< 썸네일 출처 >
https://en.wikipedia.org/wiki/Boosting_(machine_learning)#/media/File:Ensemble_Boosting.svg
#/media/File:Ensemble_Boosting.svg){kind=link}
Boosting 과 Bagging 이 Ensemble method 의 큰 부분을 이룬다. 이 둘을 잘 알아두면 좋다.
-
Q. Boosting 알고리즘이 뭔가요?
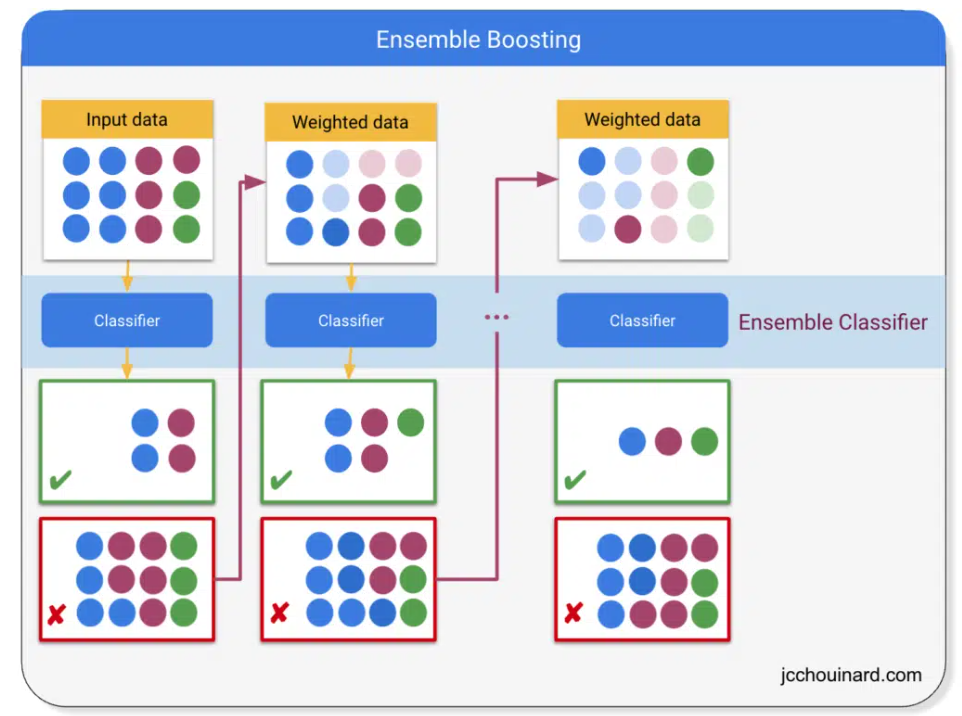
A. Boosting 알고리즘이란 앙상블 기법 중 하나로, 초반의 weak learner decision tree 를 설정해 그 에러값들을 수정해나가면서 후반의 strong learning decision tree 들을 만드는 알고리즘입니다. -
Q. Boosting 과 Bagging 의 차이는 뭔가요?
A. 둘다 앙상블 기법이지만 Bagging 또는 Bootstrap Aggregating 은 각 decision tree 가 서로 독립입니다. 하지만 Boosting 은 초반의 decision tree 의 에러값들을 후반의 decision tree 들은 수정해 나가는 식으로 학습이 진행됩니다. -
Q. Boosting 의 GBM 과 LGBM 의 차이에 대해 간략하게 말씀해주세요.
A. 네 GBM 또는 Gradient Boosting 은 Boosting 에 Gradient Descent 방식을 접목한 것입니다. 하지만 이는 연산량이 너무 많아 decision tree 들을 best tree 가 아닌 greedy method 으로 tree 를 만드는 것을 light GBM 이고 이는 연산량이 현저히 적습니다. -
Q. Boosting Algorithm 의 장단점에 대해 간략하게 말씀해주세요.
A. Boosting 알고리즘의 장점으로 쉬운 해석력과 뛰어난 성능을 꼽을 수 있습니다. 실제 XGBoost 은 분류와 회귀에서 머신러닝 알고리즘 중에서 성능이 제일 뛰어나다고 할 수 있습니다. 하지만 boosting 의 단점으로는 scaling, online learning 이 안된다는 점과 결측치에 취약하다는 점을 꼽을 수 있습니다.
Boosting Algorithms
Boosting Algorithm 정의
- Ensemble 기법 중 하나로써, 초반의 weak learner 에서의 에러를 줄여가는 식으로 sequentially 학습을 하는 것을 말한다. 즉, 초반의 모델에 영향을 받는다.
일단 Boosting 과 Bagging 의 차이부터 알아보자. 둘다 Ensemble method 의 하나이지만 boosting 은 시작 모델의 에러를 줄여나가는 방식으로 후반의 모델들이 설계가 된다. 하지만 bagging(bootstrap aggregating) 은 각 모델들이 완전히 독립적이다. Bagging 의 대표적인 알고리즘은 decision tree 를 대거로 만드는 Random Forest 이다.
Boosting 장점
Boosting 알고리즘은 weak learner 들이 순차적으로 제시되는 것이기 때문에 해석하기가 쉽다. 성능도 매우 뛰어나다. 실제로 XGBoost 은 성능이 매우 뛰어난 머신러닝 알고리즘으로 유명하다.
Boosting 단점
Boosting 알고리즘은 이상치에 취약하다. 그 이유는 boosting 알고리즘은 모든 에러값들을 맞추려고 하는데 이상치에 이상한 수정이 가해지면 모델이 꼬일 수 있다. 전처리를 잘 해줘야한다.
또한 Boosting 은 scaling, online learning 이 매우 힘들다. 그 이유는 초반의 모델들에 의해 후반의 모델들이 학습을 하기 때문에 새로운 데이터가 들어오는 것을 어떻게 할 수 없다.
Boosting Algorithm 의 발전 순서.
1. AdaBoost. Adaptive Boosting Machine
Boosting 알고리즘의 시초. Adaptive boosting 은 단순히 의사결정나무에서 잘못 분류된 데이터포인트들의 weight 를 높여 다음에는 더 잘 분류되기를 목적으로 함.
2. Gradient Boosting. GBM
Boosting 에서 에러값들의 weight를 높이는 것보다 gradient descent 알고리즘을 접목해 loss function이 최소가 되는 세타값을 찾아가는 것을 목적으로 함. 기울기의 음수 방향으로 일정 크기만큼 여러번 바꿈. 하지만 이 GBM 을 포함한 대부분의 boosting 알고리즘들은 과적합이 될 우려가 있다는게 큰 단점.
3. Extreme Gradient Boosting. XGBoost
과적합이 너무 일어나는 Gradient Boosting 을 막기 위해 loss function 에다 regularization term 을 추가해 막는 것. 이 XGBoost 은 회귀나 분류에서나 성능이 매우 뛰어난 것으로 유명하다.
4. Light Gradient Boosting. Light GBM
GBM 을 기본으로 하지만 너무 많은 연산을 줄이기 위해 weak learner 들마다 best tree 를 찾는 것이 아니라 greedy 한 방법으로 tree 를 구축해 연산을 대폭 줄인 것이다.
