
[본인인증] 아임포트를 통해 다날 본인인증 연동하기
우선 아임포트 관리자 페이지와 다날 파트너 센터에 로그인할 수 있어야 한다.
아임포트 관리자 페이지: 가맹점 식별코드, REST API 키, REST API secret, MID(PG 상점아이디), 웹훅 발송 공통 URL, CPID, CPPWD, 확인 가능
1) 아임포트 휴대폰 본인인증 연동 소개
https://docs.iamport.kr/tech/mobile-authentication?lang=ko#send-imp-uid
서버인 나는 사실상 step 5부터 진행했다.
2) 아임포트 REST API 페이지
https://api.iamport.kr/
결제완료된 정보, 결제 취소, 상태별 결제 목록 조회 등의 기능을 하는 REST API를 실제로 동작해볼 수 있음
3) 아임포트 매뉴얼 페이지 (깃헙)
https://github.com/iamport/iamport-manual/tree/master/SMS%EB%B3%B8%EC%9D%B8%EC%9D%B8%EC%A6%9D
4) 아임포트 파이썬 rest client 페이지 (깃헙)
파이썬 사용자를 위한 아임포트 REST API 연동 모듈
https://github.com/iamport/iamport-rest-client-python
사실상 내가 참고한 부분은 이곳
5) iOS 개발자 입장에서 작성된 아임포트 휴대폰 본인인증 연동하기
https://swieeft.github.io/2020/02/23/ImportSMSiOS.html
[python] Request with Requests
https://requests.readthedocs.io/en/latest/user/quickstart/
위코드 2차 프로젝트였던가 크롤링하면서 requests 모듈을 사용했던 것 같다. 다른 것 검색하다가 우연히 들어가게 되었는데 이런 공식문서가 존재하는줄 몰랐다. 읽어보니 이제사 이해되는 것들도 많고 좋았다.
[github] 아직도 어렵고 헷갈리는 git
https://velog.io/@luna238/Git-branch%EA%B5%AC%EC%A1%B0%EC%99%80-git%EB%AA%85%EB%A0%B9%EC%96%B4
이것저것 보다가 들어갔는데 위코드 동기 효식님 블로그였다는 것! 정리 정말 잘 해놓으셨음.
[mysql] Mysql Access 오류 : Access Denied
오류 발생 시점: 데이터 수정 후 테이블 덤프 --> 덤프한 테이블 import하려고 할 때
Access denied; you need (at least one of) the SUPER privilege(s) for this operation
https://stackoverflow.com/questions/44015692/access-denied-you-need-at-least-one-of-the-super-privileges-for-this-operat
해당 링크에 들어가면 질문에 대한 답이 여러개 나오는데 나의 경우 두 번째 방식으로 해결했다. 우선 내 파일에 DEFINER가 있지 않았기 때문에
SET @@SESSION.SQL_LOG_BIN=0; 과 SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '';, SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;을 주석처리하는 방식으로 진행했다.
[git] Git 명령어 오해 사건 : 옵션 m
git branch -m '브랜치명' 명령어는 해당 브랜치의 이름을 개명시키는 옵션이다. 나는 위의 명령어가 해당 브랜치를 만들면서 동시에 이동(옵션 m==move로 생각)할 수 있는 명령어라고 생각했었다. 그래서 dev 브랜치에서 feature브랜치로 이동할 때, 브랜치를 만들면서 동시에 이동하고자 해당 명령어를 쳤었는데 때마다 dev 브랜치의 이름이 내가 설정한 브랜치 이름으로 바뀌고 있었고 그래서 때마다 삭제시킨적 없는데 dev 브랜치가 자꾸 사라지는 기현상을 겪고 있었다. (;;) 명령어를 익힐 때에는 확실히 익힐 것...
[django, mysql] django와 연결된 mysql : 데이터 수정의 순서
입사 초기(라기에는 지금도 초기이지만..) 데이터를 갈아끼우거나 수정할 때에 mysql단에서 작업을 해버린 후(mysql workbench(GUI단에서)로 테이블 description을 추가하거나 컬럼 자체를 추가 or 삭제) 뒤늦게 models.py를 고치는 일이 왕왕있었다. 당시에는 정말로 정신없이 작업하다보니 일의 순서라는 것이 거의 없이 일을 닥치는대로 하는 것이 습관되어 그랬었다. 그때와 달리 지금의 나는 Models.py를 먼저 수정하고, 해당 model을 mysql에 적용시킨 이후(makemigrations, migrate를 통해) DB 작업하는 것을 선호한다.
나중에 알아보니
1) 데이터 모델을 먼저 수정하고 데이터를 갈아끼우거나
2) 데이터를 갈아끼운 후 모델을 수정하나
사실상 일의 단도리만 잘쳐주면 큰 문제는 발생하지 않는다고 한다.
2)번의 순서로 일을처리하게 되었을 경우, python manage.py inspectdb 명령어를 이용하여 이미 적용된 DB의 models.py를 가져올 수 있다. 만일 python manage.py inspectdb > models.py라고 치면 바로 models.py로 만들어버릴 수도 있다(이건 처음부터 애초에 모두 작업된 DB로 view짜는 작업을 시작할 때 사용할 수있을 것)
그러나 이 경우 inspect한 내용이 명확성(섬세함)이 떨어진다. 일례로 CharField의 max_length나 default 옵션, null 옵션등이 확실히 내가 의도한대로 나오지 않는 경우가 많다. 따라서 역시 나는 models.py를 수정한 후, DB를 건드리는 방식으로 앞으로도 작업할 것 같다.
[django] routing 분기처리
입사 초기(라기엔 지금도 초기이지만..2) 단일 프로젝트(이하 A)로 시작했던것과 달리 새로운 프로젝트가 추가됨에 따라 urls.py를 이용하여 프로젝트별 view를 따로 관리할 필요가 생겼다.
아주 간단한 예를 들어보겠다.
1) 프로젝트 A response 화면
[
{
"q_ans1": "다음으로",
"q_ans1_s": 0,
"q_ans2": "0",
"q_ans2_s": 0,
"q_ans3": "0",
"q_ans3_s": 0,
"q_ans4": "0",
"q_ans4_s": 0,
"q_ans5": "0",
"q_ans5_s": 0,
"q_ans6": "0",
"q_ans6_s": 0,
"max_count": 24,
"q_type": 1,
"source": "0",
"source_title": "0",
"title": "[보안]",
"sq": 2
}
]2) 프로젝트 B response 화면
[
{
"q_list": [
{
"q_ans1": "다음으로",
"q_ans1_s": 0
},
{
"q_ans2": "0",
"q_ans2_s": 0
},
{
"q_ans3": "0",
"q_ans3_s": 0
},
{
"q_ans4": "0",
"q_ans4_s": 0
},
{
"q_ans5": "0",
"q_ans5_s": 0
},
{
"q_ans6": "0",
"q_ans6_s": 0
}
],
"max_count": 24,
"q_type": 1,
"source": "0",
"source_title": "0",
"title": "[보안]",
"sq": 2
}
]위처럼 내용은 같지만, 형식이 다르게 리스폰스가 전달되어야하는 경우가 생긴다. 프로젝트 A는 리스트 속 단일 객체에 프로퍼티를 쭉 나열하지만, 프로젝트 B의 경우 클라이언트쪽 요청으로 인해 요 바로 위의 형태로 리스폰스 형식을 바꾸어줘야했다. 게다가 이 때에 웹 페이지 용과 앱 용의 response가 달라져야한다면 조금 더 복잡해진다. (웹-프로젝트A, 웹-프로젝트B, 앱-프로젝트A, 앱-프로젝트B 로 총 네 가지 경우의 라우팅 필요)
기본적으로 django로 작성된 프로젝트는 아래와 같은 구성을 가진다.
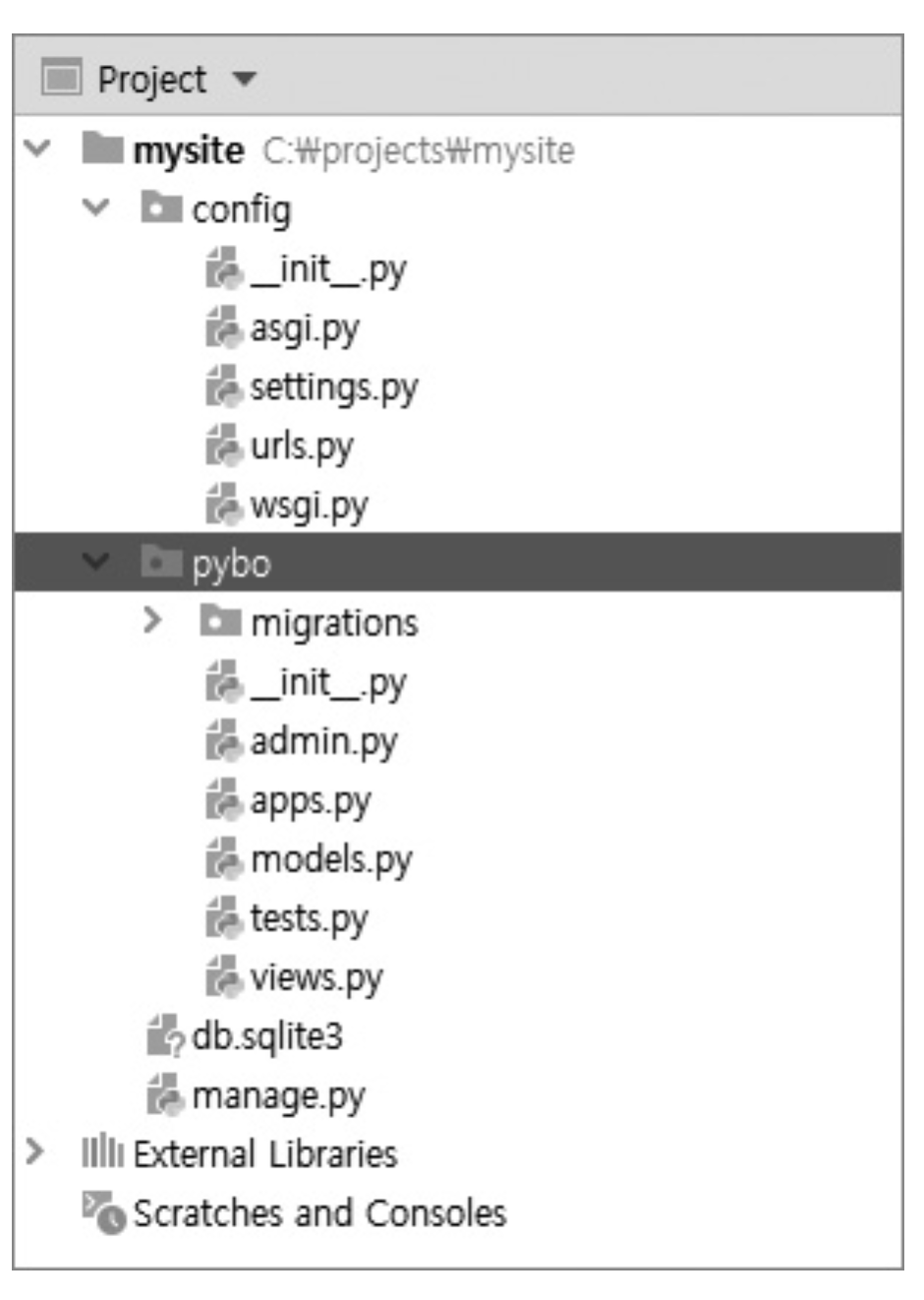
위 그림을 통해 개략적으로 이야기해보자면
1. mysite : 전체 프로젝트 디렉토리 (가장 최상단)
2. config : 전체 프로젝트에 대한 setting(미들웨어, 앱 추가, url등)을 다루는 디렉토리. 보통 전체 프로젝트와 같은 이름(이 경우 mysite)로 생성되어있다.
3. pybo (위 그림에서는 앱1 이름을 pybo로 했다) : 전체 프로젝트 내 앱1 디렉토리 (프로젝트를 만든 이후 기능을 추가하면서 하나씩 생성되는 디렉토리 - python manage.py startapp [앱명])
여기서 아주 초심자일 때 어려울 수 있는 부분이 config 프로젝트 내에도, pybo 프로젝트 내에도 urls.py가 존재한다는 것이다. 대체 왜 똑같은 파일이 두개씩이나 있는지에 대해 헷갈릴 수가 있다. 하지만 config 내 urls.py는 어떤 앱으로 해당 url을 연결할 것인지에 대한 1차 연결 통로로의 기능을 수행하고, 이 config의 urls.py를 통해 각 앱으로 연결된 후에는 각 앱 내의 urls.py가 실제 그 앱 내의 어떤 class (views.py 내의)로 연결을 시킬 것인지 맵핑시킨다는 점에서 둘은 차이가 있다.
위에서 말한대로 [프로젝트별]X[웹/앱별] 리스폰스가 변경되어서 보내져하는 경우 아래와 같은 방법을 통해 분기처리할 수 있다.
- config - urls.py
from django.urls import (
path,
include,
)
urlpatterns = [
path('web', include('app_1.urls')),
path('web', include('app_2.urls')),
path('web', include('app_3.urls')),
...
path('app', include('app_1.urls')),
path('app', include('app_2.urls')),
path('app', include('app_3.urls')),
...
]url이 생성될 때에 web인지, app인지를 먼저 구분하기 위해 가장 먼저 config의 urls.py에서 web/app 구분을 해준다. 이 때 include함수에는 같은 내용이 들어가는데, 직접적인 코드가 변경되는것은 해당 앱에 들어가서 맵핑을 따로 해주는 것으로 작동하기 때문에 여기까지는 동일한 내용이 들어가는 것이다.
- app_1 - urls.py
from django.urls import path
from .views import (
View1_v1,
View1_v2,
...
)
urlpatterns = [
path('/v1/app_1/[View1에 대한 이름]', View1_v1.as_view()),
path('/v2/app_1/[View1에 대한 이름]', View1_v2.as_view()),
...
]여기서 v1은 version 1로 프로젝트 A를 의미하고, v2는 version 2로 프로젝트 B를 의미한다. View1_v1, View1_v2라 클래스명을 지은 것은 내용 및 기능은 같은데 위에서 말했듯 리스폰스 방식만 살짝 달라지기 때문이다. 이런식으로 urls.py를 설정하면 최종적으로 url은 이렇게 나올 것이다.
[project A]
메인 url/web(or app)/v1/[View1에 대한 이름]
: 실제로 맵핑되는 뷰는 View1_v1
[project B]
메인 url/web(or app)/v2/[View1에 대한 이름]
: 실제로 맵핑되는 뷰는 View1_v2
이상 내가 알아낸 라우팅 분기 처리 방법이었다.
더 멋지게 분기처리하는 또다른 방법이 있을텐데 그건 차차 깨우쳐갈듯.
우선 이번에는 이 방법으로 잘 해내었다. 👏🏻
[django] first()
원래는 prefetch_related를 사용할 때에는 model명_set으로 쿼리셋을 쿼리하며 조건에 관한한 filter를 사용하여 미리 캐싱해둔 후 필요할 때마다 객체 접근 시에는 first()를 사용했었다. filter를 사용할 경우 객체가 아니라 쿼리셋이 캐싱되기 때문에 객체에 접근하기 위해 그 쿼리셋의 첫번째 객체라는 의미로 first()를 사용한 것이다. 하지만 다른 방법도 있다. 생각해보지 못한건 아니지만, 쿼리셋은 말그대로 set, 집합이기 때문에 리스트에서 접근하는 식으로 [0]를 사용해보는 것이다. 사실상 쿼리셋이라고는 하지만 내가 원하는 조건에 정확히 쿼리되는 셋에 객체가 한 개 존재한다면, 해당 쿼리셋 바로 뒤에 [0]을 사용하여 해당 집합의 첫번째 객체에 접근하게 하여 그 객체에서 내가 필요로하는 부분(컬럼)을 사용하는 것이다. 나의 경우 Queryset[0]['필요로하는 컬럼'] 방식으로 사용했고, 이 방법이 first()를 사용하는 것보다는 더욱 DB hit를 줄일 수 있는 방안이라고 생각한다.
SSR, CSR
(참조: https://d2.naver.com/helloworld/7804182
https://brownbears.tistory.com/411
https://velog.io/@namezin/CSR-SSR)
브라우저단에서 실제로 유저가 보는 화면, 바로 그 화면을 최종적으로 어디서 만들어서 보여주느냐, 어떻게 개발하느냐에 따라서 SSR, CSR이라고 나누어 부름.
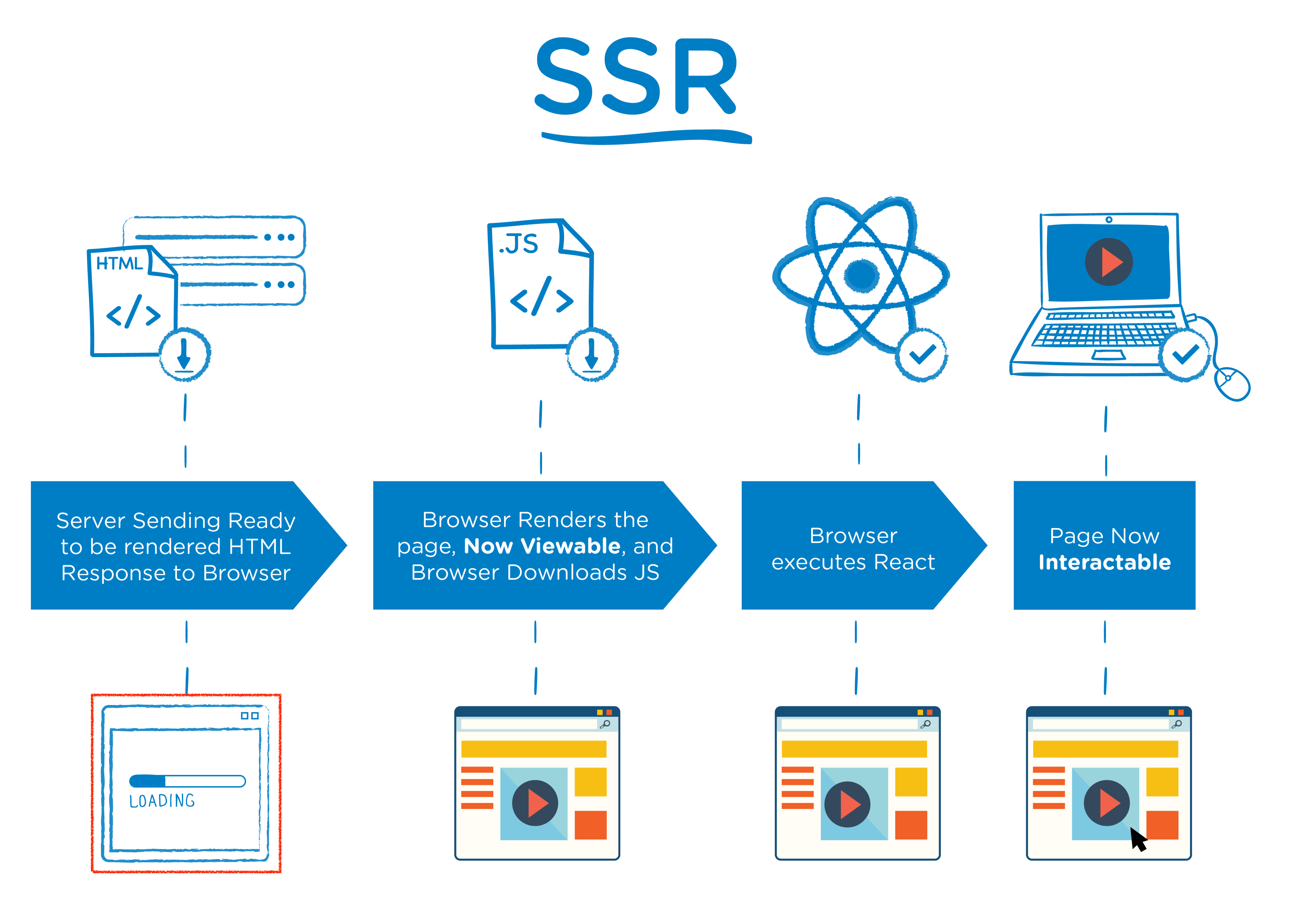
[SSR이란]
- 서버에서 사용자에게 보여줄 페이지를 모두 구성하여 보여주는 방식. 완전하게 만들어진 html 파일을 받아와서 렌더링. 모든 데이터가 매핑된 서비스 페이지를 클라이언트에게 바로 보여줄 수 있음.
- 매번 페이지를 요청할 때마다 새로고침되어 UX가 다소 떨어질 수 있음.
- 서버를 이용한 페이지 구성이므로 CSR(client side rendering)보다 페이지를 구성하는 속도가 늦음. 매번 서버에 요청해야하므로 트래픽, 서버 부하가 큼.
- 전체적으로 클라이언트에게 보여주는 콘텐츠 구성이 완료되는 시점은 빨라짐.
(CSR의 경우 SSR보다 초기 전송되는 페이지의 속도는 빠르나, 서비스에서 실제 필요한 데이터를 클라이언트단에서 추가 요청하여 재구성하여하기 때문에 전체적 페이지 완료 시점이 SSR보다 느린 것)- 더불어 SEO적인 측면으로도 더 유리함
- 사용자가 웹페이지에 접근할 때, 서버에 페이지에 대한 요청을 하며 서버에서는 html, view와 같은 리소스들을 어떻게 보여질지 해석하여 렌더링하여 사용자에게 반환
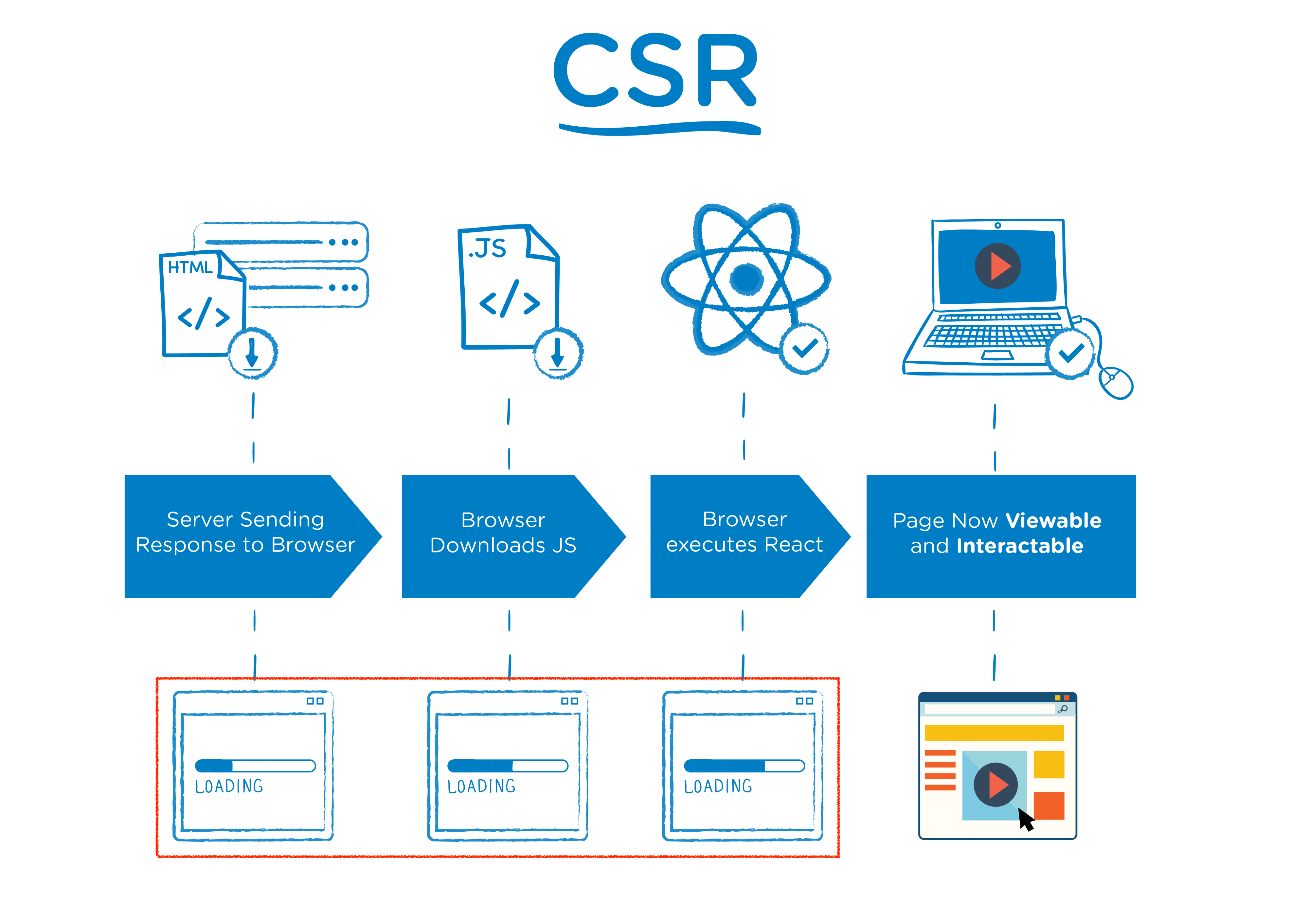
[CSR이란]
- 처음 웹서버에 요청 시에는 데이터가 없는 문서를 반환
- html 및 static 파일들이 로드되면서 데이터가 있다면, 데이터 또한 서버에 요청하고 그것이 화면상에 나타나게 된다.
- 사용자와의 상호작용을 통해 JS를 동적으로 렌더링. 필요에 따라 데이터를 서버에서 요청하고 받아와 렌더링하는 형식이다.
- 첫 로딩에서 html과 static 파일만 다 받으면 동적으로 빠르게 렌더링하므로 사용자 UX가 뛰어남
- 서버에 요청하는 횟수도 적어 서버 부담이 덜하다.
최초 한 번 서버에서 전체 페이지를 로딩하여 보여준 이후에는 사용자의 요청이 들어올 때마다, 리소스를 서버에서 제공한 후 클라이언트단에서 해석하고 렌더링하는 방식.- 초기 Angular JS, Backbone JS와 같이 SPA 개발이 쉬운 JS 프레임워크가 등장했으나, 점차 클라이언트가 무거워짐에 따라 다시 view만 관리하는 것이 좋겠다는 철학으로 회귀하여 등장한 것이 React JS. 그러나 모두 SPA 방식이라고 하여 CSR인 것은 아니다.
- 구글 검색 엔진을 제외하고는 SEO 문제가 생긴다.
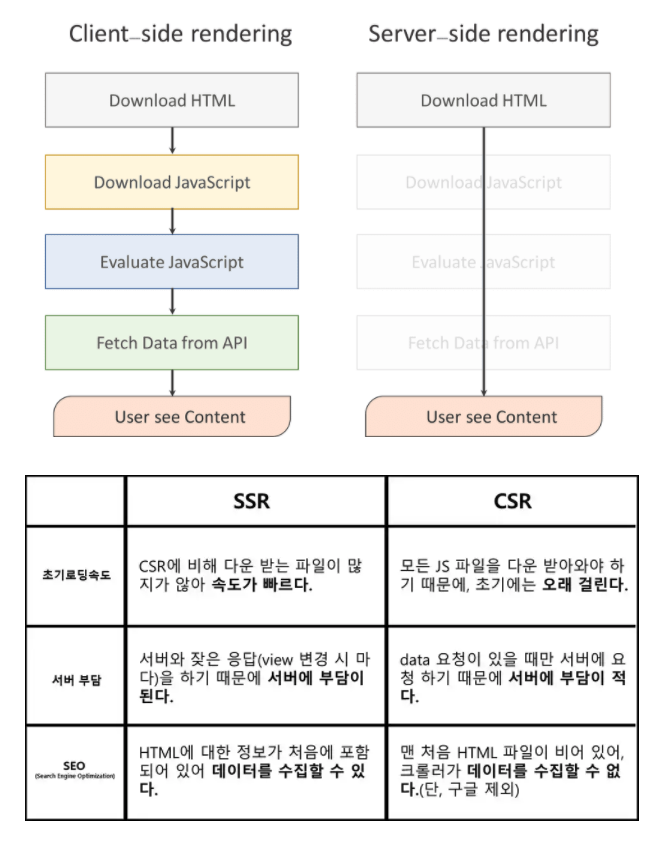
둘 간 차이점이라면 크게 초기 렌더링 속도, SEO, 보안.
- 초기 렌더링 속도
CSR: 초기 구동속도가 느림. 페이지를 읽어들이고 자바스크립트를 읽고 자바스크립트가 화면단을 구성하는 속도까지 모두 포함하기 때문.
SSR: 서버에서 view를 렌더링하여 가져오기 떄문에 view를 보기까지 초기 구동속도가 빠름. 물론 JS파일을 전부 다운로드받기 전까지는 제대로 동작하지 않지만 사용자 측면에서는 빠르다 느낄 수 있음.
- SEO
CSR: 대부분의 웹 크롤러나 봇들이 JS 파일을 실행시키지 못하고 html에서만 컨텐츠를 수집 --> CSR로 개발된 페이지를 빈 페이지로 인식하여 검색엔진에 제대로 노출되지 못하는 문제가 발생.
SSR: view를 서버에서 전부 렌더링하여 내려주므로 html에 모든 컨텐츠가 저장되어 있음. SEO 적용 측면에서 유리.
- 보안
CSR: 클라이언트 측의 쿠키 이외에는 사용자에 대한 정보 저장 공간이 마땅치 않음
SSR: 사용자에 대한 정보를 서버 측에서 세션으로 관리.
[git] stash
깃 브랜치를 새로 따서 작업을 하다보면, 지금은 커밋할 시점이 아닌데 다른 브랜치로 급히 옮겨가야하는 때가 발생한다. 이럴때 유용한 것이 git stash. git stash 명령으로 잠시 하던 작업을 임시의 공간에 저장한 후, 내가 옮겨가고 싶은 브랜치로 옮겨가서 작업을 완료한다. 그리고는 다시 돌아와서 git stash apply 명령어로 내가 아까 하던 작업을 다시 복원한다. git stash pop 명령어도 있지만, 이 명령어를 사용하기 위해서는 정확히 아까 그 브랜치로 돌아가야 한다. 하지만 git stash apply는 어떤 브랜치에가서도 사용할 수 있고, pop보다는 더 넓은 범위의 개념이라 보통 apply를 사용하는 것 같다.
UnixTime
https://www.unixtimestamp.com/index.php
유닉스타임이라는 개념이 있었다.
SDK
- 소프트웨어 개발 키트 (Software Development Kit)
- 하드웨어 플랫폼, 운영체제 또는 프로그래밍 언어 제작사가 제공하는 일련의 툴
- SDK를 활용하여 플랫폼, 시스템 또는 프로그래밍 언어에 따라 앱을 개발할 수 있음
- 직접 조립하려고 산 옷장의 부품과 함께 제공된 비닐백의 육각랜치 같은 것! 즉 작업을 완료하기에 필요한 요소는 제공되나 키트에 포함된 내용물은 제작사마다 다름.
- 기본 구성: 컴파일러, 디버거, API + 설명서, 라이브러리, 편집기, 런타임/개발환경, 테스트/분석 툴, 드라이버, 네트워크 프로토콜, 일부 SDK에는 기본 테스트 프로젝트도 포함
- JDK가 대표적인 예
SDK 선택 시 주의하여 고려할 사항
- 독점 라이센스가 있는 SDK는 오픈소스 소프트웨어 개발과 호환되지 않음
- GPL(General Public License)가 있는 SDK는 독점 앱 개발에 사용할 수 없음
- 독점 코드 요소가 있는 프로젝트를 위해서는 LGPL(Lesser General Public License)을 피해 작업할 경우 주의해야할 사항이 있음
[django] PointField
회사에서 사용하던 모델엔 위경도를 작업할 수 있는 컬럼이 있었다. 위도, 경도만 있을 때 python의 haversine을 이용하여 거리 계산을 할 수도 있지만 위도 경도 값 자체로 해당 좌표를 만들어 찍어버리는 것은 생각하지 못했다. 이런 때에 사용하면 편리한 것이 PointField이다.
좌표컬럼명 = models.PointField(null=True, srid=4326, verbose_name='컬럼명')식으로 좌표를 만들 컬럼을 models.py에 추가해준다. 물론 좌표값이 모델만 바꾼다고 들어가지는것은 아니고 직접 좌표값을 넣어줄 수 있는 코드를 또 작성해야 한다. 나는 아래처럼 작성했다.
def create():
a = [좌표값추가할모델].objects.all()
for i in a:
i.좌표컬럼명 = Point((i.위도, i.경도), srid=4326)
i.save()
return print ('Update data to [좌표값추가할모델] table')[django] annotate
annotate는 sql의 as와 같은 것으로, 실제 모델에 존재하지 않느 가상의(임의의) 컬럼을 추가하는 느낌으로 이해했다. 원래는 없지만 당장 필요한 컬럼을 내 입맛대로 정의하고 그 가상의 컬럼으로 내가 필요한 연산을 진행하면 된다. 나의 경우 거리 계산을 위해 사용했다. 내가 가진 모델에는 위의 pointfield를 이용하여 해당 건물의 좌표값을 가진 필드(a)가 있었고, 유저에게서는 해당 유저의 위/경도를 받아 유저의 위치(b)를 계산해낼 수 있었다. 내가 하고 싶었던 연산은 해당 건물과 유저 사이의 거리(a, b사이의 거리)를 계산하여 거리가 가까운 5개 값에 해당하는 건물만을 추려내는 것이었다.
[가상의 컬럼명] = Distance(
'[PointField로정의한좌표값컬럼]', [유저의위치(유저의 위경도로 계산)]
)).order_by(
'[가상의 컬럼명]'
)[:5]
이렇게 해서 딱 5개의 값을 사용할 수 있었다.
일이 바빠지니 정말 블로깅하기가 쉽지 않다 🧐
게다가 이제는 학교도 다니게 되었으니 더 쉽지 않겠지만
분명히 정리하는 시간이 주는 소중함은 무시할 수 없다
화이팅 3월 !! 잘 부탁합니다. 🙇
