멀티 컬럼 인덱스를 생성해 데이터베이스 튜닝하기
목표
100만 개의 데이터를 삽입한 테이블에서 한 번에 조회하는 데이터의 개수를 다르게 책정해 성능을 비교해 보고 개선한다.
성능 측정 수치
소요시간(ms)
성능 개선 시 성능이 개선 됐는지 정확한 판단을 하기 위해 개선 이전의 수치와 개선 이후의 수치를 정확히 측정해서 비교할 것
쿼리를 여러 번 실행해 평균적으로 어느 정도의 시간이 소요되는지 측정
과정
-
users 테이블 생성 및 확인
DROP TABLE IF EXISTS users; CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), age INT ); select * from users
-
users 테이블에 100만개의 랜덤 데이터 삽입
SET SESSION cte_max_recursion_depth = 1000000; INSERT INTO users (name, age) WITH RECURSIVE cte (n) AS ( SELECT 1 UNION ALL SELECT n + 1 FROM cte WHERE n < 1000000 ) SELECT CONCAT('User', LPAD(n, 7, '0')), FLOOR(1 + RAND() * 100) AS age FROM cte; SELECT COUNT(*) FROM users;
- 성능 측정: 데이터 100,000개 조회
SELECT * FROM users LIMIT 100000; - 성능 측정: 데이터 10개 조회
SELECT * FROM users LIMIT 10;
결과
100,000건의 데이터 조회 시: 평균 소요시간 68.4ms
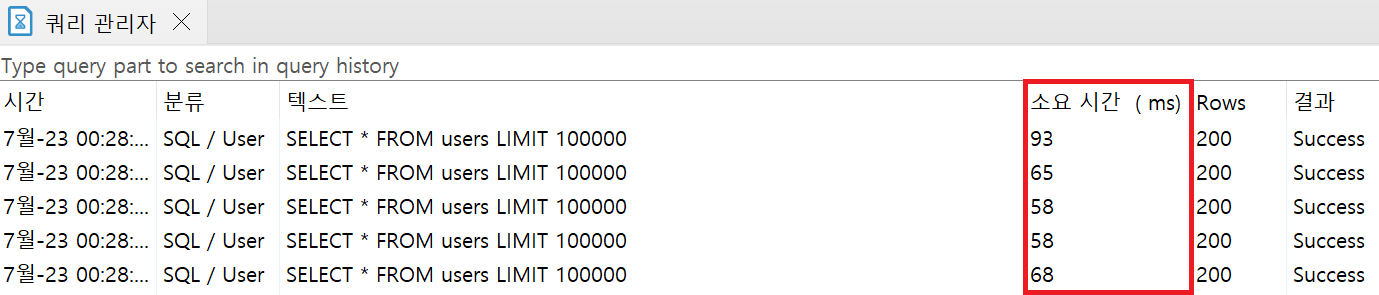
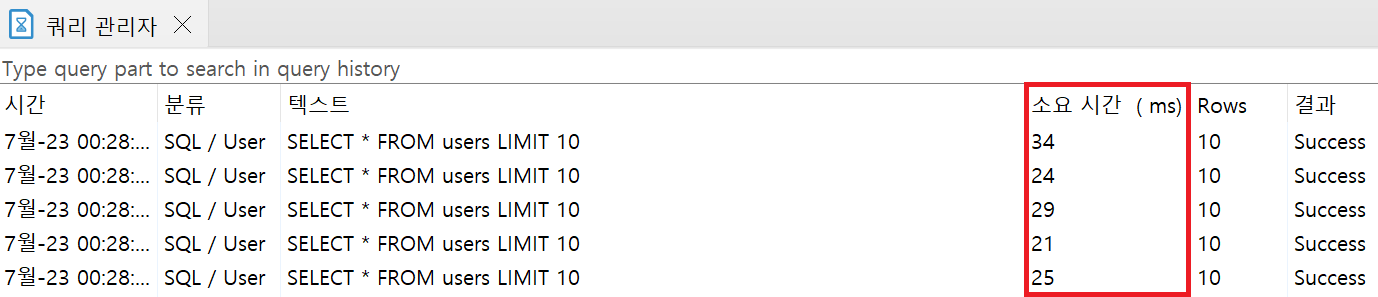
10건의 데이터 조회 시: 평균 소요시간 26.6ms
결론
100,000만건의 데이터를 조회할 때보다 10건의 데이터를 조회할 때의 소요시간이 약 3분의 1로 단축되는 것을 확인했다.
한 번에 너무 많은 양의 데이터를 조회하면 성능이 더 안 좋을 것이라는 생각을 직접 실습을 해 보며 실제로 확인했는데, 페이지 네이션이나 무한 스크롤 등을 이용해 한 번에 불러오는 데이터의 수를 제한하는 이유가 여기에 있다는 것을 알게 되었다.
참고
https://www.inflearn.com/course/%EB%B9%84%EC%A0%84%EA%B3%B5%EC%9E%90-mysql-%EC%84%B1%EB%8A%A5%EC%B5%9C%EC%A0%95%ED%99%95-sql%ED%8A%9C%EB%8B%9D
<비전공자도 이해할 수 있는 MySQL 성능 최적화 입문/실전 (SQL 튜닝편)> 강의를 토대로 작성한 내용입니다.

혁신적인 백엔드 개발자가 되고자, 기록✏️