuery는 컴퓨팅 레이어와 스토리지 레이어를 분리하여 각 레이어가 독립적으로 성능과 가용성을 유지하며 동적으로 리소스를 할당할 수 있기 때문이다.
또한, BigQuery 스토리지는 고가용성을 위해 여러 위치 간에 자동으로 복제됩니다. 물론, 이 부분은 MongoDB도 유사한 특징을 가지고 있다.
그렇다면, 이제부터 구체적으로 왜 BigQuery가 대용량 데이터에 적합한 솔루션인지 3가지 특징을 통해 알아보자. 아마, 클라우드 기반의 데이터웨어하우스 특성에 대한 전체적인 이야기가 될 수 있다.
열 기반 스토리지 (Columnar Storage)
이해하기 쉽게 RDBMS를 사용하는 사례를 하나 가정해보겠습니다.
만약, MySQL에서 아래의 쿼리를 실행한다고 생각해보자.
select product_id, client_id
from payment_table
where ~~~~
아무리 특정 컬럼을 select하고 where에 조건을 걸었다 하더라도, 일단 SSD에서 테이블 전체를 읽어와서 메모리에 올린 다음에 attribute를 필터링한다는 것을 알고 있을 것이다. 이때 발생하는 I/O 부담을 줄이려고, 우리는 보통 partitioning을 사용한다. 어쨋든, 이러한 이슈가 발생하는 이유는 일반적으로 RDBMS가 Row 기반으로 설계되었기 때문일 것이다. (필요한 컬럼만 똑딱떼어올 수 없다는 뜻이다)
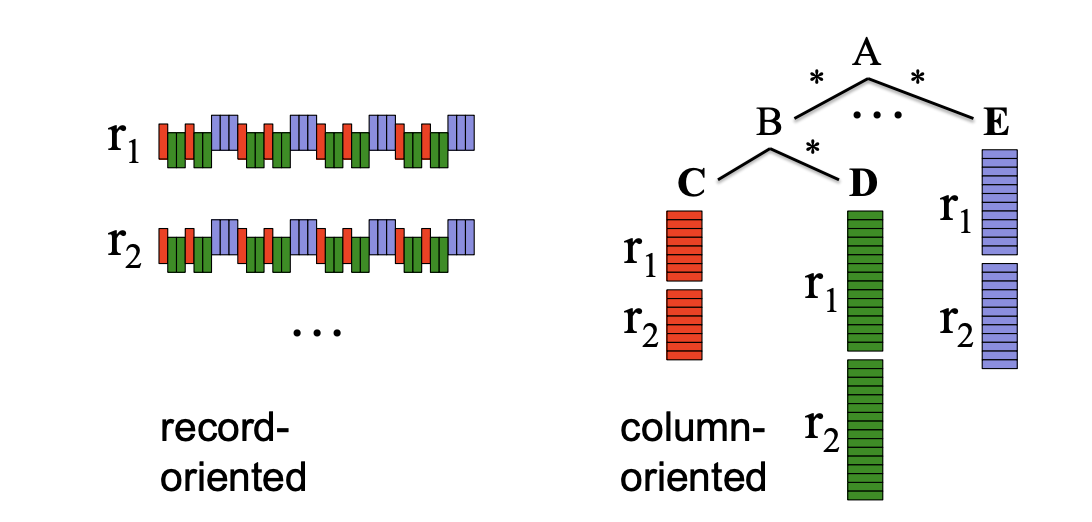
하지만, BigQuery는 레코드 별로 저장하는 것이 아니라 컬럼 별로 저장하는 열 기반 스토리지 형식을 갖추고 있기 때문에 위와 같은 상황에서는 유리한 위치를 점한다.
아래의 그래프는 관련 논문에서 single-field에 대한 접근을 기준으로 실험한 결과이다. 참고로, Dremel은 Google의 BigQuery 서비스 에서 사용되는 쿼리 엔진이다.
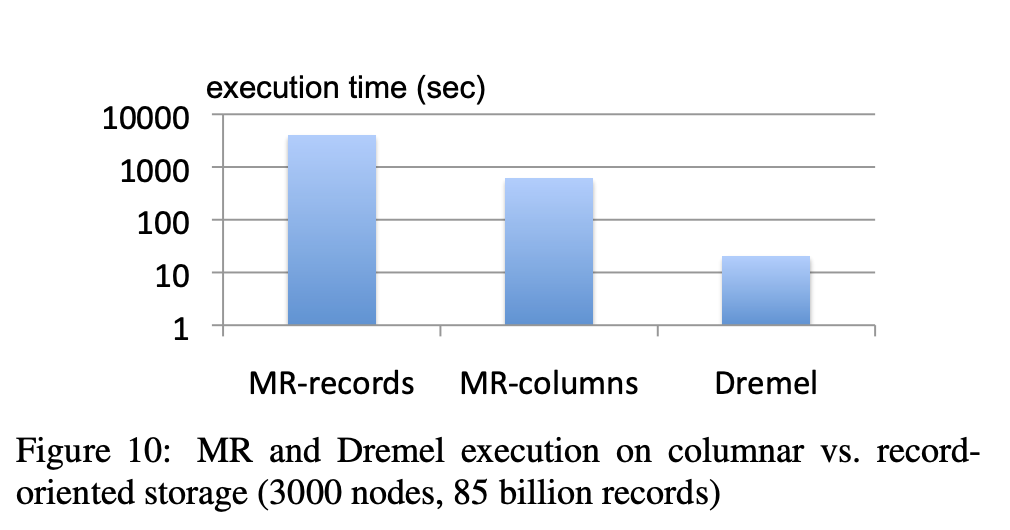
추가로, 컬럼 별로 같은 데이터 타입들로 이루어진 데이터들이 모아져있어, 컬럼별 압축률도 우수하며 컬럼을 추가하거나 삭제하는 것도 매우 빠릅니다. MongoDB 설명 말미에 각 압축 방식에 따른 Compression ratio에 대한 그림을 확인해보면 가장 높은 압출률이 10을 넘지를 못하지만, BigQuery의 경우 상회할 수 있다고 한다.
스키마 구조 (feat. Repetition Level, Definition Level)
서두에 BigQuery의 표면적인 특징을 나열하면서, 스키마 변경도 유연하게 대처가 가능하다고 언급하였다. 아마 이런 의문이 들 수 있다.
"중첩된 데이터에 대해 MongoDB는 Document-based DB니까 대처가 쉽게 가능할 것 같긴 한데, 열 지향 기반으로 설계된 BigQuery가 어떻게...?"
BigQuery는 중첩된 필드(Nested fields)와 반복된 필드(Repeated fields)를 효율적으로 저장하고 쿼리하기 위해 Repetition Level과 Definition Level을 사용한다. 이 두 개념을 통해 중첩된 데이터 구조를 열 지향 방식으로 평탄화하여 저장하고, 이를 효율적으로 쿼리할 수 있다.
일단 BigQuery가 이러한 구조를 어떻게 처리하는지 이해하기 위해, 먼저 논문에서 제공하는 두 개의 샘플 레코드(r1과 r2)와 Nested fields와 Repeated fields의 개념을 정리해보자.

What is Nested fields & Repeated fields?
- Nested fields: 중첩된 필드는 한 레코드 내에 또 다른 레코드를 포함하는 구조를 말한다. 예를 들어,
Name필드 안에Language필드가 중첩된 구조를 가질 수 있다. - Repeated fields: 반복된 필드는 한 필드 내에 여러 값을 가질 수 있는 구조를 말한다. 예를 들어,
Links필드 안에 여러 개의Forward링크를 포함할 수 있다.
Repetition Level과 Definition Level
먼저, Repetition Level과 Definition Level의 개념은 아래와 같다.
- Repetition Level (r level): Repetition Level은 반복된 필드가 몇 번째 반복인지를 나타낸다. 중첩된 반복 구조에서 각 레벨의 반복 횟수를 표현한다.
- Definition Level (d level): Definition Level은 특정 값이 정의되었는지 여부를 나타낸다. 중첩된 구조에서 각 필드가 정의된 깊이를 표현한다.
이제, 아래의 사진에서 Repetition Level과 Definition Level의 역할을 정리해보자.
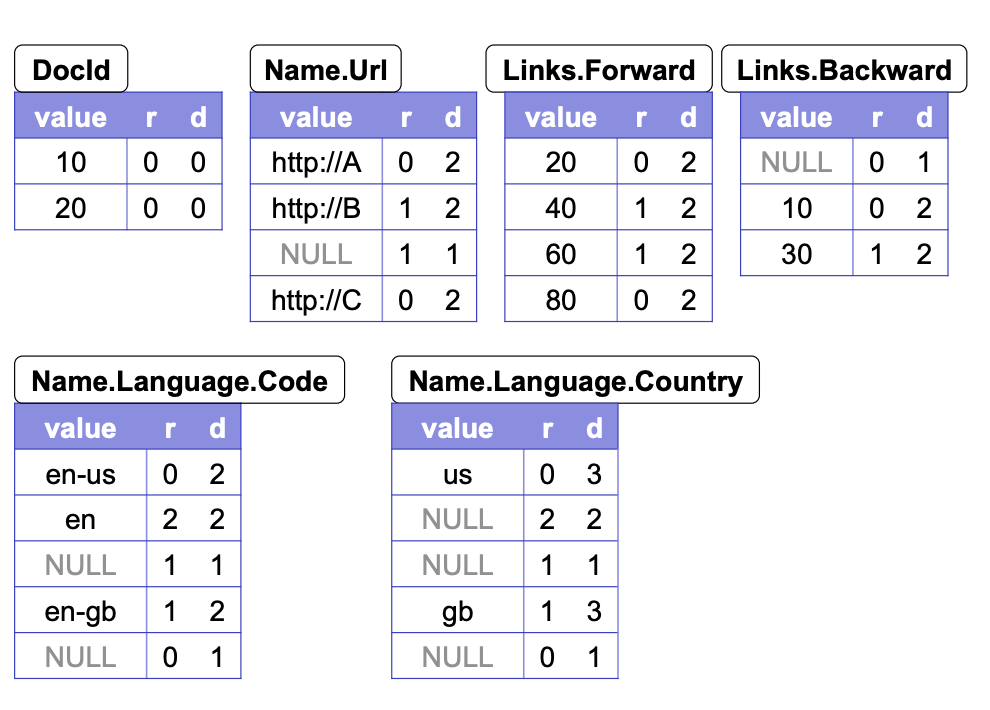
Repetition Level는 중첩된 필드나 반복된 필드가 여러 번 반복될 때 각 반복의 순서를 나타낸다. 예를 들어, Links.Forward 필드가 세 번 반복될 때 각 값의 반복 수준은 0, 1, 2가 된다.
Definition Level는 필드가 정의되었는지 여부와 정의된 깊이를 나타낸다. 예를 들어, Name.Language.Country 필드가 정의되지 않은 경우, 해당 값은 NULL로 표시되며 Definition Level은 정의되지 않은 깊이를 나타낸다.
이와 같은 변환 과정을 통해, BigQuery는 중첩된 데이터를 효율적으로 쿼리할 수 있게 된다.
그 결과, BigQuery는 열 지향 기반 데이터베이스임에도 불구하고 복잡한 계층적 데이터를 효과적으로 처리할 수 있다.
트리 기반 분산 처리 (Tree Architecture Distribution)
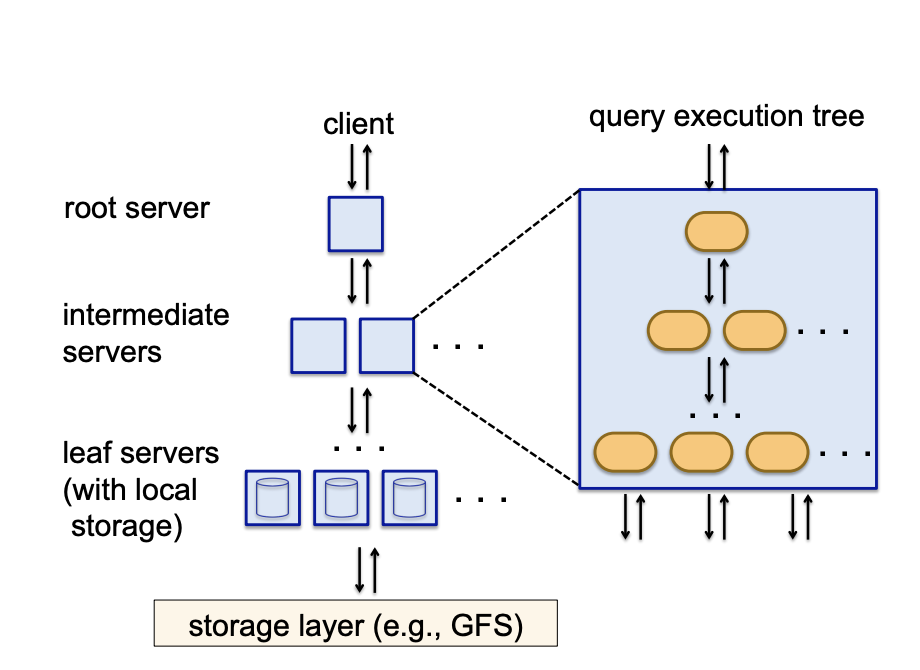
Dremel 논문 기준으로 설명하면 전체적인 과정은 아래와 같을 것입니다.
(root 서버는 mixer 0, intermediate 서버는 mixer 1이라는 용어로 쓰이기도 하니, 같은 개념이라고 이해해도 무관합니다)
- 쿼리 입력: root 서버에 SQL 쿼리를 입력
- 쿼리 분할: root 서버는 입력된 SQL 쿼리를 더 작은 SQL 문으로 분할하여 intermediate 서버로 전달
- 중간 서버 처리: intermediate 서버는 root 서버로부터 받은 쿼리를 다시 더 작은 단위로 쪼개어 leaf 서버로 전달
- leaf 서버 처리: leaf 서버는 실제 데이터를 저장하고 있는 파일 시스템에서 데이터를 읽어와 쿼리 연산을 수행
- 결과 집계: leaf 서버는 연산 결과를 부모 노드(intermediate 서버)로 전달 -> intermediate 서버는 받은 결과를 집계하여 루트 서버로 전달
- 최종 결과 반환: root 서버는 모든 결과를 취합하여 최종 쿼리 결과를 반환
실제 SQL 쿼리를 예시를 통해, 위 과정을 적용해보자.
SELECT
customer_id,
SUM(purchase_amount) AS total_purchase
FROM
ecommerce_data_transactions
WHERE
purchase_date BETWEEN '2020-01-01' AND '2022-12-31'
GROUP BY
customer_id
ORDER BY
total_purchase DESC
LIMIT
5
- 디스크에서 customer_id, purchase_date, purchase_amount 컬럼만을 읽어들입니다.
- leaf 서버: 각 leaf 노드에서 읽어들인 데이터를 가지고 2020~2022년 기간의 데이터를 고객 ID 단위로 그룹화하고, 해당 고객의 총 구매 금액을 계산합니다.
- intermediate 서버: LEAF 노드에서 계산된 고객별 총 구매 금액을 합칩니다.
- root 서버: intermediate 서버에서 올라온 모든 값을 합치면서 총 구매 금액을 기준으로 소팅합니다. 소팅이 끝난 후에, 상위 5명의 레코드를 반환합니다.
마무리
지금까지 MySQL, MongoDB, BigQuery의 아키텍처와 구동원리를 알아보았습니다. 모두 동일한 관점에서 글을 작성하지는 않았지만, 글을 통해 각 DB/DW가 가지고 있는 특징을 이해한다면 훨씬 효과적인 DB 선택과 그에 따른 효율적인 아키텍쳐를 구성할 수 있을 것입니다.
참고문헌
- Real MySQL 8.0 written by 백은빈, 이성욱
- mongoDB Story 2: mongoDB 특징과 구성요소 : NHN Cloud Meetup
- 카카오와 MongoDB
- MongoDB 서버 구축 및 아키텍쳐 - 엘키의 주절 주절
- MongoDB 부수기
- BigQuery 개요 | Google Cloud
- Dremel: Interactive Analysis of Web-Scale Datasets (Google paper)
- 갈아먹는 BigQuery [1] 빅쿼리 소개
- 갈아먹는 BigQuery [2] 빅쿼리 스키마 및 데이터 모델
- 구글 빅데이타 플랫폼 빅쿼리 아키텍쳐 소개
