HAVING문이 사용된 SQL문 튜닝하기
목표
100만개의 데이터를 삽입한 테이블에서 age가 20 이상 30미만인 직원의 salary 최대값을 조회할 때 index를 사용해 성능을 측정한다.
성능 측정 수치
소요시간(ms)
성능 개선 시 성능이 개선 됐는지 정확한 판단을 하기 위해 개선 이전의 수치와 개선 이후의 수치를 정확히 측정해서 비교할 것
쿼리를 여러 번 실행해 평균적으로 어느 정도의 시간이 소요되는지 측정
과정
-
테이블 생성 및 확인
DROP TABLE IF EXISTS users; CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), age INT, department VARCHAR(100), salary INT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP );
-
users 테이블에 100만개의 데이터 삽입 및 확인
SET SESSION cte_max_recursion_depth = 1000000; INSERT INTO users (name, age, department, salary, created_at) WITH RECURSIVE cte (n) AS ( SELECT 1 UNION ALL SELECT n + 1 FROM cte WHERE n < 1000000 ) SELECT CONCAT('User', LPAD(n, 7, '0')) AS name, FLOOR(1 + RAND() * 100) AS age, CASE WHEN n % 10 = 1 THEN 'Engineering' WHEN n % 10 = 2 THEN 'Marketing' WHEN n % 10 = 3 THEN 'Sales' WHEN n % 10 = 4 THEN 'Finance' WHEN n % 10 = 5 THEN 'HR' WHEN n % 10 = 6 THEN 'Operations' WHEN n % 10 = 7 THEN 'IT' WHEN n % 10 = 8 THEN 'Customer Service' WHEN n % 10 = 9 THEN 'Research and Development' ELSE 'Product Management' END AS department, FLOOR(1 + RAND() * 1000000) AS salary, TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at FROM cte; SELECT COUNT(*) FROM users;
-
인덱스 생성 전 조회 성능 측정 및 실행 계획 조회
# 성능측정 SELECT age, MAX(salary) FROM users GROUP BY age HAVING age >= 20 AND age < 30; -
age 컬럼에 인덱스 생성
CREATE INDEX idx_age ON users (age); SHOW INDEX FROM users; -
age 컬럼에 인덱스 생성 후 조회 성능 측정 및 실행 계획 조회
-- 성능 측정 SELECT age, MAX(salary) FROM users GROUP BY age HAVING age >= 20 AND age < 30; -- 실행 계획 EXPLAIN SELECT age, MAX(salary) FROM users GROUP BY age HAVING age >= 20 AND age < 30; -- 실행 계획 세부 내용 EXPLAIN ANALYZE SELECT age, MAX(salary) FROM users GROUP BY age HAVING age >= 20 AND age < 30;
-
성능 개선을 위한 SQL문 튜닝
→ HAVING절의 조건을 WHERE절로 변경SELECT age, MAX(salary) FROM users WHERE age >= 20 AND age < 30 GROUP BY age; -
SQL문 튜닝 후 조회 성능 측정 및 실행 계획 조회
-- 성능 측정 SELECT age, MAX(salary) FROM users WHERE age >= 20 AND age < 30 GROUP BY age; -- 실행 계획 EXPLAIN SELECT age, MAX(salary) FROM users WHERE age >= 20 AND age < 30 GROUP BY age; -- 실행 계획 세부 내용 EXPLAIN ANALYZE SELECT age, MAX(salary) FROM users WHERE age >= 20 AND age < 30 GROUP BY age;
결과
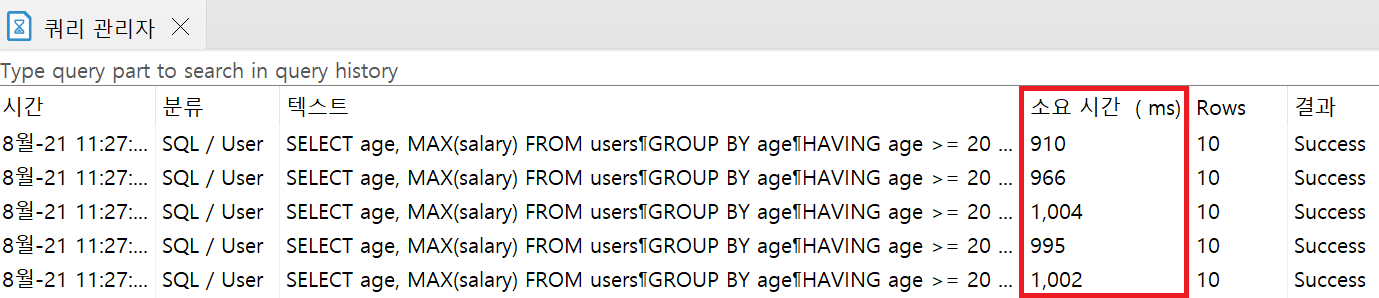
인덱스 생성 전
- 평균 소요시간 975.4ms
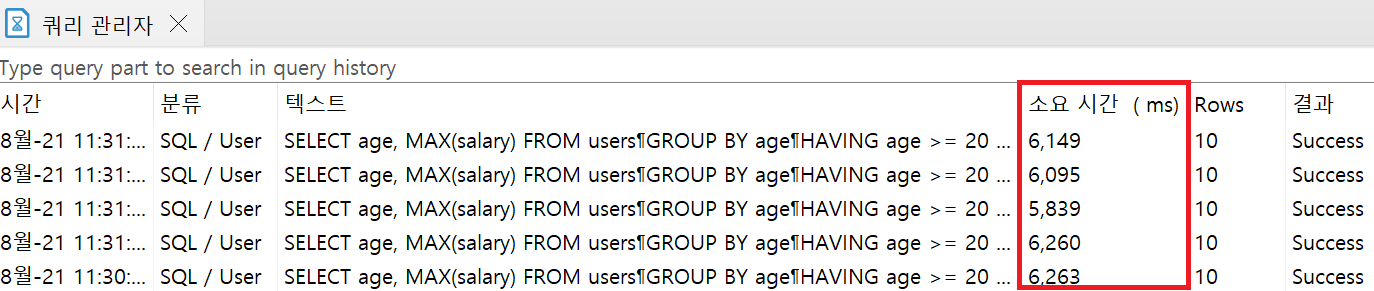
age 컬럼에 인덱스 생성 후
- 평균 소요시간 6,121.2ms
- type: index ➡️ Index Full Scan
- key: idx_age ➡️ 사용한 인덱스
- rows: 996,433 ➡️ 996,433개의 데이터에 접근
- 세부 내용: users 테이블에 대해 Index Full Scan을 진행하여 100만개의 rows에 접근 후 age컬럼을 기준으로 그룹화와 salary 데이터에 대한 집계 진행. 마지막에 age에 대한 조건을 충족시키는 10개 데이터 조회


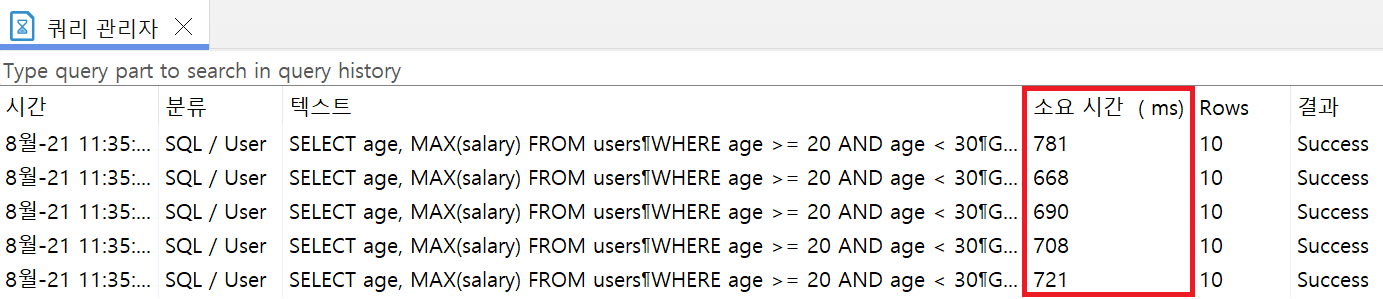
age 컬럼에 인덱스 생성 및 SQL문 튜닝 후
- 평균 소요시간 713.6ms
- type: index ➡️ Index Range Scan
- key: idx_age ➡️ 사용한 인덱스
- rows: 201,800 ➡️ 201,800개의 데이터에 접근
- 세부 내용: users 테이블에 대해 Index Range Scan을 진행하여 age컬럼에 대한 조건에 맞는 99948개의 rows에 접근 후 age컬럼을 기준으로 그룹화와 salary 데이터에 대한 집계 진행하여 10개 데이터 조회


결론
인덱스 생성 전 평균 소요시간은 975.4ms였지만 age컬럼에 인덱스를 생성한 뒤 성능 측정을 하니 평균 소요시간이 6,121.2ms로 오히려 성능이 낮아졌다.
실행 계획 세부내용을 보면 조건이 HAVING절에 있기 때문에 index full scan을 먼저 진행함으로써 거의 모든 행에 접근하게 되며, 이 많은 데이터를 바탕으로 그룹화와 집계를 진행하는데 시간이 많이 소요되었음을 알 수 있다. 또한 age 컬럼에 대해 스캔을 했지만 이후에 HAVING절의 조건에 부합하는 데이터를 찾기 위해 또 다시 age컬럼에 대해 접근을 하니 비효율적이다.
하지만 HAVING절의 age조건을 WHERE문으로 변경한 뒤 성능 측정을 하니 WHERE절의 조건을 먼저 읽은 뒤 그 조건에 맞게 index range scan으로 99948개의 rows에만 접근함으로써 접근한 행 수와 소요시간이 대폭 줄어든 것을 확인할 수 있었다. 처음부터 접근한 행 수가 줄어들어 그룹화를 진행하는데도 소요시간이 짧게 걸린다. 이는 인덱스 생성 전보다 소요시간이 약 3분의 1 단축된 결과이다.
결론적으로, 그룹화를 진행해야하는 SQL문으로 조회를 할 때 반드시 HAVING절에 조건을 두어야 하는 것이 아닌 상황이라면 WHERE절에 조건을 두는 것이 성능 측면에서 효율적일 수 있다는 ㅣ사실을 확인했다.
참고
https://www.inflearn.com/course/%EB%B9%84%EC%A0%84%EA%B3%B5%EC%9E%90-mysql-%EC%84%B1%EB%8A%A5%EC%B5%9C%EC%A0%95%ED%99%95-sql%ED%8A%9C%EB%8B%9D
<비전공자도 이해할 수 있는 MySQL 성능 최적화 입문/실전 (SQL 튜닝편)> 강의를 토대로 작성한 내용입니다.
