많이 사용되지만 혼동되는 ML/DL 관련 용어들과 개념들에 대해 정리해보았습니다 :)
AI vs ML vs DL
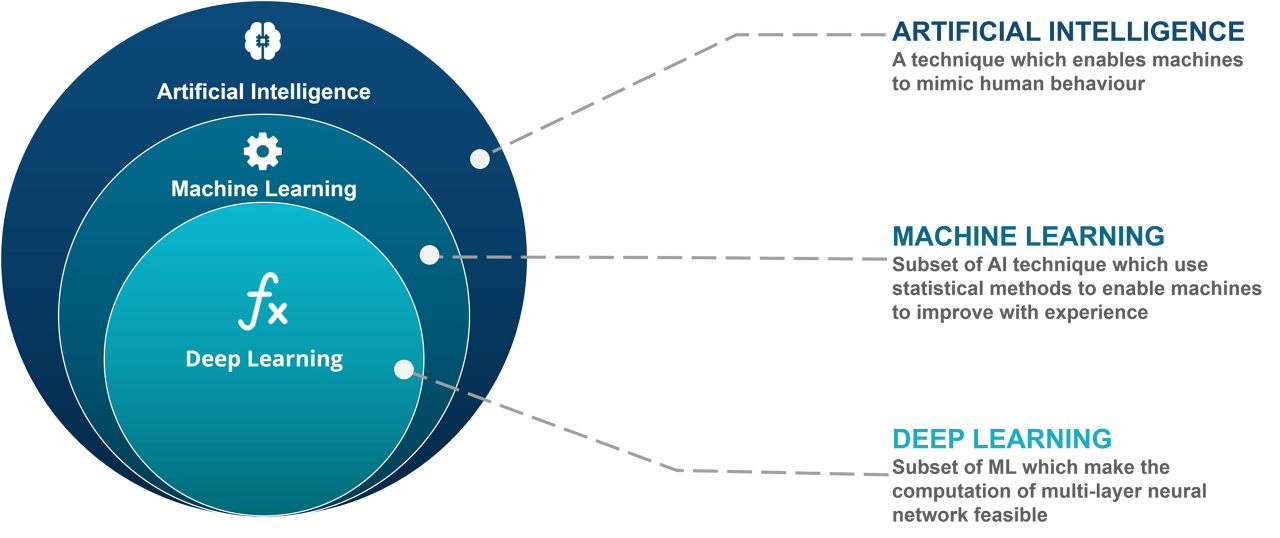
Components of Deep Learning
-
Data: 이 문제를 풀기 위해 어떤 데이터를 사용해야할까? -
Model: 어떤 모델이 원하는 결과를 최대한 잘 도출할까?
ex) GPT-3, LSTM, GAN, ResNet -
Loss function: 모델을 어떻게 학습시킬까?
ex)
Regression type -> MAE, MSE, RMSE
Classification type -> Binary cross-entropy, Categorial cross-entropy
Optimization Algorithm: 네트워크를 어떻게 줄일까?
Overview of Deep Learning history posted by Denny Britz
시간에 따른 딥러닝 모델의 발전과정 overview에 대한 글인데, 흥미롭게 읽어서 가져와보았습니다 :)
https://dennybritz.com/posts/deep-learning-ideas-that-stood-the-test-of-time/
-
AlexNet (2012)
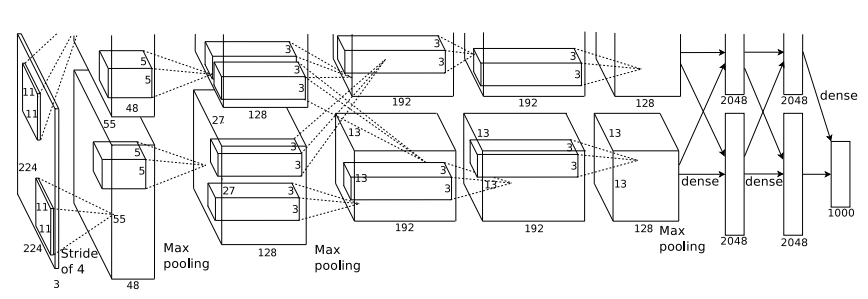
-
DQN (2013)
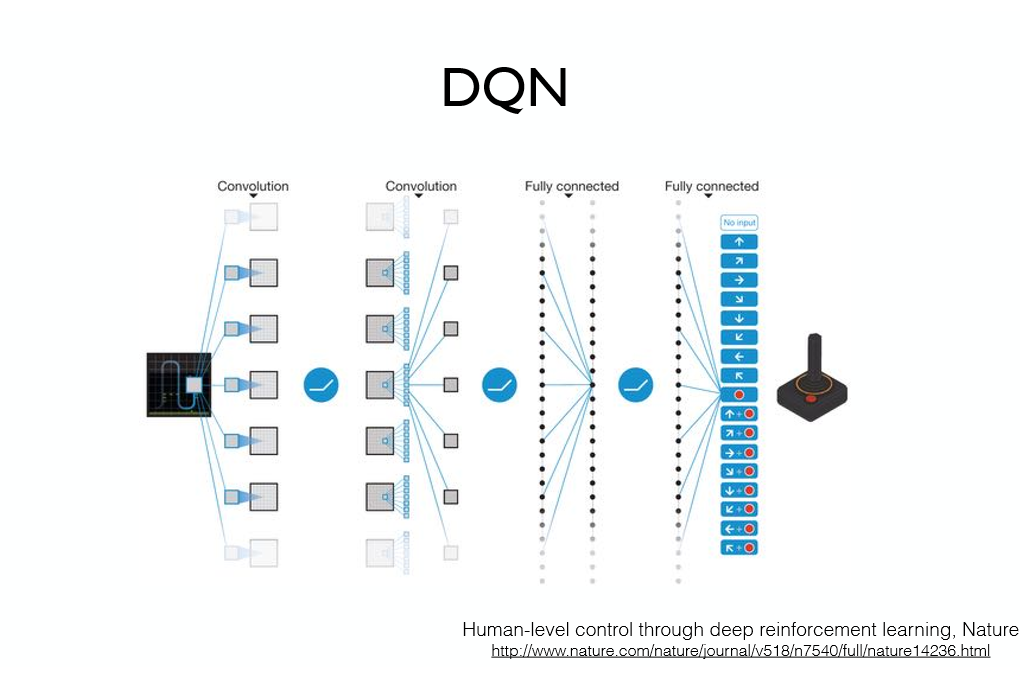
-
Seq2Seq by Attention (2014)
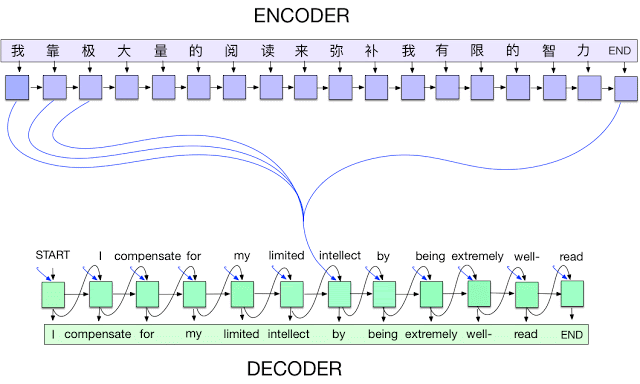
-
Adam Optimizer (2014) -
GAN (2014, 2015) -
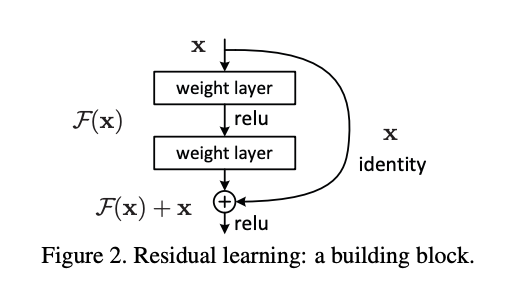
ResNet (2015)
-
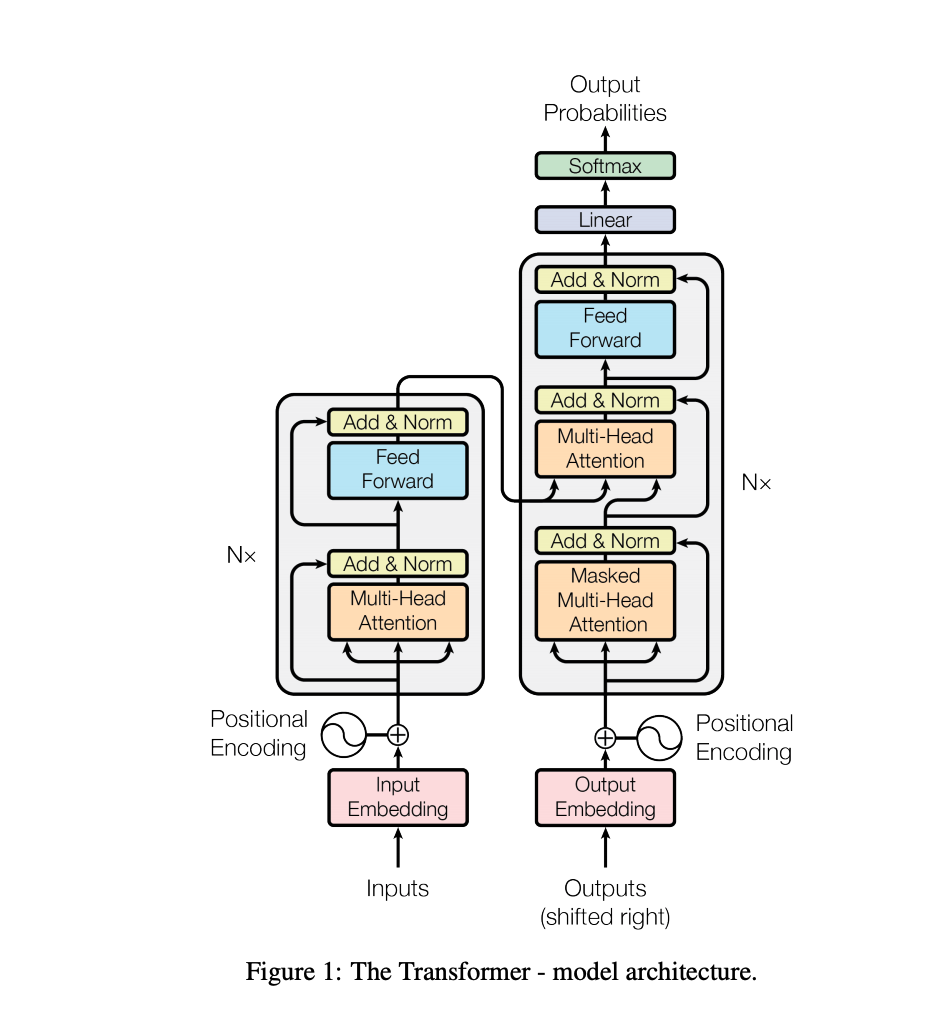
Transformer (2017)
-
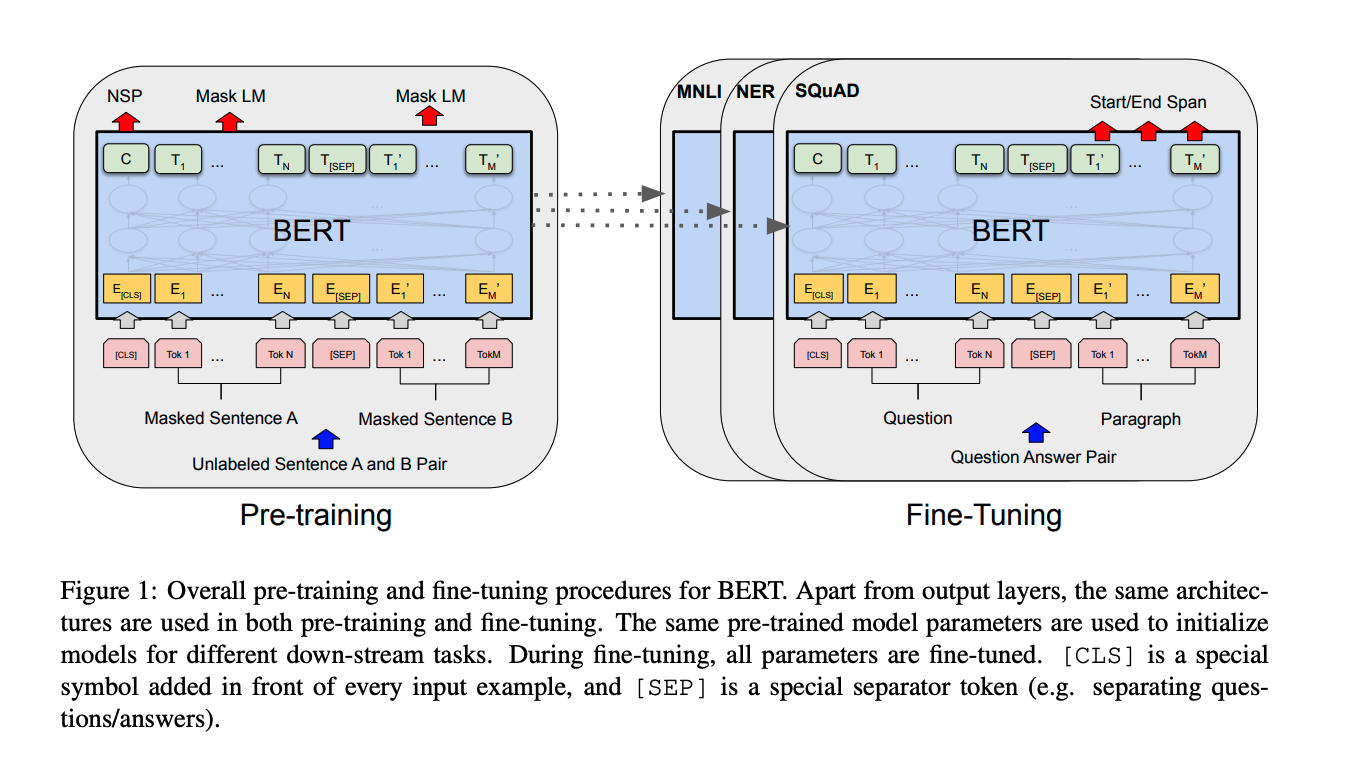
BERT and fine tuned models (2018)
-
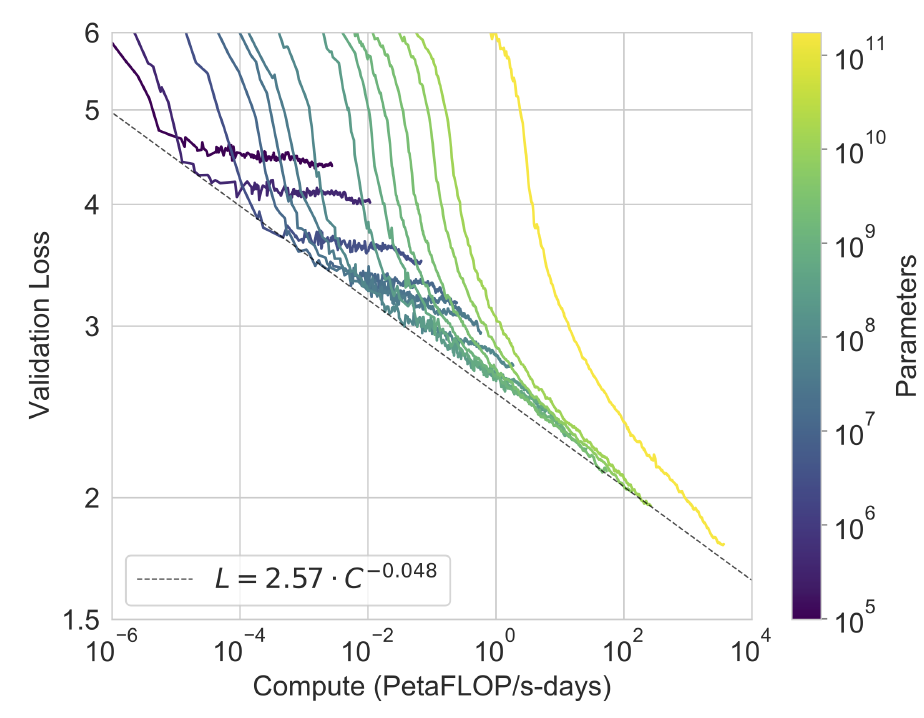
Large Language models like GPT-3 (2019~)
Optimization
-
Generalization: 학습된 모델이 unseen data에서도 work well?Generalization performance=> Generalization gap = (Test error - Training error)
-
Overfitting: Training data에서는 well work, Test data에서는 not well work -
Underfitting: 네트워크가 간단하거나 train이 부족해서 Training data에서도 not well work -
parameter: 최적해에서 찾고 싶은 값 (ex: weight, bias) -
hyperparameter: output을 결정하는 변수 (ex: learning rate; 어떤 loss function을 사용할 것인지?) -
Cross-validation: Training data를 partition하여 Train data, Validation data에 적용 (Training data -> Training data + Validation data)- 최적의 hyperparameter set을 찾고 고정한 상태에서 학습시킬 때는 모든 데이터 활용
(test data x)
- 최적의 hyperparameter set을 찾고 고정한 상태에서 학습시킬 때는 모든 데이터 활용
-
Bias: 얼마나 목표 타겟에 가깝나- low bias: 타겟에 가깝다
- high bias: 타겟에서 멀다
-
Variance: 얼마나 모여있는지- low variance -> 잘 모여있다
- high variance : overfitting 가능성 큼
-
Bias and Variance Tradeoff: bias와 variance를 동시에 줄이기는 쉽지 않다 -
Bootstrapping: dataset에서 무작위로 표본을 추출하여 여러 예측 모델 생성 (any test or metric that uses random sampling) -
Bagging (Boostrapping aggregating) 앙상블: 독립적으로 고정된 학습데이터로 모델 여러개를 훈련 (averaging or voting)- 예) 10만개의 학습데이터로 하나의 모델을 학습하지 않고, 80%로 n개의 모델을 돌리고 값의 평균 또는 voting 출력값을 사용
참고문헌

공감하며 읽었습니다. 좋은 글 감사드립니다.