실행 계획 조회하기
목표
특정 데이터 조회 시 실행 계획을 사용해 보고 실행 계획이 나타내는 항목들을 통해 해석해본다.
실행 계획이란?
옵티마이저(Optimizer)는 사용자가 질의한 SQL문에 대해 최적의 실행방법을 결정하는 역할을 수행하는데, 이 최적의 실행방법을 '실행 계획'이라고 한다.
과정
-
테이블 생성 및 확인
DROP TABLE IF EXISTS users; # 기존 테이블 삭제 CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), age INT ); SELECT * FROM users;
- 데이터 삽입
INSERT INTO users (name, age) VALUES ('박미나', 26), ('김미현', 23), ('김민재', 21), ('이재현', 24), ('조민규', 23), ('하재원', 22), ('최지우', 22);
- 실행 계획 조회
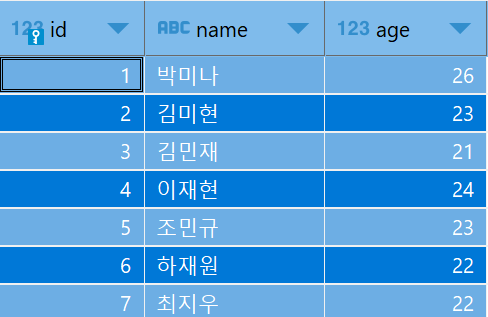
위의 테이블에서 age = 23인 유저만을 조회해오는 작업을 할 것이다.
가시적으로 나타낸다면 다음과 같다.
<users 테이블>
 <age = 23인 유저만을 조회하는 SQL문 실행 후 ↓>
<age = 23인 유저만을 조회하는 SQL문 실행 후 ↓>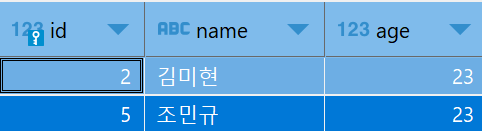
users 테이블에서 age = 23인 유저를 조회하는 아래 SQL문에 대한 실행 계획을 조회하기
실행 계획 조회
EXPLAIN [SQL문]
EXPLAIN SELECT * FROM users
WHERE age = 23;-
실행 계획에 대한 세부 정보 조회
실행 계획 세부 정보 조회
EXPLAIN ANALYZE [SQL문]users 테이블에서 age = 23인 유저를 조회하는 아래 SQL문에 대한 실행 계획 세부정보를 조회하기
EXPLAIN ANALYZE SELECT * FROM users WHERE age = 23;
실행 계획 조회 결과
실행 계획을 조회하면 총 12개 항목에 대해 실행 방법을 결정하는 것을 알 수 있다. 간단한 SQL문을 조회한 것이라 NULL 값이 많이 포함되어 있다.


-
id: 실행 순서. 위의 예시는 단순한 sql문이라 계획을 한 가지만 생성했지만 복잡한 sql문을 다룰 때 여러 실행 계획을 세운다.
-
select_type: 쿼리의 종류(SIMPLE, PRIMARY, SUBQUERY, DERIVED등)
-
table: 조회한 테이블 명
-
partitions: 접근한 파티션 목록
-
type: 테이블의 데이터를 조회하는 방식
-
possible keys: 사용 가능한 인덱스 목록
-
key: 데이터 조회시 실제로 사용한 인덱스 값
-
key_len: 사용한 인덱스의 byte 수
-
ref: 테이블 조인 상황에서의 데이터 조회 기준값
-
rows: SQL문 수행을 위해 접근한 데이터의 모든 행의 수. 낮을수록 성능 ↑
-
filtered: 필터 조건에 따라 실제 사용될 것으로 예측되는 레코드 건수의 비율. 높을수록 성능 ↑
-
Extra: 부가 정보
이외에 각 항목마다 옵션들이 많지만 세부 옵션들은 다른 포스팅에 담도록 하겠다.
위의 12가지 항목 중 SQL 튜닝에서 중요하게 사용되는 항목은 bold 체로 표시했으며, 여기에서의 핵심 항목은 다음과 같다.✅ SQL튜닝의 핵심은 rows에 있다.
실행 계획에 대한 해석
- id: 1
한 개의 쿼리를 실행 - select_type: SIMPLE
UNION이나 SUBQUERY를 사용하지 않은 단순한 SELECT 쿼리 - table: users
users 테이블 사용 - type: ALL
인덱스 활용 없이 테이블을 전부 뒤져서 데이터를 찾는 Full Table Scan - rows: 7
7개 행에 접근. - filtered: 14.29
필터링 후 14.29%의 비율로 레코드가 실제로 사용될 것을 예측 - Extra: Using where
where문을 사용
실행 계획에 대한 세부 정보 조회 결과
다음과 같이 EXPLAIN 컬럼에 아주 긴 구문이 결과로 나온다.
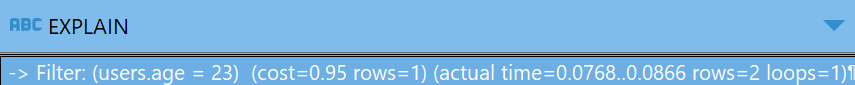
실행 계획에 대한 세부 정보 해석
위에서 나온 EXPLAIN컬럼의 값을 확인해보면 다음과 같다.
-> Filter: (users.age = 23) (cost=0.95 rows=1) (actual time=0.0473..0.0547 rows=2 loops=1)
-> Table scan on users (cost=0.95 rows=7) (actual time=0.0435..0.052 rows=7 loops=1)
-
아래의 결과부터 읽는다.
- Table scan on users: users 테이블을 풀 스캔
- rows: 접근한 데이터 행의 수는 7개
- actual time
0.0435 - 첫 번째 데이터에 접근하기까지의 시간(ms)
0.052 - 마지막 데이터에 접근하기까지의 시간(ms)
-
위의 결과를 읽는다.
-
Filter: (users.age = 23) : users테이블에서 age=23의 조건으로 데이터 필터링
-
총 작업을 수행하는 데 걸린 시간: 0.0547ms
-
필터링에 걸린 시간: 0.0547 - 0.052 = 0.0027ms
-
결론
SELECT * FROM users
WHERE age = 23;users 테이블에서 age=23인 user를 조회하기 위해 사용한 위의 SQL문은 해당 테이블의 모든 행에 접근해 데이터를 확인 후 조건을 만족하는 데이터만 필터링 해 조회해왔으므로 효율적이지 못한 SQL문이라고 할 수 있다.
age컬럼에 인덱스를 추가하는 등의 작업을 더해 조회 성능을 향상시킬 수 있겠다.
지금까지 SQL문을 실행해 걸리는 소요 시간으로 성능을 측정해 왔는데 실행 계획을 조회하니 항목별로 세부적인 확인이 가능해 SQL문 작성 시 고려해야 할 부분을 더 직관적으로 알 수 있게 됐다. 앞으로 더 복잡한 SQL문 작성 시 성능 개선을 위해 이용할 일이 많지 않을까 싶다.
참고
https://www.inflearn.com/course/%EB%B9%84%EC%A0%84%EA%B3%B5%EC%9E%90-mysql-%EC%84%B1%EB%8A%A5%EC%B5%9C%EC%A0%95%ED%99%95-sql%ED%8A%9C%EB%8B%9D
<비전공자도 이해할 수 있는 MySQL 성능 최적화 입문/실전 (SQL 튜닝편)> 강의를 토대로 작성한 내용입니다.
https://rnokhs.tistory.com/entry/MySQL-%EC%8B%A4%ED%96%89-%EA%B3%84%ED%9A%8D-%ED%86%BA%EC%95%84%EB%B3%B4%EA%B8%B0
