이번에는 요 박스를 움직여서 머리위의 공이 떨어지지 않도록 밸런스를 잡는 게임인거 같습니다

보통 강화학습의 시작점으로 튜토리얼되는 CartPole과 비슷한 느낌이네요.
- 지난내용에서 설치가 완료된 Unity 프로젝트를 켜봅시다
- Package Manager에서 ML-Agents를 키고
- 3D Ball 샘플을 Import
(저의 경우는 이 부분이 이미 ML-Agents 전체가 Import되어있었습니다) - Project 윈도우에서
Assets/ML-Agents/Examples/3DBall/Scenes폴더의 3DBall Scene을 열어봅시다
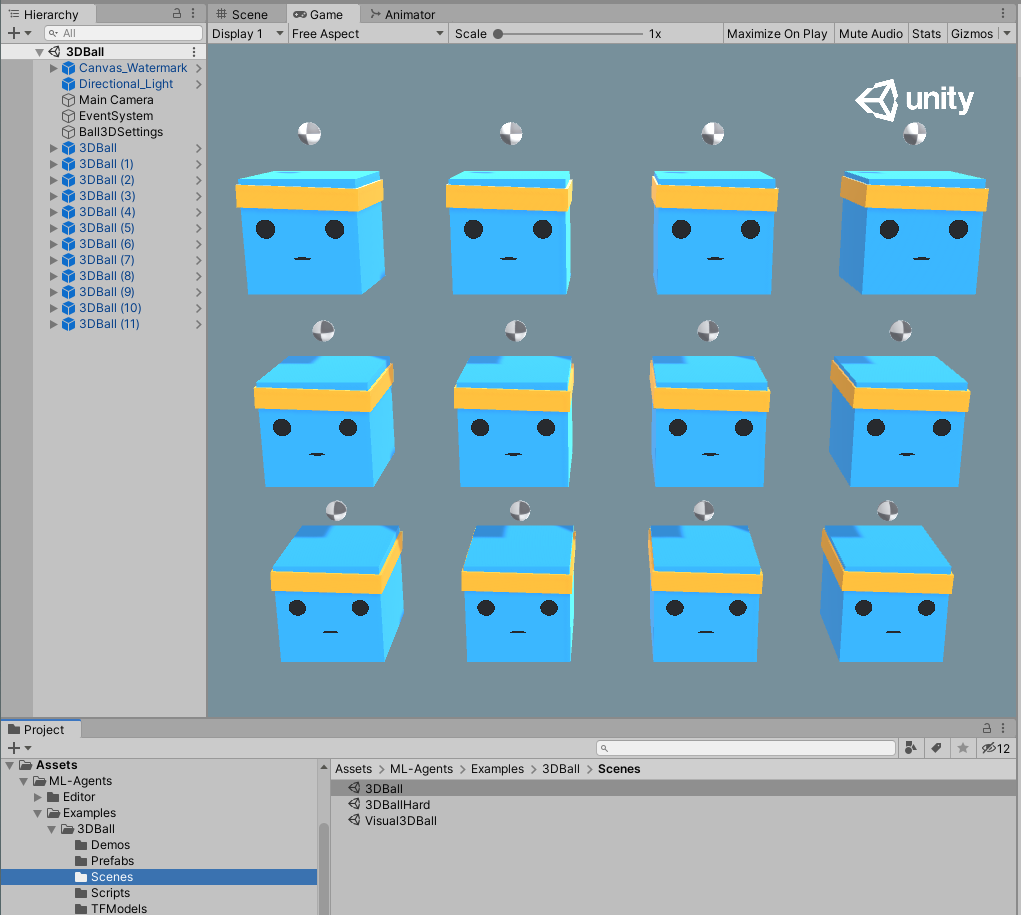
Unity Environment에 대한 이해
유니티에서 Agent는 스스로 환경에 대해 이해하고 상호작용하는 개체입니다. Environment는 하나 이상의 Agent들과 agent들과 상호작용하는 entity들을 포함하는 Scene을 의미합니다.
유니티에서 scene에 있는 모든 object들은 GameObject로 관리되며, 행동(behaviors), 외형(graphics), 물리 로직(physics)들이 포함된 개념입니다. GameObject에 관한 모든 상세사항은 Inspector 윈도우에서 확인하실 수 있습니다.
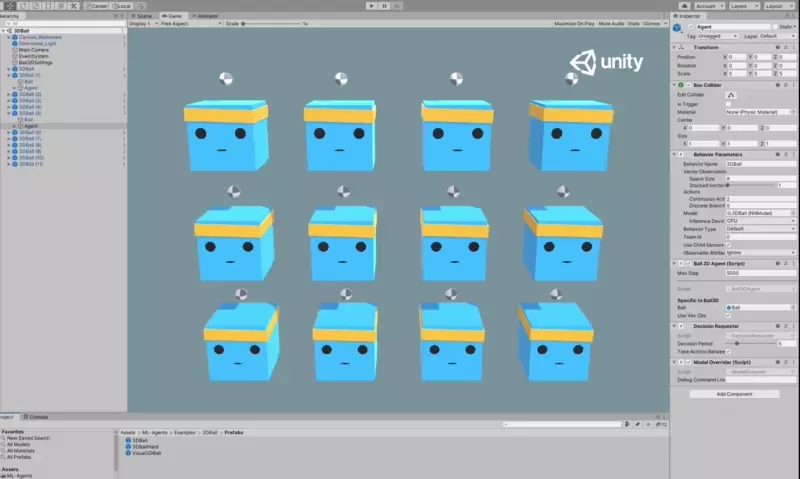
처음에 이 3D Ball을 열었을때, 12개의 상자가 눈에 들어올텐데요. 이 상자들은 게임에서 각각 독립적인 개체로 행동하지만, 12개의 상자들이 모두 같은 로직으로 행동합니다.
즉, 동시에 12개의 상자들로부터 다양한 환경에서의 행동기록을 수집할 수 있다는거죠
Agent
앞서 설명한 Agent에 대해 보다 더 깊이 이해하기 위해서는 Hierarchy 윈도우에서 하나의 3DBall을 확장해봅시다
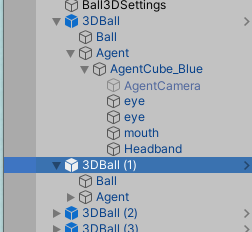
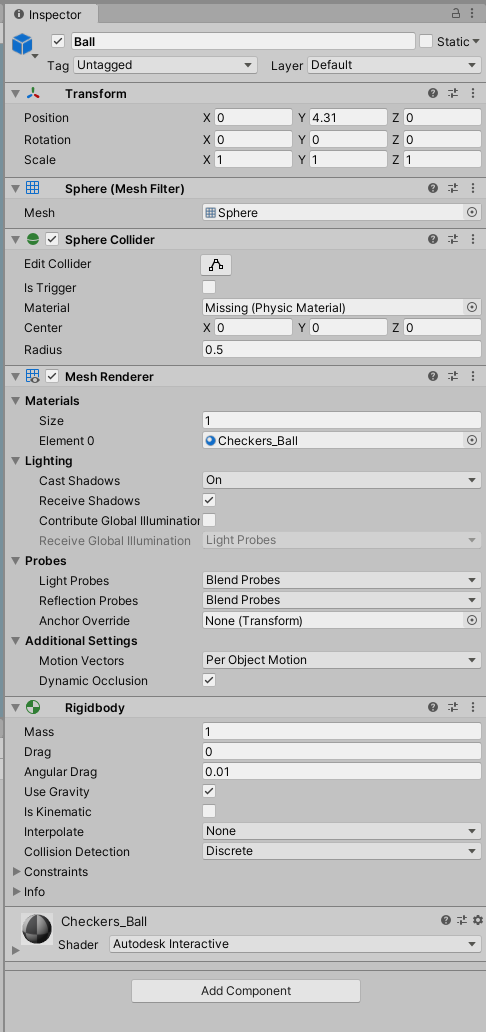
최 상위의 3DBall에서와 달리, 내부의 Ball에서는 공의 속성(외형, 크기, 위치, 물리적 성질(강체))을 확인할 수 있고
Agent에서는 각 상자들이 어떻게 행동할지를 기록하는 Script들이 들어있습니다....만
이거 버전문제인지 제 프로젝트에서는 깨져있다고 나오네요.
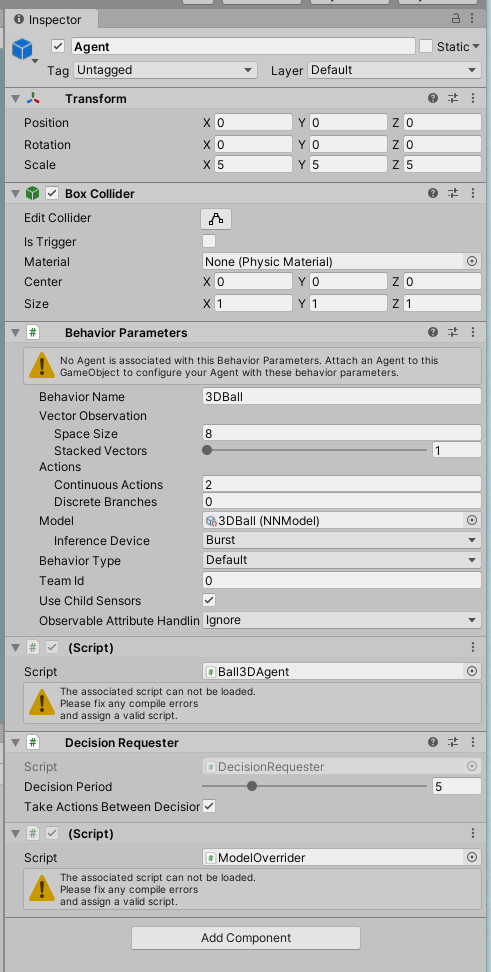
에반데...
일단 콘솔창에 떠있는 에러메시지를 보고 수정해봅시다.
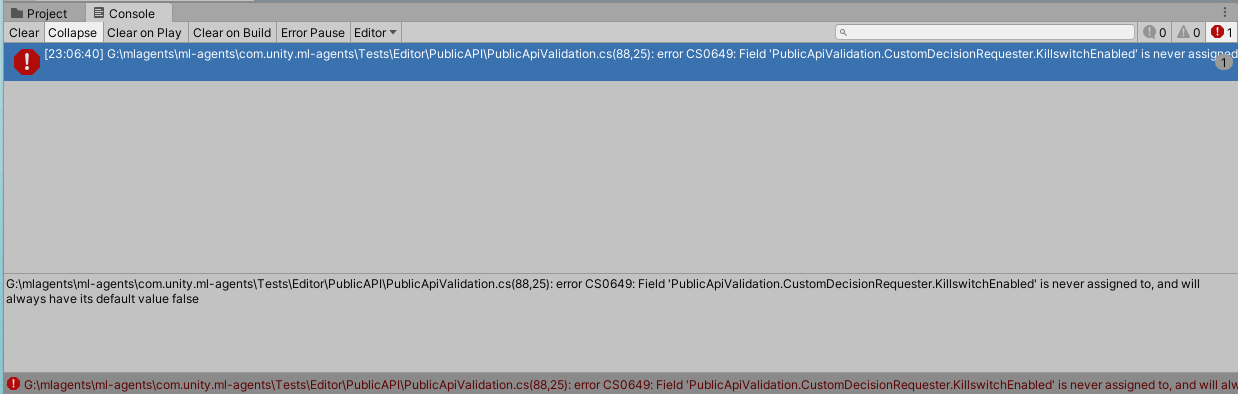
의도한건 아닌데, 딥러닝쪽 동양계 외국 블로그에 도움을 참 많이 받네요.
Pose-estimation할때도 그랬고
Jetson NX할때도 그랬고
정확하게 현 상황과 일치하는 블로그가 있었습니다.
unity2019.4.5f1 Run ML-Agents Error:PublicApiValidation.cs(88,25): error CS0649
중국블로그라 읽을 수 없어서, 내용 중 추가 링크를 다시 따라가보니
ml-agents github Issue tracker
심플하게, 에러가 난 변수의 초기화를 하면 된다는 내용이였습니다.
public bool KillswitchEnabled = false;관련 에러가 사라지긴했는데, 여전히 Script들의 경고 메시지는 남아있네요. 이게 문제가 아니였던거 같습니다.
The associated script can not be loaded.
Please fix any compile errors and assign a valid script.위 에러문구로 검색해보니, 관련 에러가 버전문제나 class명차이 등등 다양한 이유로 발생하는 유니티 고질병인거 같습니다.
[해결법] the associated script can not bo loaded
저의 경우는 reimport했더니 해결되었습니다.
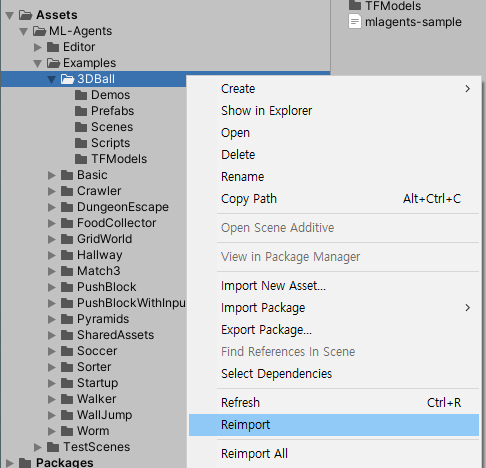
뭔가 길게 돌아온 느낌인데, 다시 원문 내용을 진행해보면
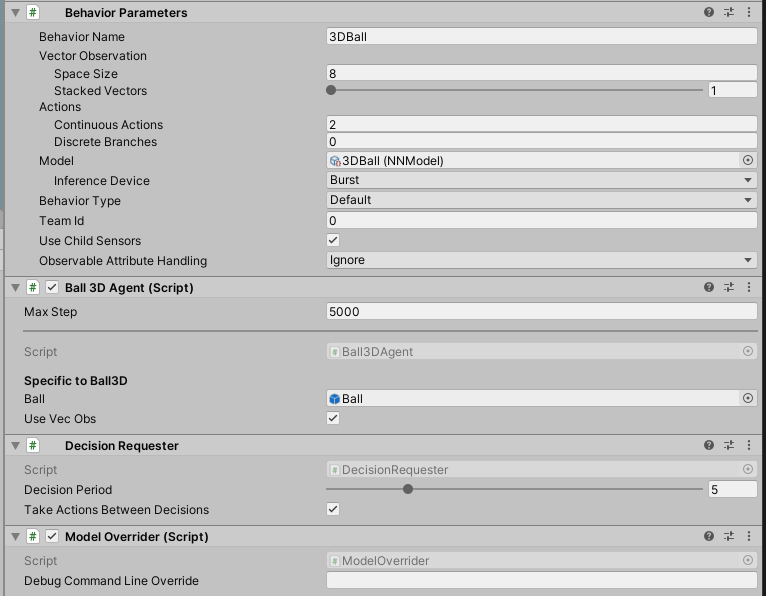
- Agent의 Inspector를 보면 Behavior Parameters 스크립트에서 정의된 수치들을 통해서, 박스가 어떻게 움직일지를 설정할 수 있습니다.
- Model의 부분에는 학습된 강화학습 모델을 지정합니다. 해당 모델은
Examples/3DBall/TFModels에 들어있습니다. - Space Size의 경우, 각 벡터정보를 얼마나 관찰하여 정보로 활용할지에 관한 내용이라고 합니다. x,z방향의 회전, 공의 x,y,z 상대적 위치와 가속도 정보
- Actions에서는 Agent가 행동하는 방법에 대한 정의라고 보시면 될거 같습니다. 연속행동(Continuous)과 구분된(Discrete) 행동으로 나눌 수 있는데, 3D Ball에서는 박스의 x,z rotaion이 주어진 행동이므로 Continuous Actions가 2로 설정되어있습니다.
- Inference Device는 CPU로 설정해봅시다. 다른 옵션들에 대해서는 궁금하긴 한데, 우선 tutorial문서에 추가 설명은 없어서 차후에 나오면 얘기해보겠습니다.
- Model의 부분에는 학습된 강화학습 모델을 지정합니다. 해당 모델은
- 각각의 옵션들은 Project의 prefab을 열어서 하게되면, 전체적용되고, Scene에서 각각의 GameObject를 개별적으로 변경해줄수도 있습니다
여기까지 했으면, 이제 기본 준비가 끝난거 같습니다.
실행버튼을 눌러서 잘 동작하는지 확인해봅시다
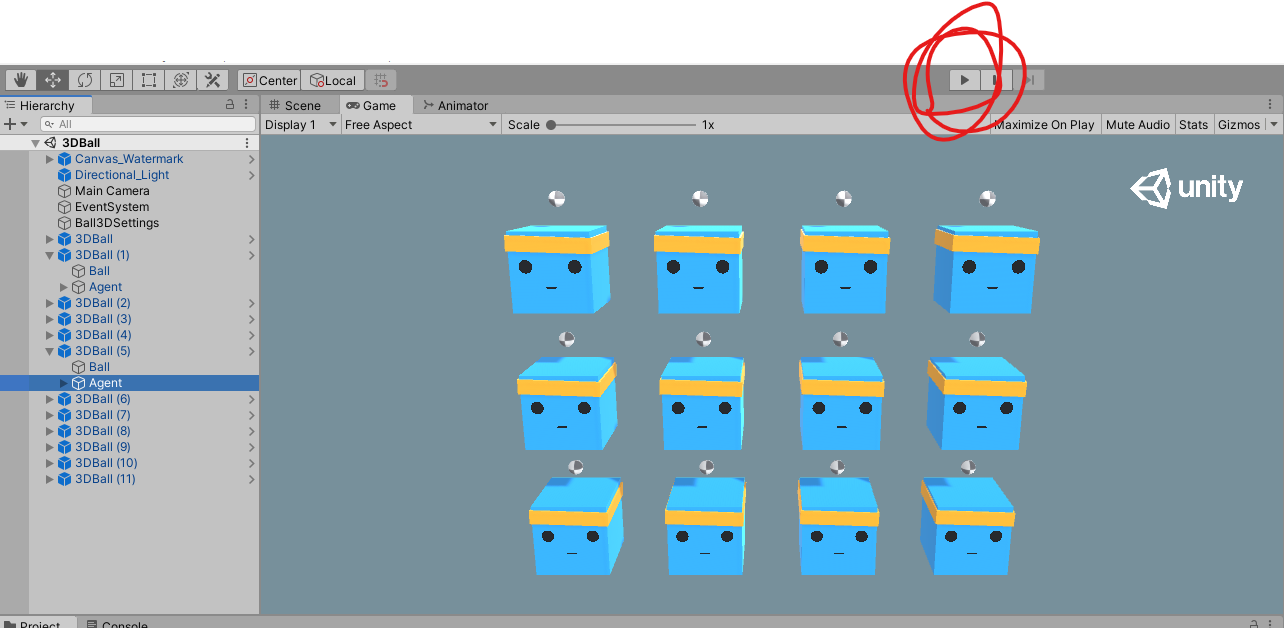
아니 왤케 잘 버티는데
가뿐하게 Max인 5000 Step을 버티고 새로 시작하기까지 해서...
원래는 하나 죽는거 보고 끌려고 했는데, 죽질 않더군요...
Training a new model with Reinforcement Learning
위에서는 기존에 제공된 모델로 동작을 확인해봤지만, 사실 새로운 모델을 만드는 방법을 학습하는게 중요합니다.
다른 사람이 만들어둔 모델로 응용할 수 있는 범위가 큰 다른 분야와 달리 (Ex. 얼굴인식 모델을 만들어두면, 마스크 미착용 인식, 유동인구 분석, 얼굴인식 보안등 활용가능)
강화학습의 경우 환경이 굉장히 유니크하기 때문에 다른분야에 써먹기 어렵죠. (굉장히 유사함에도 불구하고, 위 박스 모델을 카트폴 모델에 그대로 적용하기는 쉽지 않을거 같은 느낌이네요... 될거 같기도 하고?)
자신의 환경을 정의하고 자신의 모델을 만들어 낼 수 있는게 중요합니다.
이번장에서는 mlagents-learn 커맨드를 통해 학습과 추론 양쪽을 경험해보고자 합니다
커맨드 프롬프트를 열어봅시다
(전 보통 win+r 로 실행창을 열고 cmd를 입력합니다)
ml-agents가 설치된 경로로 이동해서
(installation에서 하란대로 했으면, 경로 상관없이 명령어가 실행될거라고 하는데, 전 안되네용. 뭐 안했었는지 한달전이라 기억도 안남)
라고 해서 지난 문서 확인하고 오니 전 기존 활용하던 가상환경으로 세팅했었네요.
테스트삼아 실행해보니 잘됨
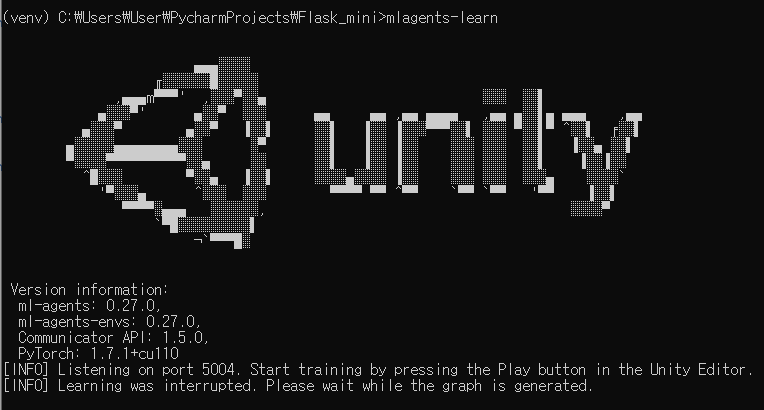
우선 하란대로 mlagents-learn config/ppo/3DBall.yaml --run-id=first3DBallRun 명령어를 통해서 학습을 진행해봅시다.
위 명령어대로 진행하기 위해서는 config파일이 있는 경로에서 명령을 실행하시면 됩니다
대충 요기
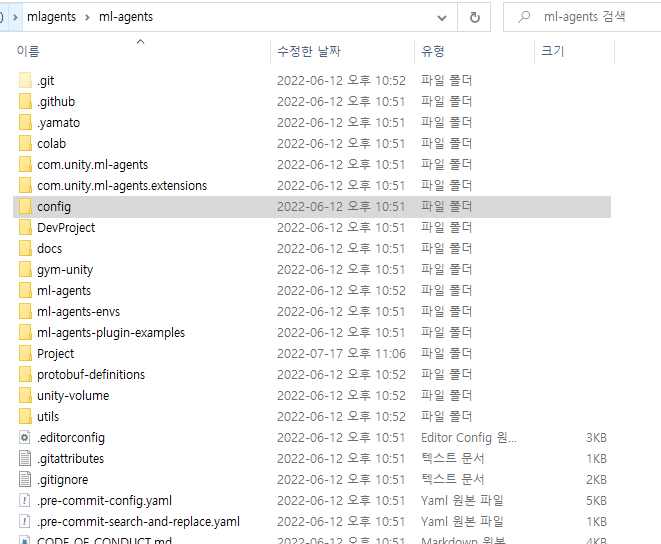
경로 잘못 잡아서 에러났던 모습들
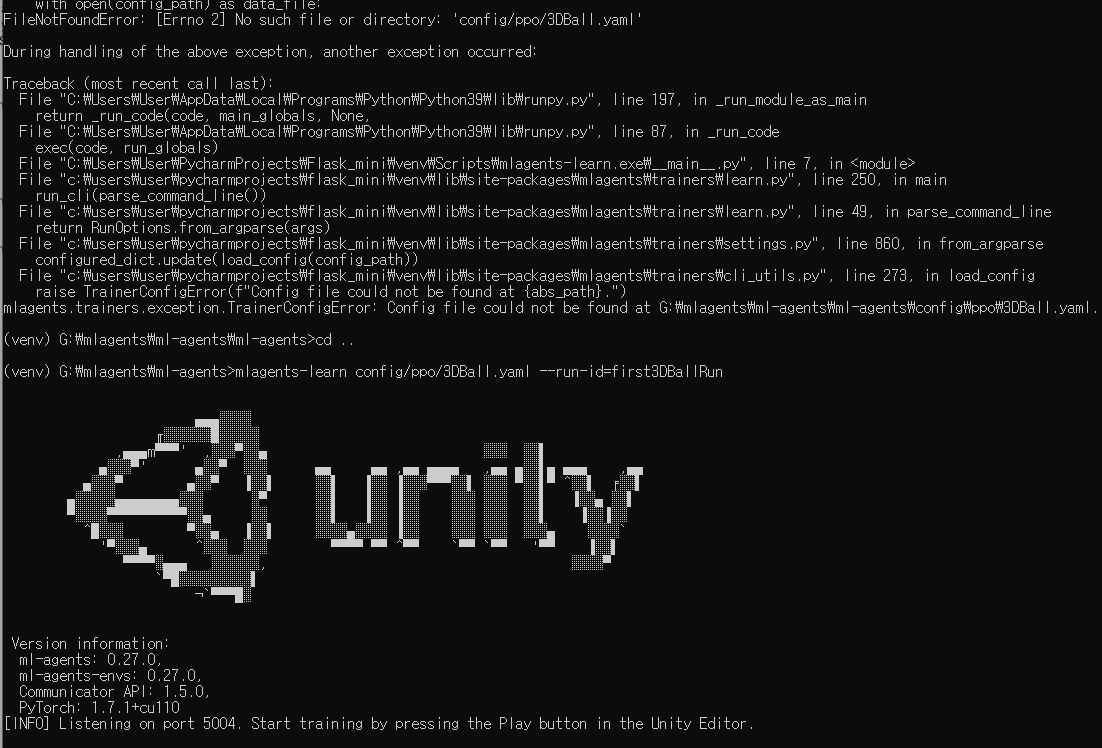
뭔가 돌아가는거 같으니 일단 두고 관련 파일들을 잠깐 열어서 내용을 확인해봅시다.
config/ppo/3DBall.yaml에는 기본 학습 설정이 저장되있다고 합니다.
behaviors:
3DBall:
trainer_type: ppo
hyperparameters:
batch_size: 64
buffer_size: 12000
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 500000
time_horizon: 1000
summary_freq: 12000trainer_type인 ppo가 뭔 의미일지 궁금하긴한데, 나머지 하이퍼 패러미터나 네트워크 세팅같은건 학습모델을 얼마나 세세하게 학습할지를 결정짓는 내용들입니다.
기본 설정은 50만 스텝을 반복하게 되어있네요.
... 침몰
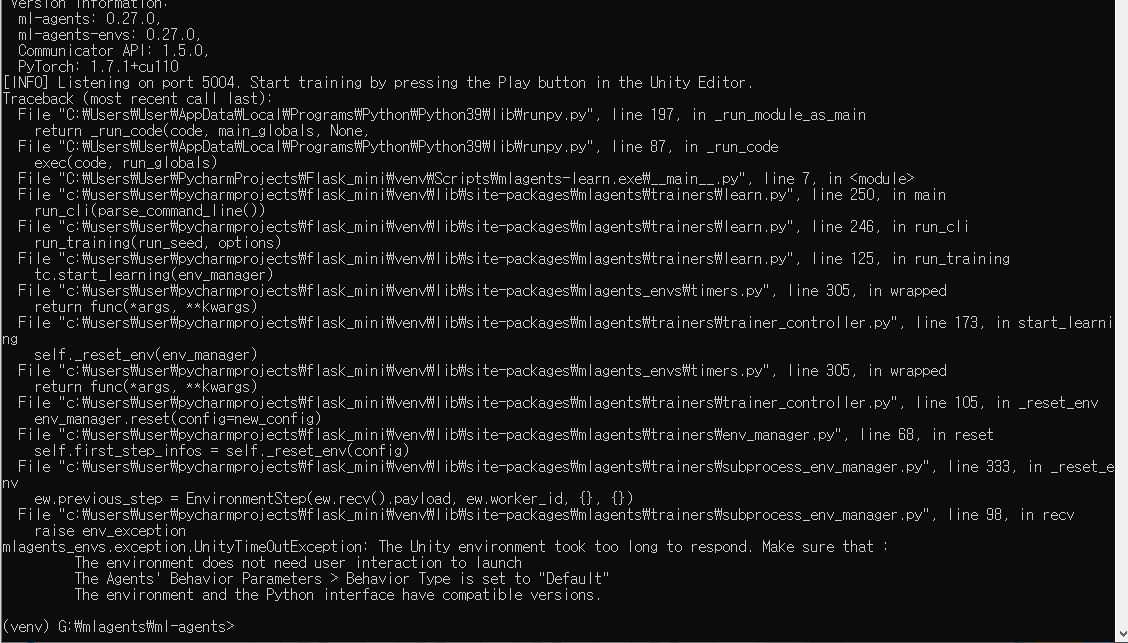
이거 버전문제인거면 진짜 피곤한데.....
현 시점에서 Unity버전 바꾸기도 그렇고, Python버전이야 바꿀 순 있는데 솔직히 귀찮고...
는 돈다 오 개신기
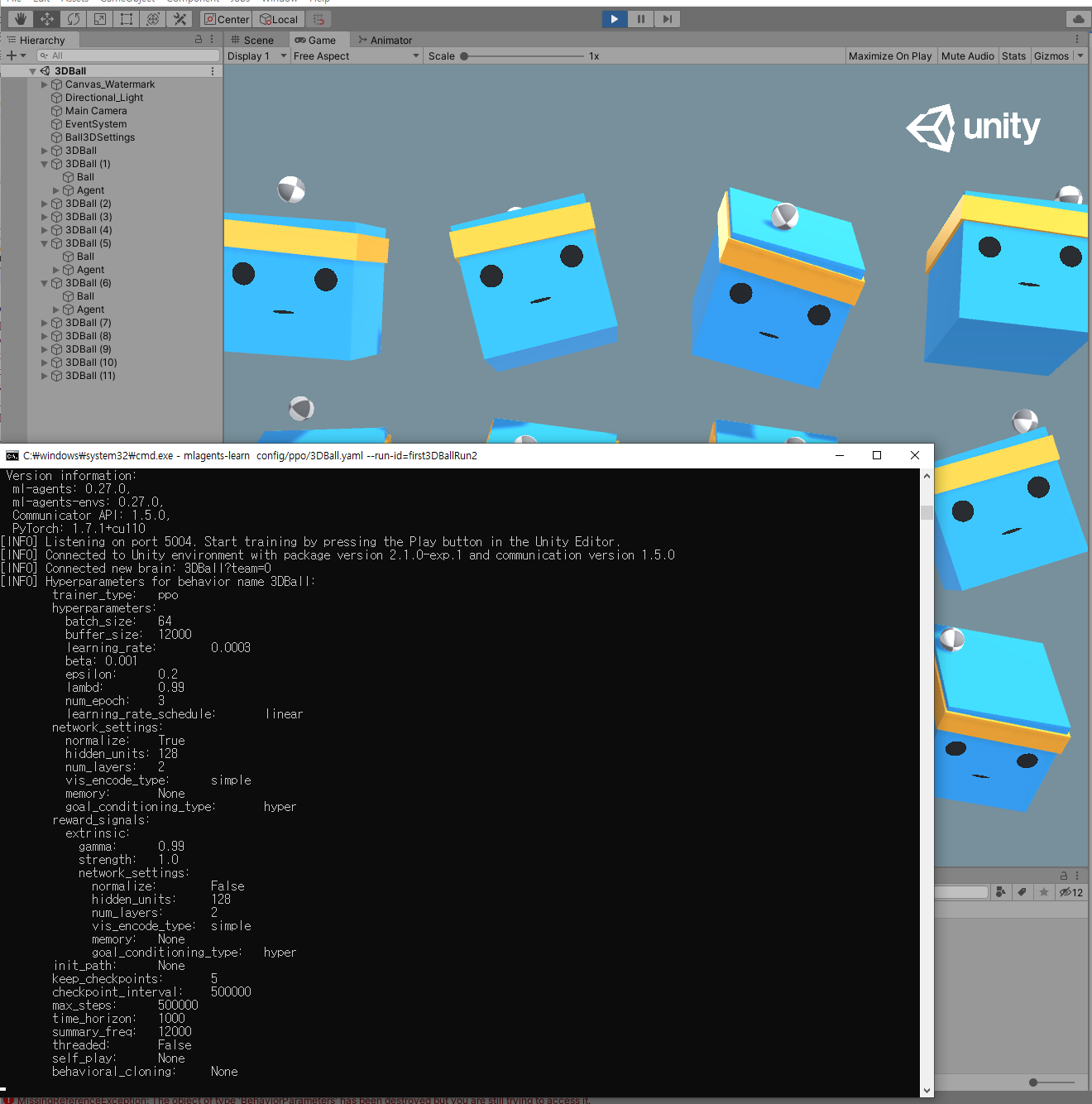
개꿀잼이네 이거 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
튜토리얼의 4번 메시지를 config.yaml 내용 확인하느라 너무 늦게 본게 문제였습니다.
When the message "Start training by pressing the Play button in the Unity Editor" is displayed on the screen, you can press the Play button in Unity to start training in the Editor.
즉, mlagent-learn 실행후에 유니티상에서 Run을 해야지 학습이 연동되서 실행되는것
unity상에서 visual studio code와 연동해서 디버그할때도 이런느낌으로 code에서 디버그 실행하고, 유니티에서 런 따로 해줬는데 비슷한 느낌이네요.
착실하게 스텝이 진행되는 모습
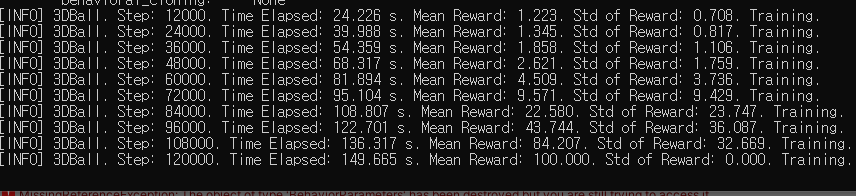
10분도 안되서 25만회를 돌파.
생각보다 금방 결과를 확인할 수 있을거 같습니다.
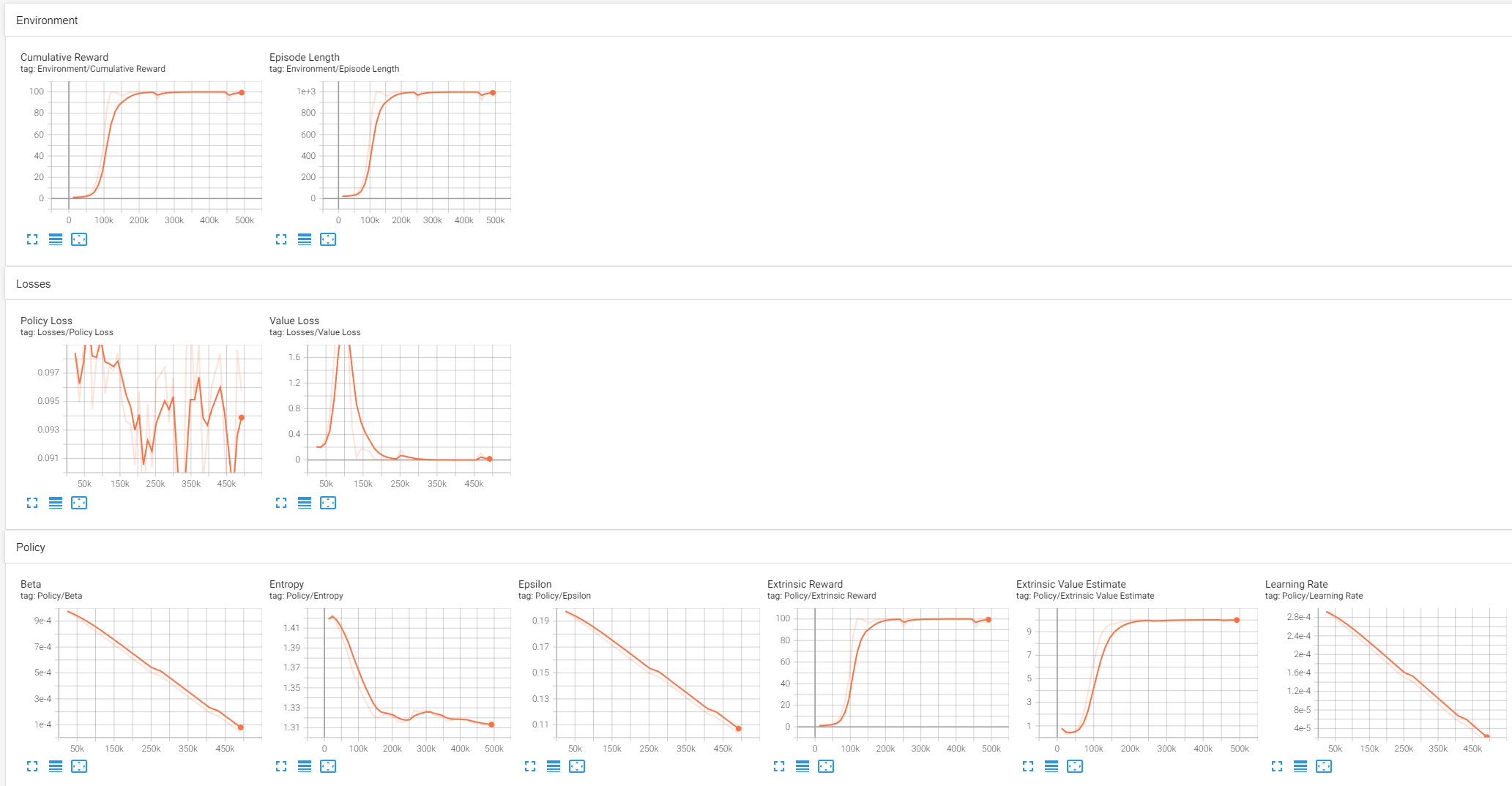
학습이 진행되는 [INFO]메시지에서 Mean Reward가 점진적으로 상향하는지를 살펴보라고 하네요.
아마 공이 중앙에 있을수록 높은 점수(Reward)를 획득하도록 되어있고, 12개의 상자들의 평균 점수가 높은 방향으로 학습되도록 구성되있을거 같습니다.
이쪽에서 Unity Editor상이 아닌, 별도의 빌드로 실행프로그램을 만들어서 학습하는것도 가능하다고 안내하고 있습니다. 아마 이쪽이 학습시간은 더 빠를듯 하네요.
승리
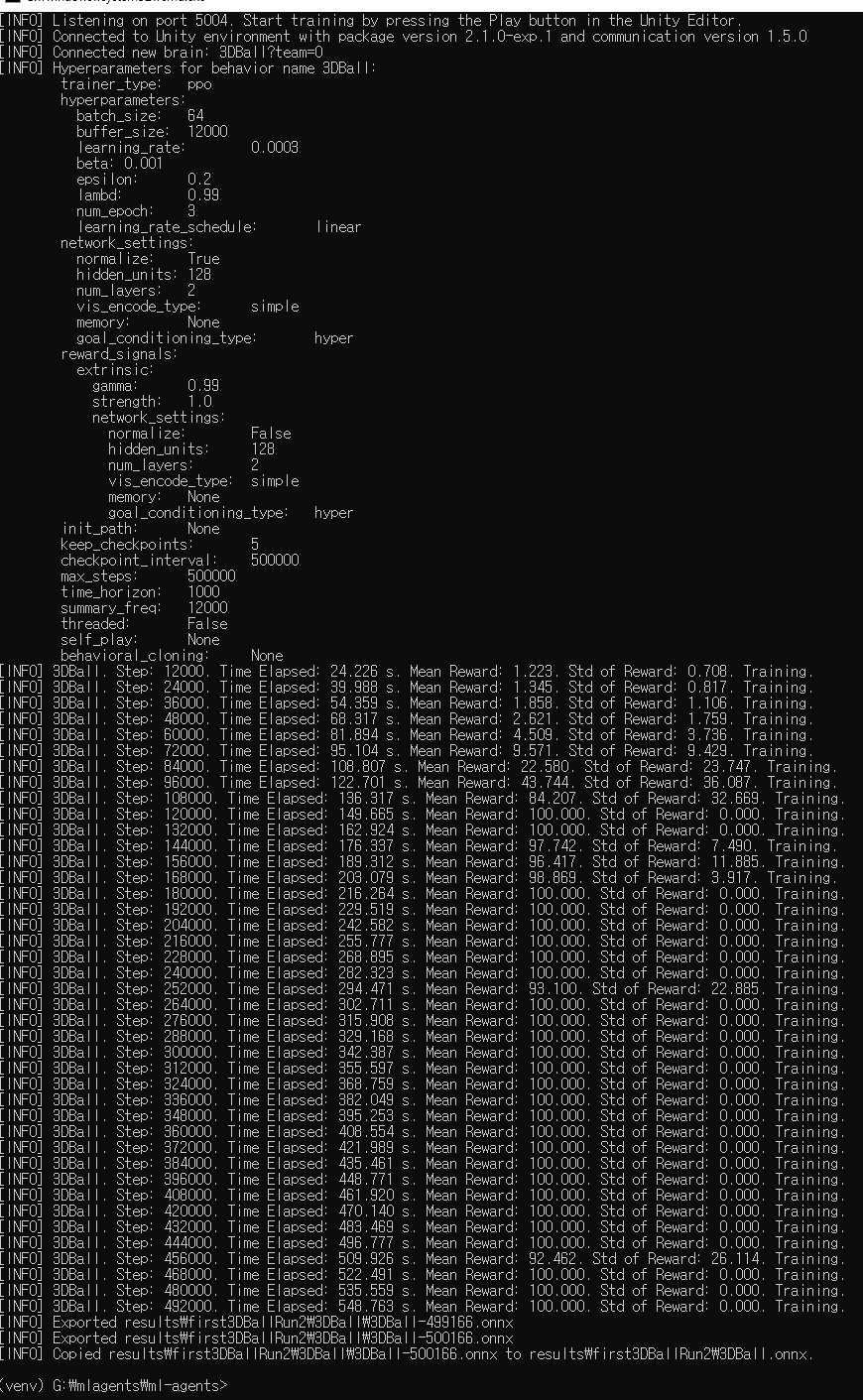
학습이 완료된 후에는 tensorboard를 통해서 결과를 확인할 수 있습니다.
tensorboard --logdir results
별도의 설정이 없었다면 아마 6006 포트로 열릴겁니다
localhost:6006
화면상에서 가장 중요한 결과는 Cumulative Reward라고 하네요
아직은 각 항목들이 그래프를 통해 말하고자 하는 바를 이해하고 있진 않지만, 뭔가 잘 된거 같긴합니다
Embedding the model into the Unity Environment
여기까지 학습페이즈가 잘 완료되었고
이제 이 학습된 모델을 다시 게임에 적용해서 확인해보도록 합시다.
사실, 학습하는 방법을 배워야 한다고 했는데 주어진 명령어를 실행하고 수치가 올라가는걸 확인한것 뿐이라서 뭔가 배웠다고 할 수 있는 단계는 아니지만
그래도 '무언가 해봤다', '이런게 되더라' 라는 경험은 중요합니다.
마지막 종지부를 찍어봅시다.
저의 경우는 result폴더에 학습페이즈에서 지정한 id폴더에 저장되어있습니다
생각했던것보다 훨씬 더 작은 크기의 모델이라 신기하네요.
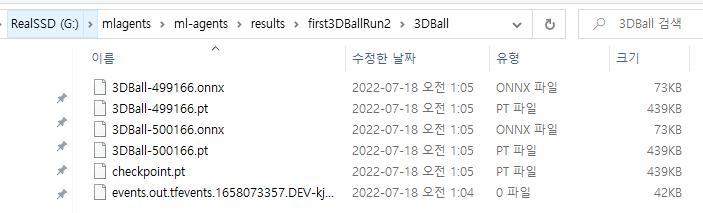
확장자 onnx 파일을 3DBall의 TFModels 경로로 복사해봅시다.
그후 아까와 비슷한 느낌으로 3DBall Prefab을 연 후, 하위 Agent의 Behavior Parameter의 Model항목에 학습된 모델을 드래그 앤 드롭하시면 우리의 모델이 세팅이 됩니다.
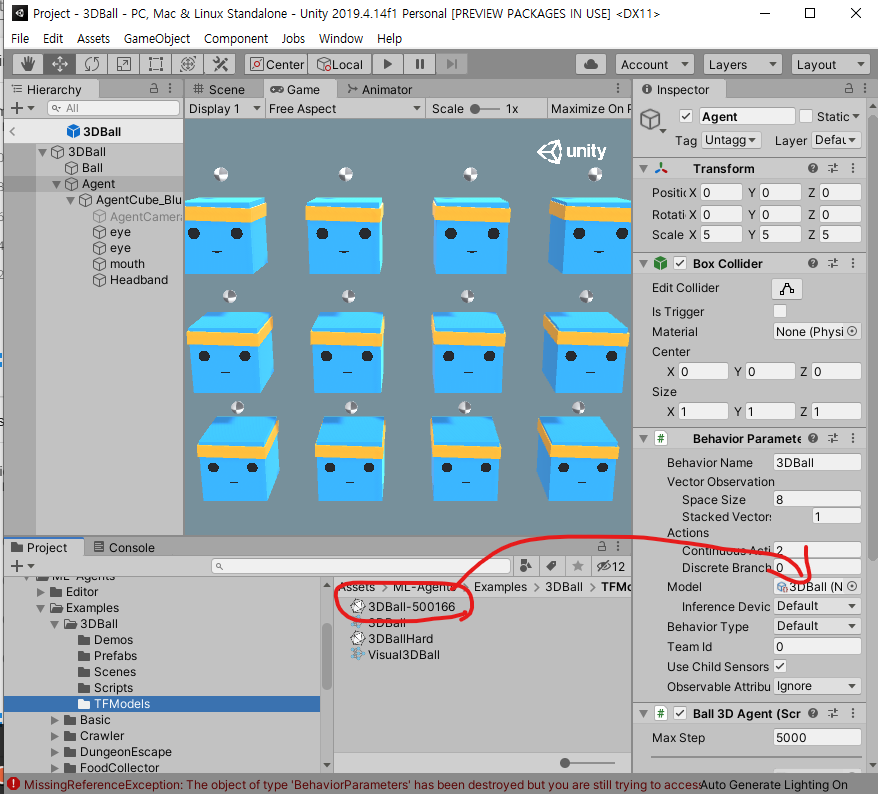

세팅 후 Ctrl+S 누르셔서 저장하신 후, Scene에 있는 3DBall의 Agent로 가서 변경점이 반영됬는지 확인하고 Run해서 테스트해보시면 되겠습니다.
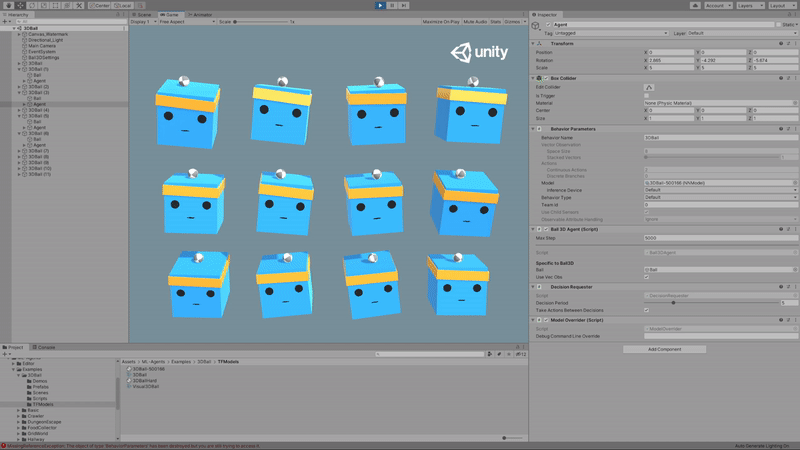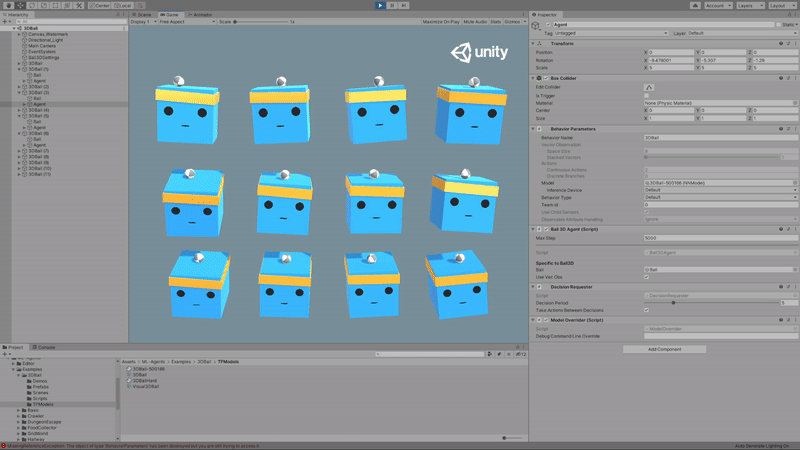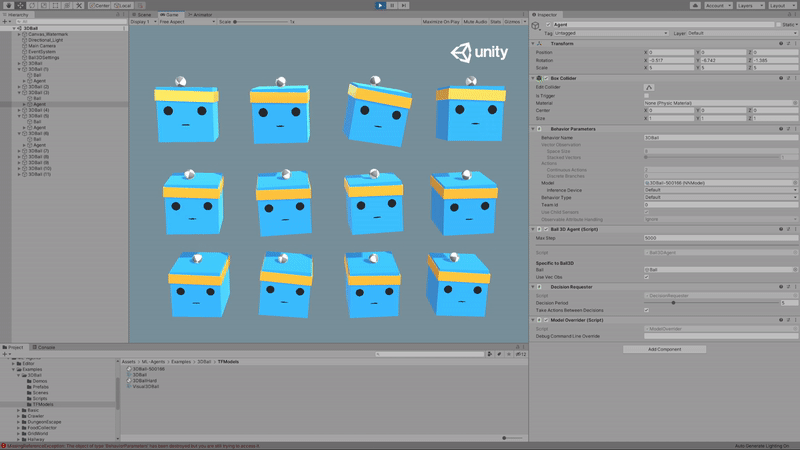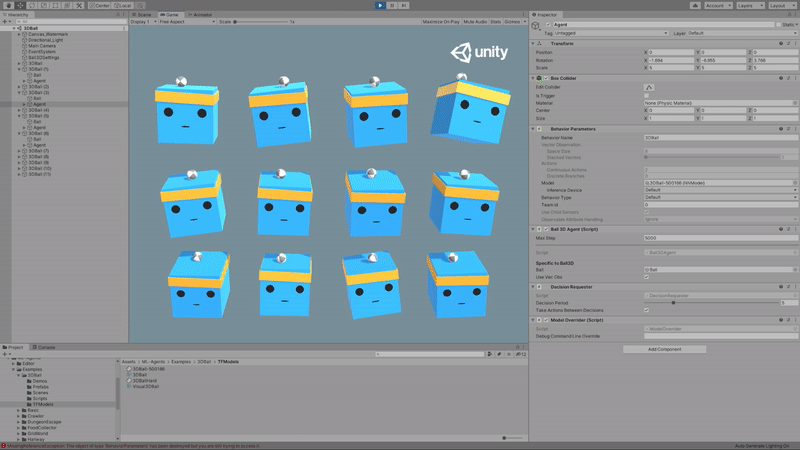
아까 모델보다 훨씬 얌전하게 움직이는 느낌적인 느낌?
보다 격한 환경으로 설정해서 완성된 모델의 성능비교도 해보고 싶지만,
아무튼, 이번 튜토리얼은 여기까지 입니다! 수고 많으셨습니다.
버전문제로 잘 안될까 걱정이 많았는데 생각보다 스무스하게 잘 진행된거 같습니다. 앞으로가 기대되네요.
튜토리얼의 다음 스텝은 아래와 같은데, 아마 순서대로 하나씩 진행해볼거 같습니다.
Next Steps
- For more information on the ML-Agents Toolkit, in addition to helpful background, check out the ML-Agents Toolkit Overview page.
- For a "Hello World" introduction to creating your own Learning Environment, check out the Making a New Learning Environment page.
- For an overview on the more complex example environments that are provided in this toolkit, check out the Example Environments page.
- For more information on the various training options available, check out the Training ML-Agents page.
