WHERE문과 ORDER BY문이 모두 사용된 SQL문에 각각 인덱스를 생성하여 성능 비교하기
목표
100만개의 데이터를 삽입한 테이블에서 다양한 조건을 만족하는 100개의 데이터를 찾기 위해 WHERE문과 ORDER BY문이 모두 사용된 SQL문 작성시 WHERE문과 ORDER BY문 둘 중 어디에 인덱스를 생성하는것이 효율적인지 비교해본다.
성능 측정 수치
소요시간(ms)
성능 개선 시 성능이 개선 됐는지 정확한 판단을 하기 위해 개선 이전의 수치와 개선 이후의 수치를 정확히 측정해서 비교할 것
쿼리를 여러 번 실행해 평균적으로 어느 정도의 시간이 소요되는지 측정
과정
-
테이블 생성 및 확인
DROP TABLE IF EXISTS users; CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), department VARCHAR(100), salary INT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP );
-
users 테이블에 100만개의 데이터 삽입 및 확인
SET SESSION cte_max_recursion_depth = 1000000; INSERT INTO users (name, department, salary, created_at) WITH RECURSIVE cte (n) AS ( SELECT 1 UNION ALL SELECT n + 1 FROM cte WHERE n < 1000000 ) SELECT CONCAT('User', LPAD(n, 7, '0')) AS name, CASE WHEN n % 10 = 1 THEN 'Engineering' WHEN n % 10 = 2 THEN 'Marketing' WHEN n % 10 = 3 THEN 'Sales' WHEN n % 10 = 4 THEN 'Finance' WHEN n % 10 = 5 THEN 'HR' WHEN n % 10 = 6 THEN 'Operations' WHEN n % 10 = 7 THEN 'IT' WHEN n % 10 = 8 THEN 'Customer Service' WHEN n % 10 = 9 THEN 'Research and Development' ELSE 'Product Management' END AS department, FLOOR(1 + RAND() * 1000000) AS salary, TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at FROM cte; SELECT COUNT(*) FROM users;
-
인덱스 생성 전 조회 성능 측정 및 실행 계획 조회
# 성능측정 SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100; # 실행 계획 조회 EXPLAIN SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100; -
ORDER BY문의 salary 컬럼에 인덱스 생성
CREATE INDEX idx_salary ON users (salary); SHOW INDEX FROM users; -
salary 컬럼에 인덱스 생성 후 조회 성능 측정 및 실행 계획 조회
-- 성능 측정 SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100; -- 실행 계획 EXPLAIN SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100; -- 실행 계획 세부 내용 EXPLAIN ANALYZE SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100;
-
salary컬럼에 생성한 인덱스 삭제 후 WHERE문의 created_at컬럼에 인덱스 생성
ALTER TABLE users DROP INDEX idx_salary; CREATE INDEX idx_created_at ON users (created_at); SHOW INDEX FROM users; -
created_at 컬럼에 인덱스 생성 후 조회 성능 측정 및 실행 계획 조회
-- 성능 측정 SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100; -- 실행 계획 EXPLAIN SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100; -- 실행 계획 세부 내용 EXPLAIN ANALYZE SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY) AND department = 'Sales' ORDER BY salary LIMIT 100;
결과
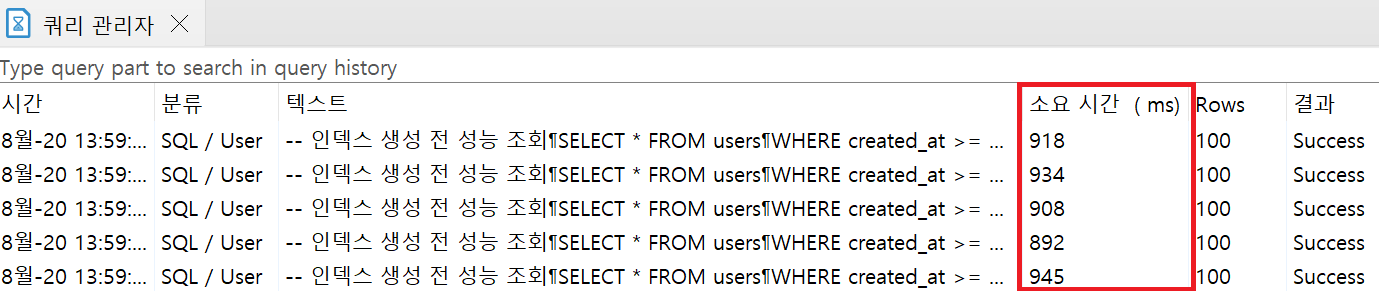
인덱스 생성 전
- 평균 소요시간 919.4ms
- type: ALL ➡️ Full Table Scan
- rows: 996,637 ➡️ 996,637개의 데이터에 접근
- 세부 내용: users 테이블에 대해 Full Table scan 진행하여 100개 데이터 조회

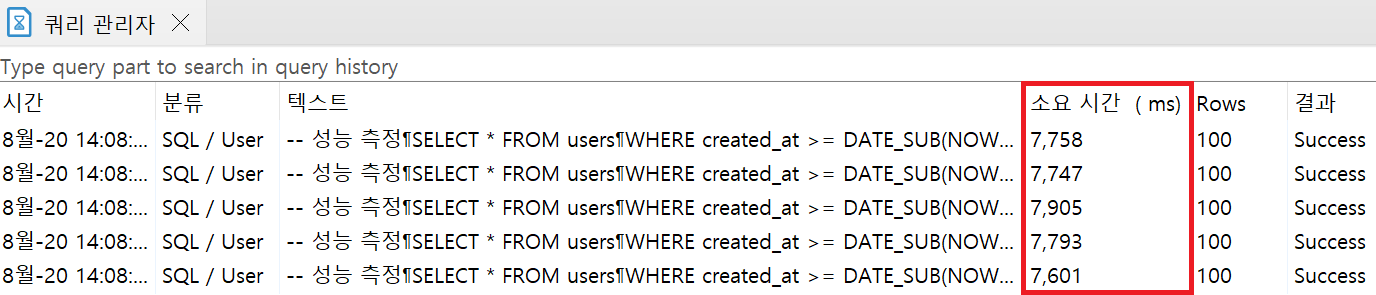
ORDER BY문의 salary 컬럼에 인덱스 생성 후
- 평균 소요시간 7760.8ms
- type: index ➡️ Index Full Scan
- key: idx_salary ➡️ 사용한 인덱스
- rows: 100 ➡️ 100개의 데이터에 접근
- 세부 내용: users 테이블에 대해 Index Full Scan 진행 후 100개 데이터 조회
처음에 index full scan으로 994108개의 rows에 접근 후 WHERE문 조건 필터링


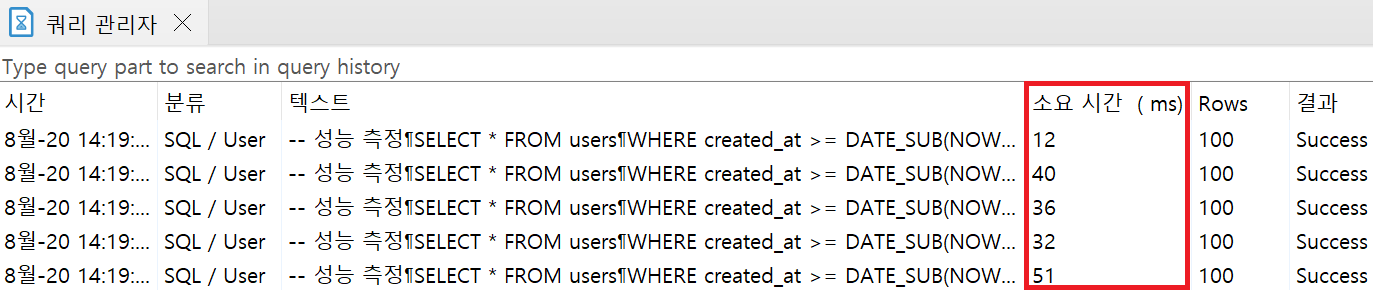
WHERE문의 created_at 컬럼에 인덱스 생성 후
- 평균 소요시간 34.2ms
- type: index ➡️ Index Range Scan
- key: idx_created_at ➡️ 사용한 인덱스
- rows: 1069 ➡️ 1069개의 데이터에 접근
- 세부 내용: users 테이블에 대해 Index Range Scan 진행 후 100개 데이터 조회
처음에 index range scan으로 1069개의 rows에 접근 후 WHERE문 조건 필터링


결론
인덱스 생성 전 평균 소요시간은 919.4ms.
먼저 ORDER BY문의 salary 컬럼에 인덱스를 생성한 뒤 성능 측정을 하니 처음 index full scan을 할 때 994108개의 rows에 접근하여 filtering을 진행 했으며 평균 소요시간이 7760.8ms로 오히려 성능이 낮아졌다.
하지만 WHERE문의 created_at 컬럼에 인덱스를 생성한 뒤 성능 측정을 하니 index range scan을 하여 1,069개의 rows에만 접근을 했으며 filtering 진행 시간까지의 소요시간이 훨씬 줄어든 것을 확인 할 수 있었다. 평균 소요시간은 34.2ms로, 인덱스 생성 전보다 소요시간이 약 27분의 1로 단축되었다.
결론적으로, WHERE절과 ORDER BY절이 모두 존재하는 SQL문에서는 WHERE절의 조건에 해당하는 컬럼에 index를 생성함으로써 접근 rows의 갯수를 줄이는 것이 성능 측면에서 훨씬 효율적인 작업이라는 것을 확인 할 수 있었다.
하지만 모든 SQL문에서 적용되는 것은 아닐 수 있으니 성능 측정과 실행계획 조회는 습관적으로 해 주자.
✅ 짚고 넘어가기
1. 인덱스 사용 후 더 낮아진 검색 성능
인덱스를 사용해본 이래 처음으로 인덱스를 사용한 뒤 성능이 더 떨어진 경우를 만났다.
인덱스를 생성하기 전 평균 919.4ms의 성능을 보였던 반면, ORDER BY문의 salary 컬럼에 인덱스를 생성한 뒤 성능 측정을 하니 평균 7760.8ms로 오히려 소요시간이 8배 증가했다.
소요시간이 증가한 이유는 salary 컬럼에 index를 생성했을 때 해당 테이블은 id와 salary 컬럼만 가지고 있기 때문에 WHERE문의 조건을 만족하기 위한 created_at 컬럼과 department 컬럼에 접근하려면 다시 원본 테이블에 접근해야하기 때문이다.
2. WHERE구문에서 사용된 두 컬럼 중 created_at 컬럼에 인덱스를 생성한 이유
WHERE구문에 created_at 컬럼과 department 컬럼에 대한 두 조건이 걸려 있었는데 왜 department 컬럼이 아닌 created_at 컬럼에 인덱스를 생성했을까?
그 이유는 created_at 컬럼이 department 컬럼보다 고유성이 짙은 컬럼이기 때문이다. 또한 3일 이내라는 더 구체적인 조건이 더해져 created_at 컬럼에 인덱스를 생성할 경우 더 적은 수의 rows에 접근할 것이며 소요시간이 더 적을 것이라는 유추를 할 수 있다.
이에 관한 실습은 다음의 포스팅에서 확인 가능하다.
https://velog.io/@iiingkeep/MySQL-성능-최적화-데이터베이스-튜닝-실습-7-WHERE문이-사용된-SQL문-튜닝2
참고
https://www.inflearn.com/course/%EB%B9%84%EC%A0%84%EA%B3%B5%EC%9E%90-mysql-%EC%84%B1%EB%8A%A5%EC%B5%9C%EC%A0%95%ED%99%95-sql%ED%8A%9C%EB%8B%9D
<비전공자도 이해할 수 있는 MySQL 성능 최적화 입문/실전 (SQL 튜닝편)> 강의를 토대로 작성한 내용입니다.
